
当您的现有业务对数据库的并发读写、扩展性和可用性的要求较高,且需要使用复杂的检索或大数据分析时,如果原有数据库的数据架构不能满足现在的业务需求或改造成本较大,则您可以通过DataWorks数据集成服务将现有数据库中的数据迁移到Tablestore表中存储和使用。您还可以通过DataWorks数据集成服务实现表格存储表中数据的跨实例或者跨账号迁移以及将表格存储数据迁移到OSS或者MaxCompute中备份和使用。
应用场景
DataWorks数据集成是稳定高效、弹性伸缩的数据同步平台,适用于MySQL、Oracle、MaxCompute、Tablestore等多种异构数据源之间的数据迁移与同步。
表格存储支持通过DataWorks数据集成实现的数据迁移场景包括将数据库数据迁移到表格存储、表格存储数据跨实例或者跨账号迁移同步和将表格存储数据迁移到OSS或者MaxCompute。
将数据库数据迁移到表格存储
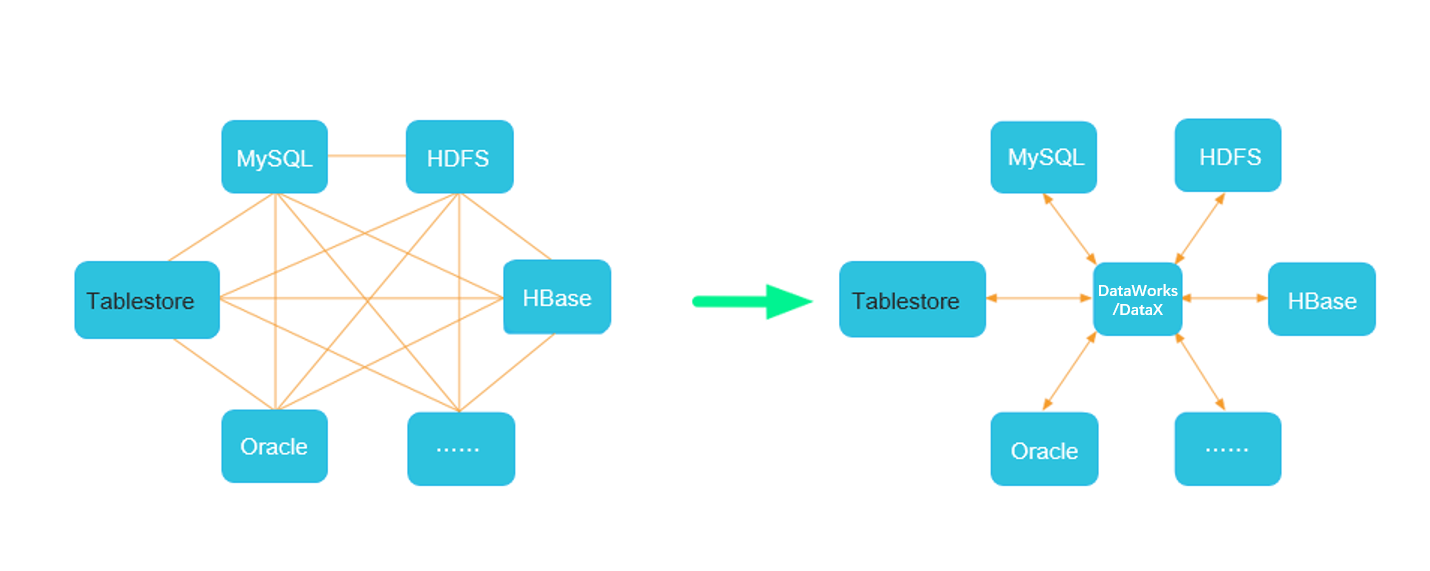
DataWorks提供各种异构数据源之间稳定高效的数据同步功能,可以实现将多种数据库迁移到表格存储,如下图所示。
DataWorks支持的数据源与读写插件详情请参见DataWorks支持的数据源与读写插件。
表格存储数据跨实例或者跨账号迁移同步
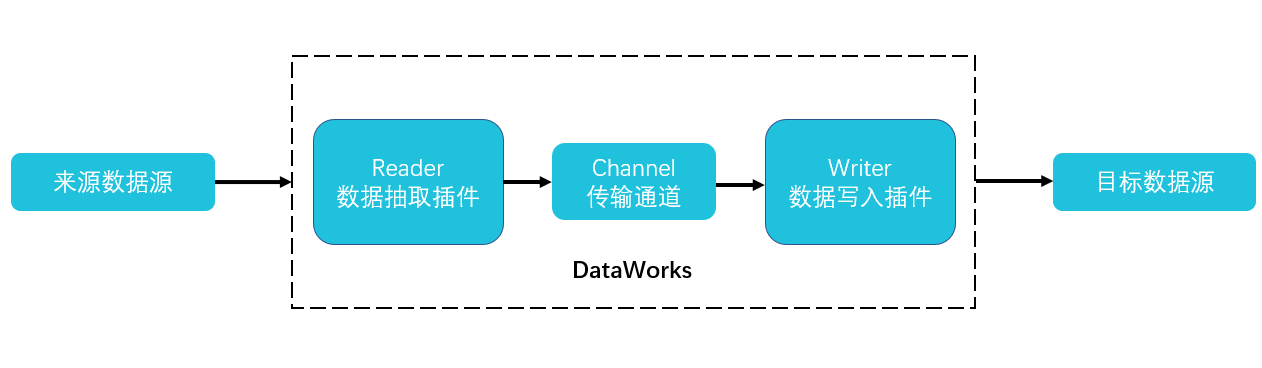
通过在DataWorks中配置表格存储相关的Reader和Writer插件,即可以完成表格存储数据表或者时序表的数据复制,如下图所示。表格存储相关的插件说明请参见下表。
插件 | 说明 |
OTSReader | 用于读取表格存储表中的数据,并可以通过指定抽取数据范围实现数据增量抽取的需求。 |
OTSStreamReader | 用于增量导出表格存储表中的数据。 |
OTSWriter | 用于向表格存储中写入数据。 |
将表格存储数据迁移到OSS或者MaxCompute
表格存储数据支持迁移到OSS或者MaxCompute,请根据实际场景选择。
云原生大数据计算服务(MaxCompute)是一种快速、完全托管的TB/PB级数据仓库解决方案。您可以使用MaxCompute备份表格存储数据或将表格存储数据迁移到MaxCompute中使用。
阿里云对象存储OSS(Object Storage Service)是一款海量、安全、低成本、高可靠的云存储服务。您可以使用OSS备份表格存储数据或者将表格存储数据同步到OSS后下载文件到本地。
迁移方案
请根据实际业务需求通过DataWorks数据集成实现表格存储与不同数据源之间的数据迁移。
数据导入的迁移方案包括同步MySQL数据到表格存储、同步Oracle数据到表格存储、同步Kafka数据到表格存储、同步HBase数据到表格存储、同步MaxCompute数据到表格存储、同步表格存储数据表中数据到另一个数据表和同步表格存储时序表中数据到另一个时序表。
数据导出的迁移方案包括同步表格存储数据到MaxCompute和同步表格存储数据到OSS。
数据导入
数据导入相关的迁移方案说明请参见下表。
迁移方案 | 说明 |
同步MySQL数据到表格存储 | MySQL数据库中的数据只能迁移到表格存储的数据表中。 迁移过程中会使用到MySQL的Reader脚本配置和表格存储的Writer脚本配置,具体数据源配置如下:
|
同步Oracle数据到表格存储 | Oracle数据库中的数据只能迁移到表格存储的数据表中。 迁移过程中会使用到Oracle的Reader脚本配置和表格存储的Writer脚本配置。具体数据源配置如下:
|
同步Kafka数据到表格存储 | Kafka中的数据支持迁移到表格存储的数据表或者时序表中。 重要
迁移过程中会使用到Kafka的Reader脚本配置和表格存储的Writer脚本配置。具体数据源配置如下:
|
同步HBase数据到表格存储 | HBase数据库中数据只支持迁移到表格存储的数据表中。 迁移过程中会使用到HBase的Reader脚本配置和表格存储的Writer脚本配置。具体数据源配置如下:
|
同步MaxCompute数据到表格存储 | MaxCompute的数据只支持迁移到表格存储的数据表中。 迁移过程中会使用到MaxCompute的Reader脚本配置和表格存储的Writer脚本配置。具体数据源配置如下:
|
同步PolarDB-X 2.0数据到表格存储 | PolarDB-X 2.0的数据只支持迁移到表格存储的数据表中。 迁移过程中会使用到PolarDB-X 2.0的Reader脚本配置和表格存储的Writer脚本配置,具体数据源配置如下:
|
同步表格存储数据表中数据到另一个数据表 | 表格存储数据表数据只支持迁移到表格存储另一个数据表中。 迁移过程中会使用到表格存储的Reader脚本配置和Writer脚本配置,具体数据源配置请参见Tablestore数据源。实际使用过程中请参考读写宽表数据的相关内容进行配置。 |
同步表格存储时序表中数据到另一个时序表 | 表格存储时序表数据只支持迁移到表格存储另一个时序表中。 迁移过程中会使用到表格存储的Reader脚本配置和Writer脚本配置,具体数据源配置请参见Tablestore数据源。实际使用过程中请参考读写时序数据的相关内容进行配置。 |
数据导出
数据导出相关的迁移方案说明请参见下表。
迁移方案 | 说明 |
同步表格存储数据到MaxCompute | 您可以使用MaxCompute备份表格存储数据或者将表格存储数据迁移到MaxCompute中使用。 迁移过程中会使用到表格存储的Reader脚本配置和MaxCompute的Writer脚本配置。具体数据源配置如下:
|
同步表格存储数据到OSS | 同步到OSS中的文件可自由下载,也可作为表格存储数据的备份存储于OSS。 迁移过程中会使用到表格存储的Reader脚本配置和OSS的Writer脚本配置。具体数据源配置如下:
|
前提条件
确定迁移方案后,完成相应准备工作。
已确保源数据源和DataWorks之间以及目标数据源和DataWorks之间的网络连通。
已完成源数据源的版本确认、账号准备、权限配置、产品特有配置等操作。更多信息,请参见相应数据源文档中的配置要求。
已完成目标数据源的服务开通、所需资源创建等操作。更多信息,请参见相应数据源文档中的配置要求。
注意事项
如果使用过程中遇到任何问题,请提交工单或者加入钉钉群36165029092(表格存储技术交流群-3)联系我们。
请确保DataWorks数据集成服务支持迁移相应产品版本的数据。
目标数据源的数据类型必须与源数据源的数据类型相匹配,否则迁移过程中会产生脏数据。
确定迁移方案后,请务必仔细阅读相应数据源文档中的使用限制、注意事项等信息。
迁移Kafka数据前,请务必根据实际业务场景选择合适的表格存储数据模型存储数据。
配置流程
请根据迁移方案了解通过DataWorks数据集成实现数据迁移的配置流程。

具体步骤说明请参见下表。
序号 | 步骤 | 说明 |
1 | 请根据迁移方案创建所需数据源。
| |
2 | DataWorks数据集成提供向导式的开发引导,通过可视化的填写和下一步的引导,助您快速完成数据同步任务的配置工作。向导模式的学习成本低,但无法支持部分高级功能。 | |
3 | 数据迁移结果验证 | 请根据迁移方案在相应数据源中查看导入的数据。
|
配置示例
数据导入
通过DataWorks数据集成,您可以将MySQL、Oracle、MaxCompute等数据库中的数据同步至表格存储的数据表,或实现跨账号、跨实例的表格存储数据同步。例如同步MaxCompute数据、同步数据表数据到另一个数据表、同步时序表数据到另一个时序表等。
此处以使用向导模式同步MaxCompute数据至表格存储数据表为例,介绍具体操作。
准备工作
在进行后续操作之前,请确保已完成以下准备工作。
已获取MaxCompute项目和源表信息。
已开通表格存储服务、创建实例及创建目标数据表,并获取实例名称、实例访问地址、地域ID等信息。
说明表格存储数据表的主键结构(包括数据类型及顺序)必须与MaxCompute源表的主键相匹配。数据表的属性列无需预先定义,将在数据写入时动态指定。
已为阿里云账号或RAM用户(具备Tablestore与MaxCompute服务的权限)创建AccessKey。
已开通DataWorks服务,并在MaxCompute实例或Tablestore实例所在地域创建工作空间。
如果MaxCompute实例和Tablestore实例不在同一地域,请参考以下操作步骤创建VPC对等连接实现跨地域网络连通。
此处以DataWorks工作空间与MaxCompute实例位于同一地域(华东1(杭州)),而Tablestore实例位于华东2(上海)为例进行说明。
为Tablestore实例绑定VPC。
登录表格存储控制台,在页面上方选择地域。
单击实例别名进入实例管理页面。
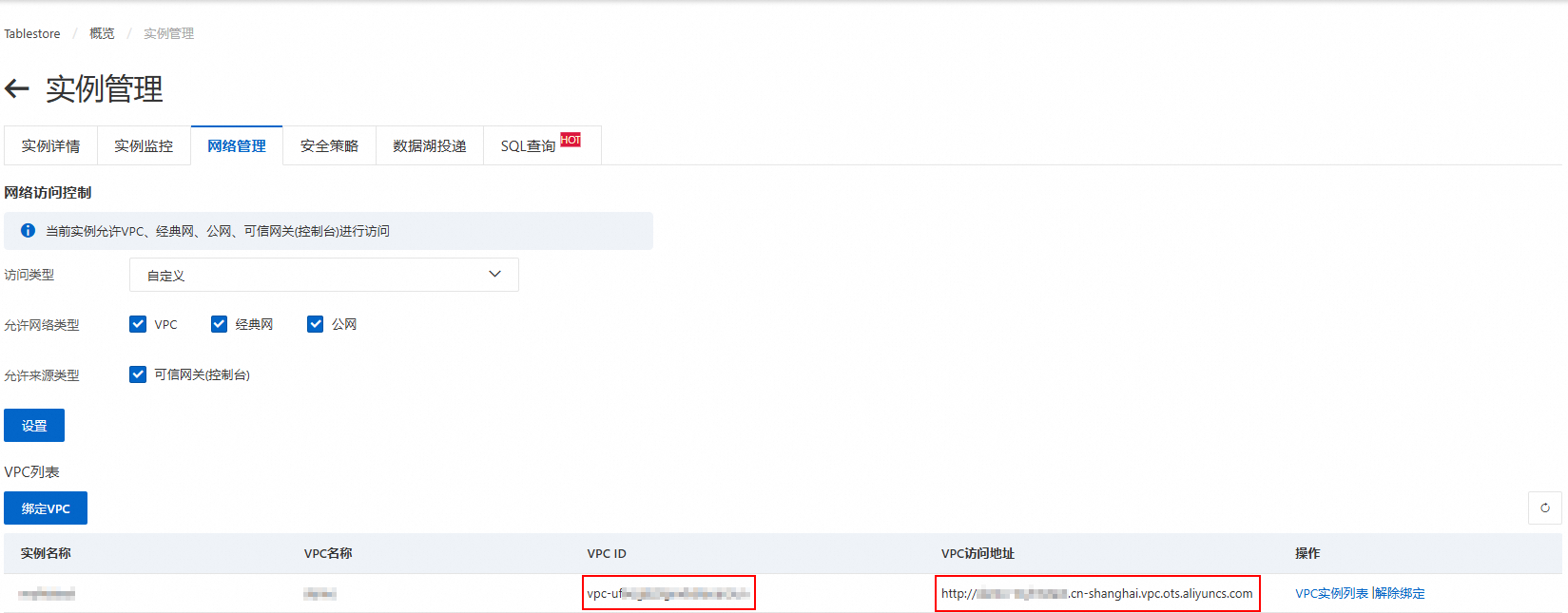
切换到网络管理页签,单击绑定VPC,选择VPC和交换机并填写VPC名称,然后单击确定。
请耐心等待一段时间,VPC绑定成功后页面将自动刷新,您可以在VPC列表查看绑定的VPC ID和VPC访问地址。
说明后续在DataWorks控制台添加Tablestore数据源时,将使用该VPC访问地址。
获取DataWorks工作空间资源组的VPC信息。
登录DataWorks控制台,在页面上方选择工作空间所在地域,然后单击左侧工作空间菜单,进入工作空间列表页面。
单击工作空间名称进入空间详情页面,单击左侧资源组菜单,查看工作空间绑定的资源组列表。
在目标资源组右侧单击网络设置,在资源调度 & 数据集成区域查看绑定的专有网络,即VPC ID。
创建VPC对等连接并配置路由。
登录专有网络VPC控制台。在页面左侧单击专有网络菜单,依次选择Tablestore实例和DataWorks工作空间所在地域,并记录VPC ID对应的网段地址。

在页面左侧单击VPC对等连接菜单,然后在VPC对等连接页面单击创建对等连接。
在创建对等连接页面,输入对等连接名称,选择发起端VPC实例、接收端账号类型、接收端地域和接收端VPC实例,单击确定。
在VPC对等连接页面,找到已创建的VPC对等连接,分别在发起端VPC实例列和接收端VPC实例列单击配置路由条目。
目标网段需填写对端VPC的网段地址。即在发起端VPC实例配置路由条目时,填写接收端VPC实例的网段地址;在接收端VPC实例配置路由条目时,填写发起端VPC实例的网段地址。
步骤一:新增表格存储数据源和MaxCompute数据源
步骤二:通过向导模式配置离线同步任务
数据开发(Data Studio)旧版
一、新建任务节点
进入数据开发页面。
登录DataWorks控制台。
在页面上方,选择资源组和地域。
在左侧导航栏,单击。
在数据开发页面的下拉框中,选择对应工作空间后单击进入数据开发。
在DataStudio控制台的数据开发页面,单击业务流程节点下的目标业务流程。
如果需要新建业务流程,请参见创建业务流程。
在数据集成节点上右键单击,然后选择新建节点 > 离线同步。
在新建节点对话框,选择路径并填写名称,然后单击确认。
在数据集成节点下,将显示新建的离线同步节点。
二、配置同步任务
在数据集成节点下,双击打开新建的离线同步任务节点。
配置网络与资源。
选择离线同步任务的数据来源、数据去向以及用于执行同步任务的资源组,并测试连通性。
在网络与资源配置步骤,选择数据来源为MaxCompute(ODPS),并选择数据源名称为新增的MaxCompute数据源。
选择资源组。
选择资源组后,系统会显示资源组的地域、规格等信息以及自动测试资源组与所选数据源之间连通性。
说明Serverless资源组支持为同步任务指定运行CU上限,如果您的同步任务因资源不足出现OOM现象,请适当调整资源组的CU占用取值。
选择数据去向为Tablestore,并选择数据源名称为新增的表格存储数据源。
系统会自动测试资源组与所选数据源之间连通性。
测试可连通后,单击下一步。
配置任务并保存。
在配置任务步骤的配置数据来源与去向区域,根据实际情况配置数据来源和数据去向。
数据来源
参数
说明
数据源
默认显示上一步选择的MaxCompute数据源。
Tunnel资源组
即Tunnel Quota,默认选择“公共传输资源”,即MC的免费quota。
MaxCompute的数据传输资源选择,具体请参见购买与使用独享数据传输服务资源组。
说明如果独享tunnel quota因欠费或到期不可用,任务在运行中将会自动切换为“公共传输资源”。
表
源表。
过滤方式
同步数据的过滤逻辑,支持以下两种方式 :
分区过滤:通过分区表达式过滤指定来源数据的同步范围,选择此方式时还需配置分区信息和分区不存在时参数。
数据过滤:通过SQL的WHERE过滤语句指定来源数据的同步范围(不需要填写WHERE关键字)。
分区信息
说明过滤方式选择为分区过滤时需要配置。
指定分区列的取值。
取值可以是固定值,如
ds=20220101。取值可以是调度系统参数,如
ds=${bizdate},当任务运行时,会自动替换调度系统参数。
分区不存在
说明过滤方式选择为分区过滤时需要配置。
分区不存在时,同步任务的处理策略。
出错。
忽略不存在分区,任务正常执行。
数据去向
参数
说明
数据源
默认显示上一步选择的Tablestore数据源。
表
目标数据表。
主键信息
目标数据表的主键信息。
写入模式
数据写入表格存储的模式,支持以下两种模式:
PutRow:对应于Tablestore API PutRow,插入数据到指定的行。如果该行不存在,则新增一行。如果该行存在,则覆盖原有行。
UpdateRow:对应于Tablestore API UpdateRow,更新指定行的数据。如果该行不存在,则新增一行。如果该行存在,则根据请求的内容在这一行中新增、修改或者删除指定列的值。
配置字段映射。
配置数据来源与数据去向后,需要指定来源字段和目标字段的映射关系。配置字段映射关系后,任务将根据字段映射关系,将源表字段写入目标表对应类型的字段中。更多信息,请参见4. 配置字段映射关系。
重要在来源字段中必须指定主键信息,以便读取主键数据。
由于在上一步的数据去向下已配置了目标表的主键信息,因此在目标字段中不可再配置主键信息。
当字段的数据类型为INTEGER时,您需要将其配置为INT,DataWorks会自动将其转换为INTEGER类型。如果直接配置为INTEGER类型,日志将会出现错误,导致任务无法顺利完成。
配置通道控制。
您可以通过通道配置,控制数据同步过程相关属性。相关参数说明详情可参见离线同步并发和限流之间的关系。
单击
 图标,保存配置。
图标,保存配置。
三、运行同步任务
单击
图标。在参数对话框,选择运行资源组的名称。
单击运行。
数据开发(Data Studio)新版
一、新建任务节点
进入数据开发页面。
登录DataWorks控制台。
在页面上方,选择资源组和地域。
在左侧导航栏,单击。
在数据开发页面的下拉框中,选择对应工作空间后单击进入Data Studio。
在DataStudio控制台的数据开发页面,单击项目目录右侧的
图标,然后选择。说明首次使用项目目录时,也可以直接单击新建节点按钮。
在新建节点对话框,选择路径并填写名称,然后单击确认。
在项目目录下,将显示新建的离线同步节点。
 图标,然后选择
图标,然后选择二、配置同步任务
在项目目录下,单击打开新建的离线同步任务节点。
配置网络与资源。
选择离线同步任务的数据来源、数据去向以及用于执行同步任务的资源组,并测试连通性。
在网络与资源配置步骤,选择数据来源为MaxCompute(ODPS),并选择数据源名称为新增的MaxCompute数据源。
选择资源组。
选择资源组后,系统会显示资源组的地域、规格等信息以及自动测试资源组与所选数据源之间连通性。
说明Serverless资源组支持为同步任务指定运行CU上限,如果您的同步任务因资源不足出现OOM现象,请适当调整资源组的CU占用取值。
选择数据去向为Tablestore,并选择数据源名称为新增的表格存储数据源。
系统会自动测试资源组与所选数据源之间连通性。
测试可连通后,单击下一步。
配置任务并保存。
在配置任务步骤的配置数据来源与去向区域,根据实际情况配置数据来源和数据去向。
数据来源
参数
说明
数据源
默认显示上一步选择的MaxCompute数据源。
Tunnel资源组
即Tunnel Quota,默认选择“公共传输资源”,即MC的免费quota。
MaxCompute的数据传输资源选择,具体请参见购买与使用独享数据传输服务资源组。
说明如果独享tunnel quota因欠费或到期不可用,任务在运行中将会自动切换为“公共传输资源”。
表
源表。
过滤方式
同步数据的过滤逻辑,支持以下两种方式 :
分区过滤:通过分区表达式过滤指定来源数据的同步范围,选择此方式时还需配置分区信息和分区不存在时参数。
数据过滤:通过SQL的WHERE过滤语句指定来源数据的同步范围(不需要填写WHERE关键字)。
分区信息
说明过滤方式选择为分区过滤时需要配置。
指定分区列的取值。
取值可以是固定值,如
ds=20220101。取值可以是调度系统参数,如
ds=${bizdate},当任务运行时,会自动替换调度系统参数。
分区不存在
说明过滤方式选择为分区过滤时需要配置。
分区不存在时,同步任务的处理策略。
出错。
忽略不存在分区,任务正常执行。
数据去向
参数
说明
数据源
默认显示上一步选择的Tablestore数据源。
表
目标数据表。
主键信息
目标数据表的主键信息。
写入模式
数据写入表格存储的模式,支持以下两种模式:
PutRow:对应于Tablestore API PutRow,插入数据到指定的行。如果该行不存在,则新增一行。如果该行存在,则覆盖原有行。
UpdateRow:对应于Tablestore API UpdateRow,更新指定行的数据。如果该行不存在,则新增一行。如果该行存在,则根据请求的内容在这一行中新增、修改或者删除指定列的值。
配置字段映射。
配置数据来源与数据去向后,需要指定来源字段和目标字段的映射关系。配置字段映射关系后,任务将根据字段映射关系,将源表字段写入目标表对应类型的字段中。更多信息,请参见4. 配置字段映射关系。
重要在来源字段中必须指定主键信息,以便读取主键数据。
由于在上一步的数据去向下已配置了目标表的主键信息,因此在目标字段中不可再配置主键信息。
当字段的数据类型为INTEGER时,您需要将其配置为INT,DataWorks会自动将其转换为INTEGER类型。如果直接配置为INTEGER类型,日志将会出现错误,导致任务无法顺利完成。
配置通道控制。
您可以通过通道配置,控制数据同步过程相关属性。相关参数说明详情可参见离线同步并发和限流之间的关系。
单击保存,保存配置。
三、运行同步任务
单击任务右侧的调试配置,选择运行的资源组。
单击运行。
步骤三:查看同步结果
数据导出
通过DataWorks数据集成,您可以将表格存储数据导出到MaxCompute或OSS中。
同步表格存储数据到MaxCompute
将表格存储的增量数据同步到MaxCompute后,您可以在DataWorks中使用ODPS SQL将表格存储的增量数据转换为全量数据格式。
同步表格存储数据到OSS
计费说明
其他方案
您可以根据需要将表格存储数据下载到本地文件。
您也可以通过DataX、通道服务等迁移工具完成数据导入。
迁移工具 | 说明 | 迁移方案 |
DataX将不同数据源的同步抽象为从源头数据源读取数据的Reader插件,以及向目标端写入数据的Writer插件。 | ||
通道服务(Tunnel Service)是基于表格存储数据接口之上的全增量一体化服务。通过为数据表建立数据通道,可以简单地实现对表中历史存量和新增数据的消费处理,适用于源表为表格存储数据表的数据迁移与同步。 | ||
数据传输服务DTS(Data Transmission Service)是阿里云提供的实时数据流服务,支持关系型数据库(RDBMS)、非关系型数据库(NoSQL)、数据多维分析(OLAP)等数据源间的数据交互,集数据同步、迁移、订阅、集成、加工于一体,助您构建安全、可扩展、高可用的数据架构。 | ||
Canal基于MySQL数据库增量日志解析,提供增量数据订阅和消费功能,是阿里开源CDC工具,它可以获取MySQL binlog数据并解析,然后将数据变动传输给下游。基于Canal,您可以实现从MySQL到其他数据库的实时同步。 | ||
Tapdata Cloud是由Tapdata提供的集数据复制、数据开发为一体的实时数据服务,能够在跨云、跨地域、多类型数据源的场景下,提供毫秒级的实时数据同步服务和数据融合服务。 |
附录:字段类型映射
以下列出了常用产品与表格存储的字段类型映射关系,实际使用时请按照相应字段类型映射信息进行字段映射配置。
MaxCompute和Tablestore字段类型映射
MaxCompute字段类型 | Tablestore字段类型 |
STRING | STRING |
BIGINT | INTEGER |
DOUBLE | DOUBLE |
BOOLEAN | BOOLEAN |
BINARY | BINARY |
MySQL和Tablestore字段类型映射
MySQL字段类型 | Tablestore字段类型 |
STRING | STRING |
INT、INTEGER | INTEGER |
DOUBLE、FLOAT、DECIMAL | DOUBLE |
BOOL、BOOLEAN | BOOLEAN |
BINARY | BINARY |
Kafka和Tablestore字段类型映射
Kafka Schema Type | Tablestore字段类型 |
STRING | STRING |
INT8、INT16、INT32、INT64 | INTEGER |
FLOAT32、FLOAT64 | DOUBLE |
BOOLEAN | BOOLEAN |
BYTES | BINARY |