定价概述 | 开通百炼不会产生费用,调用大模型实现文本生成、图片生成、语音合成等任务时,会产生模型推理(调用)费用。此外,如果训练(调优)新模型或将模型部署到实例也会产生费用。  查看账单:请访问账单详情和成本分析页面。 查看模型调用统计:请访问模型观测页面。 |
计费项 | 模型推理(调用)计费方式 | 按模型调用量 | 计费公式 | 费用 = 调用消耗量 × 单价 | 计费说明 | 免费额度:在免费额度内,实时调用不收费。查看剩余额度数据按小时更新,高峰期可能有小时级延迟。 计费单价:查看价格 如何付费:调用模型会自动扣费,也称为后付费。充值入口 您也可预付费,预付费与后付费价格相同,无折扣差异。 |
模型训练(调优)如何进行模型训练(调优),请参见:模型调优 计费方式 | 按训练数据量计费 | 计费公式 | 费用 = (训练数据 Token 数 + 混合训练数据 Token 数)× 循环次数 × 训练单价 开始训练前会显示预估费用和计费详情 | 计费说明 | 模型训练后获得的新模型必须进行模型部署才能评测和调用。 |
模型部署如何进行模型部署,请参见:模型部署简介 计费方式 | 按资源占用时长计费 | 按模型调用量计费 | 计费公式 | 费用 = 资源占用时长 × 资源数量 × 单价 支持模型丰富 | 费用 = 调用消耗量 × 调用单价 单价与模型推理(调用)单价相同 | 计费说明 | 适合对大模型推理服务有低延迟、高SLA需求的场景。 | 适合对模型训练的结果进行快速验证。 |
|
模型推理(调用)计费 | 计费概述&免费额度模型调用价格请参考模型列表。详细的 RPM、TPM 等性能信息请参考限流。
说明 如何获取免费额度以及如何查看剩余免费额度请参考新人免费额度。 在模型观测页面查看具体模型的调用次数和消耗Token数。 预付费(节省计划)您可以购买节省计划(预付费),用于抵扣模型推理超出免费额度后产生的推理费用。节省计划用完后,系统会开始使用账户余额扣费,您也可以购买多个节省计划进行抵扣。 大语言模型购买方式 | 单击此处购买大语言模型推理节省计划。 | 适用模型 | 阿里云百炼平台上,按 Token 计费的在架商业化模型(例如,通义千问、DeepSeek以及通义法睿等)。请前往模型列表查看所有按Token计费的模型及其调用价格。 | 使用说明 | 使用百炼时,将优先消耗节省计划的额度。如果购买了多个节省计划,抵扣时将按节省计划到期时间的先后顺序抵扣。如果到期时间相同,先购买的节省计划将优先抵扣。 | 查询节省计划账单 | 请参见如何查询节省计划账单。 |
通义万相模型购买方式 | 单击此处购买通义万相模型节省计划。 | 购买说明 | 阿里云百炼提供五个购买档位,分别为: 20元:无折扣 100元:无折扣 1,000元:享9.8折优惠 10,000元:享9.5折优惠 30,000元:享9折优惠
优惠示例:以 1,000元 档位为例,假设生成某个视频消费1元,实际将从节省计划中抵扣1*0.98=0.98元。 | 有效期 | | 使用说明 | 使用百炼时,将优先消耗节省计划的额度。如果购买了多个节省计划,抵扣时将按节省计划到期时间的先后顺序抵扣。 | 查询节省计划账单 | 请参见如何查询节省计划账单。 | 适用模型 | 图像生成:wan2.5-t2i-preview、wan2.5-i2i-preview、wan2.2-t2i-plus、wan2.2-t2i-flash、wanx2.0-t2i-turbo、wanx2.1-t2i-plus、wanx2.1-imageedit、wanx2.1-t2i-turbo、wanx-sketch-to-image-lite、wanx-v1 视频生成:wan2.5-t2v-preview、wan2.5-i2v-preview、wan2.2-t2v-plus、wan2.2-i2v-flash、wan2.2-t2v-flash、wan2.2-i2v-plus、wanx2.1-vace-plus、wanx2.1-kf2v-plus、wanx2.1-t2v-turbo、wanx2.1-t2v-plus、wanx2.1-i2v-turbo、wanx2.1-i2v-plus 请前往模型列表查看所有模型及其调用价格。 |
通义语音模型购买方式 | 单击此处购买通义语音模型节省计划。 | 购买说明 | 阿里云百炼提供五个购买档位,分别为: 20元:享9.8折优惠 100元:享9.6折优惠 500元:享9折优惠 1,000元:享8.5折优惠 5,000元:享8折优惠
优惠示例:以 1,000元 档位为例,假设消费1元,实际将从节省计划中抵扣1*0.85=0.85元。 ASR模型按秒计费,TTS模型按字符计费,请前往模型列表查看模型调用价格。 | 有效期 | 六个月。 | 使用说明 | 使用百炼时,将优先消耗节省计划的额度。如果购买了多个节省计划,抵扣时将按节省计划到期时间的先后顺序抵扣。 | 查询节省计划账单 | 请参见如何查询节省计划账单。 | 适用模型 | 因地域而异: 北京: 实时语音合成(CosyVoice):cosyvoice-v3-plus、cosyvoice-v3-flash、cosyvoice-v2、cosyvoice-v1 实时语音合成(Qwen-TTS-Realtime):qwen3-tts-flash-realtime、qwen3-tts-flash-realtime-2025-09-18、qwen-tts-realtime、qwen-tts-realtime-latest、qwen-tts-realtime-2025-07-15 语音合成(Qwen-TTS):qwen3-tts-flash、qwen3-tts-flash-2025-09-18、qwen-tts、qwen-tts-latest、qwen-tts-2025-05-22、qwen-tts-2025-04-10 实时语音识别(Paraformer):paraformer-realtime-v2、paraformer-realtime-v1、paraformer-realtime-8k-v2、paraformer-realtime-8k-v1 实时语音识别(Fun-ASR):fun-asr-realtime、fun-asr-realtime-2025-11-07、fun-asr-realtime-2025-09-15 实时语音识别(Qwen-ASR-Realtime):qwen3-asr-flash-realtime、qwen3-asr-flash-realtime-2025-10-27 实时长语音识别/翻译(Gummy):gummy-realtime-v1 实时短语音(一句话)识别/翻译(Gummy):gummy-chat-v1 录音文件识别(Paraformer):paraformer-v2、paraformer-v1、paraformer-8k-v2、paraformer-8k-v1、paraformer-mtl-v1 录音文件识别(Fun-ASR):fun-asr、fun-asr-2025-11-07、fun-asr-2025-08-25、fun-asr-mtl、fun-asr-mtl-2025-08-25 录音文件识别(Qwen-ASR):qwen3-asr-flash-filetrans、qwen3-asr-flash-filetrans-2025-11-17、qwen3-asr-flash、qwen3-asr-flash-2025-09-08 录音文件识别(SenseVoice):sensevoice-v1
新加坡: 实时语音合成(Qwen-TTS-Realtime):qwen3-tts-flash-realtime、qwen3-tts-flash-realtime-2025-09-18 语音合成(Qwen-TTS):qwen3-tts-flash、qwen3-tts-flash-2025-09-18 实时语音识别(Qwen-ASR-Realtime):qwen3-asr-flash-realtime、qwen3-asr-flash-realtime-2025-10-27 录音文件识别(Fun-ASR):fun-asr、fun-asr-2025-11-07、fun-asr-2025-08-25 录音文件识别(Qwen-ASR):qwen3-asr-flash-filetrans、qwen3-asr-flash-filetrans-2025-11-17、qwen3-asr-flash、qwen3-asr-flash-2025-09-08
请前往模型列表查看所有模型。 |
预付费资源包您可以购买预付费资源包,用于抵扣实时推理调用费用,相比按量付费更加优惠,具体可参考模型列表。 订购地址 | 大语言模型推理资源包qwen-plus | 大语言模型推理资源包qwen-max | 大语言模型推理资源包qwen-turbo | 适用模型 | qwen-plus及qwen-plus-latest 的实时推理服务(非思考模式) | qwen-max及qwen-max-latest 的实时推理服务(非思考模式) | qwen-turbo及qwen-turbo-latest 的实时推理服务(非思考模式) | 包含输入和输出总tokens | 1,200万/1.1亿 | 1,800万/3,900万/3.9亿/11.7亿/19.5亿 | 3,500万/3.5亿/17.5亿/35亿 | 价格(元) | 11.66/114.4 | 57.6/125/1250/3750/6250 | 11.45/114.45/572.25/1144.5 | 有效期 | 自购买日起生效,有效期可选 3 个月、6 个月或 1 年。 | 自购买之日起有效期为 1 年。 | 自购买之日起有效期为 1 年。 |
重要 资源包只适用于上述规格的模型,抵扣规则因模型而异。 常见问题 如何查看资源包及相关信息? 查看资源包剩余量:访问阿里云费用与成本页面,点击资源包查看剩余量情况,点击统计查看使用信息。具体请参见资源包使用介绍。 资源包统计数据存在一定延迟,具体以统计详情页为准。 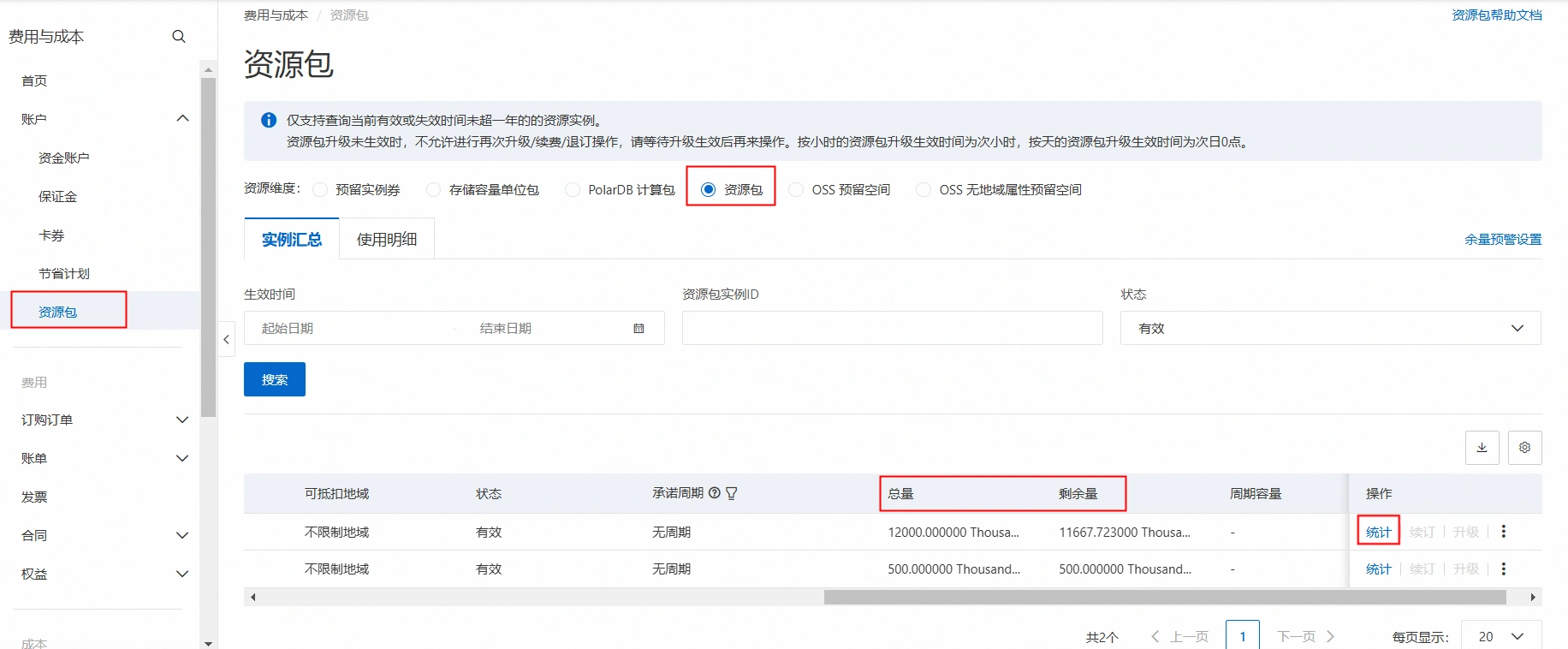
查看剩余的免费额度:访问模型广场页面,找到目标模型并单击查看详情,即可查看免费额度信息。具体请参见新人免费额度。 控制台显示的免费额度每小时更新,非实时数据。 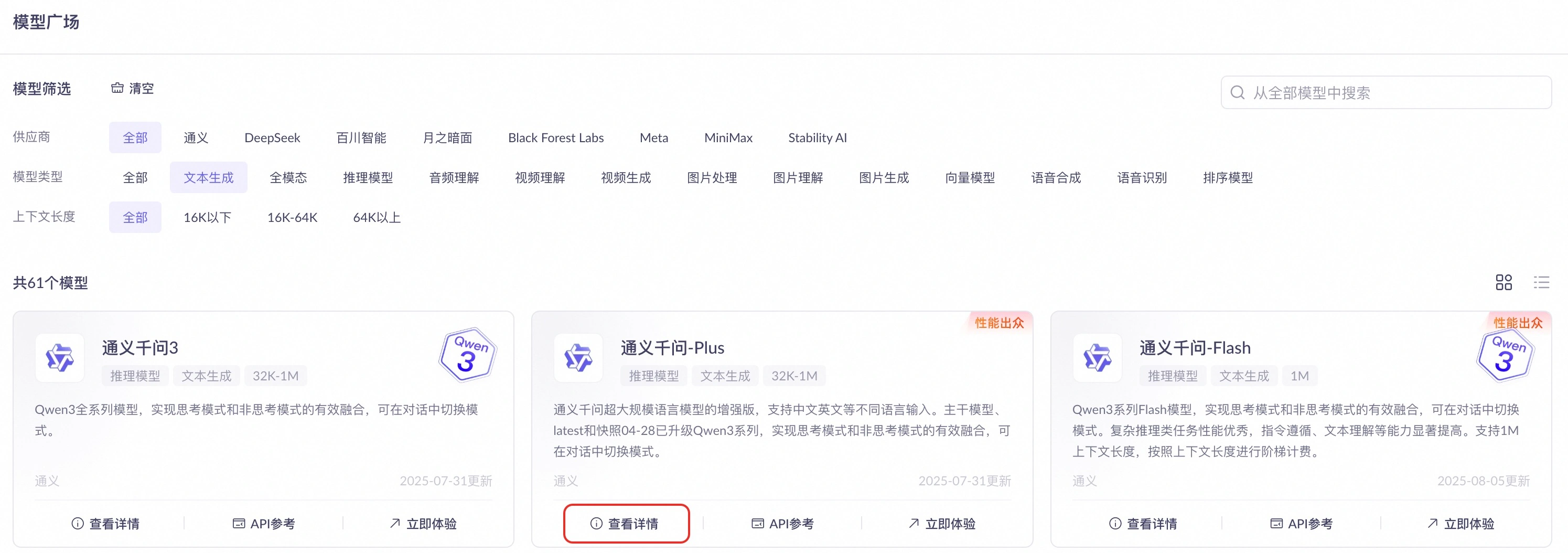
查看模型的调用信息:模型调用完一小时后,在模型观测页面设置查询条件(例如,选择时间范围、业务空间等),再在模型列表区域找到目标模型并单击操作列的监控,即可查看该模型的调用统计结果。具体请参见用量与性能观测文档。 数据按小时更新,高峰期可能有小时级延迟,请您耐心等待。 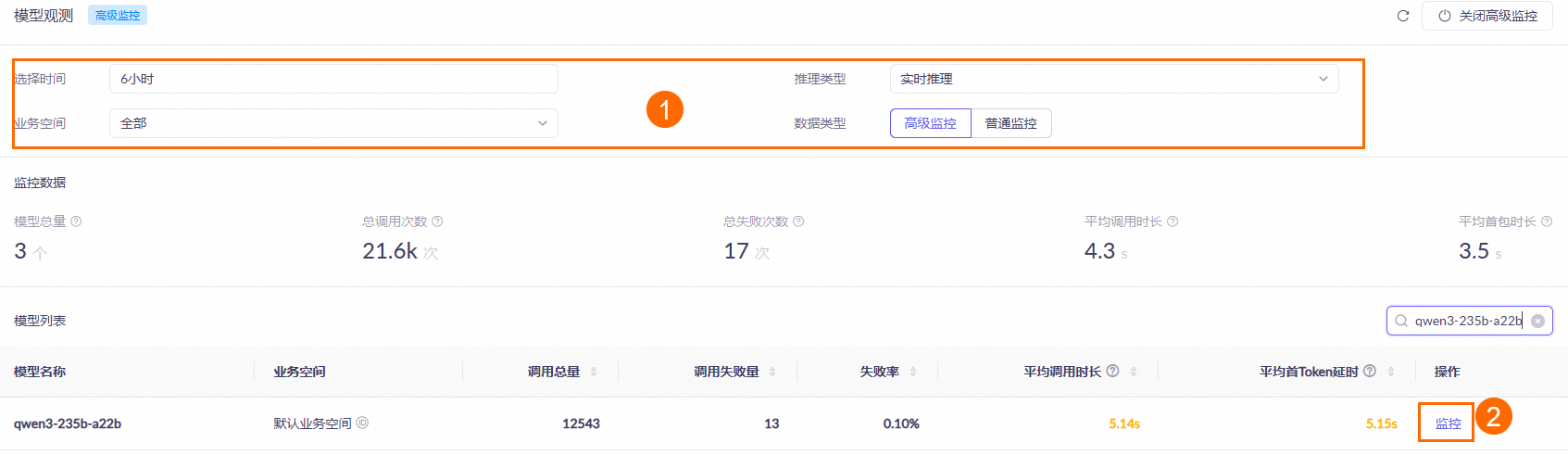
查看账单详情:请前往阿里云账单详情页面。
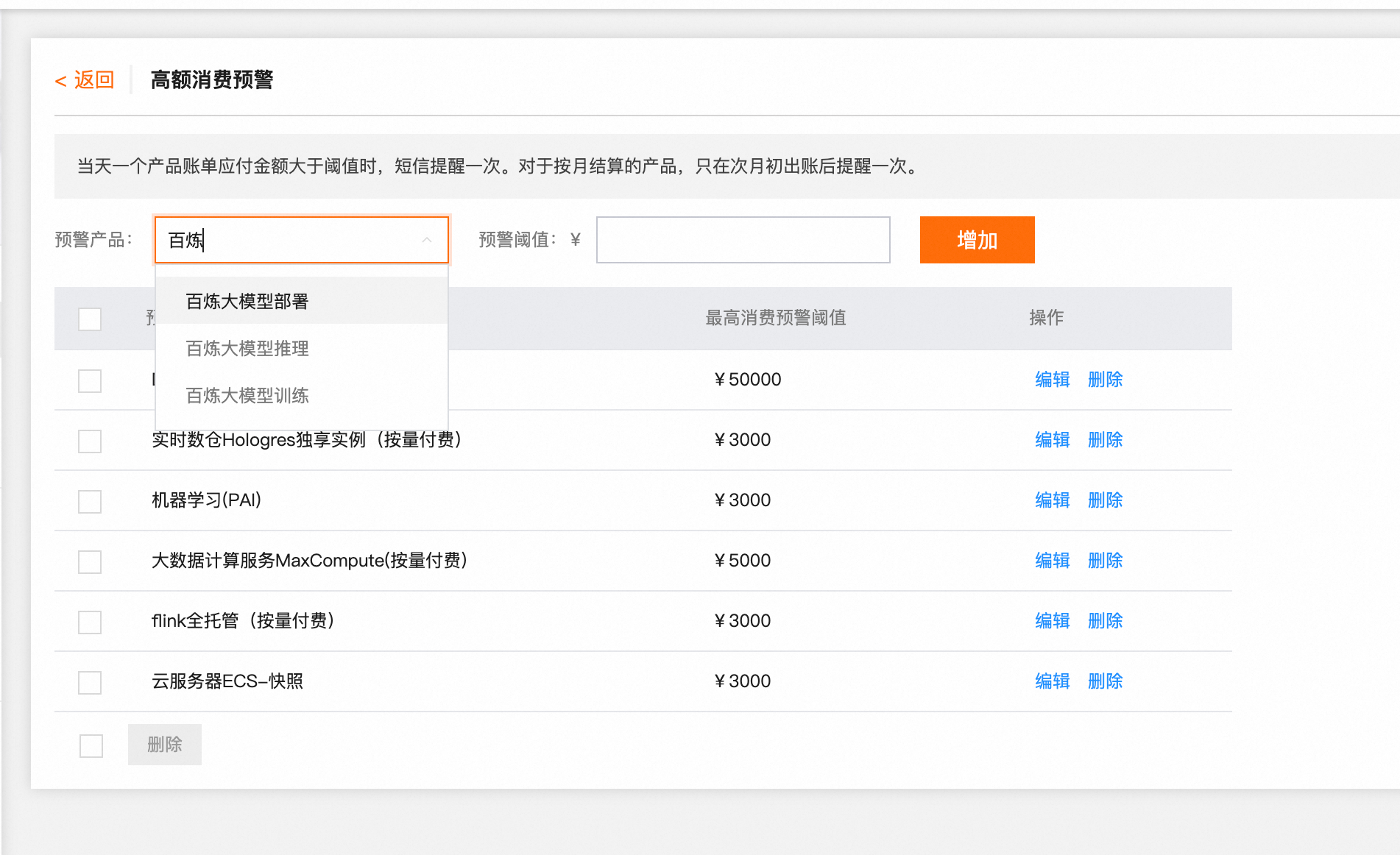
费用的抵扣顺序是什么? 新人免费额度 > 资源包 > 账户余额。资源包购买后立即生效,无需手动“激活”或“绑定”。 资源包额度用完后是否有提醒? 可以设置资源包余量预警,当资源包使用量低于预设阈值时,系统将通过短信、邮件及站内信自动触发通知。 当前可以购买哪些模型的资源包? 当前仅推出了qwen-plus、qwen-plus-latest和qwen-max、qwen-max-latest模型的资源包,暂不支持其他模型。 资源包订购后支持退款吗? 不支持自动退款,参考阿里云平台交易规范,预付费商品未发生使用的按未使用额度费用申请退款。关于退订管理,请参见退订规则。 如果先购买了资源包但未开通阿里云百炼服务,应该如何使用? 请登录阿里云百炼控制台,点击页面右下角 图标领取免费额度并开通后付费计费项,优先会抵扣免费额度,待免费额度消耗完后,才会开始抵扣资源包。 图标领取免费额度并开通后付费计费项,优先会抵扣免费额度,待免费额度消耗完后,才会开始抵扣资源包。
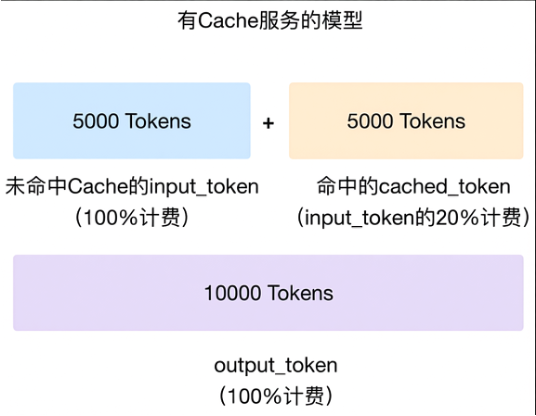
Batch 调用减免对于无需实时响应的推理场景,批量推理(Batch API)能异步处理大批量的数据请求,成本仅为实时推理的 50%,且接口兼容OpenAI,适合执行模型评测、数据标注等批量作业。 |
模型训练(调优)计费 | 文本生成模型-通义千问计费方式 | 按训练的数据量计费 | 计费公式 | 模型训练费用 = (训练数据 Token 总数 + 混合训练数据 Token 总数)× 循环次数 × 训练单价(最小计费单位:1 token) 您可以查看模型训练控制台底部的预估训练费用,并单击计算详情,查看训练 Token 总数、循环次数和训练单价。 |
通义千问模型服务 | 模型规格 | 价格 | 通义千问2.5-72B | qwen2.5-72b-instruct | 0.15元/千Token | 通义千问2-开源版-72B | qwen2-72b-instruct | 通义千问1.5-开源版-72B | qwen1.5-72b-chat | 通义千问-Plus-0723 | qwen-plus-0723 | | 通义千问3-32B | qwen3-32b | 0.04 元/千Token | | 通义千问3-14B | qwen3-14b | 0.03元/千Token | 通义千问2.5-32B | qwen2.5-32b-instruct | 通义千问2.5-14B | qwen2.5-14b-instruct | 通义千问1.5-开源版-14B | qwen1.5-14b-chat | 通义千问-Plus | qwen-plus | 通义千问Turbo | qwen-turbo | 通义千问-Turbo-0624 | qwen-turbo-0624 | | 通义千问3-8B | qwen3-8b | 0.006元/千Token | 通义千问2.5-7B | qwen2.5-7b-instruct | 通义千问2-开源版-7B | qwen2-7b-instruct | 通义千问1.5-开源版-7B | qwen1.5-7b-chat |
通义千问VL模型服务 | 模型规格 | 价格 | 通义千问VL-Max-0201 | qwen-vl-max-0201 | 0.15元/千Token | 通义千问VL-Plus | qwen-vl-plus | 0.03元/千Token | | | | 通义千问3-VL-8B-Instruct | qwen3-vl-8b-instruct | 0.012元/千Token | 通义千问3-VL-8B-Thinking | qwen3-vl-8b-thinking | | | | 通义千问2.5-VL-72B | qwen2.5-vl-72b-instruct | 0.05 元/千Token | 通义千问2.5-VL-32B | qwen2.5-vl-32b-instruct | 0.02 元/千Token | 通义千问2.5-VL-7B | qwen2.5-vl-7b-instruct | 0.01 元/千Token |
视频生成模型-通义万相
说明 模型训练流程请参见模型调优。训练完成后的新模型需先完成模型部署,才能调用。 训练Tokens总量的计算公式 训练Tokens总量=(i=1∑N视频i的计费时长)×1024max_pixels×n_epochs 其中: N:训练集中的视频总数。 max_pixels:训练时指定的超参数,表示视频的最大像素数(创建微调任务时配置)。 n_epochs:训练时指定的超参数,表示循环次数(创建微调任务时配置)。 视频计费时长计算规则:先将原始视频时长(秒)四舍五入取整,根据模型限制取最终值。 wan2.2模型:计费时长=min(5, 四舍五入后的时长),即单条视频最多按 5 秒计算。 wan2.5模型:计费时长=min(10, 四舍五入后的时长),即单条视频最多按 10 秒计算。
计费示例 假设微调wan2.2模型,训练集包含 2 条视频,时长分别为 3.4 秒 和 6.5 秒,max_pixels = 262144,n_epochs = 400,训练单价 = 0.06元/千Token: 模型服务 | 模型规格 | 训练价格(每千Token) | 通义万相-图生视频-基于首帧 | wan2.2-i2v-flash | 0.06元 | wan2.5-i2v-preview | 0.32元 |
|
模型部署计费 | 通义千问模型-按模型单元(时间)计费基于时间的计费方式都支持手动扩缩容,灵活调整并发量。
说明 模型单元是百炼平台提供的算力部署最小单位,按照使用时长收取资源费用。 计费方式 | 计费公式 | 按资源占用时长(后付费) | 费用 = 使用时长(小时)× 模型单元数量 × 模型单元单价(不满1分钟按1分钟计费) 部署前可以在模型部署控制台查看不同模型的预估每小时费用。 | 资源包月(预付费) | 费用 = 购买时长(月)× 模型单元数量 × 模型单元包月单价(不满1天按1天计费) 如果在开始使用的一个月内提前退订,日单价将为 1.2 倍,退订细节请参考非全额退款。 |
通义千问模型服务 | 单价 | 单价(预付费) | 通义千问-Turbo-0624 | 96元/小时 | 46,000元/月 | 通义千问2.5-开源版-14B | 通义千问2.5-开源版-7B | 通义千问2-开源版-7B | 通义千问3-14B | 通义千问3-8B | 通义千问-Plus-0723 | 192元/小时 | 92,000元/月 | 通义千问2.5-开源版-72B | 通义千问2.5-开源版-32B | 通义千问2-开源版-72B | 通义千问3-32B |
通义千问VL模型服务 | 单价 | 单价(预付费) | 通义千问VL-Plus | 40元/小时 | 20,000元/月 | 通义千问3-VL-8B-Instruct | 96元/小时 | 46,000元/月 | 通义千问3-VL-8B-Thinking | 通义千问2.5-VL-7B | 通义千问VL-Max-0201 | 160元/小时 | 80,000元/月 | 通义千问2.5-VL-32B | 192元/小时 | 92,000元/月 | 通义千问2.5-VL-72B |
通义千问模型-按实例(时间)计费(旧)
说明 自 2025年 10月 24 日起,按实例计费方式不再支持新购。 计费方式 | 计费公式 | 按实例资源占用时长计费 | 费用 = 资源占用时长(小时)× 实例数量 × 实例单价(不满1小时按1小时计费) 部署前可以在模型部署控制台查看不同模型的预估每小时费用。 | 资源包月计费/预付费 | 费用 = 购买时长(月)× 实例数量 × 模型对应的实例单价 购买资源:请前往模型部署控制台(点击右上角的资源池管理)购买。(资源购买完成后便开始计费) 退订资源:请前往主账号的退订管理退订。退订后,将根据未用时长退回未使用金额。(不满1天按1天计费) |
通义千问模型服务 | 模型类型 | 独占实例资源规格 | 实例单价 | 实例单价 (预付费) | 通义千问-Turbo-0624 | 微调模型 | 基础版v2-Qwen2 | 40元/实例/小时 | 20,000元/月 | 通义千问2.5-开源版-14B | 通义千问2.5-开源版-7B | 通义千问2-开源版-7B | 通义千问1.5-开源版-14B | 基础版 | 通义千问1.5-开源版-7B | 通义千问3-14B | NA | 无法预付费 | 通义千问3-8B | 通义千问-Plus-0723 | 标准版v2-Qwen2 | 160元/实例/小时 | 80,000元/月 | 通义千问2.5-开源版-72B | 通义千问2.5-开源版-32B | 通义千问2-开源版-72B | 通义千问1.5-开源版-72B | 标准版 | 通义千问3-32B | NA | 无法预付费 |
通义千问VL模型服务 | 模型类型 | 独占实例资源规格 | 算力单元单价 | 单价 (预付费) | 通义千问VL-Plus | 微调模型 | 基础版 | 40元/实例/小时 | 20,000元/月 | 通义千问VL-Max-0201 | 标准版 | 160元/实例/小时 | 80,000元/月 | | | | | 通义千问2.5-VL-7B | NA | 40元/实例/小时 | 无法预付费 | 通义千问2.5-VL-32B | 160元/实例/小时 | 通义千问2.5-VL-72B | 160元/实例/小时 |
通义千问模型-按模型 Token 调用量计费按模型调用量计费方式价格很低。而如果需要进一步增加并发量,需要部署后在模型部署控制台手动申请,平台会进行人工审批。
重要 一个模型是可以在百炼的模型调优中进行重复训练的。 只有在基于以下基础模型进行“SFT高效训练”后获得的自定义模型,才支持按调用量计费。 计费方式 | 按模型调用量 | 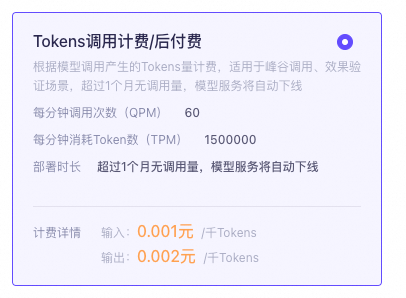
| 计费公式 | 费用 = 模型输入 Token 数 × 模型输入单价 + 模型输出 Token 数 × 模型输出单价(最小计费单位:1 token) |
基础模型 | 输入单价 | 输出单价 | 通义千问3-32B | 0.002元/千Token | 非思考模式:0.008元/千Token 思考模式:0.02元/千Token | 通义千问3-14B | 0.001元/千Token | 非思考模式:0.004元/千Token 思考模式:0.01元/千Token | 通义千问3-8B | 0.0005元/千Token | 非思考模式:0.002元/千Token 思考模式:0.005元/千Token | 通义千问 2.5-72B | 0.004元/千Token | 0.012元/千Token | 通义千问 2.5-32B | 0.002元/千Token | 0.006元/千Token | 通义千问 2.5-14B | 0.001元/千Token | 0.003元/千Token | 通义千问 2.5-7B | 0.0005元/千Token | 0.001元/千Token | 通义千问2.5-VL-72B | 0.016元/千Tokens | 0.048元/千Tokens | 通义千问2.5-VL-32B | 0.008元/千Tokens | 0.024元/千Tokens | 通义千问2.5-VL-7B | 0.002元/千Tokens | 0.005元/千Tokens | 通义千问 2-开源版-7B | 0.001元/千Token | 0.002元/千Token |
图片、视频生成模型(预置)-按实例(时间)计费计费方式 | 计费公式 | 按实例资源占用时长计费 | 费用 = 资源占用时长(小时)× 实例数量 × 实例单价(不满1小时按1小时计费) 部署前可以在模型部署控制台查看不同模型的预估每小时费用。 | 实例包月计费/预付费 | 费用 = 购买时长(月)× 实例数量 × 模型对应的实例单价 购买资源:请前往模型部署控制台(点击右上角的资源池管理)购买。(资源购买完成后便开始计费) 退订资源:请前往主账号的退订管理退订。退订后,将根据未用时长退回未使用金额。(不满1天按1天计费) |
图片生成模型服务 | 模型类型 | 独占实例资源规格 | 实例单价 | 实例单价 (预付费) | 通义万相-文本生成图像-0521 | 预置模型 | 轻量版 | 20元/实例/小时 | 10,000元/月 |
视频生成模型服务 | 模型类型 | 独占实例资源规格 | 实例单价 | 实例单价 (预付费) | 悦动人像EMO-detect | 预置模型 | 轻量版 | 20元/实例/小时 | 10,000元/月 | 悦动人像EMO | 舞动人像AnimateAnyone-detect | 舞动人像AnimateAnyone |
调用统计您可以在模型观测页面查看已部署的模型的调用统计数据。 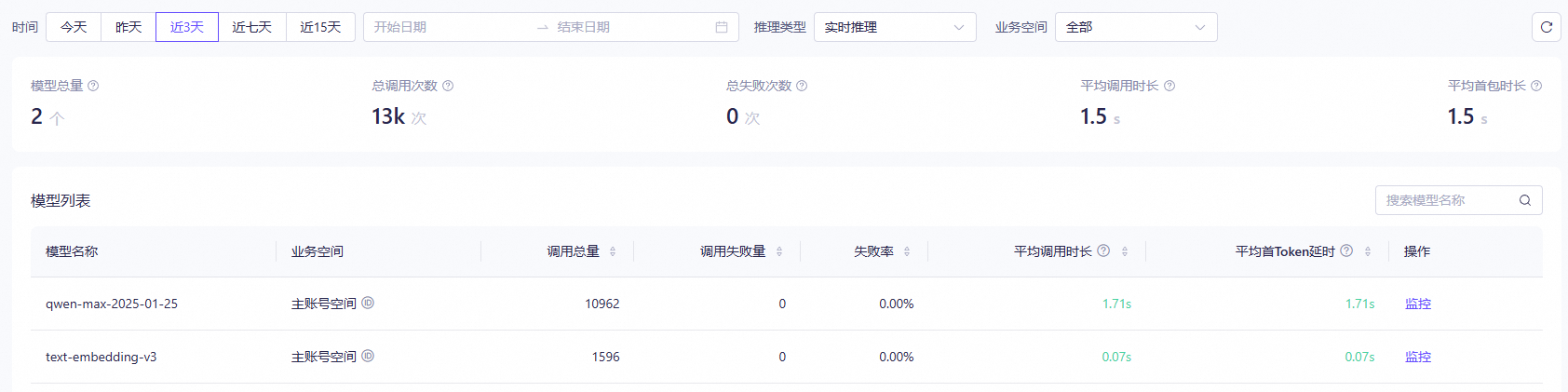
|
常见问题 | 通用如何付费/充值?使用时发生余额不足、欠费等情况请直接前往费用与成本页面充值需要的金额。 预付费方法: 如何续费?2024年3月15日之后,大模型服务平台百炼商业化升级后统一将预付费服务改成后付费服务,因此用户无需手动续费,直接使用后付费计费逻辑即可。 如何关闭计费?您可以设置高额消费预警,将预警阈值设置为一个较低值,阿里云将在产生意外扣费时通知您,避免您产生更多损失。 如何查看调用次数和消耗Token数(文本消耗量等)?您可以在模型观测页面查看某个业务空间下,某个具体模型的调用次数和消耗Token数。(暂不支持基于 API Key 粒度) 如何计算 Token 数?Token是模型用来表示自然语言文本的基本单位,可以直观地理解为“字”或“词”。 对于中文文本,1个Token通常对应一个汉字或词语。例如,“你好,我是通义千问”会被转换成['你好', ',', '我是', '通', '义', '千', '问']。 对于英文文本,1个Token通常对应3至4个字母或1个单词。例如,"Nice to meet you."会被转换成['Nice', ' to', ' meet', ' you', '.']。
不同的大模型切分Token的方法可能不同。您可以使用SDK在本地查看经过通义千问模型切分后的Token数据。 查看经过通义千问模型切分后的Token数据: # 请确保已经安装了DashScope Python SDK
from dashscope import get_tokenizer
# 获取tokenizer对象,目前只支持通义千问系列模型
tokenizer = get_tokenizer('qwen-turbo')
input_str = '通义千问具有强大的能力。'
# 将字符串切分成token并转换为token id
tokens = tokenizer.encode(input_str)
print(f"经过切分后的token id为:{tokens}。")
print(f"经过切分后共有{len(tokens)}个token")
# 将token id转化为字符串并打印出来
for i in range(len(tokens)):
print(f"token id为{tokens[i]}对应的字符串为:{tokenizer.decode(tokens[i])}")
// Copyright (c) Alibaba, Inc. and its affiliates.
// dashscope SDK版本 >= 2.13.0
import java.util.List;
import com.alibaba.dashscope.exception.NoSpecialTokenExists;
import com.alibaba.dashscope.exception.UnSupportedSpecialTokenMode;
import com.alibaba.dashscope.tokenizers.Tokenizer;
import com.alibaba.dashscope.tokenizers.TokenizerFactory;
public class Main {
public static void testEncodeOrdinary(){
Tokenizer tokenizer = TokenizerFactory.qwen();
String prompt ="如果现在要你走十万八千里路,需要多长的时间才能到达? ";
// encode string with no special tokens
List<Integer> ids = tokenizer.encodeOrdinary(prompt);
System.out.println(ids);
String decodedString = tokenizer.decode(ids);
assert decodedString == prompt;
}
public static void testEncode() throws NoSpecialTokenExists, UnSupportedSpecialTokenMode{
Tokenizer tokenizer = TokenizerFactory.qwen();
String prompt = "<|im_start|>system\nYour are a helpful assistant.<|im_end|>\n<|im_start|>user\nSanFrancisco is a<|im_end|>\n<|im_start|>assistant\n";
// encode string with special tokens <|im_start|> and <|im_end|>
List<Integer> ids = tokenizer.encode(prompt, "all");
// 24 tokens [151644, 8948, 198, 7771, 525, 264, 10950, 17847, 13, 151645, 198, 151644, 872, 198, 23729, 80328, 9464, 374, 264, 151645, 198, 151644, 77091, 198]
String decodedString = tokenizer.decode(ids);
System.out.println(ids);
assert decodedString == prompt;
}
public static void main(String[] args) {
try {
testEncodeOrdinary();
testEncode();
} catch (NoSpecialTokenExists | UnSupportedSpecialTokenMode e) {
e.printStackTrace();
}
}
}
本地运行的tokenizer可以用来估计文本的Token量,但是得到的结果不保证与模型服务端完全一致,仅供参考。如果您对通义千问的tokenizer细节感兴趣,请参考: tokenizer参考。 计费规则调用模型后免费额度为什么没有减少?免费额度数据按小时更新,高峰期可能有小时级延迟。因此,您需要在模型调用完一小时后再查看剩余额度。 超出免费额度的Token如何计费?按实际消耗的Token数计费。由于单价(输入成本或输出成本)为每千Token的价格,因此计算公式为: 费用=实际消耗的Token数/1000 × 单价。 例如,qwen-vl-max的输入成本为 0.003元/每千Token,剩余免费额度为5万Token。在某次调用时,输入Token为50400,则超出免费额度的Token费用为 400/1000 × 0.003元。 多轮对话怎么计费?在多轮对话中,历史对话的输入输出都会作为新一轮的模型输入 token 进行计费。 模型部署什么时候开始计费?当模型完成部署,即状态为运行中时,开始收取模型部署的费用。模型状态为部署中、欠费、部署失败时,均不会计费。 如果是包月预付费,模型状态为运行中后,开始消耗包月时间。 取消模型训练会收费么?会,如果您主动取消训练,之前已产生的费用仍会被计算。其他原因导致的训练中断,百炼平台不会向您收取训练费用。 大模型应用会收费吗?只创建应用不会收费。但如果调用应用进行了问答,则会根据调用的模型类型收取模型调用费用。 为什么大语言模型推理节省计划没有进行抵扣?如果免费额度没有使用完的话是不会出账产生费用,未出账的情况下也是不需要节省计划抵扣的,免费额度使用完了产生账单扣费后会通过节省计划抵扣。 欠费为什么账户有余额但仍然显示欠费?账户是否欠费的判断依据是账户可用额度。账户可用额度=(现金余额+信控额度)-(当月未结清+历史未结清)。若账户可用额度小于0,即视为欠费。 将鼠标移动到费用与成本首页的账户可用额度区域,即可查看现金余额、信控额度、当月未结清、历史未结清金额。 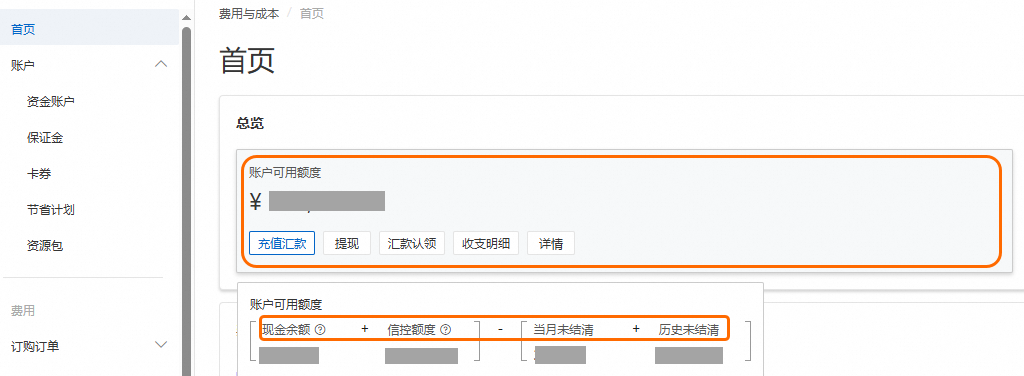
现金余额:您的账户余额。就是您充值的金额,在消费之后所剩的余额。 信控额度:您的账号申请到的信用额度。阿里云可以授权给指定客户信用额度,在信控额度范围内,客户可以先赊销使用云产品,再按账期对消费产生的账单进行还款。 阿里云直客账户,且开启了信控才会展示信控额度。如您需要信控额度,请联系您的客户经理进行申请。 当月未结清金额:当月截止目前已消费但未结清的金额。 历史未结清金额:在之前月份里累积到至今仍未支付的所有账单费用汇总(不包含当前月)。 如果开启了自动销账功能,系统会自动依据账单的生成时间,以账户的资产(包括储值卡、代金券、信控退款、现金余额)自动核销账单,可能不会显示未结清金额。
欠费有什么影响?如果账户欠费,即使有免费额度、资源包等,也无法进行模型调用。您可以前往充值汇款页面进行充值。 百炼API调用报错:如何快速处理服务未开通或账户欠费问题?1. 服务未开通 使用阿里云主账号前往百炼控制台,如果页面顶部显示以下消息,您需要开通百炼的模型服务,以获得免费额度。如果未显示该消息,则表示您已经开通。 
2. 账户余额不足 余额核查:登录费用与成本页面,确认余额是否充足。 充值操作:点击充值按钮,输入所需金额并完成支付。
3. 设置消费预警(防止重复报错) 账单进行模型推理、模型调优及模型部署后,为什么在账单详情页面查不到相关账单? 如何查看百炼所有服务的费用支出?在成本分析页面,成本类型选择应付金额,时间粒度选择月,选择时间范围(假设为2024年12月),产品选择大模型服务平台百炼,即可查看所选时间范围内百炼的成本支出。 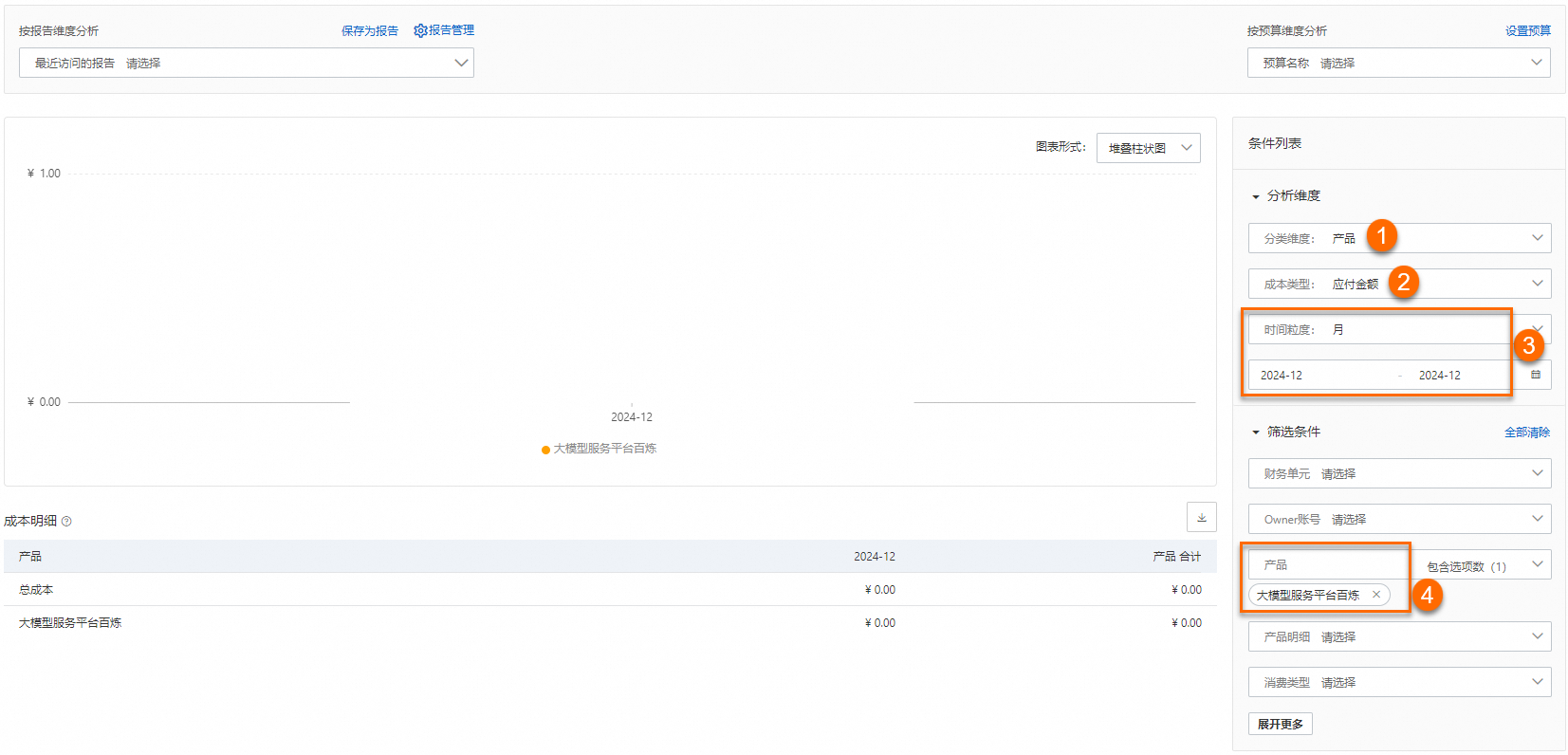
如何查看百炼的模型推理服务的费用支出?在成本分析页面,成本类型选择应付金额,时间粒度选择月,选择时间范围(假设为2024年07月~12月),产品明细选择百炼大模型推理,即可查看所选时间范围内模型推理总花费。 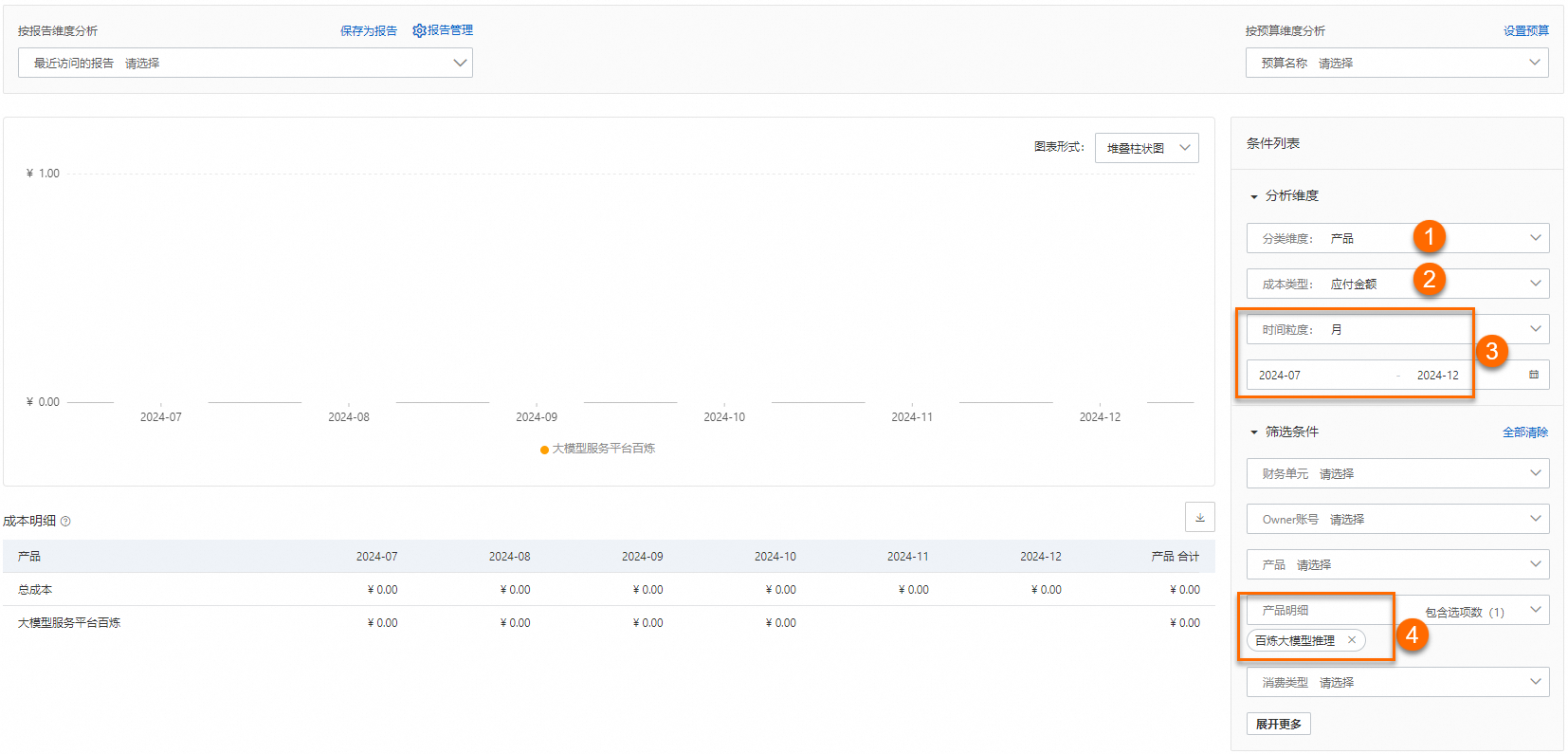
如何查看百炼的具体模型的推理费用支出?以模型 qwen-max 为例。在账单详情页面,选择账单月份,再选择商品名称为百炼大模型推理,单击搜索。 在资产/资源实例ID列找到所有与qwen-max相关的实例。将这些实例对应的应付金额相加,即可得出所选账期内调用qwen-max模型进行模型推理所支付的费用。 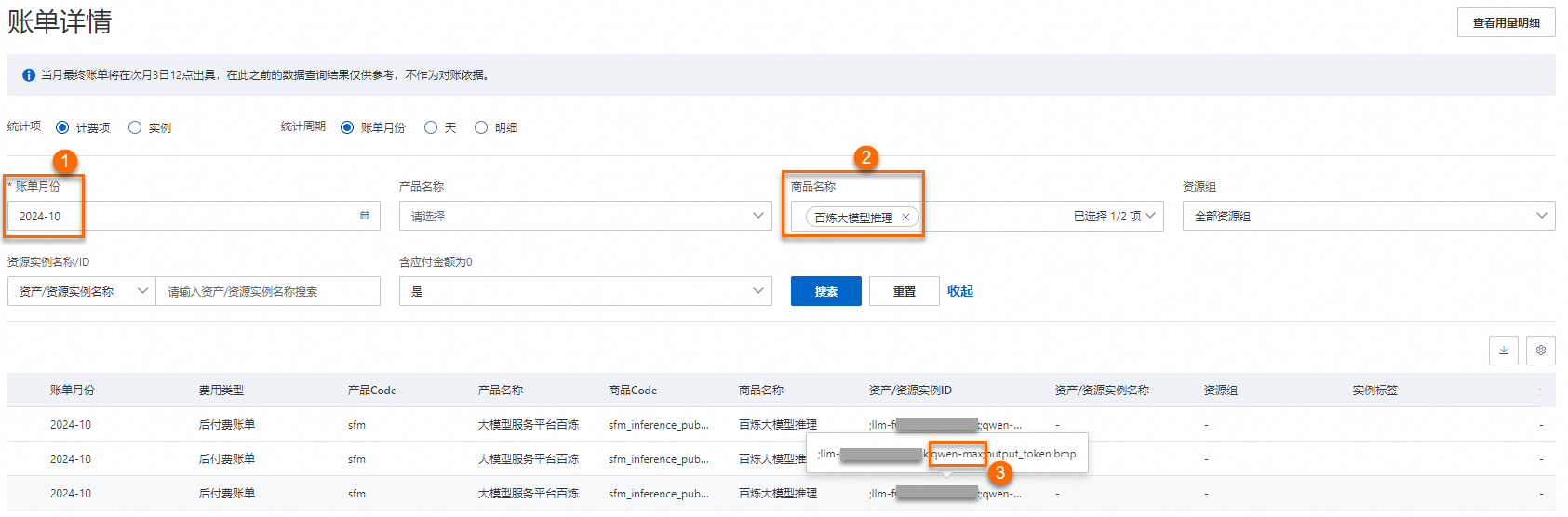
如何在明细账单中导出和查看消耗Token数?在账单详情页面费用中心账单明细账单页签中,统计项选择计费项进行导出,可在账单中查看到Token用量。 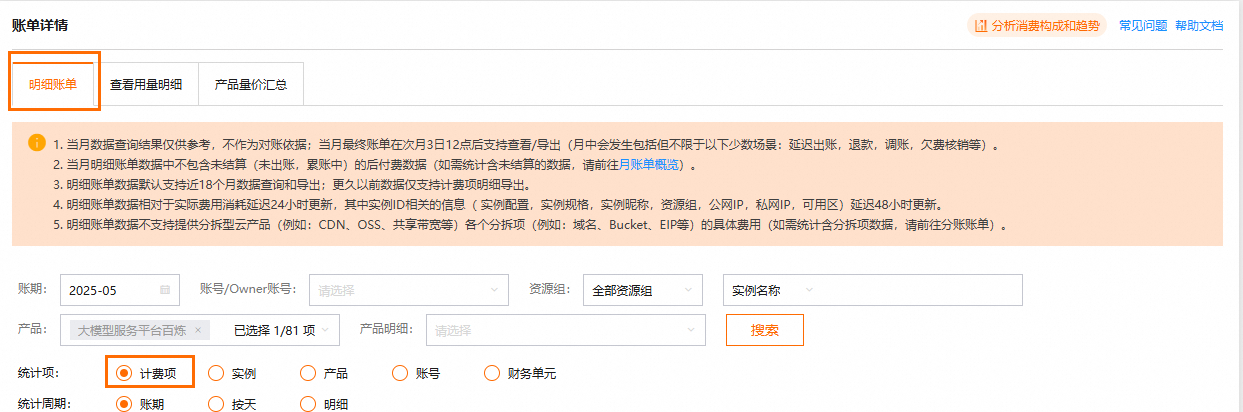
如何对业务空间添加实例标签以便后续分账?针对阿里云百炼账号下的不同业务空间打标,实现更加灵活地分账操作。具体步骤为: 在业务空间管理确定标签绑定的业务空间Workspace ID(示例:llm-xxx),并在账单详情确定业务空间的地域信息。 

在标签管理页面选择资源绑定标签。 
资源选择方式选择"输入多个资源ID",在产品选项卡搜索并选择"大模型服务平台百炼:业务空间"并选择业务空间对应地域,资源ID输入框中填写Workspace ID,完成后点击绑定标签按钮执行操作。 
在绑定标签页面中创建标签键值或使用已创建的预置标签与业务空间绑定,当完成键值输入或选择好预置标签后点击确定即可完成业务空间标签的绑定。 

至此您已完成对阿里云百炼业务空间的标签绑定,您可在账单详情页面通过实例标签列验证与查询业务空间的绑定标签。 
如何对大模型相关明细账单进行账单核对?自2024年9月7日以后产生的大模型推理、部署与训练账单,可通过ApiKeyID、业务空间ID、模型名称、输入/输出类型、调用渠道、实例标签进行账单核对。 在账单详情页面,选择账单月份,再选择产品名称为大模型服务平台百炼,单击搜索。将搜索结果下载到本地,按照资产/资源实例ID列的内容进行账单核对。 完整的资产/资源实例ID,例如12xxx;llm-xxx;qwen-max;output_token;app,依次表示ApiKeyID;业务空间ID;模型名称;输入/输出类型;调用渠道。如果您的资产/资源实例ID中没有包含ApiKeyID,则表示该收费项是通过控制台调用产生的。 完整的实例标签,例如key:test value:test,依次表示标签键(key)标签值(value)。当某实例标签数为两个或以上时,标签键值信息将依次排列并以分号划分,例如key:test1 value:test1; key:test2 value:test2。 前往百炼API Key管理页面,根据 ApiKeyID 确认对应的 API-Key,以完成基于 API-Key 的账单核对操作。 调用渠道包括app、bmp及assistant-api。app表示通过应用调用模型,bmp表示通过控制台模型体验调用模型。assistant-api表示通过Assistant API调用模型。 
按量后付费账单如何结算?阿里云按量后付费云资源账单结算方式不是实时扣费,而是先从账户可用额度中冻结截止目前已消费但未结清的金额。在次月初,月最终账单完成出账后,才实际扣除上个月的账单费用。 成本控制如何限制模型调用量?希望免费额度用完后不扣费 为避免额外消费,阿里云百炼提供免费额度用完即停功能。 希望限制单位时间内的模型调用量或Token消耗量 为子业务空间设置限流。前往业务空间管理页面,找到目标子业务空间,点击模型权限流控设置,调整各模型的请求数限流和Token限流。 希望对消耗Token数量做告警 为模型开销设置告警规则,详情可参考用量与性能观测。 模型告警仅触发告警通知,不会终止模型调用。
抵扣券/优惠券如果有抵扣券或者优惠券,产生的费用如何扣费?阿里云扣费顺序请前往账单常见问题中查询“按量付费商品账单的扣款顺序”或“包年包月订单的扣款顺序”。 云工开物学生专属300元优惠券可以抵扣哪些模型的费用?优惠券的适用范围可在学生用券中心页面的模型服务页签下查看。具体请以下单购买时抵扣情况为准。 
|
| |