StarRocks数据源为您提供读取和写入StarRocks的双向通道,本文为您介绍DataWorks的StarRocks数据同步的能力支持情况。
支持的版本
支持EMR Serverless StarRocks 2.5和3.1版本。
支持EMR on ECS:StarRocks 2.1版本。详情请参见:StarRocks概述。
支持的字段类型
支持大部分StarRocks类型,包括数值类型、字符串类型、日期类型。
数据同步前准备
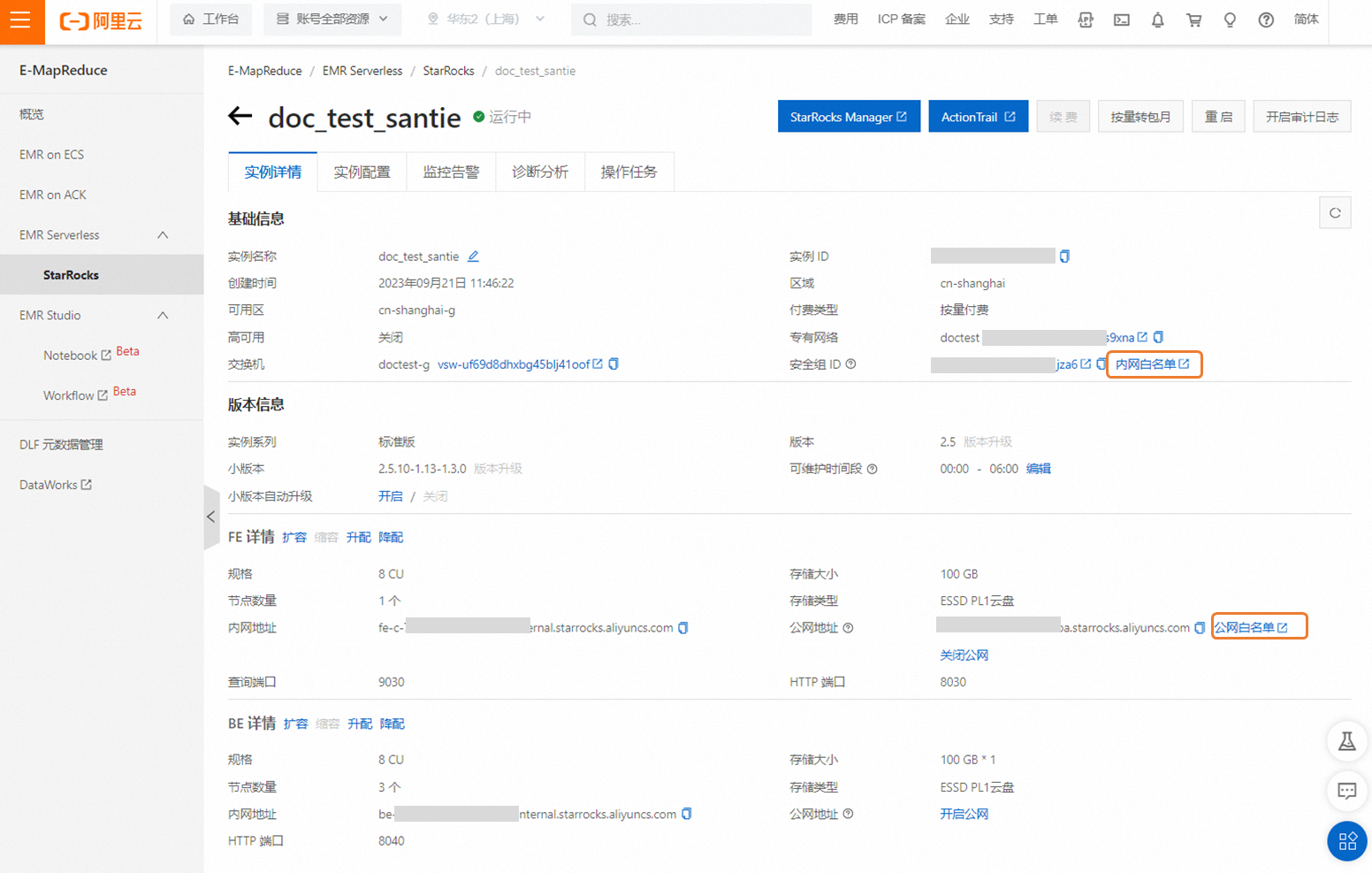
为保证资源组网络连通性,您需要提前将后续要使用的DataWorks独享资源组的白名单IP地址添加至EMR Serverless StarRocks实例的内网白名单中,同时,还需要允许该网段访问9030、8030、8040端口。
各DataWorks独享资源组的白名单IP地址可查看以下文档获取:
添加EMR Serverless StarRocks实例白名单的操作入口如下。
数据同步任务开发
StarRocks数据同步任务的配置入口和通用配置流程指导可参见下文的配置指导,详细的配置参数解释可在配置界面查看对应参数的文案提示。
创建数据源
在进行数据同步任务开发时,您需要在DataWorks上创建一个对应的数据源,操作流程请参见创建并管理数据源。创建数据源时JDBC URL拼接方式如下:
如果使用的是阿里云emr starrocks Serverless,则JDBC URL的拼接方式是:
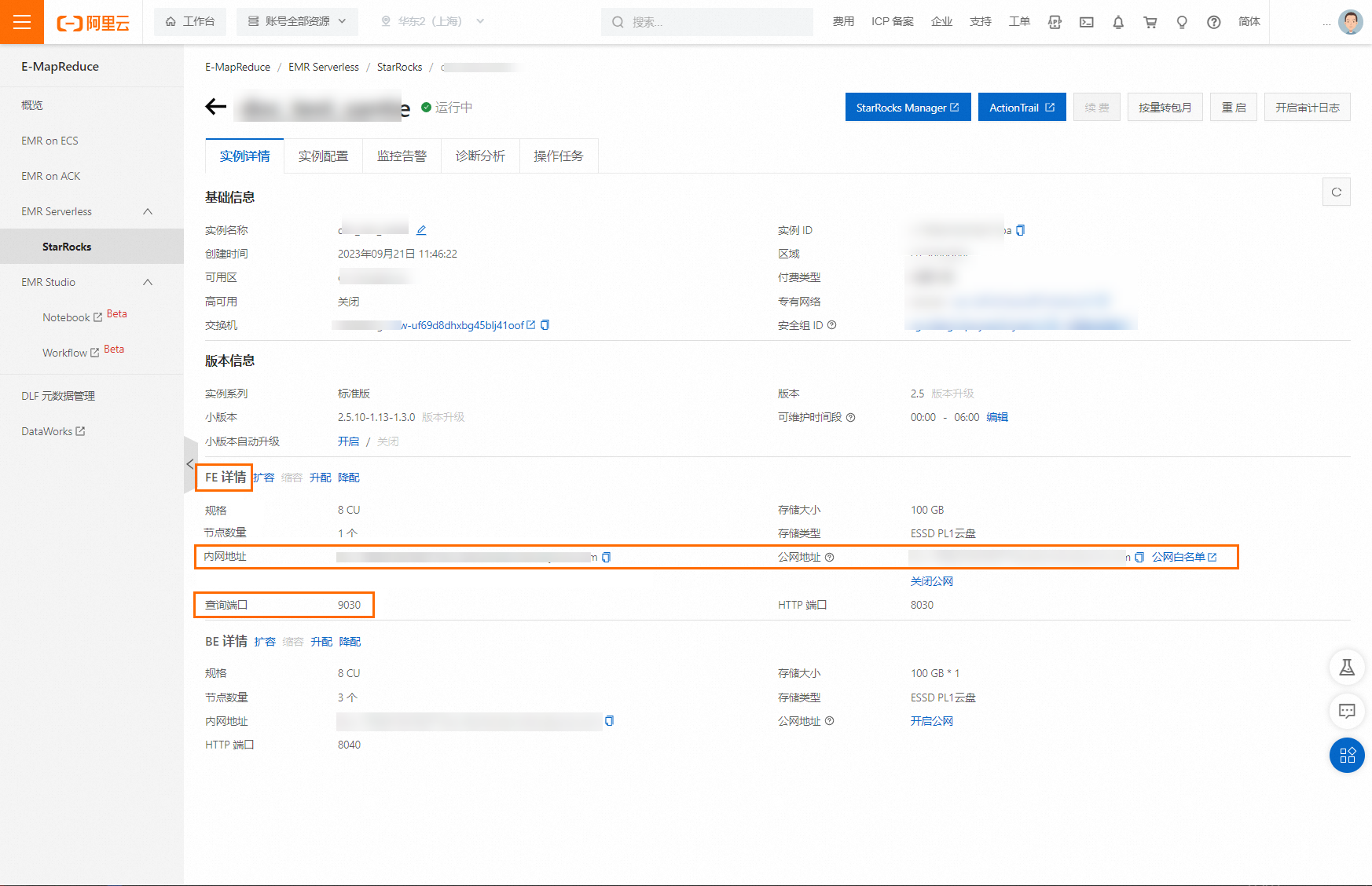
jdbc:mysql://<FE URL>:<FE查询端口>/<数据库名称>,其中:
FE信息:您可以在实例详情页获取。
数据库:使用EMR StarRocks Manager连接实例后,可以在SQL Editor或者元数据管理查看到对应的数据库。
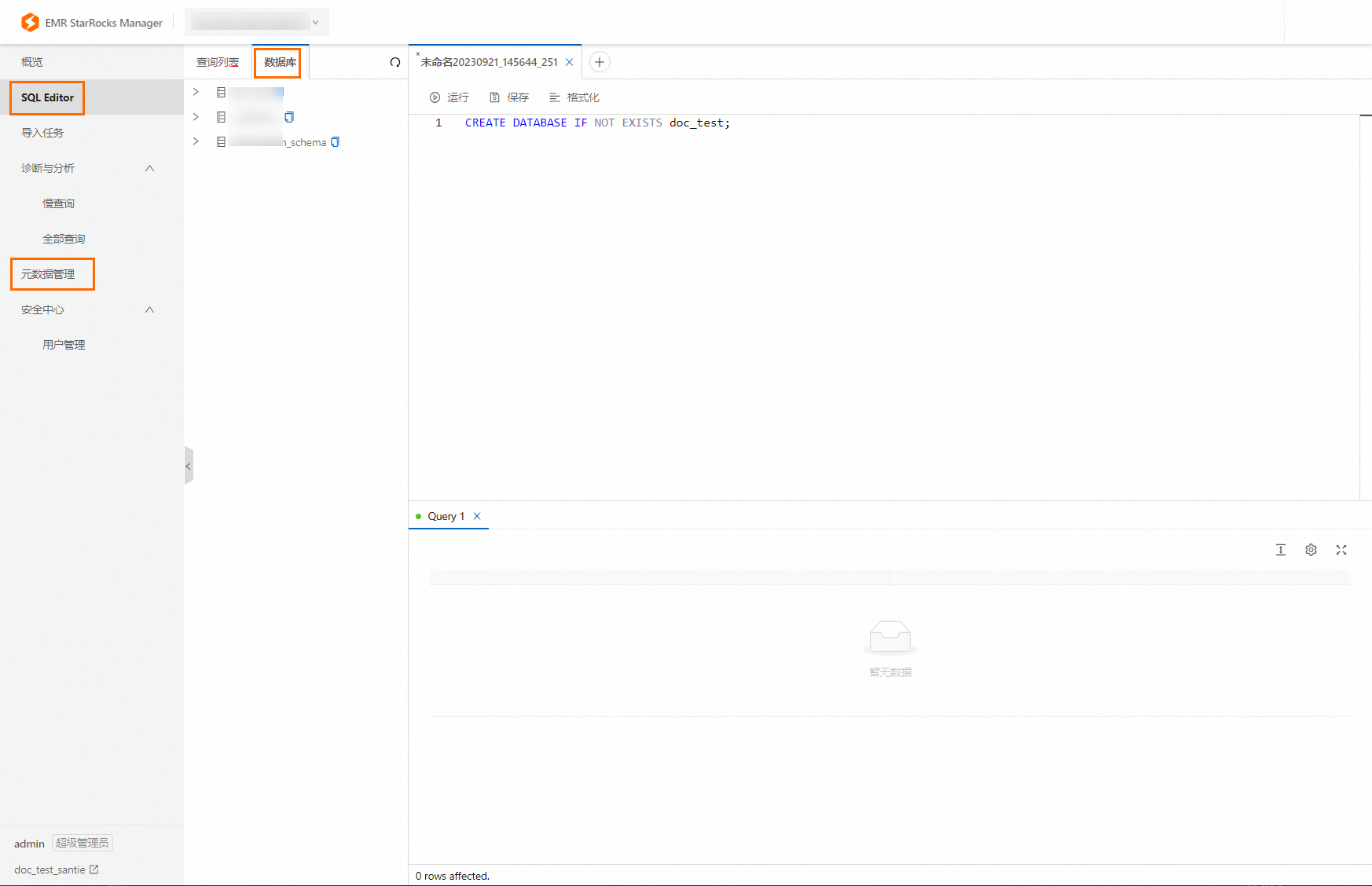
如果需要创建数据库,可以直接在SQL Editor里执行SQL命令进行创建。
单表离线同步任务配置指导
操作流程请参见通过向导模式配置离线同步任务、通过脚本模式配置离线同步任务。
脚本模式配置的全量参数和脚本Demo请参见下文的附录:脚本Demo与参数说明。
附录:脚本Demo与参数说明
附录:离线任务脚本配置方式
如果您配置离线任务时使用脚本模式的方式进行配置,您需要在任务脚本中按照脚本的统一格式要求编写脚本中的reader参数和writer参数,脚本模式的统一要求请参见通过脚本模式配置离线同步任务,以下为您介绍脚本模式下的数据源的Reader参数和Writer参数的指导详情。
Reader脚本Demo
{
"stepType": "starrocks",
"parameter": {
"selectedDatabase": "didb1",
"datasource": "starrocks_datasource",
"column": [
"id",
"name"
],
"where": "id>100",
"table": "table1",
"splitPk": "id"
},
"name": "Reader",
"category": "reader"
}Reader脚本参数
参数 | 描述 | 是否必选 | 默认值 |
datasource | StarRocks数据源名称。 | 是 | 无 |
selectedDatabase | StarRocks数据库名称。 | 否 | StarRocks数据源内配置的数据库名称。 |
column | 所配置的表中需要同步的列名集合。 | 是 | 无 |
where | 筛选条件,在实际业务场景中,往往会选择当天的数据进行同步,将where条件指定为
| 否 | 无 |
table | 选取的需要同步的表名称。 | 是 | 无 |
splitPk | StarRocks Reader进行数据抽取时,如果指定splitPk,表示您希望使用splitPk代表的字段进行数据分片,数据同步因此会启动并发任务进行数据同步,提高数据同步的效能。推荐splitPk用户使用表主键,因为表主键通常情况下比较均匀,因此切分出来的分片也不容易出现数据热点。 | 否 | 无 |
Writer脚本Demo
{
"stepType": "starrocks",
"parameter": {
"selectedDatabase": "didb1",
"loadProps": {
"row_delimiter": "\\x02",
"column_separator": "\\x01"
},
"datasource": "starrocks_public",
"column": [
"id",
"name"
],
"loadUrl": [
"1.1.1.1:8030"
],
"table": "table1",
"preSql": [
"truncate table table1"
],
"postSql": [
]
},
"name": "Writer",
"category": "writer"
}Writer脚本参数
参数 | 描述 | 是否必选 | 默认值 |
datasource | StarRocks数据源名称。 | 是 | 无 |
selectedDatabase | StarRocks数据库名称。 | 否 | StarRocks数据源内配置的数据库名称。 |
loadProps | StarRocks StreamLoad请求参数。使用StreamLoad CSV导入,此处可选择配置导入参数。如果无特殊配置则使用{}。可配置参数包括:
| 是 | 无 |
column | 所配置的表中需要同步的列名集合。 | 是 | 无 |
loadUrl | 填写StarRocks FrontEnd IP、Http Port(一般默认是8030),如果有多个FrontEnd节点,可全部配置上,并使用逗号(,)分隔。 | 是 | 无 |
table | 选取的需要同步的表名称。 | 是 | 无 |
preSql | 执行数据同步任务之前率先执行的SQL语句。例如,执行前清空表中的旧数据(truncate table tablename)。 | 否 | 无 |
postSql | 执行数据同步任务之后执行的SQL语句。 | 否 | 无 |
- 本页导读 (1)