
GPU 多机训练的瓶颈常在节点间通信,RoCE、InfiniBand 专网又成本高昂。在搭载 GPU 的集群上启用阿里云弹性 RDMA(eRDMA),无需专网即可在 VPC 内获得高吞吐、低延迟通信,配合 Arena 提交 PyTorch 分布式作业加速训练。
适用范围
集群类型:仅支持 ACK托管集群 Pro 版。
集群版本:≥ 1.26。
GPU 实例规格:L20N(对应 ECS 实例规格ecs.ebmgn9g、ecs.ebmgn9gc、ecs.ebmgn9ge),默认配备弹性 RDMA(eRDMA)网卡。
方案说明
eRDMA 在普通 VPC 网络下提供 RDMA 直通能力,可绕过内核协议栈直接进行节点间内存读写,显著降低通信延迟、提升吞吐,从而缓解多机训练的网络瓶颈。
本文的整体操作流程如下:
安装 ACK eRDMA Controller 组件,使集群能够识别并调度 eRDMA 资源。
创建并配置 GPU 节点池。
验证节点上的 GPU 与 eRDMA 资源。
通过 Arena 提交训练作业并验证eRDMA加速。
操作步骤
步骤一:安装 ACK eRDMA Controller 组件
请在创建 eRDMA/GPU 节点池前,先安装 ACK eRDMA Controller 组件。若安装组件前集群中已有节点,需先确保节点池已按步骤二配置,再将这些节点从节点池中移除并重新添加,eRDMA 才能生效。
如果集群网络插件为 Terway,还需配置 Terway 的网卡白名单,避免 Terway 修改 eRDMA 网卡。配置方式请参见 为弹性网卡(ENI)配置白名单。
当节点存在多张网卡时,ACK eRDMA Controller 为附加的 eRDMA 网卡配置路由时,默认采用比同网段网卡更低的路由优先级(默认值
200)。如需手动配置网卡,请注意避免路由冲突。
登录容器服务管理控制台,在左侧导航栏选择集群列表。
在集群列表页面,单击目标集群名称,然后在左侧导航栏,单击组件管理。
在组件管理页面,单击网络页签,定位 ACK eRDMA Controller 组件,按照页面提示配置组件并完成安装。主要配置项如下:
配置项
说明
preferDriver(驱动类型)
选择集群节点上使用的 eRDMA 驱动类型。GPU场景需选择
ofed。关于驱动类型的详细说明,请参见 启用eRDMA。
是否为Pod分配节点全部eRDMA设备
可选值:
True(勾选):为 Pod 分配节点上所有 eRDMA 设备。GPU场景需勾选。
False(不勾选):Pod 根据 NUMA 拓扑分配一个 eRDMA 设备。节点需开启 CPU Static Policy 才能保证 Pod 和设备的固定 NUMA 分配。配置方式请参见 创建和管理节点池。
安装完成后,在左侧导航栏选择,选择命名空间 ack-erdma-controller,查看 Pod 运行状态,确认组件运行正常。
步骤二:创建并配置 GPU 节点池
登录容器服务管理控制台,在左侧导航栏选择集群列表。
在集群列表页面,单击目标集群名称,然后在左侧导航栏,选择。
单击创建节点池,主要配置如下。更多配置,请参考创建和管理节点池。
配置节点池镜像:在参数栏,选择云市场镜像中的 Alibaba Cloud Linux 3 64 位(预装 eRDMA 软件栈)镜像,该镜像使用cgroup v2。不同可用区的镜像 ID 与版本信息请参考云市场镜像详情。
配置 GPU 节点驱动版本:在参数栏添加标签,键为
ack.aliyun.com/nvidia-driver-version,值为580.126.09。配置关闭 PCIe ACS (Access Control Services) 功能的脚本:关闭 PCIe ACS 可提升 GPU 与 eRDMA 网卡间的 P2P 通信能力。在中填写以下脚本,使节点在启动时自动关闭 PCIe ACS。
config_disable_acs_service(){ cat << 'EOF' > /usr/bin/disable_pcie_acs #!/bin/bash ret=0 found_acs_pci=0 for BDF in $(lspci -d "*:*:*" | awk '{print $1}'); do # skip if it doesn't support ACS setpci -v -s ${BDF} ECAP_ACS+0x6.w > /dev/null 2>&1 if [ $? -ne 0 ]; then continue else found_acs_pci=1 setpci -v -s ${BDF} ECAP_ACS+0x6.w=0000 if [ $? -eq 0 ]; then echo "[SUCCESS] Disabled ACS on ${BDF}" else echo "[ERROR] Failed to Disable ACS on ${BDF}" ((ret++)) fi fi done if [ $found_acs_pci -eq 0 ]; then echo "[SKIP] no device found that supports ACS" fi exit $ret EOF chmod +x /usr/bin/disable_pcie_acs # 创建 systemd service 文件 cat << 'EOF' > /etc/systemd/system/disable_pcie_acs.service [Unit] Description=Disable PCIe Access Control Services (ACS) After=multi-user.target [Service] Type=oneshot ExecStart=/usr/bin/disable_pcie_acs RemainAfterExit=yes [Install] WantedBy=multi-user.target EOF # 重新加载 systemd 配置并设置开机自启动 systemctl daemon-reload systemctl enable disable_pcie_acs.service systemctl start disable_pcie_acs.service echo "disable_pcie_acs service has been configured and enabled for auto-start" } config_disable_acs_service节点创建完成后,可登录节点执行
lspci -vvv | grep ACSCtl确认 PCIe ACS 状态:输出包含SrcValid-表示 PCIe ACS 已关闭,SrcValid+表示仍处于开启状态,需重新检查脚本是否生效。说明ecs.ebmgn9g、ecs.ebmgn9gc、ecs.ebmgn9ge 实例的 GPU 之间没有 NVLink、NVSwitch 高速互联,机内卡间通信默认通过 PCIe 进行,效率远低于 NVLink/NVSwitch。因此除了跨节点通过 eRDMA 加速外,还需关闭 PCIe ACS,以提升机内 GPU 与 eRDMA 网卡间的 P2P 通信能力。
步骤三:验证节点 eRDMA 资源
节点池创建完成后,确认节点上的 GPU 和 eRDMA 资源已正确识别并可被调度。
方法一:连接集群,使用 kubectl 连接集群并执行以下命令查看节点的可分配资源。
kubectl get node <节点名称> -o jsonpath='{.status.allocatable}'预期输出如下,表明节点已成功上报 GPU 和 eRDMA 资源:
{"aliyun/erdma":"400","cpu":"15890m","ephemeral-storage":"243149919035","hugepages-1Gi":"0","hugepages-2Mi":"0","memory":"128290128Ki","nvidia.com/gpu":"1","pods":"64"}"nvidia.com/gpu":"1":表示可用的 GPU 数量为 1。"aliyun/erdma":"400":表示该节点可分配 400 份 eRDMA 资源。
方法二:登录支持 eRDMA 的节点,执行以下命令查看 eRDMA 设备信息。
ibv_devinfo预期输出中显示
erdma_0与erdma_1两个设备且端口状态均为PORT_ACTIVE,表示 eRDMA 设备已正常启用。
步骤四:(可选)安装 ACK KubeSkoop 组件并配置 eRDMA 监控
如需在训练过程中监控 eRDMA 网卡流量,安装ACK KubeSkoop 组件并接入监控。安装需在提交训练作业前完成,以便采集到完整的流量数据。
在集群列表页面,单击目标集群名称,然后在左侧导航栏,单击组件管理。
在组件管理页面,单击网络页签,定位 ACK KubeSkoop 组件,按照页面提示配置组件并完成安装。
安装完成后,在左侧导航栏选择,选择命名空间
ack-kubeskoop,查看 Pod 运行状态,确认组件运行正常。然后访问ARMS控制台接入中心功能,搜索 ACK KubeSkoop 网络监控,选定目标集群并完成监控接入。
步骤五:通过 Arena 提交训练作业
使用 Arena 提交 PyTorch 分布式训练作业,并申请 eRDMA 资源加速节点间通信。
配置Arena客户端 并提交训练作业。更多参数,请参见 Arena提交作业核心参数说明。
创建两个分别命名为
mymodels和myworkspace的 OSS PVC 实例,分别存放模型,以及训练输出和配置文件。
本文基于 ms-swift 4.2.0 官方镜像并为其添加 eRDMA 支持,镜像构建方法请参见构建生产环境支持 eRDMA 的容器镜像。训练方式为两节点使用 GRPO 对 Qwen/Qwen3.5-35B-A3B 模型进行强化学习微调。
训练过程中如遇问题,请参考常见问题。NCCL 环境变量的完整说明请参见附录。
arena submit pytorch \
--name=pytorch-swift \
--namespace=default \
--workers=2 \
--gpus=8 \
--share-memory=1000Gi \
--device=aliyun/erdma=2 \
--nproc-per-node=8 \
--env=UCX_TLS=tcp \
--env=UCX_NET_DEVICES=eth0 \
--env=NCCL_SOCKET_IFNAME=eth0 \
--env=NCCL_IB_HCA=erdma_0,erdma_1 \
--env=NCCL_IB_DISABLE=0 \
--env=NCCL_IB_GID_INDEX=1 \
--env=NCCL_NET_GDR_LEVEL=SYS \
--env=NCCL_P2P_LEVEL=SYS \
--env=NCCL_GIN_TYPE=0 \
--env=FLA_TILELANG=0 \
--env=VLLM_MOE_BACKEND=triton \
--data=mymodels:/models \
--data=myworkspace:/workspace \
--clean-task-policy=None \
--image=kube-ai-registry.cn-shanghai.cr.aliyuncs.com/kube-ai/swift:ubuntu22.04-cuda13.0.3-py312-torch2.11.0-vllm0.20.1-modelscope1.36.3-erdma \
--image-pull-policy=Always \
--tensorboard \
--logdir=/workspace/logs \
"export NNODES=\$PET_NNODES \
MASTER_ADDR=\$PET_MASTER_ADDR \
MASTER_PORT=\$PET_MASTER_PORT \
NPROC_PER_NODE=\$PET_NPROC_PER_NODE \
NODE_RANK=\$PET_NODE_RANK && \
megatron rlhf \
--rlhf_type grpo \
--model /models/Qwen/Qwen3.5-35B-A3B \
--dataset open-r1/DAPO-Math-17k-Processed \
--tuner_type full \
--packing true \
--enable_thinking false \
--max_length 2048 \
--global_batch_size 32 \
--micro_batch_size 1 \
--num_generations 8 \
--max_completion_length 512 \
--tensor_model_parallel_size 4 \
--expert_tensor_parallel_size 1 \
--expert_model_parallel_size 8 \
--sequence_parallel true \
--optimizer_cpu_offload true \
--optimizer_offload_fraction 1 \
--moe_grouped_gemm true \
--moe_permute_fusion true \
--reward_funcs accuracy \
--temperature 0.9 \
--train_iters 15 \
--logging_steps 1 \
--lr 5e-5 \
--beta 0.04 \
--epsilon 0.2 \
--epsilon_high 0.28 \
--attention_backend flash \
--recompute_granularity full \
--recompute_method uniform \
--recompute_num_layers 1 \
--dataloader_num_workers 4 \
--dataloader_pin_memory true \
--no_save_optim true \
--no_save_rng true \
--use_vllm true \
--vllm_mode colocate \
--vllm_gpu_memory_utilization 0.3 \
--vllm_tensor_parallel_size 8 \
--vllm_enforce_eager true \
--vllm_max_model_len 2048 \
--sleep_level 2 \
--output_dir /workspace/output \
--tensorboard_dir /workspace/logs"在 ecs.ebmgn9g、ecs.ebmgn9gc、ecs.ebmgn9ge 实例规格上,NCCL 需要手动指定通信拓扑图文件以保证通信效率。请将拓扑图文件保存到镜像内的绝对路径,并通过 --env=NCCL_GRAPH_FILE=<拓扑图文件绝对路径> 传入。拓扑图文件的获取方式请参见NCCL 环境变量配置。
步骤六:验证训练作业与 eRDMA 加速
确认训练作业已成功启动,并验证 eRDMA 网络已生效。
查看 Master Pod 的日志,日志中显示训练 iteration 信息,说明训练作业正常运行。
kubectl logs pytorch-swift-worker-0 | head -n 50验证 eRDMA 是否生效。在上述 Pod 日志中查找关键信息
Using network IB,如果出现此行,表示节点间通信已通过 eRDMA 加速。
步骤七:(可选)监控 eRDMA 网卡流量
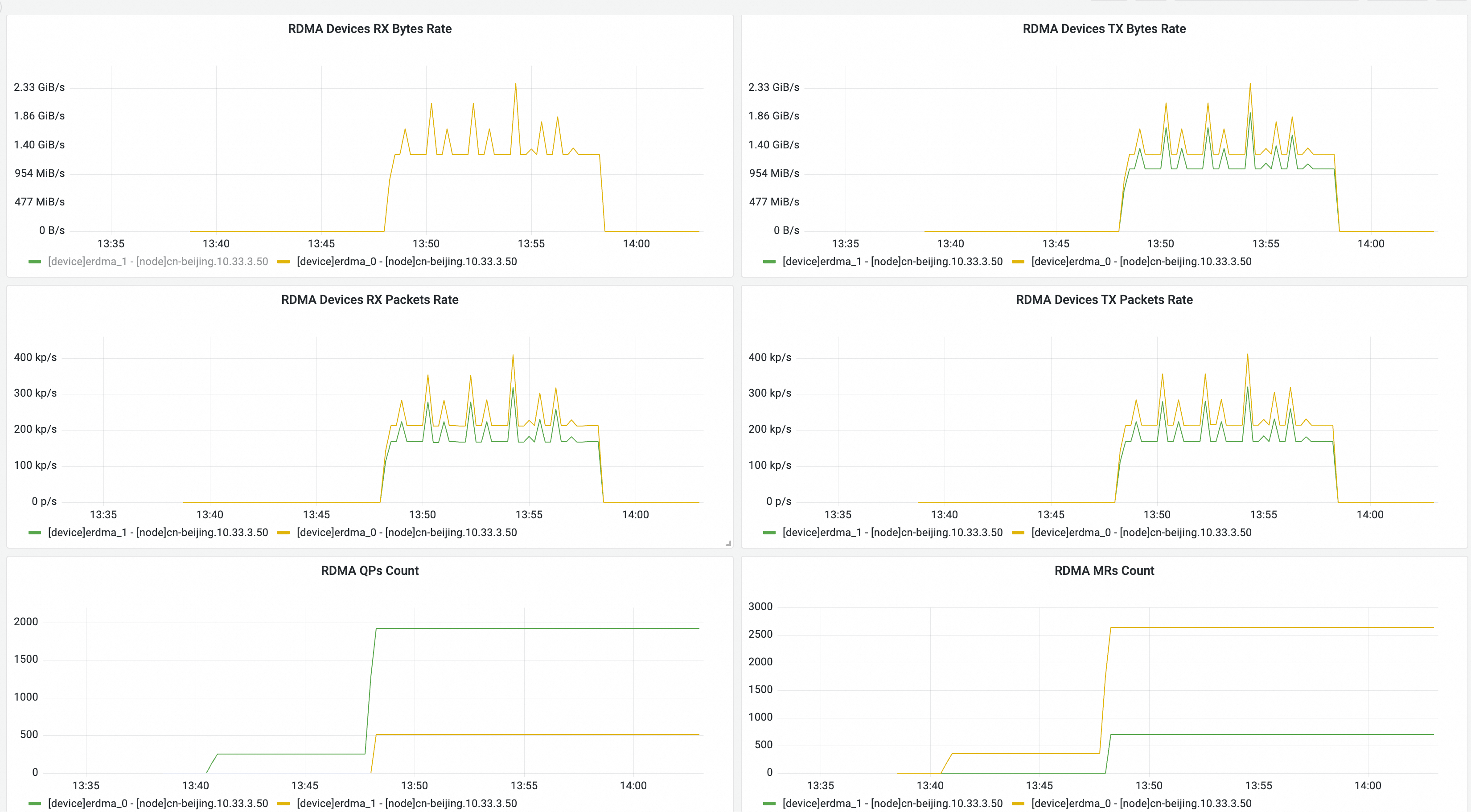
如已在步骤四中安装 KubeSkoop 组件,可实时监控 eRDMA 网卡的网络流量,验证数据传输情况。
访问 ARMS控制台接入管理功能,在已接入环境中选择目标集群,单击组件管理中的 ACK KubeSkoop 网络监控,可分别查看 Node 和 Pod 级别的监控大盘。
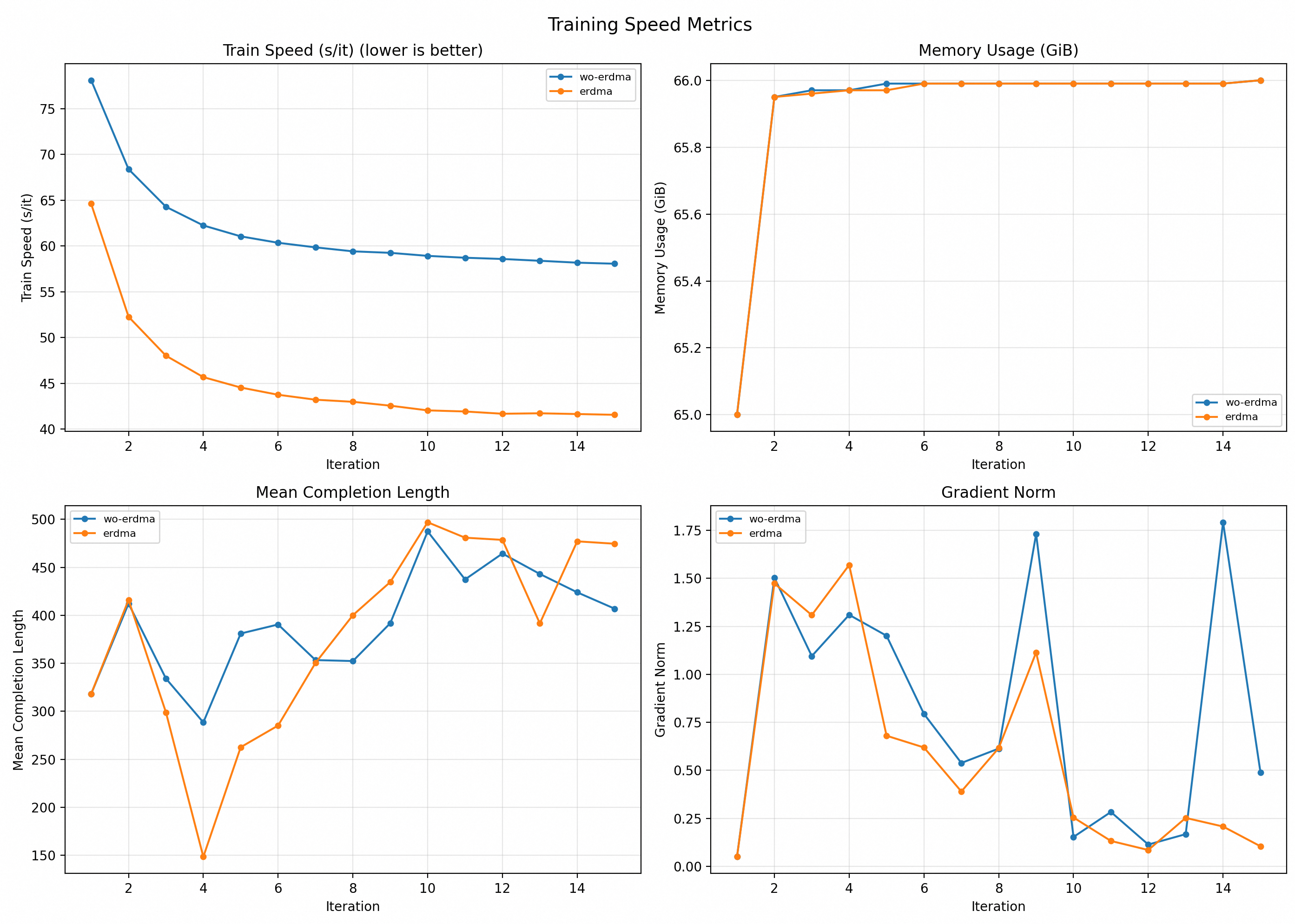
性能对比
通过记录训练任务的相关指标和日志,对比开启 eRDMA 前后的训练性能。从下图可得,使用 eRDMA 的训练任务,其迭代时间相比未使用 eRDMA 时最多有超过 28% 的降幅。
为更清晰地对比 eRDMA 开启前后的性能差异,以下两组训练任务在执行前均进行了相同轮次的 warmup。本文性能数据基于特定实验室环境测得,实际性能因模型、规格、数据集与网络状况等因素而异,仅供参考。
ACK 集群提供 AI Profiling 功能,可从 Torch、Python 和 CUDA Kernel 多个层面分析训练性能,深入定位计算、通信和内存使用上的瓶颈。
清理资源
训练作业完成后,执行以下命令删除作业。此操作将删除作业相关的所有 Pod 和资源,但不会删除 TensorBoard 日志等持久化数据。
arena delete pytorch-swift -n default预期输出:
INFO[0001] The training job pytorch-swift has been deleted successfully常见问题
为什么日志中没有显示 NET/IB : Using erdma_0?
可能的原因包括:
未在提交命令中添加
--device=aliyun/erdma=2参数。节点不支持 eRDMA,或 eRDMA Controller 组件未正确安装。
容器镜像中缺少 RDMA 用户态库(libibverbs、librdmacm 等)。
解决方法:
执行
kubectl get node <节点名> -o jsonpath='{.status.allocatable}'确认节点是否有aliyun/erdma资源。登录节点执行
ibv_devinfo检查 eRDMA 设备是否正常。检查容器镜像是否包含必要的 RDMA 库。
训练过程中出现 NCCL timeout 错误怎么办?
NCCL timeout 通常由网络不稳定或配置不当引起。建议:
增加超时时间:设置
--env=NCCL_IB_TIMEOUT=23(默认为 20)。增加重试次数:设置
--env=NCCL_IB_RETRY_CNT=10(默认为 7)。检查节点间的网络连通性和 eRDMA 设备状态。
训练过程中出现 NCCL Cannot allocate memory 错误怎么办?
NCCL Cannot allocate memory 通常由宿主机 ulimit 配置限制造成。建议:
检查节点或节点容器运行时的 ulimit 配置,关注 locked memory、open files、stack size 等字段。请注意,该操作会在节点级别全局生效,可能造成内存碎片。
提升 Pod 的权限级别,并在 Pod 启动参数中自行设置 ulimit 值,可参考如下配置。
重要提升权限操作会引入额外的安全风险,请在完全理解配置后果后谨慎配置。
apiVersion: v1 kind: Pod metadata: name: custom-ulimit spec: containers: - name: configure image: <YOUR_TRAINING_IMAGE> command: - /bin/sh - -c - | ulimit -l unlimited echo "Current memlock limit:" ulimit -l echo "Sleeping..." sleep infinity securityContext: capabilities: add: ["SYS_RESOURCE"]
如何判断 eRDMA 是否真正提升了训练性能?
可以通过以下方式对比:
分别提交使用 eRDMA 和不使用 eRDMA 的训练作业(通过是否添加
--device=aliyun/erdma=2区分)。对比相同训练步数下的完成时间。
使用 AI Profiling 工具分析通信时间占比。
通常在多节点(2 个以上)、模型参数量较大(数十亿参数以上)的场景下,eRDMA 的性能提升最为明显。
Arena 提交作业失败,提示资源不足怎么办?
可能的原因包括:
GPU 或 eRDMA 资源不足。
节点不满足调度条件(如节点选择器、污点容忍)。
解决方法:
执行
kubectl get nodes查看节点状态和可用资源。执行
kubectl describe pod <Pod名>查看 Pod 调度失败的详细原因。根据提示调整资源请求或增加节点。
附录
Arena 提交作业核心参数说明
参数 | 说明 | 建议配置 |
| 作业名称,集群内全局唯一 | 使用具有业务含义的名称 |
| 作业所属的命名空间 | 根据团队或项目隔离 |
| Worker 节点数量(包含 Master) | 设置为 2 表示 1 个 Master + 1 个 Worker |
| 每个 Worker 使用的 GPU 卡数 | 根据模型大小和显存需求设置 |
| 启用 eRDMA 的关键参数,为每个 Worker 分配 eRDMA 资源 | 必须设置以启用 eRDMA,ecs.ebmgn9g、ecs.ebmgn9gc、ecs.ebmgn9ge实例规格建议设置为 2 |
| 每个节点启动的训练进程数 | 通常设置为与 |
| Pod 清理策略 | 设置为 |
| 环境变量 | 用于配置 NCCL 通信参数 |
NCCL 环境变量配置
在使用 ecs.ebmgn9g、ecs.ebmgn9gc、ecs.ebmgn9ge实例规格时,针对完整使用整机 8 卡 GPU 和 2 张 eRDMA 网卡的固定通信场景,可使用预设的 NCCL 通信拓扑信息,加快 NCCL 通信初始化过程,避免 NCCL 2.30 及之前版本拓扑探测不准确带来的通信效率问题。通过 NCCL_GRAPH_FILE 环境变量指向拓扑图 XML 文件的绝对路径来使用。请在充分了解 NCCL 通信过程后,结合具体通信场景谨慎使用。
环境变量 | 说明 | 推荐配置 |
| 控制是否禁用 IB/RoCE | eRDMA 场景下设置为 0,排查测试时可设置为 1 |
| 指定用于通信的网卡接口 | 设置为 |
| GPU 与 NIC 间的最大拓扑距离,不超过设定值时使用 GPU Direct RDMA(LOC、PIX、PXB、PHB、SYS,分别对应 0-4) | eRDMA 场景下推荐设置为 |
| GPU 间的最大拓扑距离,不超出设定值时使用点对点通信(LOC: 0、NVL、PIX: 1、PXB: 2、PHB: 3、SYS: 4) | eRDMA 场景下推荐设置为 |
| 集合通信算法 | 可选 |
| 日志级别 | 调试时设置为 |
| 指定使用的 RDMA 网卡 | 通过 |
| IB 通信超时时间 | 根据网络延迟调整 |
| IB 通信失败重试次数 | 不稳定网络可适当增加 |
| 当 P2P 禁用时,控制是否禁用共享内存。禁用则回退到 Socket 通信 | 根据具体环境按需调整 |
| 指定 NCCL 通信拓扑文件的绝对路径 | 根据具体硬件拓扑而定。仅 ecs.ebmgn9g、ecs.ebmgn9gc、ecs.ebmgn9ge 实例规格需使用示例文件 |
更多 NCCL 环境变量说明,请参见 NCCL 官方文档。
参考 Dockerfile
以下 Dockerfile 在 ms-swift 官方镜像基础上安装了 eRDMA 用户态库,可作为自定义训练镜像的参考。
FROM modelscope-registry.cn-beijing.cr.aliyuncs.com/modelscope-repo/modelscope:ubuntu22.04-cuda13.0.3-py312-torch2.11.0-vllm0.20.1-modelscope1.36.3-swift4.2.0
RUN wget -qO - https://mirrors.aliyun.com/erdma/GPGKEY | apt-key add - && echo "deb [ arch=amd64 ] https://mirrors.aliyun.com/erdma/apt/ubuntu jammy/erdma main" | tee /etc/apt/sources.list.d/erdma.list && apt update && apt install -y libibverbs1 ibverbs-providers ibverbs-utils librdmacm1使用 ms-swift 对 Qwen3-4B-Instruct-2507 进行 LoRA 微调
以下示例使用单卡两节点对 Qwen3-4B-Instruct-2507 进行 LoRA 微调,可作为入门验证场景。
arena submit pytorch \
--name=pytorch-swift \
--namespace=default \
--workers=2 \
--gpus=1 \
--nproc-per-node=1 \
--device=aliyun/erdma=1 \
--env=UCX_TLS=tcp \
--env=UCX_NET_DEVICES=eth0 \
--env=NCCL_SOCKET_IFNAME=eth0 \
--env=NCCL_IB_HCA=erdma_0,erdma_1 \
--env=NCCL_IB_DISABLE=0 \
--env=NCCL_IB_GID_INDEX=1 \
--env=NCCL_NET_GDR_LEVEL=SYS \
--env=NCCL_P2P_LEVEL=SYS \
--env=NCCL_GIN_TYPE=0 \
--clean-task-policy=None \
--image=kube-ai-registry.cn-shanghai.cr.aliyuncs.com/kube-ai/swift:ubuntu22.04-cuda13.0.3-py312-torch2.11.0-vllm0.20.1-modelscope1.36.3-erdma \
--image-pull-policy=Always \
--data=mymodels:/models \
--data=myworkspace:/workspace \
--tensorboard \
--logdir=/workspace/logs \
"torchrun \
--master_port \${PET_MASTER_PORT} \
--nproc_per_node=\${PET_NPROC_PER_NODE} \
--nnodes=\${PET_NNODES} \
--node_rank=\${PET_NODE_RANK} \
--master_addr=\${PET_MASTER_ADDR} \
sft.py \
--model /models/Qwen/Qwen3-4B-Instruct-2507 \
--tuner_type lora \
--dataset 'swift/self-cognition#1000' \
--num_train_epochs 1 \
--lora_rank 8 \
--lora_alpha 32 \
--learning_rate 1e-4 \
--gradient_accumulation_steps \$(( 32 / \$PET_NPROC_PER_NODE / \$PET_NNODES )) \
--eval_steps 100 \
--save_steps 100 \
--save_total_limit 2 \
--logging_steps 5 \
--model_author swift \
--model_name swift-robot"