
随着大语言模型(LLM)的广泛应用,如何在生产环境中实现其高效、稳定且大规模的部署与运维,已成为企业面临的核心挑战。云原生 AI 推理套件(AI Serving Stack)基于阿里云容器服务,专为云原生AI推理而设计的端到端解决方案。该套件致力于解决LLM推理的全生命周期问题,提供从部署管理、智能路由、弹性伸缩、深度可观测的一体化能力。无论是刚刚起步还是已经拥有大规模AI业务,云原生AI推理套件都能轻松驾驭复杂的云原生AI推理场景。
核心功能
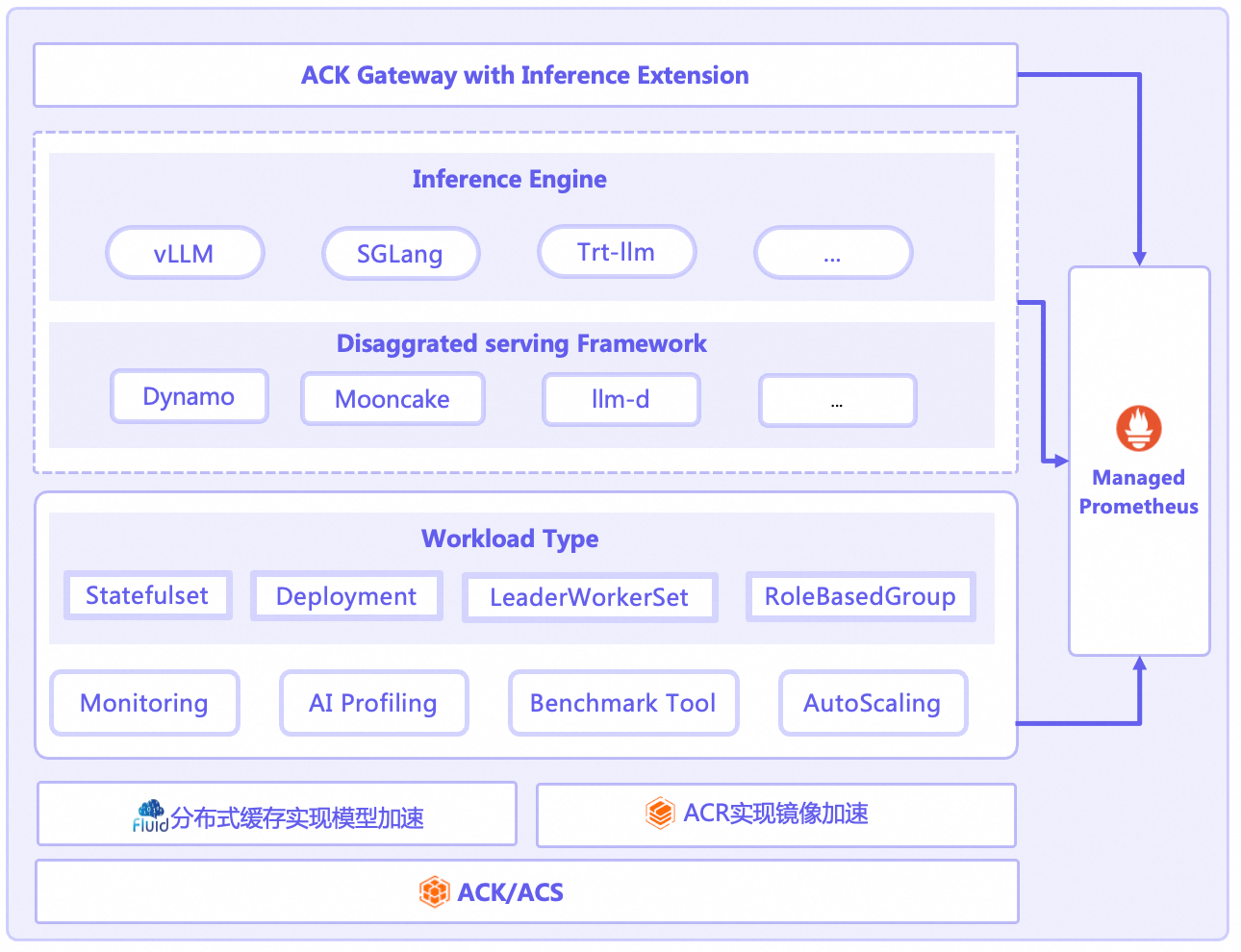
云原生AI推理套件通过其创新的工作负载设计、精细化的弹性能力、深度的可观测性以及强大的扩展机制,为用户在Kubernetes上运行LLM推理服务推理提供了前所未有的便捷与效能。AI推理套件具有以下核心功能。
功能项 | 说明 | 相关文档 |
支持单机LLM推理 | 使用StatefulSet部署LLM推理服务,支持单机单卡和单机多卡部署。 | |
支持多机分布式LLM推理 | 使用LeaderWorkerSet部署多机多卡的分布式推理服务。 | |
支持多种推理引擎的PD分离部署 | 各种推理引擎实现PD分离的架构各不相同,部署方案各异,因此AI推理套件使用RoleBasedGroup作为工作负载,统一部署各种推理引擎的PD分离架构。 | |
弹性扩缩容 | 成本与性能的平衡是LLM服务的关键。AI推理套件提供了业界领先的多维度、多层次弹性伸缩能力。
| |
可观测性 | 黑盒化的推理过程是性能优化的巨大障碍。AI推理套件提供了开箱即用的深度可观测性方案。
| |
推理网关 | ACK Gateway with Inference Extension组件是基于Kubernetes社区Gateway API及其Inference Extension规范实现的增强型组件,支持Kubernetes四层/七层路由服务,并提供面向生成式AI推理场景的一系列增强能力。它能够简化生成式AI推理服务的管理流程,并优化在多个推理服务工作负载之间的负载均衡性能。 | |
模型加速 | 在AI推理场景中,LLM模型加载慢导致应用冷启动耗时高、弹性伸缩受阻等问题。Fluid通过构建分布式缓存将远端模型文件缓存到节点本地,实现极速启动、零冗余、极致弹性。 | |
性能剖析 | 为了进行更深层次的性能分析,可使用AI Profiling工具,它允许开发者在不中断服务、不修改代码的前提下,通过GPU容器进程数据的采集,对在线运行的训练推理服务进行性能观测剖析。
|
免责声明
AI推理套件为开源推理引擎及其PD分离框架提供部署管理的能力,阿里云为AI推理套件提供技术支持,但对于用户在使用过程中因开源引擎和开源PD分离框架本身产生的缺陷从而导致用户业务受损的情况,阿里云不提供赔偿或者补偿等商务服务。