当MaxCompute提供的内建函数无法支撑您的业务实现时, 您可以根据本文提供的开发流程,使用开发工具(例如IntelliJ IDEA(Maven)或MaxCompute Studio)自行编写代码逻辑创建自定义函数(UDF),并在MaxCompute中进行调用,以满足多样化业务需求。本文为您介绍如何通过Java语言编写UDF。
使用限制
访问外网
MaxCompute默认不支持通过自定义函数访问外网。如果您需要通过自定义函数访问外网,请根据业务情况填写并提交网络连接申请表单,MaxCompute技术支持团队会及时联系您完成网络开通操作。表单填写指导,请参见网络开通流程。
访问VPC网络
MaxCompute默认不支持通过UDF访问VPC网络。如果您的UDF涉及访问VPC网络中的资源时,需要先创建MaxCompute与目标VPC网络间的网络连接,才可以直接通过UDF访问VPC网络中的资源,操作详情请参见通过UDF访问VPC网络资源。
读取表数据
目前版本不支持使用UDF/UDAF/UDTF读取以下场景的表数据:
做过表结构修改(Schema Evolution)的表数据。
包含复杂数据类型的表数据。
包含JSON数据类型的表数据。
Transactional表的表数据。
注意事项
在编写Java UDF前,您需要先了解UDF代码结构,以及Java UDF使用的数据类型与MaxCompute支持的数据类型间的映射关系,二者之间的映射关系请参见附录:数据类型。
在编写Java UDF时,您需要注意:
不同UDF JAR包中不建议存在类名相同但实现逻辑不一样的类。例如UDF1、UDF2分别对应资源JAR包udf1.jar、udf2.jar,两个JAR包里都包含名称为
com.aliyun.UserFunction.class的类但实现逻辑不一样,当同一条SQL语句中同时调用UDF1和UDF2时,MaxCompute会随机加载其中一个类,此时会导致UDF执行结果不符合预期甚至编译失败。Java UDF中输入或返回值的数据类型是对象,数据类型首字母必须大写,例如String。
SQL中的NULL值通过Java中的NULL表示。Java Primitive Type无法表示SQL中的NULL值,不允许使用。
UDF开发流程
开发UDF时通常需进行准备工作、编写UDF代码、上传并注册UDF、调试UDF这几个步骤。同时MaxCompute支持多种工具,以下以常见的MaxCompute Studio、DataWorks、odpscmd三种工具为例,以一个具体的示例为您介绍UDF开发的通用流程。
使用MaxCompute Studio
以下以开发一个字符小写转换功能的UDF为例,为您介绍使用MaxCompute Studio开发并调用Java UDF的操作步骤如下。
准备工作。
使用MaxCompute Studio开发调试UDF时,您需要先安装MaxCompute Studio并连接MaxCompute项目,做好UDF开发前准备工作。操作详情请参见:
编写UDF代码。
在Project区域,右键单击Module的源码目录(即),选择。
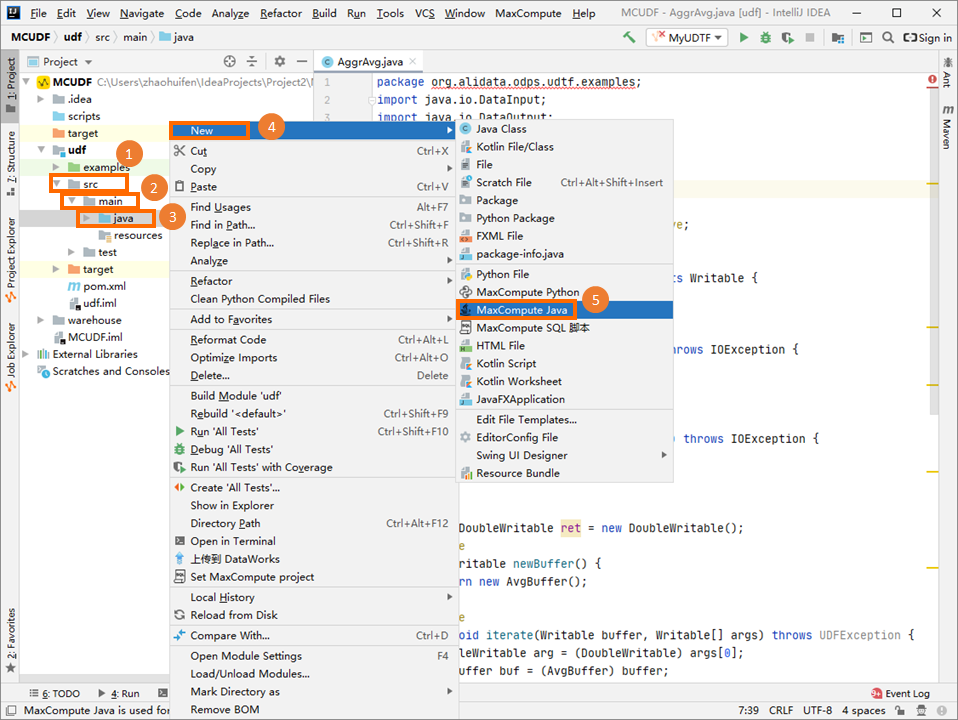
在Create new MaxCompute java class对话框,单击UDF并填写Name后,按Enter键。
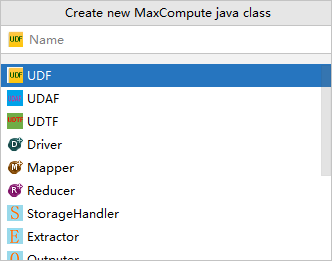
Name为创建的MaxCompute Java Class名称。如果还没有创建Package,在此处填写packagename.classname,会自动生成Package。本示例创建的Java Class名称为Lower。
在代码编写区域开始开发UDF代码。
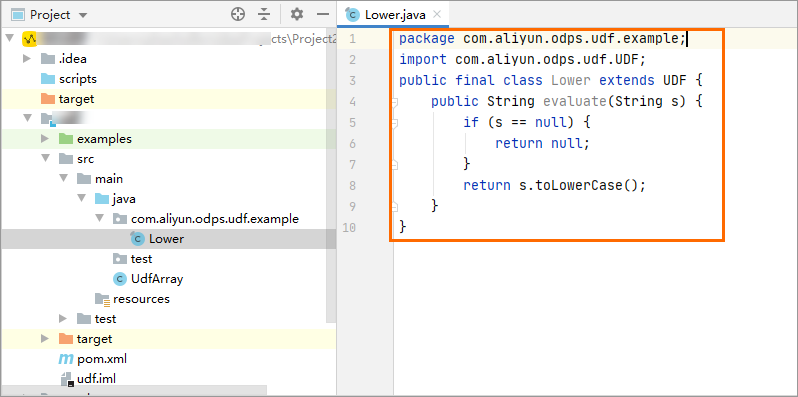 UDF代码示例如下。
UDF代码示例如下。package com.aliyun.odps.udf.example; import com.aliyun.odps.udf.UDF; public final class Lower extends UDF { public String evaluate(String s) { if (s == null) { return null; } return s.toLowerCase(); } }说明如果需要本地调试Java UDF,请参见开发和调试UDF。
上传并注册UDF。
在UDF Java文件上单击右键,选择Deploy to server...,在Package a jar, submit resource and register function对话框中配置如下参数后,单击OK。
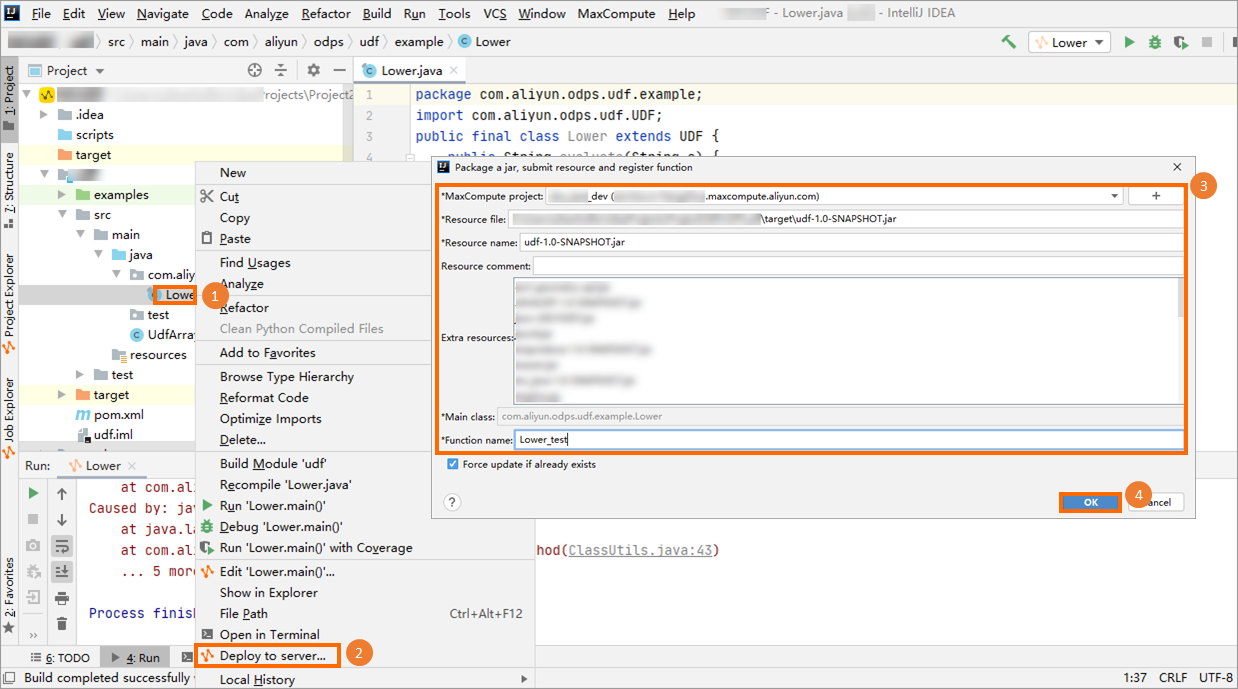
MaxCompute project:UDF所在的MaxCompute项目名称。由于UDF本身是在连接的MaxCompute项目下编写的,此处保持默认值即可。
Resource file:UDF依赖的资源文件路径。此处保持默认值即可。
Resource name:UDF依赖的资源。此处保持默认值即可。
Function name:注册的函数名称,即后续SQL中调用的UDF名称。例如Lower_test。
调试UDF。
在左侧导航栏单击Project Explore,在目标MaxCompute项目上单击右键,选择Open Console并在Console区域输入调用UDF的SQL语句,按Enter键运行即可。
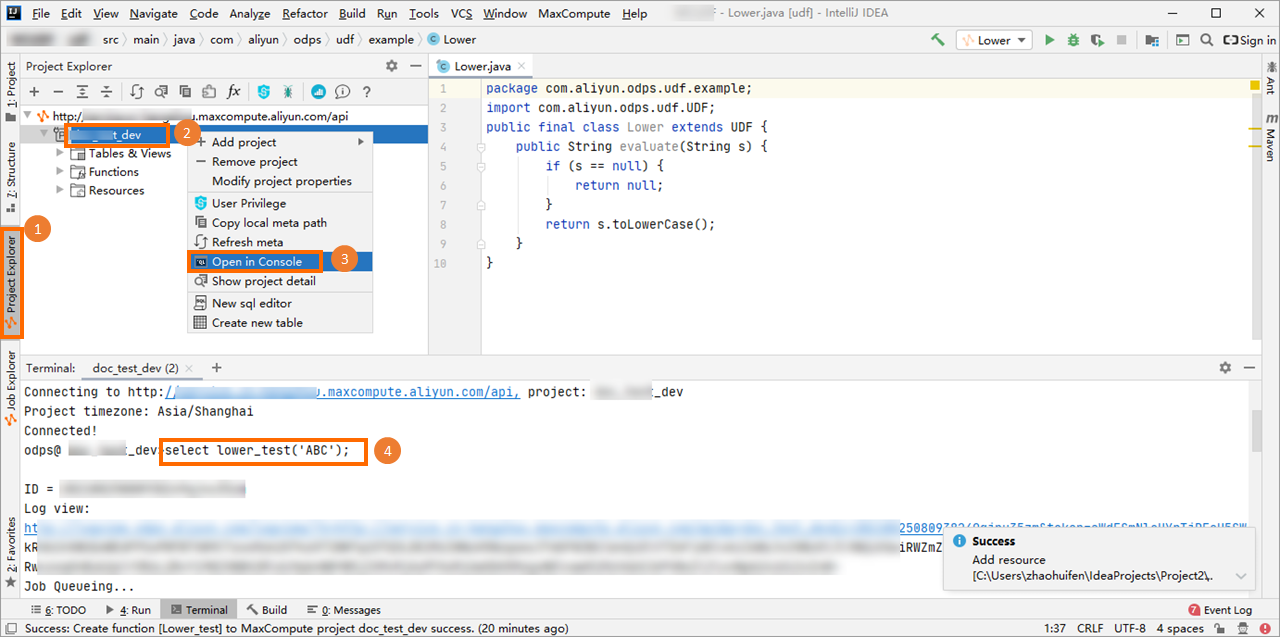 SQL语句示例如下。
SQL语句示例如下。select lower_test('ABC');返回结果如下。
+-----+ | _c0 | +-----+ | abc | +-----+
使用DataWorks
准备工作。
使用DataWorks开发调试UDF时,您需要先开通DataWorks并绑定MaxCompute项目,做好UDF开发前准备工作。操作详情请参见使用DataWorks连接。
编写UDF代码。
您可以在任意Java开发工具中开发UDF代码并打包为一个JAR包。您可以使用以下UDF代码示例。
package com.aliyun.odps.udf.example; import com.aliyun.odps.udf.UDF; public final class Lower extends UDF { public String evaluate(String s) { if (s == null) { return null; } return s.toLowerCase(); } }上传并注册UDF。
您可以将已打包好的代码包通过DataWorks上传并完成UDF注册,操作详情请参见:
调试UDF。
注册完成UDF后,您可以创建一个ODPS SQL节点,在节点中编写并创建SQL命令来调试UDF。创建ODPS SQL节点的操作请参见创建ODPS SQL节点,调试命令示例如下。
select lower_test('ABC');
使用odpscmd
准备工作。
使用odpscmd开发调试UDF时,您需要先下载安装odpscmd工具,并配置config文件连接MaxCompute项目,做好UDF开发前准备工作。操作详情请参见使用客户端(odpscmd)连接。
编写UDF代码。
您可以在任意Java开发工具中开发UDF代码并打包为一个JAR包。您可以使用以下UDF代码示例。
package com.aliyun.odps.udf.example; import com.aliyun.odps.udf.UDF; public final class Lower extends UDF { public String evaluate(String s) { if (s == null) { return null; } return s.toLowerCase(); } }上传并注册UDF。
您可以将已打包好的代码包通过odpscmd上传并完成UDF注册,操作详情请参见:
调试UDF。
注册完成UDF后,您可以编写并创建SQL命令来调试UDF。调试命令示例如下。
select lower_test('ABC');
UDF开发完成后:UDF调用说明
按照上述UDF开发流程,完成Java UDF开发后,您即可在odpscmd中通过MaxCompute SQL调用Java UDF。调用方法如下:
在归属MaxCompute项目中使用自定义函数:使用方法与内建函数类似,您可以参照内建函数的使用方法使用自定义函数。
跨项目使用自定义函数:即在项目A中使用项目B的自定义函数,跨项目分享语句示例:
select B:udf_in_other_project(arg0, arg1) as res from table_t;。更多跨项目分享信息,请参见基于Package跨项目访问资源。
UDF示例demo
附录:UDF代码结构
您可以使用Java语言编写UDF代码,代码中需要包含如下信息:
Java包(Package):可选。
您可以将定义的Java类打包,为后续查找和使用类提供方便。
继承UDF类:必选。
必需携带的UDF类为
com.aliyun.odps.udf.UDF。当您需要使用其他UDF类或者需要用到复杂数据类型时,请根据MaxCompute SDK添加需要的类。例如STRUCT数据类型对应的UDF类为com.aliyun.odps.data.Struct。@Resolve注解:可选。格式为
@Resolve(<signature>),signature用于定义函数的输入参数和返回值的数据类型。当您需要在UDF中使用STRUCT数据类型时,无法基于com.aliyun.odps.data.Struct反射分析得到Field Name和Field Type,所以需要用@Resolve注解来辅助获取。即如果您需要在UDF中使用STRUCT,请在UDF Class中加上@Resolve注解,注解只会影响参数或返回值中包含com.aliyun.odps.data.Struct的重载。例如@Resolve("struct<a:string>,string->string")。详细使用示例,请参见复杂数据类型示例。自定义Java类:必选。
UDF代码的组织单位,定义了实现业务需求的变量及方法。
evaluate方法:必选。非静态的Public方法,位于自定义的Java类中。
evaluate方法的输入参数和返回值的数据类型将作为SQL语句中UDF的函数签名Signature(定义UDF的输入与输出数据类型)。您可以在UDF中实现多个
evaluate方法,在调用UDF时,MaxCompute会依据UDF调用的参数类型匹配正确的evaluate方法。编写Java UDF时可以使用Java Type或Java Writable Type,MaxCompute项目支持处理的数据类型与Java数据类型的详细映射关系,请参见附录:数据类型。
UDF初始化或结束代码:可选。您可以通过
void setup(ExecutionContext ctx)和void close()分别实现UDF初始化和结束。void setup(ExecutionContext ctx)方法会在evaluate方法前调用且仅会调用一次,可以用来初始化一些计算所需要的资源或类的成员对象。void close()方法会在evaluate方法结束后调用,可以用来执行一些清理工作,例如关闭文件。
UDF代码示例如下。
使用Java Type类型
//将定义的Java类组织在org.alidata.odps.udf.examples包中。 package org.alidata.odps.udf.examples; //继承UDF类。 import com.aliyun.odps.udf.UDF; //自定义Java类。 public final class Lower extends UDF { //evaluate方法。其中:String标识输入参数的数据类型,return标识返回值。 public String evaluate(String s) { if (s == null) { return null; } return s.toLowerCase(); } }使用Java Writable Type类型
//将定义的Java类组织在com.aliyun.odps.udf.example包中。 package com.aliyun.odps.udf.example; //添加Java Writable Type类型必需的类。 import com.aliyun.odps.io.Text; //继承UDF类。 import com.aliyun.odps.udf.UDF; //自定义Java类。 public class MyConcat extends UDF { private Text ret = new Text(); //evaluate方法。其中:Text标识输入参数的数据类型,return标识返回值。 public Text evaluate(Text a, Text b) { if (a == null || b == null) { return null; } ret.clear(); ret.append(a.getBytes(), 0, a.getLength()); ret.append(b.getBytes(), 0, b.getLength()); return ret; } }
MaxCompute还支持直接使用在其兼容的Hive版本上开发的UDF,请参见Hive兼容数据类型。
附录:数据类型
数据类型映射
为确保编写Java UDF过程中使用的数据类型与MaxCompute支持的数据类型保持一致,您需要关注二者间的数据类型映射关系。具体映射关系如下。
在MaxCompute中不同数据类型版本支持的数据类型不同。从MaxCompute 2.0版本开始,扩展了更多的新数据类型,同时还支持ARRAY、MAP、STRUCT等复杂类型。更多MaxCompute数据类型版本信息,请参见数据类型版本说明。
MaxCompute Type | Java Type | Java Writable Type |
TINYINT | java.lang.Byte | ByteWritable |
SMALLINT | java.lang.Short | ShortWritable |
INT | java.lang.Integer | IntWritable |
BIGINT | java.lang.Long | LongWritable |
FLOAT | java.lang.Float | FloatWritable |
DOUBLE | java.lang.Double | DoubleWritable |
DECIMAL | java.math.BigDecimal | BigDecimalWritable |
BOOLEAN | java.lang.Boolean | BooleanWritable |
STRING | java.lang.String | Text |
VARCHAR | com.aliyun.odps.data.Varchar | VarcharWritable |
BINARY | com.aliyun.odps.data.Binary | BytesWritable |
DATE | java.sql.Date | DateWritable |
DATETIME | java.util.Date | DatetimeWritable |
TIMESTAMP | java.sql.Timestamp | TimestampWritable |
INTERVAL_YEAR_MONTH | 不涉及 | IntervalYearMonthWritable |
INTERVAL_DAY_TIME | 不涉及 | IntervalDayTimeWritable |
ARRAY | java.util.List | 不涉及 |
MAP | java.util.Map | 不涉及 |
STRUCT | com.aliyun.odps.data.Struct | 不涉及 |
Hive兼容数据类型
当MaxCompute项目采用2.0数据类型版本时,支持Hive风格的UDF,您可以直接使用在MaxCompute兼容的Hive版本上开发的Hive UDF。
MaxCompute兼容的Hive版本为2.1.0,对应Hadoop版本为2.7.2。如果UDF是在其他版本的Hive或Hadoop上开发的,您需要使用兼容的Hive或Hadoop版本重新编译UDF JAR包。
在MaxCompute上使用Hive UDF的具体案例,请参见兼容Hive Java UDF示例。