
PrestoDB是基于MPP架构的开源大数据分布式SQL查询引擎,支持对接MySQL、Elasticsearch、Tablestore等多种数据源。使用PrestoDB对接表格存储Tablestore后,基于PrestoDB on Tablestore您可以使用SQL查询与分析Tablestore中的数据、写入数据到Tablestore以及导入数据到Tablestore。
背景信息
PrestoDB是基于MPP架构的开源大数据分布式SQL查询引擎,支持对接MySQL、Elasticsearch、Tablestore等多种数据源。PrestoDB可以作为查询工具、数据ETL工具、压力器和统一查询引擎来满足不同场景的数据处理需求。
PrestoDB作为日常开发和调查问题时的查询工具,支持通过SQL查询或分析表中数据。
PrestoDB作为数据ETL工具,支持实现跨表或跨实例的数据复制以及异构数据源的数据拷贝。
PrestoDB作为压力器,支持批量扫描或者批量写入数据。
PrestoDB作为数据中台内的统一查询引擎,支持对接多种异构数据源。
通过PrestoDB使用Tablestore前,您需要使用PrestoDB对接Tablestore。对接完成后,基于PrestoDB on Tablestore您可以使用SQL查询与分析Tablestore中的数据、写入数据到Tablestore以及导入数据到Tablestore。
前提条件
已准备带有Linux系统或者macOS系统的服务器并完成如下软件的安装,本文以Linux系统为例介绍。
说明如果当前没有带有Linux系统的服务器,推荐您使用云服务器ECS部署Linux系统后再进行操作。更多信息,请参见通过控制台使用ECS实例(快捷版)。
已完成Java 8(64-bit)和Python3开发环境的安装。
已完成PrestoDB安装。
请根据所用PrestoDB版本下载相应的prestodb-tablestore-connector文件并将文件上传到PrestoDB安装目录下的
plugin目录中,然后解压文件。prestodb-tablestore-connector插件版本与PrestoDB版本的配套关系请参见下表。
插件版本
PrestoDB版本
说明
0.280
首个版本发布。本插件适用于PrestoDB 0.280及之后版本。
已获取PrestoDB要对接的Tablestore相关信息,例如访问账号、实例信息、表信息等。
已为具有Tablestore操作权限的RAM用户创建AccessKey。具体操作,请参见获取AccessKey。
说明如果未为RAM用户授予操作Tablestore的权限,请完成授权后再进行操作。具体操作,请参见通过RAM Policy为RAM用户授权。
注意事项
只适用于宽表模型。
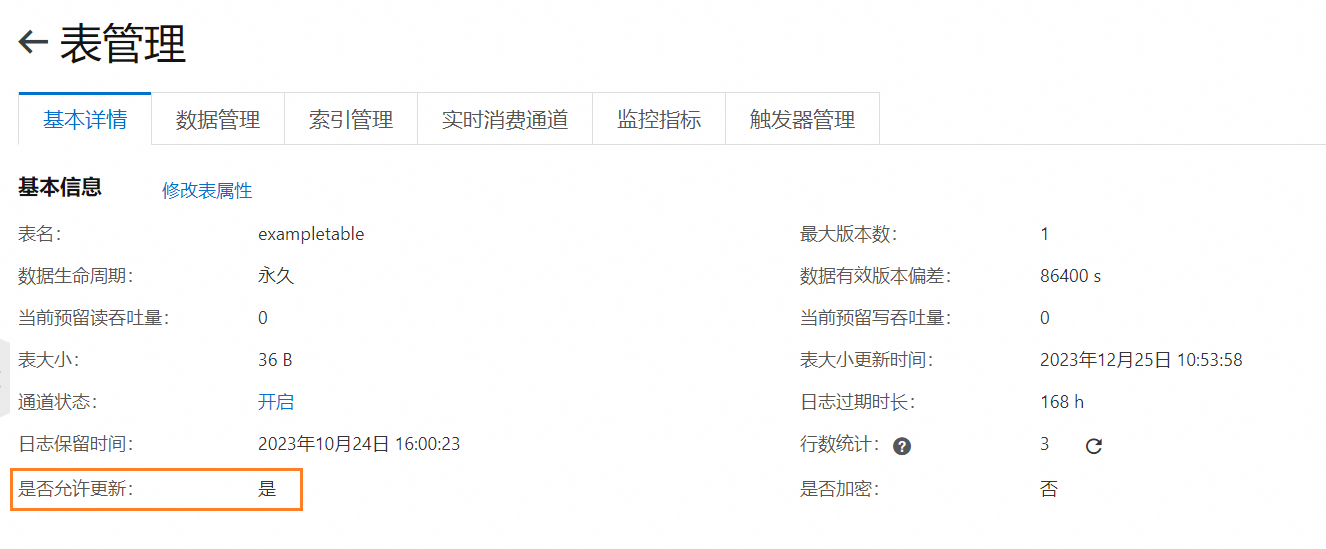
当前PrestoDB的写入模式默认为UpdateRow,暂时不提供PutRow的写入模式。如果需要通过PrestoDB写入数据到Tablestore,请务必确保Tablestore数据表的是否允许更新配置为是,否则数据无法写入。
重要由于使用了多元索引数据生命周期(即取值不为-1)时,您必须配置Tablestore数据表的是否允许更新配置为否,因此如果某个表使用了多元索引数据生命周期,则无法通过PrestoDB写入数据到该表。
如果实际场景中有使用PutRow的写入模式需求,请通过钉钉搜索36165029092(
表格存储技术交流群-3)加入联系我们。
您可以通过控制台在数据表的基本详情页签查看是否允许更新的配置或者通过SDK调用DescribeTable接口查询。
字段类型映射
表格存储与PrestoDB都有其自身的类型,两者之间的字段类型对应关系请参见下表。
Tablestore的字段类型 | PrestoDB的字段类型 |
string | varchar |
integer | bigint |
double | double |
boolean | boolean |
binary | varbinary |
使用流程
通过PrestoDB使用Tablestore的主要步骤包括使用PrestoDB对接Tablestore、运行PrestoDB的SQL CLI、创建Schema和映射表以及使用SQL操作数据。
步骤一:使用PrestoDB对接Tablestore
安装PrestoDB后,您需要进行PrestoDB的Catalog配置和Schema配置来完成PrestoDB和Tablestore的对接,其中Catalog配置文件的存放路径为etc/catalog/tablestore.properties。
配置说明
操作步骤
在Catalog配置文件中指定Schema的配置模式并完成相应参数配置。此处以Meta表动态配置方式为例介绍对接配置操作。
进入PrestoDB安装目录,然后在PrestoDB安装目录下的
etc/catalog/路径中创建tablestore.properties文件。重要请确保已具有文件的可执行权限后再进行编辑操作。
Catalog配置文件所处的目录如下图所示。
编辑
tablestore.properties文件并根据实际修改配置示例后拷贝到文件中。使用Meta表动态配置方式时,请配置
tablestore.schema-mode为meta-table。说明如果要使用本地静态文件配置方式进行Schema配置,请配置
tablestore.schema-mode为file并配置tablestore.schema-file为本地静态文件完整路径,然后在静态文件中配置Schema信息。更多信息,请参见Server配置。connector.name=tablestore tablestore.schema-mode=meta-table #tablestore.schema-mode=file tablestore.schema-file=/users/test/tablestore/presto/tablestore.schema tablestore.meta-instance=metastoreinstance tablestore.endpoint=http://metastoreinstance.cn-hangzhou,ots.aliyuncs.com/ tablestore.accessid=**************** tablestore.accesskey=************************** tablestore.meta-table=meta_table tablestore.auto-create-meta-table=true具体配置项说明请参见下表。
配置项
示例
是否必选
说明
connector.name
tablestore
是
连接器名称。此项必须配置tablestore。
tablestore.schema-mode
meta-table
是
Schema模式配置。此处配置为
meta-table。tablestore.meta-instance
metastoreinstance
是
Tablestore中用于存储元数据的实例,请根据实际修改。更多信息,请参见实例。
重要请确保配置的实例已在阿里云账号中存在。
tablestore.endpoint
http://metastoreinstance.cn-hangzhou,ots.aliyuncs.com/
是
Tablestore中用于存储元数据的实例的访问地址,请修改实际修改。更多信息,请参见服务地址。
tablestore.accessid
****************
是
具有存储元数据的实例访问权限的用户AccessKey ID和AccessKey Secret。
tablestore.accesskey
**************************
tablestore.meta-table
meta_table
是
Tablestore中用于存储元数据的表名,请根据实际修改。
tablestore.auto-create-meta-table
true
否
是否需要自动创建元数据表。默认值为true,表示创建Schema时会自动创建元数据表。
保存配置文件并退出。
说明您可以执行cat命令确认配置是否保存成功。
步骤二:运行Presto的SQL CLI
对接完成后,您可以启动Presto Server并运行SQL。
获取client可执行程序。
下载PrestoDB客户端。
此处以presto-cli-0.280-executable.jar为例介绍。
将PrestoDB客户端保存到PrestoDB安装目录下的
bin目录中。在PrestoDB安装目录下的
bin目录中执行如下命令获取client可执行程序。# 将PrestoDB客户端文件重命名为presto。其中presto-cli-0.280-executable.jar请替换为实际所用的客户端版本名称。 mv presto-cli-0.280-executable.jar presto # 为用户授予操作presto文件的权限。 chmod +x prestoclient可执行程序的所处目录如下图所示。
在PrestoDB安装目录下的
bin目录中执行命令启动Presto Server。重要启动Presto Server时,您必须分别启动Coordinator和至少一个Worker。
# 支持前台运行和后台运行两种启动方式,其中前台运行方式更方便查看运行日志。 # 方式一:后台运行 ./launcher start # 方式二:前台运行 ./launcher run在PrestoDB安装目录下的
bin目录中执行如下命令启动SQL CLI。说明PrestoDB默认运行在8080端口。如果要修改端口配置,请修改
etc/config.properties中的http-server.http.port配置。修改部分config配置后需要重启服务器使配置生效。
命令中的
./presto为client可执行程序在PrestoDB安装目录下的bin目录中的相对路径。
./presto --server localhost:8080 --catalog tablestore --schema default配置项说明请参见下表。
配置项
示例
是否必选
说明
--server
localhost:8080
是
Presto Server的URI,请根据实际替换。此项的配置必须与PrestoDB安装目录下
etc/config.properties文件中的discovery.uri参数的配置相同。--catalog
tablestore
是
Catalog配置文件的名称,此处配置为tablestore,与创建的Catalog配置文件名称相同。
--schema
default
是
Schema配置,保持default配置即可。
步骤三:创建Schema和映射表
使用Meta表动态配置的Schema配置模式时,您需要手动创建并使用Schema用于配置对接的Tablestore实例和进行用户鉴权,然后再创建Tablestore表的映射表用于数据查询和分析。
如果使用的是本地静态文件配置的Schema配置模式,则无需执行此步骤。
执行如下命令创建Schema。
创建一个访问Tablestore myinstance实例的Schema,Schema名称为testdb。
CREATE SCHEMA tablestore.testdb WITH ( endpoint = 'https://myinstance.cn-hangzhou.ots.aliyuncs.com', instance_name = 'myinstance', access_id = '************************', access_key = '********************************' );具体参数配置说明请参见下表。
参数
示例
是否必选
说明
endpoint
https://myinstance.cn-hangzhou.ots.aliyuncs.com
是
Tablestore实例的访问地址。更多信息,请参见服务地址。
instance_name
myinstance
是
Tablestore实例名称。更多信息,请参见实例。
access_id
************************
是
阿里云账号或者RAM用户的AccessKey ID。
access_key
********************************
是
阿里云账号或者RAM用户的AccessKey Secret。
执行
use <SCHEMA_NAME>;命令使用创建的Schema。其中
<SCHEMA_NAME>请替换为实际创建的Schema名称。您可以执行show schemas;命令获取Schema列表。执行如下命令Tablestore数据表的映射表。
重要创建映射表时,请注意如下事项:
请确保映射表中的字段类型和表格Tablestore数据表中的字段类型相匹配更多信息,请参见字段类型映射。
映射表名称必须与Tablestore中实际的表名称相同。
SQL语句CREATE TABLE中的table_name用于映射到Tablestore中实际的表。您可以为Tablestore中的同一个数据表创建多个不同的映射表。
映射表中必须包括数据表的所有主键列,但是支持只包括部分属性列。
映射表中主键列的名称和顺序必须与Tablestore数据表中主键列的名称和顺序保持一致。映射表中每一个属性列可通过指定 origin_name参数来映射到Tablestore中实际表内的列名。
假设数据表名为main_table,包括gid和uid两个主键列以及col1、col2和col3三个属性列。
以下SQL示例用于为Tablestore数据表main_table创建一个同名映射表。
CREATE TABLE if not exists main_table ( gid bigint, uid bigint, c1 boolean with (origin_name = 'col1'), c2 bigint with (origin_name = 'col2'), c3 varchar with (origin_name = 'col3') ) WITH ( table_name = 'main_table' );
步骤四:使用SQL操作数据
使用SQL操作Tablestore数据前,请确保已使用use <SCHEMA_NAME>;命令使用所需Schema。
使用SQL语句查询Schema配置、表的元数据以及读写Tablestore表中数据。更多SQL示例,请参见常用SQL示例。
查询Schema配置。
获取Schema列表
show schemas;获取指定Schema中表列表
show tables;
查看指定表的元数据
其中
<TABLE_NAME>请替换为实际的表名称。describe <TABLE_NAME>;数据操作。
读写Tablestore数据。
写入数据
插入一行数据
以下示例用于在main_table中插入一行数据。
insert into main_table values(10001,10001,true,100,'hangzhou');批量导入数据
重要批量导入数据前,请确保已创建目标表,且目标表的表结构与源数据表的表结构保持一致。
以下示例用于将main_table表中gid大于0且uid小于10000的gid、uid、c1、c2和c3列数据批量导入到sampletable表中。
insert into sampletable select gid, uid, c1, c2, c3 from main_table where gid > 0 and uid < 100000;
读取数据
以下示例用于查询sampletable表中gid列值大于0,uid列值小于10且c1等于true的行数据。
select * from sampletable where gid > 0 and uid < 10 and c1 = true;
计费说明
表格存储支持VCU模式(原预留模式)和CU模式(原按量模式)两种计费模式,请根据所用的实例模型参考相应计费模式了解计费信息。更多信息,请参见计费概述。
VCU模式(原预留模式):计费项包括计算能力、数据存储量和外网下行流量,其中数据存储量包括高性能存储、容量型存储和多元索引存储。
使用计算引擎访问表格存储时会消耗计算资源。存储元数据的表占用的数据存储量与创建实例时的存储规格相关。
CU模式(原按量模式):计费项包括读吞吐量、写吞吐量、数据存储量和外网下行流量。
使用计算引擎访问表格存储时,表格存储会根据具体的读写请求按照读写吞吐量计量计费。存储元数据的表占用的数据存储量与创建实例时的存储规格相关。
相关文档
您可以使用MaxCompute、Spark、函数计算、Flink等其他计算引擎查询与分析Tablestore表中数据。更多信息,请参见计算与分析概述。您也可以使用表格存储的SQL查询和多元索引统计聚合功能查询与分析表中数据。更多信息,请参见SQL查询介绍和多元索引介绍。
您也可以通过DataWorks集成服务、DataX等其他工具将其他数据源的数据迁移到表格存储中。更多信息,请参见迁移工具。
如果要以图表等形式可视化展示数据,您可以使用DataV或者Grafana实现。更多信息,请参见数据可视化工具。
结合计算引擎和表格存储您可以实现表格存储结合Spark流批处理实现一体化存储和计算、表格存储结合实时计算Flink进行大数据分析等解决方案。