表格存储(Tablestore)面向海量结构化数据提供Serverless表存储服务,同时针对物联网场景深度优化提供一站式的IoTstore解决方案。适用于海量账单、IM消息、物联网、车联网、风控、推荐等场景中的结构化数据存储,提供海量数据低成本存储、毫秒级的在线数据查询和检索以及灵活的数据分析能力。
前置概念
阅读本文前,您可能需要了解如下概念:
基本概念
在使用表格存储前,您需要了解以下基本概念。
术语 | 说明 |
地域 | 地域(Region)物理的数据中心,表格存储服务会部署在多个阿里云地域中,您可以根据自身的业务需求选择不同地域的表格存储服务。更多信息,请参见表格存储已经开通的Region。 |
读写吞吐量 | 读吞吐量和写吞吐量的单位为读服务能力单元和写服务能力单元,服务能力单元(Capacity Unit,简称CU)是数据读写操作的最小计费单位。更多信息,请参见读写吞吐量。 |
实例 | 实例(Instance)是使用和管理表格存储服务的实体,每个实例相当于一个数据库。表格存储对应用程序的访问控制和资源计量都在实例级别完成。更多信息,请参见实例。 |
服务地址 | 每个实例对应一个服务地址(EndPoint),应用程序在进行表和数据操作时需要指定服务地址。更多信息,请参见服务地址。 |
数据生命周期 | 数据生命周期(Time To Live,简称TTL)是数据表的一个属性,即数据的存活时间,单位为秒。表格存储会在后台对超过存活时间的数据进行清理,以减少您的数据存储空间,降低存储成本。更多信息,请参见数据版本和生命周期。 |
数据存储模型
表格存储提供了宽表(WideColumn)模型、时序(TimeSeries)模型和消息(Timeline)模型三种数据存储模型,请根据使用场景选择合适的模型。不同数据存储模型支持的功能特性请参见功能特性。
模型 | 描述 |
宽表模型 | 类Bigtable/HBase模型,可应用于元数据、大数据等多种场景,支持数据版本、生命周期、主键列自增、条件更新、局部事务、原子计数器、过滤器等功能。更多信息,请参见宽表模型。 |
时序模型 | 针对时间序列数据的特点进行设计的模型,可应用于物联网设备监控、设备采集数据、机器监控数据等场景,支持自动构建时序元数据索引、丰富的时序查询能力等功能。更多信息,请参见时序模型。 |
消息模型 | 针对消息数据场景设计的模型,可应用于IM、Feed流等消息场景。能满足消息场景对消息保序、海量消息存储、实时同步的需求,同时支持全文检索与多维度组合查询。更多信息,请参见消息模型。 |
产品计费
表格存储支持预留模式(预付费)和按量模式(后付费)两种计费模式,详细说明请参见下表。
计费模式 | 描述 |
VCU模式(原预留模式) | 按照资源评估结果预先购买预留VCU或开启弹性能力后按实际使用量支付计算性能消耗费用。您可以叠加使用预留VCU和弹性能力来节约成本。
此模式能为用户节省更多的计算资源支付费用。同时此模式也通过配置弹性能力上限或关闭弹性能力保障整体使用资源可控,避免异常流量导致的额外费用,是对于成本可控场景的更优选择。 说明 关于评估选型的更多信息,请参见资源预估选型。 计费项包括计算能力、数据存储量和外网下行流量,其中数据存储量包括高性能存储、容量型存储和多元索引存储。更多信息,请参见VCU模式(原预留模式)。 |
CU模式(原按量模式) | 根据业务的实时读写吞吐量、存储空间等资源计费,无需提前规划硬件资源消耗。 此模式适用于业务峰谷变化较大,不可预测的场景。CU模式(原按量模式)提供的弹性能力能够保障应用系统应对突发流量,是对于业务稳定场景的更优选择。 重要 CU模式(原按量模式)下当前无法控制整体资源的使用上限,需要业务层来自行管控避免异常流量与使用导致的表格存储资源开销。 计费项包括读吞吐量、写吞吐量、数据存储量和外网下行流量。更多信息,请参见CU模式(原按量模式)。 |
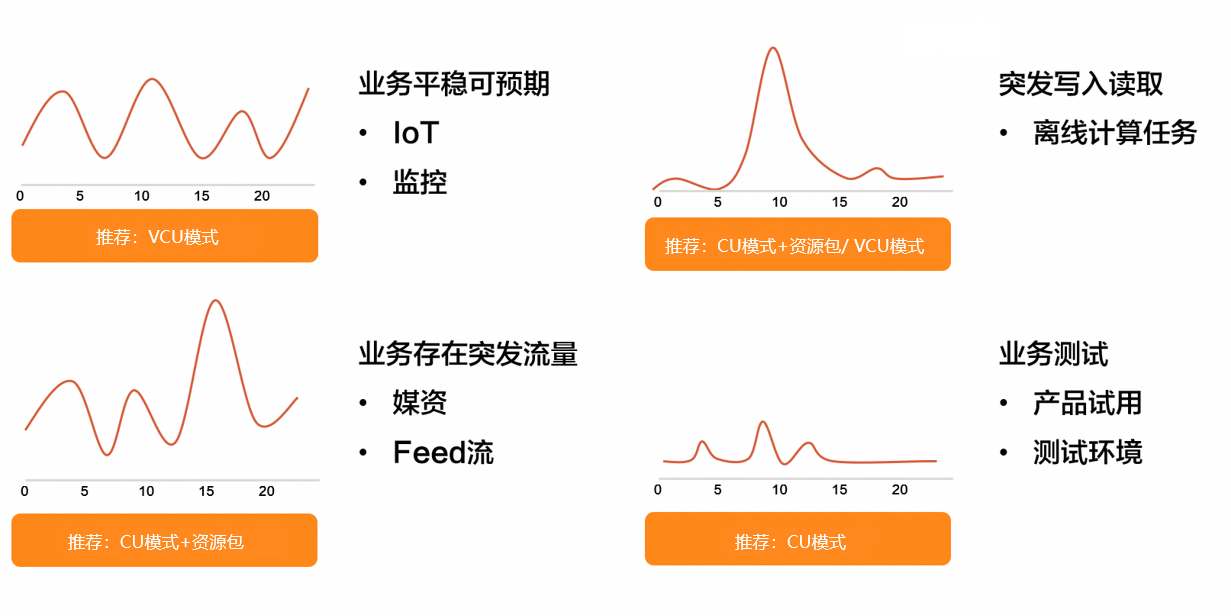
根据实际业务场景选择相应的推荐方案。
业务场景 | 描述 | 推荐方案 | 相关文档 |
业务平稳可预期 | 业务场景中无剧烈的波峰波谷,同时不会出现意外的突增流量,例如监控、IoT场景等。 | VCU模式(原预留模式) | |
业务存在突发流量 | 业务场景中存在不可预测的突发峰值,例如媒资、新闻等。 |
|
|
批量离线任务 | 每天存在定时低频但海量的数据离线读写。 | CU模式(原按量模式)和资源包 | |
业务测试 | 前期测试产品搭建测试环境。 | CU模式(原按量模式) |
使用方式
您可以通过如下方式使用表格存储产品。
使用方式 | 描述 |
控制台 | 阿里云提供的Web服务页面,方便您便捷地操作表格存储。更多信息,请参见表格存储控制台。 |
SDK | 支持主流开发语言Java、Go、Python、Node.js、.Net和PHP。更多信息,请参见SDK概览。 |
命令行工具 | 支持通过简单的命令操作表格存储。更多信息,请参见命令行工具。 |
快速入门
通过控制台或者命令行工具,您可以快速体验宽表模型中数据表或者时序模型中时序表的操作。更多信息,请参见快速入门。
计算与分析
表格存储支持通过MaxCompute、Spark、Hive或者HadoopMR、函数计算、Flink以及表格存储SQL查询进行计算与分析,请根据实际场景选择相应分析工具。
分析工具 | 适用模型 | 操作 | 描述 |
MaxCompute | 宽表模型 | 通过MaxCompute客户端为表格存储的数据表创建外部表,即可访问表格存储中的数据。 | |
Spark | 宽表模型 | 使用Spark计算引擎时,支持通过E-MapReduce SQL或者DataFrame编程方式访问表格存储。 | |
Hive或者HadoopMR | 宽表模型 | 使用Hive或者HadoopMR访问表格存储中的数据。 | |
函数计算 | 宽表模型 | 通过函数计算访问表格存储,对表格存储增量数据进行实时计算。 | |
Flink |
| 通过实时计算Flink访问表格存储中的源表、维表或者结果表,实现大数据实时计算与分析。 | |
PrestoDB | 宽表模型 | 使用PrestoDB对接Tablestore后,基于PrestoDB on Tablestore您可以使用SQL查询与分析Tablestore中的数据、写入数据到Tablestore以及导入数据到Tablestore。 | |
表格存储多元索引 | 宽表模型 | 多元索引基于倒排索引和列式存储,可以解决大数据的多维查询和统计分析难题。当日常业务中有非主键列查询、多列组合查询、模糊查询等多维查询需求,以及求最值、统计行数、数据分组等数据分析需求时,您可以将这些属性作为多元索引中的字段,并使用多元索引查询与分析数据。 | |
表格存储SQL查询 |
| SQL查询为多数据引擎提供统一的访问接口。通过SQL查询功能,您可以对表格存储中数据进行复杂的查询和高效的分析。 |
迁移同步
您可以将异构数据平滑迁移同步到表格存储,还可以将表格存储数据同步到对象存储OSS(Object Storage Service)等服务中。
分类 | 数据同步 | 描述 |
数据导入 | 使用DataX、DTS、Canal工具或者Tapdata Cloud将MySQL数据库中的数据同步迁移到表格存储中。 | |
基于Tablestore Sink Connector将Apache Kafka中的数据批量导入到表格存储的数据表或者时序表中。 | ||
通过Tapdata Cloud的可视化界面,您可以将Oracle数据实时同步到表格存储中。 | ||
使用DataX将HBase数据库中的全量数据同步到表格存储中。 | ||
使用DataWorks将MaxCompute中的全量数据同步到表格存储中。 | ||
使用通道服务、DataWorks或者DataX将表格存储数据表中数据同步到另一个数据表中。 | ||
使用DataWorks工具将表格存储时序表中的全量数据或者增量数据同步到另一个时序表。 | ||
数据导出 | 使用DataWorks将表格存储中的全量数据或者增量数据导出到MaxCompute。 | |
使用DataWorks将表格存储中的全量数据或者增量数据导出到OSS。 | ||
使用命令行工具或者DataX工具直接下载数据到本地文件。您也可以使用DataWorks工具将数据同步到OSS后再在OSS侧下载数据到本地文件。 |
更多功能
如果要控制用户的访问权限,您可以使用访问控制RAM自定义权限实现。更多信息,请参见通过RAM Policy为RAM用户授权。
您还可以通过资源目录的管控策略、表格存储Network ACL、表格存储实例策略进一步限制用户的访问权限。更多信息,请参见授权管理。
如果要保证数据存储安全和网络访问安全,您可以使用数据表加密、VPC网络访问等方式实现。更多信息,请参见数据加密和网络安全管理。
如果要防止重要数据被误删除,您可以使用数据备份功能实现定期备份重要数据。更多信息,请参见备份Tablestore数据。
如果要为监控指标配置报警通知,您可以使用云监控实现。更多信息,请参见数据监控与报警。
如果要以图表等形式可视化展示数据,您可以使用DataV或者Grafana实现。更多信息,请参见数据可视化。
常见问题
技术支持
表格存储为您提供专业的免费的技术咨询服务,欢迎通过钉钉加入相应交流群。
为互联网应用、大数据、社交应用等开发者提供的最新技术交流群有36165029092(
表格存储技术交流群-3)。说明表格存储用户群11789671(
表格存储技术交流群)和23307953(表格存储技术交流群-2)已满,暂时无法加入。为物联网和时序模型开发者提供的技术交流群有44327024(
物联网存储 IoTstore 开发者交流群)。