本文介绍如何使用阿里云智能语音服务提供的Java SDK,包括SDK的安装方法及SDK代码示例。
前提条件
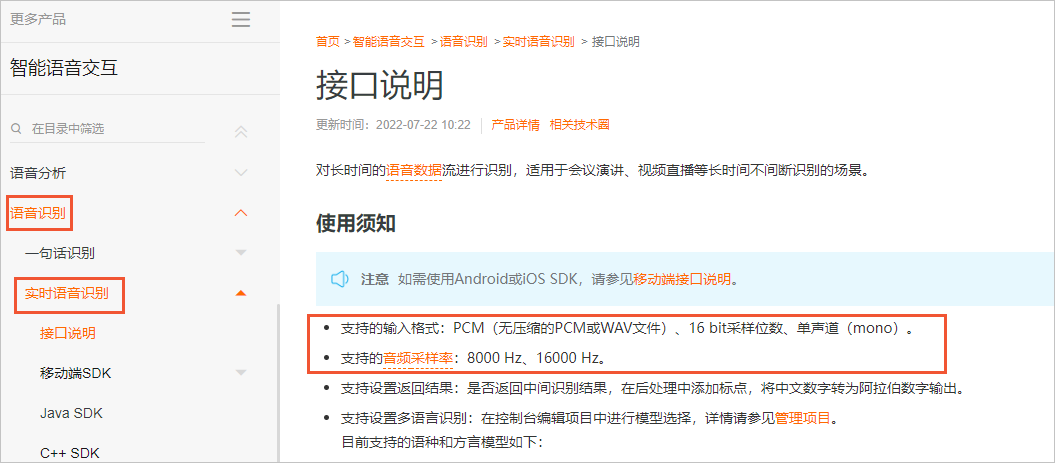
在使用SDK之前,请先阅读接口说明,详情请参见接口说明。
从2.1.0版本开始原有nls-sdk-long-asr更名为nls-sdk-transcriber。升级时需确认已删除nls-sdk-long-asr,并按编译提示添加相应回调方法。
下载安装
从Maven服务器下载最新版本SDK。
<dependency> <groupId>com.alibaba.nls</groupId> <artifactId>nls-sdk-transcriber</artifactId> <version>2.2.1</version> </dependency>Demo解压后,在pom目录运行
mvn package,会在target目录生成可执行JAR:nls-example-transcriber-2.0.0-jar-with-dependencies.jar,将JAR包拷贝到目标服务器,用于快速验证及服务压测。服务验证。
运行如下代码,并按提示提供相应参数。运行后在命令执行目录生成logs/nls.log。
java -cp nls-example-transcriber-2.0.0-jar-with-dependencies.jar com.alibaba.nls.client.SpeechTranscriberDemo服务压测。
运行如下代码,并按提示提供相应参数。其中阿里云服务URL参数为:
wss://nls-gateway-cn-shanghai.aliyuncs.com/ws/v1,语音文件为16k采样率PCM格式文件,并发数根据您的购买情况进行选择。java -jar nls-example-transcriber-2.0.0-jar-with-dependencies.jar重要自行压测超过2路并发将产生费用。
关键接口
NlsClient:语音处理客户端,利用该客户端可以进行一句话识别、实时语音识别和语音合成的语音处理任务。该客户端为线程安全,建议全局仅创建一个实例。
SpeechTranscriber:实时语音识别类,通过该接口设置请求参数,发送请求及声音数据。非线程安全。
SpeechTranscriberListener:实时语音识别结果监听类,监听识别结果。非线程安全。
更多介绍,请参见Java API接口说明。
SDK调用注意事项:
NlsClient使用了Netty框架,NlsClient对象的创建会消耗一定时间和资源,一经创建可以重复使用。建议调用程序将NlsClient的创建和关闭与程序本身的生命周期相结合。
SpeechTranscriber对象不可重复使用,一个识别任务对应一个SpeechTranscriber对象。例如,N个音频文件要进行N次识别任务,创建N个SpeechTranscriber对象。
SpeechTranscriberListener对象和SpeechTranscriber对象是一一对应的,不能在不同SpeechTranscriber对象中使用同一个SpeechTranscriberListener对象,否则不能将各识别任务区分开。
Java SDK依赖Netty网络库,如果您的应用依赖Netty,其版本需更新至4.1.17.Final及以上。
示例代码
示例中使用的音频文件为16000Hz采样率,请在管控台中将appkey对应项目的模型设置为通用模型,以获取正确的识别结果;如果使用其他音频,请设置为支持该音频场景的模型,关于模型设置,请参见管理项目。
示例中使用了SDK内置的默认外网访问服务端URL,如果您需要使用阿里云上海ECS内网访问服务端URL,则在创建NlsClient对象时,设置内网访问的URL:
client = new NlsClient("ws://nls-gateway-cn-shanghai-internal.aliyuncs.com/ws/v1", accessToken);调用接口前,需配置环境变量,通过环境变量读取访问凭证。智能语音交互的AccessKey ID、AccessKey Secret和AppKey的环境变量名:ALIYUN_AK_ID、ALIYUN_AK_SECRET、NLS_APP_KEY。
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import com.alibaba.nls.client.protocol.InputFormatEnum;
import com.alibaba.nls.client.protocol.NlsClient;
import com.alibaba.nls.client.protocol.SampleRateEnum;
import com.alibaba.nls.client.protocol.asr.SpeechTranscriber;
import com.alibaba.nls.client.protocol.asr.SpeechTranscriberListener;
import com.alibaba.nls.client.protocol.asr.SpeechTranscriberResponse;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
/**
* 此示例演示了:
* ASR实时识别API调用。
* 动态获取token。获取Token具体操作,请参见:https://help.aliyun.com/document_detail/450514.html
* 通过本地模拟实时流发送。
* 识别耗时计算。
*/
public class SpeechTranscriberDemo {
private String appKey;
private NlsClient client;
private static final Logger logger = LoggerFactory.getLogger(SpeechTranscriberDemo.class);
public SpeechTranscriberDemo(String appKey, String id, String secret, String url) {
this.appKey = appKey;
//应用全局创建一个NlsClient实例,默认服务地址为阿里云线上服务地址。
//获取token,实际使用时注意在accessToken.getExpireTime()过期前再次获取。
AccessToken accessToken = new AccessToken(id, secret);
try {
accessToken.apply();
System.out.println("get token: " + ", expire time: " + accessToken.getExpireTime());
if(url.isEmpty()) {
client = new NlsClient(accessToken.getToken());
}else {
client = new NlsClient(url, accessToken.getToken());
}
} catch (IOException e) {
e.printStackTrace();
}
}
private static SpeechTranscriberListener getTranscriberListener() {
SpeechTranscriberListener listener = new SpeechTranscriberListener() {
//识别出中间结果。仅当setEnableIntermediateResult为true时,才会返回该消息。
@Override
public void onTranscriptionResultChange(SpeechTranscriberResponse response) {
System.out.println("task_id: " + response.getTaskId() +
", name: " + response.getName() +
//状态码“20000000”表示正常识别。
", status: " + response.getStatus() +
//句子编号,从1开始递增。
", index: " + response.getTransSentenceIndex() +
//当前的识别结果。
", result: " + response.getTransSentenceText() +
//当前已处理的音频时长,单位为毫秒。
", time: " + response.getTransSentenceTime());
}
@Override
public void onTranscriberStart(SpeechTranscriberResponse response) {
//task_id是调用方和服务端通信的唯一标识,遇到问题时,需要提供此task_id。
System.out.println("task_id: " + response.getTaskId() + ", name: " + response.getName() + ", status: " + response.getStatus());
}
@Override
public void onSentenceBegin(SpeechTranscriberResponse response) {
System.out.println("task_id: " + response.getTaskId() + ", name: " + response.getName() + ", status: " + response.getStatus());
}
//识别出一句话。服务端会智能断句,当识别到一句话结束时会返回此消息。
@Override
public void onSentenceEnd(SpeechTranscriberResponse response) {
System.out.println("task_id: " + response.getTaskId() +
", name: " + response.getName() +
//状态码“20000000”表示正常识别。
", status: " + response.getStatus() +
//句子编号,从1开始递增。
", index: " + response.getTransSentenceIndex() +
//当前的识别结果。
", result: " + response.getTransSentenceText() +
//置信度
", confidence: " + response.getConfidence() +
//开始时间
", begin_time: " + response.getSentenceBeginTime() +
//当前已处理的音频时长,单位为毫秒。
", time: " + response.getTransSentenceTime());
}
//识别完毕
@Override
public void onTranscriptionComplete(SpeechTranscriberResponse response) {
System.out.println("task_id: " + response.getTaskId() + ", name: " + response.getName() + ", status: " + response.getStatus());
}
@Override
public void onFail(SpeechTranscriberResponse response) {
//task_id是调用方和服务端通信的唯一标识,遇到问题时,需要提供此task_id。
System.out.println("task_id: " + response.getTaskId() + ", status: " + response.getStatus() + ", status_text: " + response.getStatusText());
}
};
return listener;
}
//根据二进制数据大小计算对应的同等语音长度。
//sampleRate:支持8000或16000。
public static int getSleepDelta(int dataSize, int sampleRate) {
// 仅支持16位采样。
int sampleBytes = 16;
// 仅支持单通道。
int soundChannel = 1;
return (dataSize * 10 * 8000) / (160 * sampleRate);
}
public void process(String filepath) {
SpeechTranscriber transcriber = null;
try {
//创建实例、建立连接。
transcriber = new SpeechTranscriber(client, getTranscriberListener());
transcriber.setAppKey(appKey);
//输入音频编码方式。
transcriber.setFormat(InputFormatEnum.PCM);
//输入音频采样率。
transcriber.setSampleRate(SampleRateEnum.SAMPLE_RATE_16K);
//是否返回中间识别结果。
transcriber.setEnableIntermediateResult(false);
//是否生成并返回标点符号。
transcriber.setEnablePunctuation(true);
//是否将返回结果规整化,比如将一百返回为100。
transcriber.setEnableITN(false);
//设置vad断句参数。默认值:800ms,有效值:200ms~6000ms。
//transcriber.addCustomedParam("max_sentence_silence", 600);
//设置是否语义断句。
//transcriber.addCustomedParam("enable_semantic_sentence_detection",false);
//设置是否开启过滤语气词,即声音顺滑。
//transcriber.addCustomedParam("disfluency",true);
//设置是否开启词模式。
//transcriber.addCustomedParam("enable_words",true);
//设置vad噪音阈值参数,参数取值为-1~+1,如-0.9、-0.8、0.2、0.9。
//取值越趋于-1,判定为语音的概率越大,亦即有可能更多噪声被当成语音被误识别。
//取值越趋于+1,判定为噪音的越多,亦即有可能更多语音段被当成噪音被拒绝识别。
//该参数属高级参数,调整需慎重和重点测试。
//transcriber.addCustomedParam("speech_noise_threshold",0.3);
//设置训练后的定制语言模型id。
//transcriber.addCustomedParam("customization_id","你的定制语言模型id");
//设置训练后的定制热词id。
//transcriber.addCustomedParam("vocabulary_id","你的定制热词id");
//此方法将以上参数设置序列化为JSON发送给服务端,并等待服务端确认。
transcriber.start();
File file = new File(filepath);
FileInputStream fis = new FileInputStream(file);
byte[] b = new byte[3200];
int len;
while ((len = fis.read(b)) > 0) {
logger.info("send data pack length: " + len);
transcriber.send(b, len);
//本案例用读取本地文件的形式模拟实时获取语音流并发送的,因为读取速度较快,这里需要设置sleep。
//如果实时获取语音则无需设置sleep, 如果是8k采样率语音第二个参数设置为8000。
int deltaSleep = getSleepDelta(len, 16000);
Thread.sleep(deltaSleep);
}
//通知服务端语音数据发送完毕,等待服务端处理完成。
long now = System.currentTimeMillis();
logger.info("ASR wait for complete");
transcriber.stop();
logger.info("ASR latency : " + (System.currentTimeMillis() - now) + " ms");
} catch (Exception e) {
System.err.println(e.getMessage());
} finally {
if (null != transcriber) {
transcriber.close();
}
}
}
public void shutdown() {
client.shutdown();
}
public static void main(String[] args) throws Exception {
String appKey = System.getenv().get("NLS_APP_KEY");
String id = System.getenv().get("ALIYUN_AK_ID");
String secret = System.getenv().get("ALIYUN_AK_SECRET");
String url = System.getenv().getOrDefault("NLS_GATEWAY_URL", "wss://nls-gateway-cn-shanghai.aliyuncs.com/ws/v1");
//本案例使用本地文件模拟发送实时流数据。您在实际使用时,可以实时采集或接收语音流并发送到ASR服务端。
String filepath = "nls-sample-16k.wav";
SpeechTranscriberDemo demo = new SpeechTranscriberDemo(appKey, id, secret, url);
demo.process(filepath);
demo.shutdown();
}
}
常见问题
实时流识别模式,Java SDK中如何触发回调onTranscriptionComplete?
在测试实时语音识别和语音合成功能时,对应JAR包在哪里?
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>com.alibaba.nls</groupId>
<artifactId>nls-sdk-java-examples</artifactId>
<version>2.0.0</version>
<relativePath>../pom.xml</relativePath>
</parent>
<groupId>com.alibaba.nls</groupId>
<artifactId>nls-example-tts</artifactId>
<dependencies>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.0.13</version>
</dependency>
<dependency>
<groupId>com.alibaba.nls</groupId>
<artifactId>nls-sdk-tts</artifactId>
<version>${sdk.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<archive>
<manifest>
<mainClass>com.alibaba.nls.client.SpeechSynthesizerMultiThreadDemo</mainClass>
</manifest>
</archive>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id> <!-- this is used for inheritance merges -->
<phase>package</phase> <!-- bind to the packaging phase -->
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>Java SDK实时识别NlsClient类去连接server报错, 提示ERROR NlsClient:102 - failed to connect to server after 3 tries,error msg is :hostname can't be null如何解决?
使用Java Demo识别录音文件没有识别结果,使用文档中的语音文件识别可以正常识别,该如何解决?
您可以使用file命令查看语音格式,检查该格式是否符合产品要求。模型支持的标准8K数据格式为8 kHz采样率、16 bit采样位数、单声道WAV格式;16k语音数据标准格式为16 kHz采样率、16 bit采样位数、单声道WAV格式。如果测试使用,可以使用Sox或者ffmpeg等工具转成标准工具测试;如果线上使用,请参考相关产品说明。
下图以实时语音识别的接口说明为例。