
数据埋点指南
本文通过新闻行业举例说明,智能推荐适合什么样的场景,需要怎么样的埋点数据进行模型训练。
使用业务场景
以智能推荐的猜你喜欢、新闻行业为例,适用于首页的feed流推荐,以优化用户的点击率为主。如下图所示:
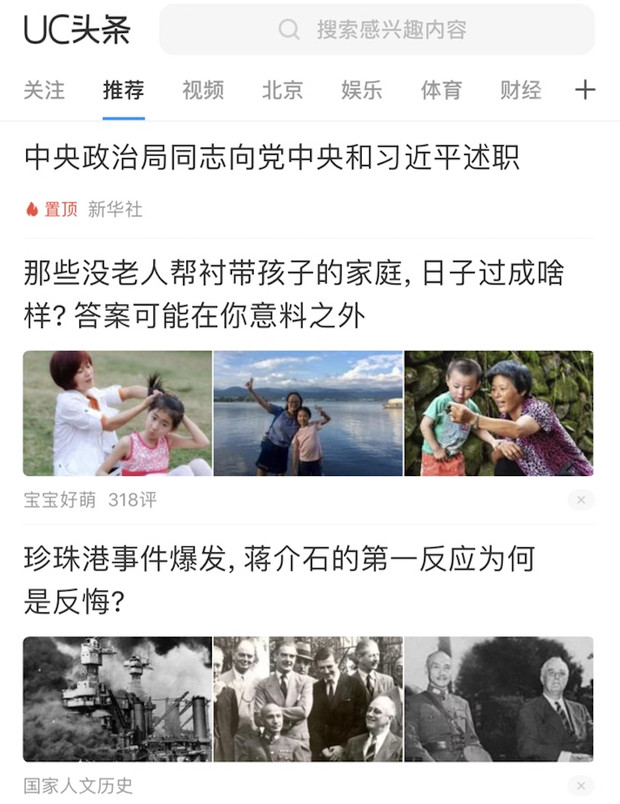
目的为通过终端用户的浏览行为,引导终端用户点击阅读feed流中推荐的内容,并在浏览深度,停留时长等相关指标有一定的促进。
训练数据
内容表
是需要向终端用户推荐的具体的内容,购买了AIRec的企业客户需要将所有需要推荐的内容,上传到内容表中。智能推荐通过模型训练,返回给每一个具体终端用户最合适的item内容。我们建议您提供有效内容的数据,这样能尽量避免无效数据而形成的影响,这对推荐效果的提升,有显著的帮助。
用户表
需要将阅读新闻的每一个终端用户相关信息,上传到用户表中,智能推荐会训练不同终端用户的喜好行为,为其推荐出最感兴趣的内容。
行为表
需要将终端用户产生的行为数据,上传到behavior表中,这部分内容是智能推荐训练模型的核心要素,脏数据会严重影响模型训练结果。行为数据如下图举例所示:
step1:打开频道
step2:点击itemC,进入详情页

用户进行了如上操作后,产生了4条推荐相关的行为:对3条item的曝光行为,对itemA的点击行为。需要将此4条行为分别记录,并按要求上传到智能推荐系统中。
埋点数据
曝光行为埋点
什么是曝光行为
曝光对应的是行为(behavior)表的bhv_type字段,是上传用户行为的一种类型。一条数据展示给用户一次,就算做一条曝光行为。
如何埋点
曝光行为主要在客户端进行埋点,举例如下:
如上图,用户浏览首页,产生了对itemA、itemB和itemC的曝光行为,需要埋点加以记录。
埋点注意事项
一条数据定位曝光行为,需要满足以下3个要素:
需要是在客户端有展示透出的行为(也就是用户可以直观的看到);
需要有一定的停留时长(比如1s);
短时间内对同一个用户的反复曝光,不应累积,只算1次。
埋点反例
1、对于用户在客户端首页的上下滑动,不应累积曝光。—- 不满足上述的第3条要素,如下图

页面下滑后:
之后用户再次上滑:

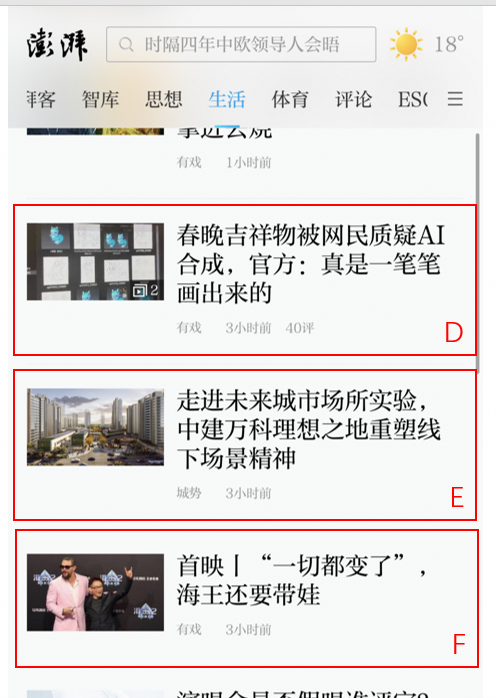

此时,所有的item(A-F)都应该分别只算做1次曝光行为(尤其是A-D,只算1次)。也就是说,只需要传给智能推荐系统6条曝光行为数据(每条数据对应1个item)。
2、对于用户从feed流点击进入详情页,再返回feed流首页,也不应累积曝光。—-不满足第3条要素。
如:
用户点击

之后返回上图1feed流。
此时,item(A-C)分别只产生了1次曝光(其中C还产生了一次点击)。需要传给智能推荐4条行为数据(A,B,C的曝光 + C的点击)
点击行为埋点
什么是点击行为
点击行为相对比较好理解,只要用户对某一个item点击阅读详情,均算作一次点击。
如何埋点
点击行为主要在客户端进行埋点,举例如下:
在feed流页面,点击C内容
进入详情页:

如上行为,用户对itemA的阅读,算是对itemA的一次点击行为。
埋点注意事项
一条数据定位点击行为,需要满足以下3个要素:
1、需要在客户端,用户产生有效的点击行为。
2、点击行为对点击后阅读时长不做限制。
3、短时间内同一用户的多次点击,不应累积,只算1次。
场景ID埋点
什么是场景
场景对应的是内容(item)表和行为(behavior)表中scene_id字段,是指数据投放的不同场景,可以理解成是对数据的一个分类。
如何埋点
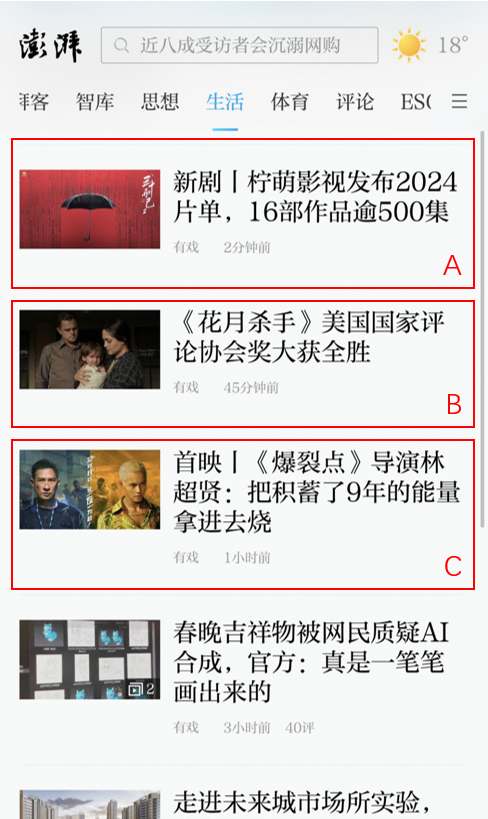
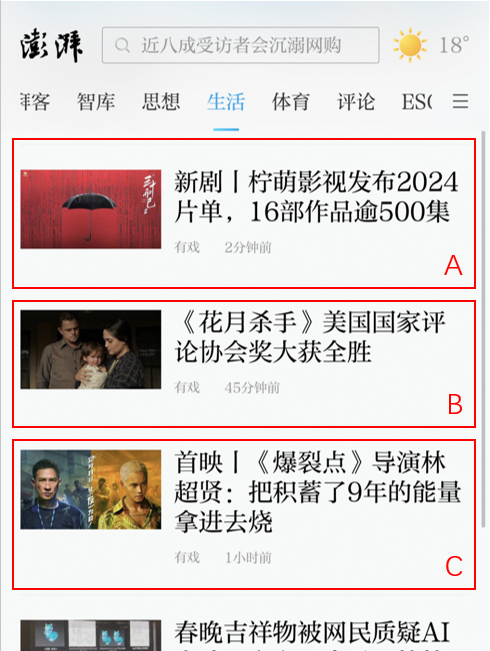
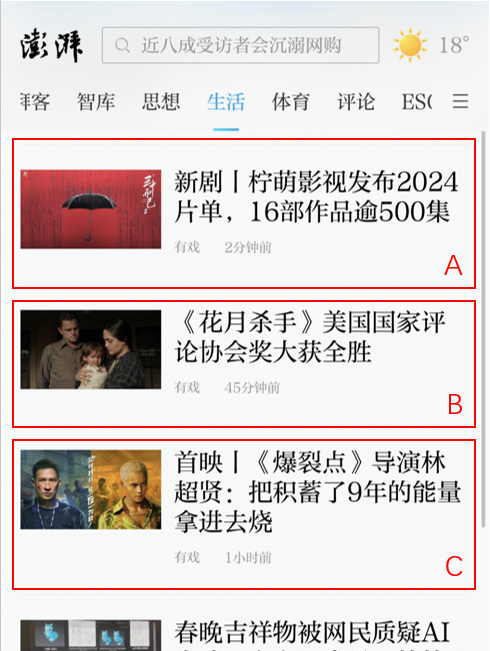
场景的埋点内容(item)主要在客户的服务器端对item进行分类,行为(behavior)主要在客户端对指定投放场景的记录。举例如下:
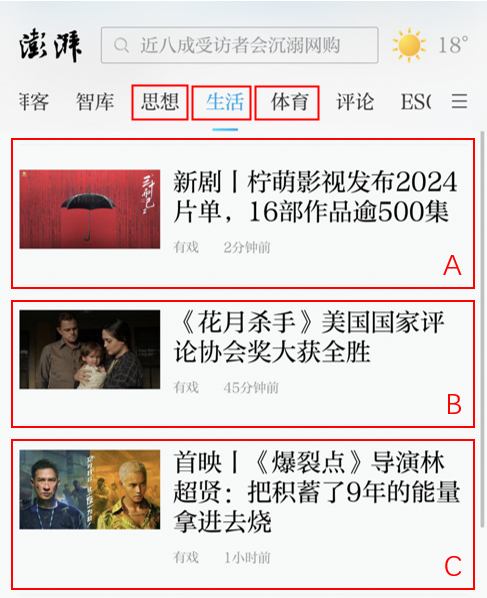
如上图,假设有“思想”、“生活”、“体育”3个场景接入了推荐系统,我们分别定义三个场景的ID为1,2,3(可自定义)。则所有在对应场景下产生的行为以及数据,均需要埋点记录对应的scene_id,并回传到智能推荐系统中,数据区别大致如下。
item表数据为
A:
item_id:itemA, scene_id:2
B:
item_id: itemB, scene_id:2
C:
item_id: itemC, scene_id:2
behavior表数据为
type:expose,scene_id:2,item_id: itemA
type:expose,scene_id:2,item_id: itemB
type:expose,scene_id:2,item_id: itemC
埋点注意事项
场景ID只是用来区分item(内容)所投放到前端的产品场景,理论上只要能明确的区分不同场景即可,不体现场景的父子关系。如:体育频道下可能您会有最新比分、赛事预告、赛事点评等,针对这种情况,我们不建议使用场景ID区分,可以使用下文提到的类目进行划分。
如何使用
在通过服务端SDK获取推荐结果时,需要带上对应的scene_id,展示对应的场景下的结果。对于有些用户会有首页的推荐需求:
1、首页没有自己的item数据。
2、希望首页展示的是多个场景下聚合的item数据。如下图中每个tag页为一个不同场景:
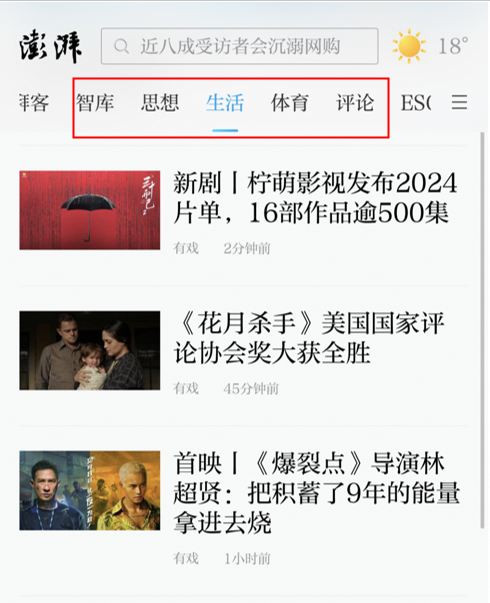
总结来说:召回用什么场景ID,回传行为的时候就回传什么ID
TAGS埋点
什么是tags
TAGS对应的是user表和item表中的tags字段,是指您对内容(item)提炼的特征的文本描述,多个tags之间直接以英文逗号分隔。
如何埋点
tags的埋点主要在服务器端或者人工运营,算法团队,对内容(item)进行的提炼,举例如下:
如上图,可以对该item提炼出:SUV,丰田,汉兰达等相关tag,并以英文逗号分隔方式,传入item表中。
类目层级埋点
什么是类目层级
类目层级对应的是内容(item)表中的category_path和category_level字段,主要作用是对相同主题和属性的内容(item)进行归类,在通过实例运营策略提升推荐结果多样性(见下文解释)中会使用到。
如何埋点
类目层级的埋点主要在服务器端,对内容(item)进行归类,举例如下:
(仅对关键字段举例)
item_id | category_path(类目分类) | category_level |
A | 足球_中超 | 2 |
B | 篮球_CBA | 2 |
C | 足球_恒大 | 2 |
对相关场景下的分类后,对应item的埋点数据填写如上所示。
失效时间埋点
什么是失效时间
失效时间对应的是内容(item)表中的expire_time字段,用来定义本条数据的过期时间。当服务器的时间大于该值时,本条数据将强制不被推荐。
如何埋点
失效时间的埋点主要在服务器端,按某一系统规则自动或者由人工设置。
埋点注意事项
1、如果本条内容(item)没有失效时间,则上传的对应字段置为空即可;
2、失效时间需要以时间戳方式提供,单位为秒(s);
3、如果第一次上传的所有数据均过期,服务无法启动。
STATUS埋点
什么是status
status对应的是内容(item)表中的status字段,用来定义本条数据是否可推荐(0:不可推荐,1:可推荐)。
如何埋点
status的埋点主要在服务器端,按某一系统规则自动或者由人工设置。
埋点注意事项
1、内容(item)表中的status字段为必填项,无法置为空;
2、第一次上传数据时,如果全部内容(item)的status埋点数据为0,则服务无法启动。
相关概念
feed流:是一种给用户持续提供内容的数据形式。
浏览深度:在一个计算周期内,每个访问次数给统计对象所带来的页面浏览量和均值。
停留时长:用户在某一个页面停留的时间。
打散:一次推荐查询中,返回的推荐结果包含多类目数据。