
EasyRec可以帮助您快速构建推荐模型。本文以读取MaxCompute表数据为例,介绍如何使用EasyRec进行模型训练、配置任务例行化及部署模型。
前提条件
开通OSS,并创建Bucket,详情请参见开通OSS服务和控制台创建存储空间。
重要创建Bucket时,不要开通版本控制,否则同名文件无法覆盖。
开通PAI,并完成OSS访问授权,详情请参见开通和云产品依赖与授权:Designer。
购买DataWorks,您可以根据需要选择合适的资源类型(建议使用按量计费),详情请参见购买指引。
如果使用子账号部署模型,则需要为其授权部署权限,建议添加EAS涉及的所有权限点,详情请参见云产品依赖与授权:EAS。
背景信息
EasyRec算法库是阿里云PAI的推荐算法工具,包含DeepFM、DIN、MultiTower及DSSM等经典推荐排序和召回算法,可以帮助您在PAI平台上快速训练推荐算法模型、验证模型效果及部署。EasyRec算法库已经在信息推送、游戏、直播及竞价广告商等客户的生产环境中部署,能够大幅提升模型训练效率。EasyRec算法库的DataConfig配置和FeatureConfig配置要求如下:
DataConfig配置
input_fields
EasyRec支持读取MaxCompute数据或HDFS数据,MaxCompute表中的每一列或CSV文件中的某一列,都需要与data_config中的一个input_fields对应,且字段顺序一致。input_fields的字段详情如下表所示。
字段
描述
示例
input_name
便于在feature_configs及data_config.label_fields中引用。
input_fields: { input_name: "label" input_type: FLOAT default_val:"" }input_type
输入类型,默认值为STRING。
default_val
数据为空时的默认填充值,通常设置为空字符串。根据input_type不同取值,default_val配置示例如下:
input_type为INT类型时,如果使用填充值6,则default_val配置为"6"。
input_type为FLOAT类型时,如果使用填充值0.5,则default_val配置为"0.5"。
说明input_fields的字段顺序必须与MaxCompute表中的字段顺序一致。
input_fields与CSV文件中的字段顺序必须一致(CSV文件无Header)。
input_fields中的input_type字段必须与MaxCompute表或CSV文件对应列的类型一致,或是可以转换的类型。例如:
MaxCompute表中STRING类型的“64”,可以转换为INT类型的64。
MaxCompute表中STRING类型的“abc”,不能转换为INT类型。
input_type
默认为CSVInput。如果在MaxCompute上,则使用OdpsInputV2。
separator
使用CSV格式的输入时,需要指定separator作为列之间的分隔符。默认使用半角逗号(,)分隔。您也可以使用二进制分隔符,例如'\001'或'\002'。
label_fields
Label相关的列名,根据算法需要可以设置多个,例如多目标算法。该列名必须在data_config中存在。
prefetch_size
Data Prefetch,以Batch为单位,默认值为32。设置prefetch_size可以提高数据加载的速度,防止数据瓶颈。
shuffle
设置该参数,可以对训练数据进行Shuffle,以获得更好的训练结果。
shuffle_buffer_size
Shuffle Queue的大小,表示每次Shuffle的数据量。该参数取值越大,训练效果越好。建议在训练前进行一次充分的Shuffle。
FeatureConfig配置
常用特征主要包括:
IdFeature(离散值特征/ID类特征)
例如user_id、item_id、category_id、age及星座均属于IdFeature。
RawFeature(连续值类特征)
RawFeature类特征可以在Designer中先进行离散化(例如等频、等距或自动离散化),变成IdFeature。也可以直接在feature_configs中配置离散化区间。
TagFeature(多值特征/标签类特征)
TagFeature类特征格式通常为“XX|XX|XX”。例如,文章标签特征为“娱乐|搞笑|热门”,其中竖杠(“|”)为分隔符。
SequenceFeature(行为序列类特征)
SequenceFeature类特征格式通常为“XX|XX|XX”。例如,用户行为序列特征为"item_id1|item_id2|item_id3",其中竖杠(“|”)为分隔符。该特征通常在DIN算法或BST算法中使用。
ComboFeature(组合特征)
对输入的离散值进行组合
各特征的共用字段及特有字段如下。
表 1. 各特征的共用字段 字段
描述
input_names
输入的字段。根据实际需要,可以设置1个或多个字段。
feature_name
特征名称。如果未设置该字段,则默认为input_names[0]。
shared_names
其它输入的数据列。仅适用于只有一个input_names的特征,不适用于有多个input_names的特征(例如ComboFeature)。
表 2. 各特征的特有字段 特征
字段
描述
示例
IdFeature
embedding_dim
Embedding Dimension。
feature_configs { input_names: "uid" feature_type: IdFeature embedding_dim: 64 hash_bucket_size: 100000 }重要不能同时指定hash_bucket_size、 num_buckets、vocab_list及vocab_file,只能指定其中之一。
hash_bucket_size
Hash Bucket的大小,取值策略如下:
对于user_id等规模比较大的特征,Hash冲突影响比较小,可以将hash_bucket_size设置为
number_user_ids/ratio,ratio通常为10~100。对于星座等规模比较小的特征,Hash冲突影响比较大,可以将hash_bucket_size设置为
number_xingzuo_ids*ratio,ratio通常为5~10。
num_buckets
Buckets Number。仅当输入为INT类型时,可以使用该参数。
vocab_list
指定词表,适合取值比较少,可以枚举的特征。例如星期、月份或星座。
vocab_file
使用文件指定词表,用于指定比较大的词表。
RawFeature
boundaries
分桶的值,通过一个数组进行设置。
feature_configs { input_names: "ctr" feature_type: RawFeature boundaries: [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0] embedding_dim: 8 }embedding_dim
如果设置了分桶,则需要配置Embedding Dimension。
TagFeature
separator
分割符,默认为竖杠(“|”)。
feature_configs { input_names: "article_tag" feature_type: TagFeature embedding_dim: 16 hash_bucket_size: 1000 }hash_bucket_size
Hash分桶大小,配置策略与IdFeature类似。
num_buckets
输入为整数时(例如6|20|32),可以配置该参数为其中的最大值。
embedding_dim
Embedding Dimension,与IdFeature中的该参数类似。
SequenceFeature
embedding_dim
Embedding Dimension。
feature_configs { input_names: "play_sequence" feature_type: SequenceFeature embedding_dim: 64 hash_bucket_size: 100000 }hash_bucket_size
配置策略同IdFeature中的该参数。
ComboFeature
input_names
需要组合的特征名,数量大于或等于2,来自data_config.input_fields.input_name。
feature_configs { input_names: ["age", "sex"] feature_type: ComboFeature embedding_dim: 16 hash_bucket_size: 1000 }embedding_dim
Embedding Dimension,类似IdFeature中的该参数。
hash_bucket_size
Hash Bucket的大小 。
数据集
本文使用天池平台上的淘宝点击数据,详情请参见数据集。
步骤一:创建工作流
进入数据开发页面。
登录DataWorks控制台,切换至目标地域后,单击左侧导航栏的,在下拉框中选择对应工作空间后单击进入数据开发。
在数据开发页面,鼠标悬停至
 图标,单击新建业务流程。
图标,单击新建业务流程。在新建业务流程对话框中,输入业务名称和描述。
单击新建。
在业务流程页面,创建PAI Designer节点。
单击新建节点,拖拽至右侧画布。
在新建节点页面的名称文本框中,输入prepare_train_data,其他参数使用默认值。
单击确认。
在业务流程页面,创建MaxCompute SQL节点。
拖拽至右侧画布。
在新建节点页面的名称文本框,输入EasyRec_train,其他参数使用默认值。
单击确认。
在业务流程页面,创建Shell节点。
拖拽至右侧画布。
在新建节点页面的名称文本框,输入deploy,其他参数使用默认值。
单击确认。
步骤二:训练并部署模型
准备数据。
您可以直接使用处理后的样本表:训练表为pai_online_project.easyrec_demo_taobao_train_data,评估表为pai_online_project.easyrec_demo_taobao_test_data,即省略PAI Designer节点,直接从MaxCompute SQL节点开始。
您也可以按照以下流程准备数据。将天池平台上淘宝点击数据整合后的表为pai_online_project.easyrec_demo_taobao_ori_data,该数据集除大部分STRING类型的IdFeature类特征外,还有一列DOUBLE类型的Price特征(RawFeature类特征),需要使用Designer的分箱组件进行特征工程,您可以为已创建的机器学习节点关联如下Designer工作流(只能关联与DataWorks在同一地域的Designer工作流),详情请参见创建机器学习(PAI)节点。
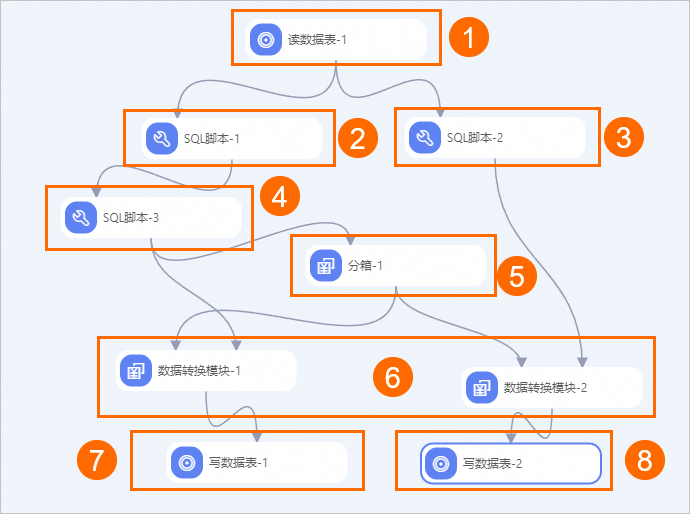 具体的实验流程如下。
具体的实验流程如下。序号
描述
①
读入数据。
②
分割出训练数据。
③
分割出评估数据。
④
Shuffle过程。
⑤
使用分箱组件,进行等频离散。
⑥
根据等频离散的结果,对数据进行转换。
⑦
将训练数据写入表。
⑧
将评估数据写入表。
训练并导出模型。
在已创建的DataWorks的MaxCompute SQL节点中,执行如下命令,进行模型训练。
PAI -project algo_public -name easy_rec_ext -Darn="acs:ram::XXXXX:role/AliyunODPSPAIDefaultRole" -Dbuckets="oss://examplebucket/xxx/" -Dcluster="{\"ps\":{\"count\":2,\"cpu\":1000,\"memory\":40000},\"worker\":{\"count\":8,\"cpu\":1000,\"memory\":40000}}" -Dcmd="train" -Dconfig="oss://examplebucket/xxx/multitower.config" -DossHost="oss-cn-region_name-internal.aliyuncs.com" -Dtrain_tables="odps://pai_online_project/tables/easyrec_demo_taobao_train_data" -Deval_tables="odps://pai_online_project/tables/easyrec_demo_taobao_test_data" -Dmodel_dir="oss://examplebucket/xxx/" -Dwith_evaluator=1;命令中的参数如下所示,需要根据实际情况替换参数值。
参数
描述
示例
project
工程名。EasyRec算法所在的project,默认为algo_public,通常不需要修改。仅特殊情况(EasyRec官方另行通知时)才需要修改。
algo_public
arn
ARN的角色名称。您可以登录PAI控制台,在页面的Designer区域,单击操作列下的查看授权信息,获取arn。
"acs:ram::XXXXX:role/AliyunODPSPAIDefaultRole"
buckets
用于指定算法将要读取的OSS bucket。
"oss://examplebucket/xxx/"
cluster
分布式运行任务信息,详情请参见PAI-TF任务参数介绍中的cluster参数介绍。
"{\"ps\":{\"count\":2,\"cpu\":1000,\"memory\":40000},\"worker\":{\"count\":8,\"cpu\":1000,\"memory\":40000}}"
cmd
需要配置为固定值train。
"train"
config
模型Config文件的OSS路径,您可以参考此处的MultiTower模型Config文件(下载Config示例)。
"oss://examplebucket/xxx/multitower.config"
ossHost
OSS Endpoint,地域和Endpoint对照表请参见公共云下OSS Region和Endpoint对照表。
oss-cn-region_name-internal.aliyuncs.com
train_tables
训练表,多个训练表之间使用半角逗号(,)分隔。
"odps://pai_online_project/tables/easyrec_demo_taobao_train_data"
eval_tables
评估表,多个评估表之间使用半角逗号(,)分隔。
"odps://pai_online_project/tables/easyrec_demo_taobao_test_data"
model_dir
模型目录,将会覆盖config配置的模型路径,一般在周期性调度时使用。
"oss://examplebucket/xxx/"
with_evaluator
是否在训练时使用一个Worker进行评估。通常设置8个Worker,其中七个Worker进行训练,一个Worker进行评估(计算测试集的AUC)。取值范围如下:
0:训练时不使用Worker进行评估。
1:训练时使用一个Worker进行评估。
1
训练完成后,系统会自动将模型导出至
model_dir配置路径下的/export/final/目录。部署模型(该步骤中的命令均在已创建的DataWorks的Shell节点中执行)。
执行如下命令编写描述服务相关信息(模型存储位置及资源规格等)的JSON文件,该文件的详细参数请参见创建服务,如下仅给出编写JSON文件的示例命令,需要您根据实际情况修改参数值。
ymd=$1 #获取例行化配置中设置的日期参数。 cat << EOF > echo.json { "cloud": { "computing": { "instance_type": "ecs.c7.large" } }, "metadata": { "instance": 1, "name": "model_name" }, "model_path": "your_model_path", "processor": "tensorflow_cpu_1.12", } EOF其中:model_path需要配置为上述步骤已生成的模型路径;name配置为模型服务名称,同地域内唯一。
部署模型。
您可以根据实际部署情况,选择创建服务或更新服务:
如果首次部署服务,则可以使用如下命令,创建新服务。
/home/admin/usertools/tools/eascmd -i <yourAccessId> -k <yourAccessKey> -e <OSS Endpoint> create <echo.json>参数
描述
示例
<yourAccessId>
阿里云账号的AccessKey ID。
无
<yourAccessKey>
阿里云账号的AccessKey Secret。
无
<OSS Endpoint>
将模型部署至某地域,此参数为该地域对应的Endpoint,取值详情请参见命令使用说明中地域与Endpoint的对应关系表。
pai-eas.cn-shanghai.aliyuncs.com
<echo.json>
上一步中编写的描述服务相关信息(模型存储位置及资源规格等)的JSON文件名称。
echo.json
如果存在已经部署的服务,则可以使用如下命令,更新服务。
/home/admin/usertools/tools/eascmd -i <yourAccessId> -k <yourAccessKey> -e <Endpoint> modify <cn-beijing/model_name> -s echo.json参数
描述
示例
<yourAccessId>
阿里云账号的AccessKey ID。
无
<yourAccessKey>
阿里云账号的AccessKey Secret。
无
<Endpoint>
将模型部署至某地域,此参数为该地域对应的Endpoint,取值详情请参见命令使用说明中地域与Endpoint的对应关系表。
pai-eas.cn-shanghai.aliyuncs.com
<cn-beijing/model_name>
模型地址与OSS数据所在地域一致。该模型名称指描述服务相关信息JSON文件中,name参数的取值。
cn-beijing/model_name
<echo.json>
描述服务相关信息的JSON文件名称。
echo.json
步骤三:配置任务例行化
以天级别更新的模型为例,需要每天例行进行以下操作:
生成训练和评估样本表。
调用EasyRec进行训练并导出模型。
将EasyRec导出后的模型部署到EAS。
在DataWorks中创建的业务流程如下所示。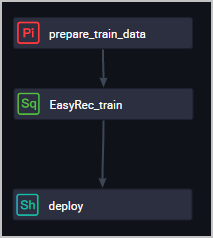 您需要自行配置各节点的属性及调度依赖等关系,此处仅以EasyRec_train节点为例,介绍如何配置节点属性及调度依赖。
您需要自行配置各节点的属性及调度依赖等关系,此处仅以EasyRec_train节点为例,介绍如何配置节点属性及调度依赖。
打开节点页面。
您可以通过以下任意一种方式打开EasyRec_train节点:
双击EasyRec_train节点。
右键单击EasyRec_train,在快捷菜单中,单击打开节点。
在节点页面,单击页面右侧的调度配置。
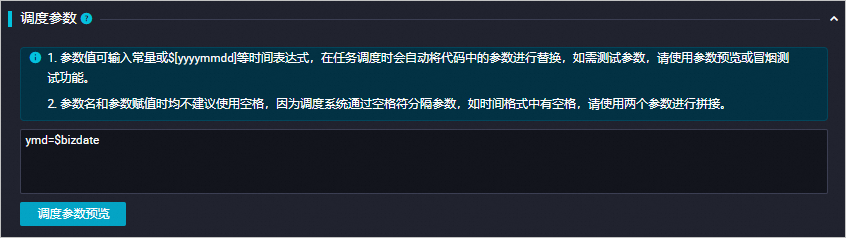
在调度配置页面的调度参数区域,配置时间参数,以区分不同天的任务。
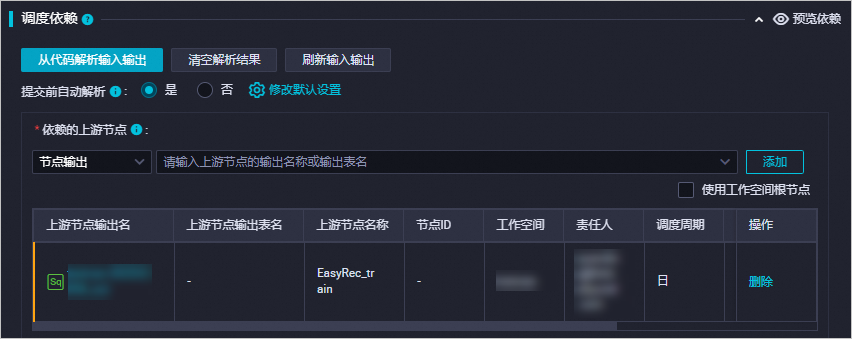
在调度配置页面的调度依赖区域,配置上下游节点,详情请参见配置同周期调度依赖。
 说明
说明如果节点无上游依赖,则使用工作空间根节点。
单击Shell节点页面上方的
 图标,保存配置。
图标,保存配置。在业务流程页面,单击上方的
 图标,运行Shell节点。
图标,运行Shell节点。
Debug
运行EasyRec命令时,DataWorks会打印Logview。您可以通过Logview快速查看模型训练效果或定位错误。
在浏览器中打开Logview(即下图红框中的链接)。
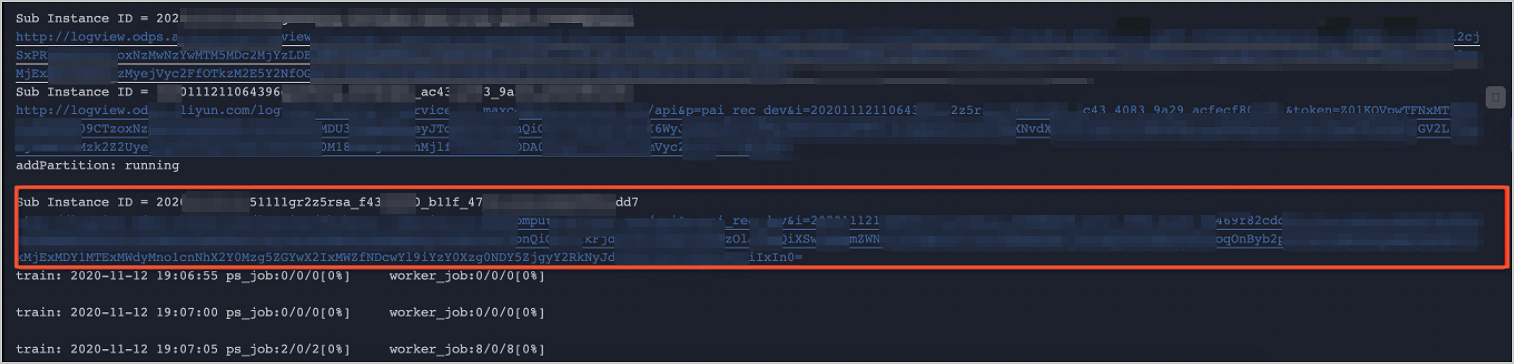
在日志页面的Job Details页签,双击ODPS Tasks实例。
在日志页面的ODPS Tasks区域,单击ODPS Tasks实例。
在Worker运行页面,可以根据需要选择查看对应的实例。
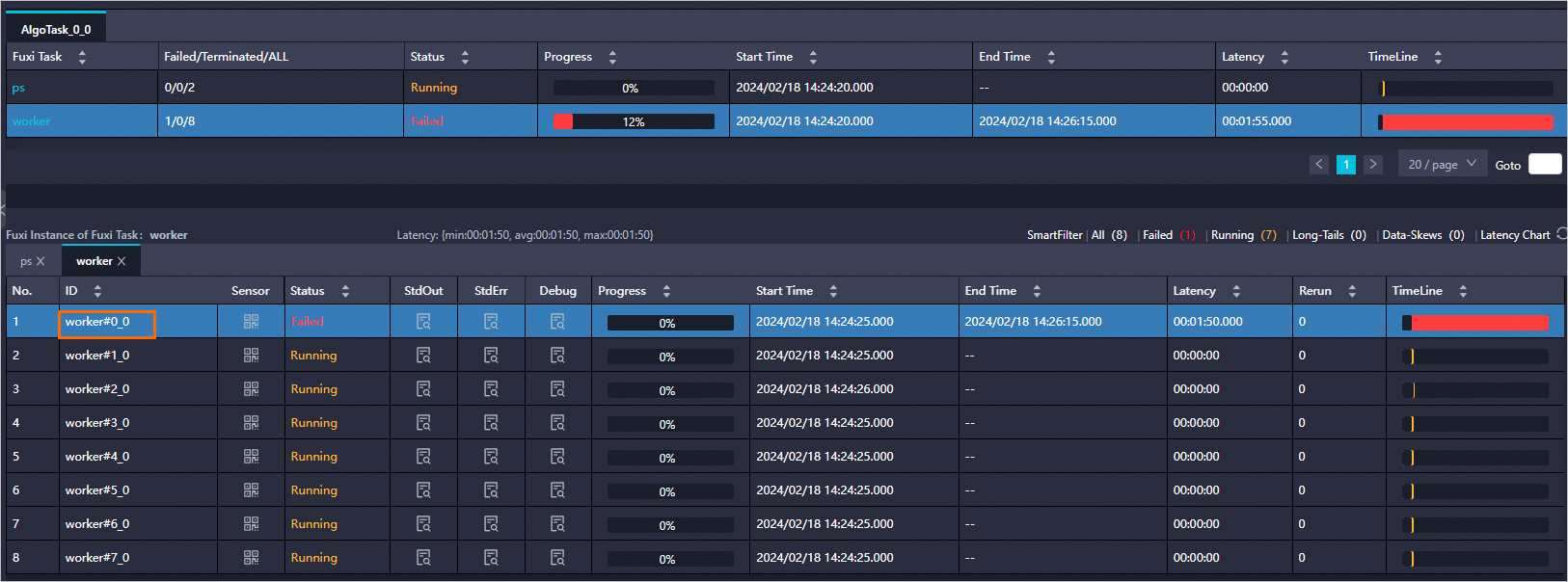 其中:
其中:worker 0为训练worker(worker 0、worker 2~worker 7均为训练worker),单击StdEarr列下的
 图标,即可查看训练进程。
图标,即可查看训练进程。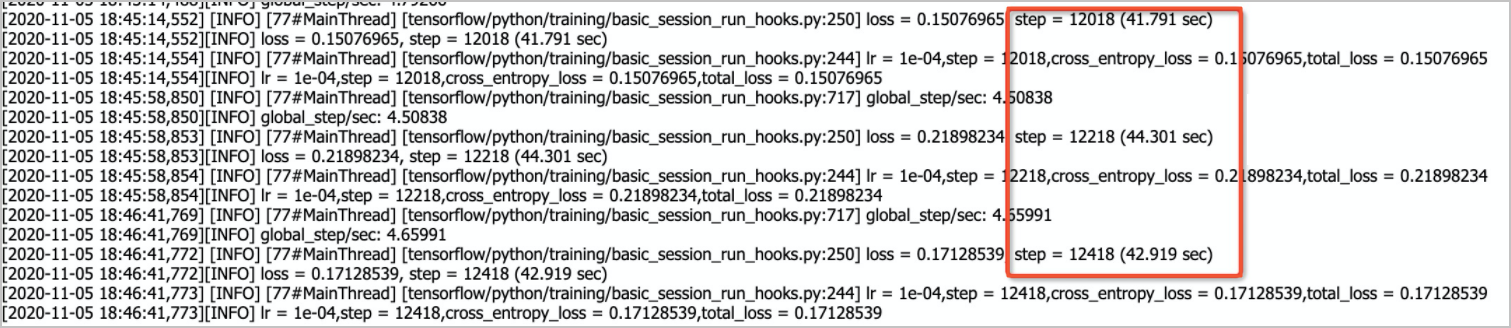 每log_step_count_steps步,打印一次日志。
每log_step_count_steps步,打印一次日志。worker1为评估worker,单击stderr列下的
 图标,即可查看模型在评估集上的指标。
图标,即可查看模型在评估集上的指标。
后续步骤
您可以在EAS中查看已经部署的模型,并在线调用该服务,详情请参见服务在线调试。