
表格存储Tablestore支持接入到DataWorks中进行管理和使用,您可以通过在DataWorks中添加Tablestore数据源来连接Tablestore服务。添加Tablestore数据源后,您可以在DataWorks中配置数据同步任务进行Tablestore数据的同步迁移或者使用SQL语句查询Tablestore数据。本文介绍如何使用SQL语句查询Tablestore数据。
背景信息
DataWorks基于MaxCompute、Hologres、EMR、AnalyticDB、CDP等大数据引擎,为数据仓库、数据湖、湖仓一体等解决方案提供统一的全链路大数据开发治理平台。更多信息,请参见什么是DataWorks。
使用场景
将表格存储接入到DataWorks,可以在DataWorks中实现高效的数据处理和分析,支持多样化的大数据应用场景。典型使用场景如下:
大规模数据存储与分析
借助表格存储的高吞吐量和大容量特性。在DataWorks中,可以通过SQL、MapReduce或自定义代码等方式直接查询和处理表格存储中的数据,进行大数据分析。例如日志分析、用户行为分析等。
实时数据处理
配合DataWorks的实时计算服务(例如Flink),可以实现表格存储数据的实时消费、处理与分析,适用于实时监控、实时报表、实时推荐系统等场景。
离线数据处理与批处理
利用DataWorks的任务调度能力,可以定时触发对表格存储中数据的批量处理作业,例如ETL(抽取、转换、加载)任务,将原始数据转化为适合分析的格式,或者定期进行数据聚合、统计分析。
数据湖与数据仓库建设
表格存储可以作为数据湖的存储层,存放原始数据或半结构化数据。通过DataWorks,可以构建数据管道,将表格存储中的数据进一步加工和清洗后,导入到MaxCompute或其他数据仓库系统,进行更复杂的分析和挖掘。
BI报表与数据可视化
DataWorks可以集成Quick BI等报表工具,直接从表格存储中提取数据,生成各种业务报表和仪表板,为企业决策提供数据支持。
机器学习与AI项目
在DataWorks中,可以利用表格存储来存储训练数据和模型特征数据,结合阿里云的机器学习平台PAI进行模型训练和预测,实现从数据准备到模型部署的全链路开发。
操作步骤
将Tablestore接入到DataWorks后,使用SQL查询功能查询和分析Tablestore中数据。
此功能适用于表格存储的宽表模型和时序模型。
准备工作
已创建RAM用户并为RAM用户授予管理表格存储权限(AliyunOTSFullAccess)和管理DataWorks权限(AliyunDataWorksFullAccess)以及创建AccessKey。具体操作,请参见使用RAM用户访问密钥访问表格存储。
根据使用的表格存储数据存储模型创建相应资源。
在DataWorks服务侧完成如下操作:
已开通DataWorks服务并创建工作空间。具体操作,请参见开通DataWorks服务和创建工作空间。
已拥有Tablestore数据源在数据分析模块的查询权限。具体操作,请参见数据查询与分析管控。
操作账号已被添加为工作空间的以下角色之一:数据分析师、模型设计师、开发、运维角色、空间管理员或项目所有者。具体操作,请参见为工作空间添加空间成员。
步骤一:在DataWorks中添加Tablestore数据源
将表格存储数据库添加为数据源,具体步骤如下:
进入数据集成页面。
登录DataWorks控制台,切换至目标地域后,单击左侧导航栏的,在下拉框中选择对应工作空间后单击进入数据集成。
在左侧导航栏,单击数据源。
在数据源列表页面,单击新增数据源。
在新增数据源对话框,找到Tablestore区块,单击Tablestore。
在新增OTS数据源对话框,根据下表配置数据源参数。
参数
说明
数据源名称
数据源名称必须以字母、数字、下划线(_)组合,且不能以数字和下划线(_)开头。
数据源描述
对数据源进行简单描述,不得超过80个字符。
地域
选择Tablestore实例所属地域。
Table Store实例名称
Tablestore实例的名称。更多信息,请参见实例。
Endpoint
Tablestore实例的服务地址,推荐使用VPC地址。
重要本文以Tablestore实例和DataWorks工作空间在同一阿里云主账号的同一地域下为例进行说明。更多场景信息,请参见各场景网络连通配置示例。
AccessKey ID
阿里云账号或者RAM用户的AccessKey ID和AccessKey Secret。获取方式请参见创建AccessKey。
AccessKey Secret
测试资源组连通性。
创建数据源时,您需要测试资源组的连通性,以保证同步任务使用的资源组能够与数据源连通,否则将无法正常执行数据同步任务。
(可选)购买并绑定资源组至当前DataWorks工作空间。具体操作,请参见新增和使用Serverless资源组。
不推荐使用旧版资源组(独享资源组和公共资源组),相较于旧版资源组,Serverless资源组支持的能力更丰富、售卖方式更统一、能有效利用资源碎片避免浪费,因此推荐您使用Serverless资源组。
说明Serverless资源组默认不具备公网访问能力。需要为绑定的VPC配置公网NAT网关和EIP后,才支持公网访问数据源。
待资源组启动成功后,在连接配置区域,单击相应资源组连通状态列的测试连通性。
测试连通性通过后,连通状态显示可连通,单击完成。
在数据源列表中,可以查看新建的数据源。
说明如果显示无法连通,表示资源组与数据源无法连通,后续相应数据源任务将无法正常执行。您可以参考以下思路排查处理。
根据右侧弹出的连通性诊断工具窗口,自助解决连通性问题。
如果连通性诊断工具未给出具体解决办法,请检查您设置的账号、密码、连接地址等参数,以及确保将资源组的IP地址加入到数据源的白名单中。更多信息,请参见网络连通方案。
步骤二:在DataWorks中使用SQL查询Tablestore数据
表格存储支持宽表模型、时序模型等数据存储模型,不同数据存储模型的使用SQL查询操作存在差异,请根据所用数据存储模型选择相应操作。
当前支持在DataWorks数据分析中对表格存储进行的SQL查询功能与表格存储自身支持的SQL查询功能一致。更多信息,请参见SQL支持功能说明。
使用SQL查询宽表数据
进入数据分析页面。
以项目管理员身份登录DataWorks控制台。
在左侧导航栏,选择数据分析 > SQL查询。
在SQL查询页面,选择地域后,选择目标工作空间并单击进入SQL查询。
新建SQL查询文件。
将鼠标移动到我的文件目录后的加号图标上,选择新建文件。
在新建文件对话框中,填写文件名,然后单击确定。
创建后的文件会显示在左侧区域栏中。
打开创建的文件后,配置要查询的数据源信息。
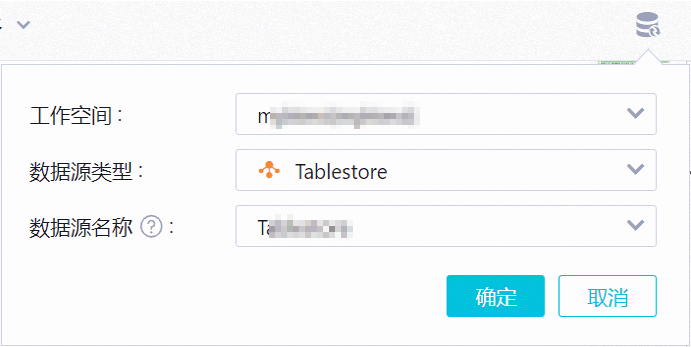
在文件界面右上角单击
 图标。
图标。在悬浮框中根据下表说明配置数据源信息。
参数
说明
工作空间
工作空间名称,请根据实际选择。
数据源类型
要查询的数据源类型,请选择Tablestore。
数据源名称
数据源名称,请选择要查询的表所在实例对应的数据源名称。
重要数据源名称列表中仅展示您有权限使用的数据源,如需更多数据源,请联系管理员在安全中心进行设置。具体操作,请参见数据查询与分析管控。
单击确定。
为表创建映射关系并运行SQL语句。
如果已为表创建了SQL映射关系,请跳过此操作。
重要创建表的SQL映射关系时,请确保SQL映射关系中的字段类型与表中的字段类型相匹配。更多信息,请参见SQL数据类型映射。
在文件中编写创建SQL映射关系的SQL语句。具体操作,请参见创建表的映射关系。
为数据表创建映射关系时,SQL映射表名称必须与数据表名称相同,且SQL的主键列必须与数据表的主键列相同。
说明如果已为数据表创建多元索引,您还可以选择为多元索引创建映射关系,以实现通过指定多元索引查询数据。具体操作,请参见创建多元索引的映射关系。
以下示例用于创建test_table表的SQL映射关系。
CREATE TABLE `test_table` ( `pk` VARCHAR(1024), `long_value` BIGINT(20), `double_value` DOUBLE, `string_value` MEDIUMTEXT, `bool_value` BOOL, PRIMARY KEY(`pk`) );单击SQL语句所在位置后,单击运行。
运行结果会显示在相应结果页签中。
使用SQL查询表中数据。
在文件中编写SELECT语句查询数据。具体操作,请参见查询数据。
以下示例用于查询test_table表中数据,并且最多返回20行数据。
SELECT `pk`, `long_value`, `double_value`, `string_value`, `bool_value` FROM test_table LIMIT 20;单击SQL语句所在位置后,单击运行。
运行结果会显示在相应结果页签中。
使用SQL查询时序数据
进入数据分析页面。
以项目管理员身份登录DataWorks控制台。
在左侧导航栏,选择数据分析 > SQL查询。
在SQL查询页面,选择地域后,选择目标工作空间并单击进入SQL查询。
新建SQL查询文件。
将鼠标移动到我的文件目录后的加号图标上,选择新建文件。
在新建文件对话框中,填写文件名,然后单击确定。
创建后的文件会显示在左侧区域栏中。
打开创建的文件后,配置要查询的数据源信息。
在文件界面右上角单击
图标。在悬浮框中根据下表说明配置数据源信息。
参数
说明
工作空间
工作空间名称,请根据实际选择。
数据源类型
要查询的数据源类型,请选择Tablestore。
数据源名称
数据源名称,请选择要查询的表所在实例对应的数据源名称。
重要数据源名称列表中仅展示您有权限使用的数据源,如需更多数据源,请联系管理员在安全中心进行设置。具体操作,请参见数据查询与分析管控。
单击确定。
为表创建映射关系并运行SQL语句。
创建时序表后,系统会自动为表创建单值模型映射关系和时间线元数据映射关系,无需手动创建。在SQL中单值模型映射关系的名称与时序表名相同,时间线元数据映射关系的表名为时序表名称后拼接
::meta。如果要以多值模型查询时序数据,您需要手动创建多值模型映射关系。否则请跳过此操作。
在文件中编写SQL语句创建SQL映射关系。更多信息,请参见时序表的SQL映射关系。
假设测量的属性同时包含了cpu、memory、disktop三种度量,此处以创建多值类型映射表
timeseries_table::muti_model为例介绍。SQL示例如下:CREATE TABLE `timeseries_table::muti_model` ( `_m_name` VARCHAR(1024), `_data_source` VARCHAR(1024), `_tags` VARCHAR(1024), `_time` BIGINT(20), `cpu` DOUBLE(10), `memory` DOUBLE(10), `disktop` DOUBLE(10), PRIMARY KEY(`_m_name`,`_data_source`,`_tags`,`_time`) );单击SQL语句所在位置后,单击运行。
运行结果会显示在相应结果页签中。
使用SQL查询表中数据。
在文件中编写SELECT语句查询数据。更多信息,请参见SQL示例。
使用单值模型映射关系查询数据
以下示例用于查询时序数据表中basic_metric度量类型的数据。
SELECT * FROM timeseries_table WHERE _m_name = "basic_metric" LIMIT 10;使用时间线元数据映射关系查询数据
以下用于查询时序元数据表中basic_metric度量类型下的时间线。
SELECT * FROM `timeseries_table::meta` WHERE _m_name = "basic_metric" LIMIT 100;使用多值模型映射关系查询数据
以下示例用于查询多值模型映射表中cpu大于20.0的所有度量信息。
SELECT cpu,memory,disktop FROM `timeseries_table::muti_model` WHERE cpu > 20.0 LIMIT 10;
单击SQL语句所在位置后,单击运行。
运行结果会显示在相应结果页签中。
计费说明
表格存储费用说明
通过DataWorks使用SQL访问表格存储时,SQL本身不会有额外的费用,但是使用SQL查询数据过程中涉及到的表扫描、索引查询等操作会产生费用。更多信息,请参见SQL查询计量计费。
其他资源费用说明
使用DataWorks工具时,DataWorks会收取相关的功能费用和资源费用。更多信息,请参见购买指引。
相关文档
您还可以通过表格存储的控制台、命令行工具、SDK、JDBC、Go语言驱动等方式使用SQL查询数据。具体操作,请参见SQL使用方式。
您还可以将Tablestore实例接入到DMS,然后使用SQL查询与分析Tablestore数据。更多信息,请参见接入到DMS。
您还可以通过MaxCompute、Spark、Hive或者HadoopMR、函数计算、Flink、PrestoDB等计算引擎实现对表中数据的计算与分析。具体操作,请参见计算与分析。
您还可以使用DataWorks数据集成服务将MySQL、Oracle、Kafka、HBase、MaxCompute、PolarDB-X 2.0、Tablestore等数据源的数据迁移到表格存储中。更多信息,请参见数据集成服务。
SQL查询可应用在表格存储物联网存储IoTstore解决方案中作为不同类型数据的统一查询接口。更多信息,请参见物联网存储简介。
物联网存储IoTstore是表格存储基于物联网场景中多源异构数据存储、高并发吞吐、海量数据高性价比存储、多维度数据处理与分析等需求推出的一站式物联网解决方案,可为物联网设备元数据、消息数据、时序轨迹等海量数据提供存储、查询、检索、分析、同步等能力。