数据对接期
1、什么是场景ID,该如何进行埋点,如何在查询中使用,行为表和内容表场景ID是否需要对应,有什么作用?
举例1.1内容表(item)中有一个itemA,其item_id为1,场景ID字段值为:1001,1002行为表(behavior)中有两条行为,分别为item_id=1,scene_id=1001,bhv_type=click;item_id=1,scene_id=1002,bhv_type=expose
场景是指物品投放的不同地方,可以理解成是对物品的一个分类。如果您没有多场景需求,将该字段(scene_id)置为空即可。如果进行埋点请阅读数据埋点中场景ID埋点部分。
一个物品可以在多个场景投放,需要在scene_id字段指定时用逗号隔开
查询中如果有多场景ID,则在参数scene_id中带上需要投放的ID即可。如果没有多场景,则不用填充此参数。详情参照获取推荐结果。
查询时如果带上1001,则可能会召回该物品(跟进算法模型决定是否推荐该物品),如果带上1003,则永远不会召回该物品
2、如何确定数据上传成功,如何查询已经上传的数据?
SDK返回结果为true则意味的消息发送成功。是否正确执行,需要通过更新记录查询、数据表查询等功能进行确认。详情文档请见:基础配置-数据源-数据与记录查询
3、类目有什么用处,该如何使用,必须填吗?
类目的合理上报,能提升效果,并能做打散功能。
类目可以仿照淘宝的类目页面,相当于对物品按N级进行归类。目前类目的功能在智能推荐中主要用于打散,也会在排序的时候作为特征考虑到模型中,对算法效果有促进作用。
类目的使用需要视用户的业务逻辑,如果没有打散需求,可以置空。如何使用参见数据规范中对类目相关字段的解释,如果埋点参见数据埋点指南,打散功能参见通过实例运营策略提升推荐结果多样性。
4、我的数据还没有准备好,如何快速通过构造的数据启动服务,测试相关的SDK?
智能推荐服务提供了可以用来测试的全量数据,可以从如下链接下载对应的数据,用以启动服务,快速测试SDK的推送和查询等相关功能。测试完毕后,可以通过新建数据版本的方式更换掉测试的全量数据,也可以直接通过增量的方式,推送覆盖原来的测试数据。
5、如何设置tag字段,用户表和物品表中的tag是需要相互关联的吗?
用户A运营了电商类的APP,自己的运营团队维护了一个标签池:红色,黄色,黑色,休闲,正装等。用来定位其商品和用户的偏好。
用户表和物品表中的tag字段是相关联的,其tag池数量建议不要超过50000。
对于传给智能推荐的user和item表,其使用的tag标签需要出自同一个标签池,所有标签个数建议不要大于50000
TAG字段主要是用户对user,item的一种画像的定义,由用户的算法团队或者运营团队人工加上的标签,也可以是user注册时自己选择的。智能推荐算法训练时,会将tag作为输入信息的一种。合理的标签,会对算法效果有正向促进的作用。
如果一个user的标签tag是黑色,正装。那么智能推荐系统会更偏向于向该用户推荐具有该标签的商品。这是一个正向促进的作用。
6、add和update操作的区别是什么?
add为新增操作,update为更新操作。
add操作将新增一条数据,若已存在则替换原本数据。新增数据需提交主键(item_id和item_type)以及全部字段信息。
update操作将更新一条已有数据,确认主键(item_id和item_type)后仅上传待更新字段即可,其他字段可以不上传。如果用update操作更新一条不存在的数据,将有可能导致数据缺失,引发不可预期的问题,因此不可把update当作add使用。
7、标签的数据怎么传?
多个标签通过逗号分隔。单条内容标签数不能超过100个,标签池总个数建议不要超过50000。
8、feature,feature_num是什么含义?
feature:字符串型描述性物料特征。
feature_num:数值型物料特征。自定义的字段特征可传到这两个字段之中。
9、item_type没有我的数据类型,怎么办?
当前已有的类型为:image、article、video、shortvideo、item、recipe、audio。
如果已有的类型中有没用到的,比如audio没用到,想要的类型为专题合辑,那么就用audio代表专题合辑。
10、traceinfo是什么?从哪里拿到?有什么作用?
①trace_info是什么:推荐链路跟踪信息。
②从哪里可以获取到:通过服务端SDK从AIRec获取推荐结果。
③trace_info如何使用:获取后,当推荐出来的item_id被用户产生了行为,需要在上报该条行为数据时,将此trace_info字段原样上报到行为表中。
④trace_info的作用:主要用于智能推荐的算法工程师进行模型调优与排查。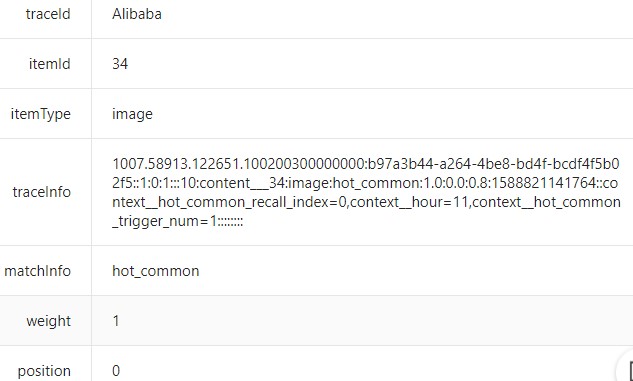
11、什么是正例数据,什么是负例数据?
正例数据指的是用户的正向反馈行为,主要是点击,点赞,购买等。初始化的时候必须有点击。
负例数据主要是的是曝光,expose。(如该内容仅有曝光而并未发生点击、点赞等行为,即认为负例的反馈。曝光、点击行为为必传行为。)
12、用户、物品、行为都需要实时上报吗?为什么?
用户和物品和行为的增量/存量数据都需要实时上报。
不实时上报的影响:行为数据:因为是实时链路,不实时上报的话做不到实时反馈。用户数据:如果有新用户没及时上报,带着新用户的ID来请求智能推荐的时候无法更精准地进行推荐。物品数据:建议是实时的。有变动的物品信息要实时更新。
13、切换标准版服务需要重新传数据吗?
不用。用入门版测试,如果想迁移正式环境直接升配,平滑升级。
14、通过服务端SDK推动数据的常见错误
①ClientException: DocumentError.MissingField : Missing fields, field names: item_id问题原因:没有上传必填字段如item_id,或者是上传过来的必填字段为空字符串。
②ClientException: BadFormat : null问题原因:需要您检查上报过来的JSON字符串是否拼接错误,导致JSON parse失败。
③ClientException: InstanceNotExist : The specified instance does not exist问题原因:1、实例还未启动成功2、推送数据代码中的region区域写错,需要改成已购实例所在区域。
④ServerException:FetchDocumentBackendError:Internal server error问题原因:请检查传过来的JSON数据中固定的字符串是否拼写错误,如field错写成了filed。
15、埋点逻辑暂时无法提供曝光或trace_info数据怎么办?
如您的应用埋点逻辑暂时不支持获取到曝光数据或无法回传traceinfo数据,我们也提供了可由AIRec自行处理,不需要您来上传数据的功能,曝光数据与trace_info数据可分别进行设置:
对曝光行为数据特殊处理:
曝光行为数据是指:“推荐的商品在用户浏览的feed流中出现一定时间并确保被用户看到”的行为返回的数据。曝光数据作为用户后续任何行为数据的前提,对于智能推荐算法来说是必须的,但如果您暂时没有办法提供准确的曝光数据,您可以选择让AIRec智能推荐自动补足曝光数据,以快速启动实例。 如您需要开启此功能:
操作设置:
在智能推荐控制台中,点击数据源:
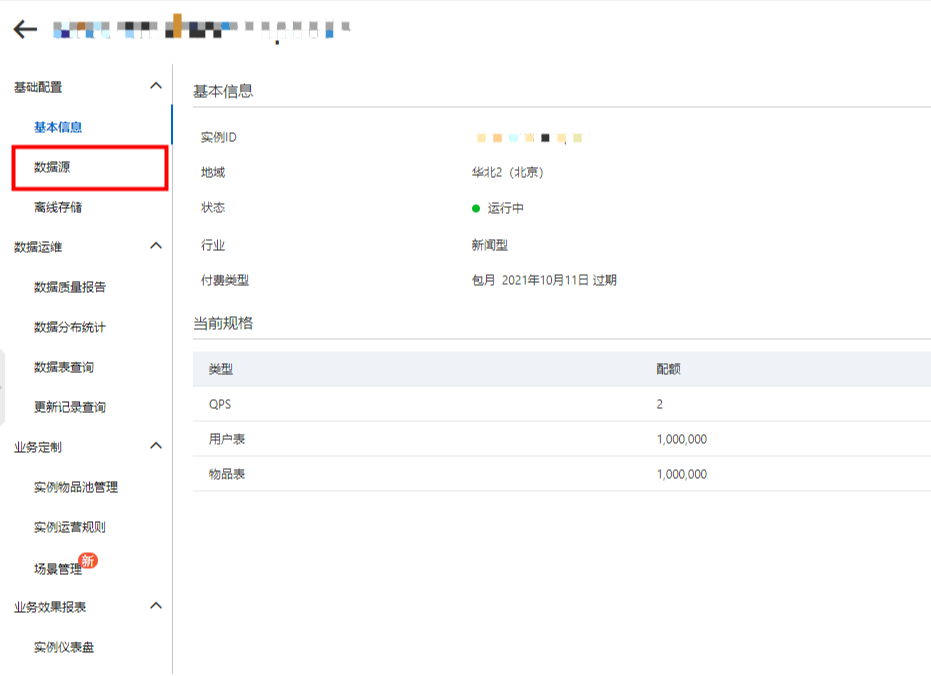
点击实时数据源展开分页,即可看到功能开关:

点击“否,需要特殊处理”
对trace_info数据特殊处理:
trace_info数据用于在模型计算时,区分出用户行为是否是在基于智能推荐提供的推荐结果的基础上进行的点击等操作,并用此进一步对推荐算法进行迭代更新,如果您暂时没有办法提供准确的traceInfo数据,您可以选择让AIRec智能推荐自动补足traceInfo数据,以快速启动实例
(trace_info数据详解可见上文问题10)
如您需要开启此功能:
操作设置:
在智能推荐控制台中,点击数据源:
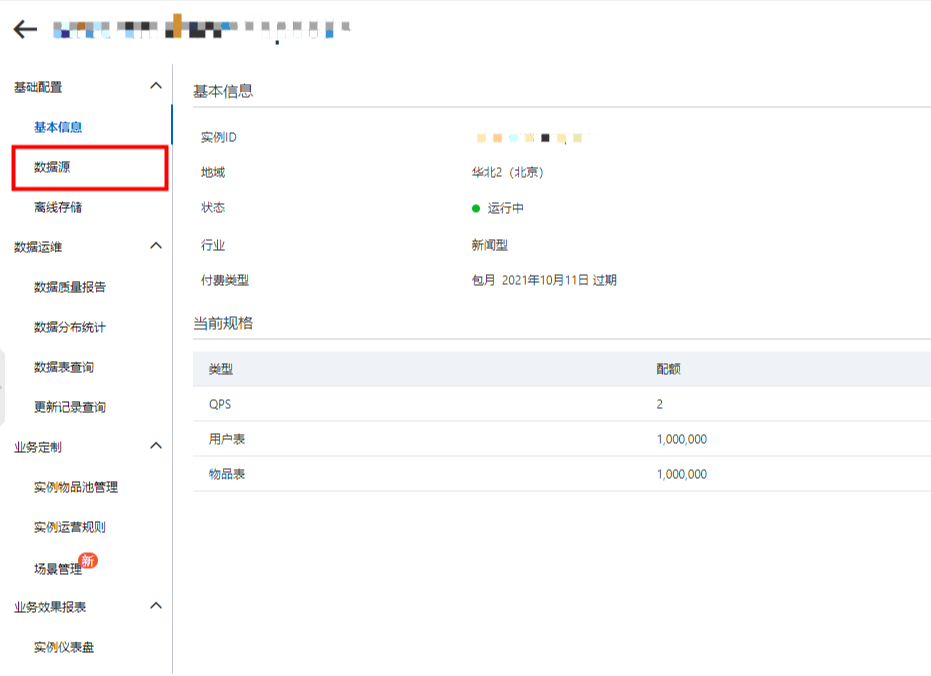 点击实时数据源展开分页,即可看到功能开关:
点击实时数据源展开分页,即可看到功能开关:
点击“否,需要特殊处理”即可开启功能,智能推荐会自行处理相关数据。