
HPA默认支持基于CPU和内存指标实现自动伸缩,可能无法满足更为复杂的运维场景。如果您需要将Prometheus收集的Custom Metrics与External Metrics转换为HPA可用的弹性伸缩指标,您可以参见本文获取监控数据并实现对应的伸缩配置,为应用提供更灵活、便捷的扩缩机制。
前提条件
已部署阿里云Prometheus监控组件。具体操作,请参见使用阿里云Prometheus监控。
已部署ack-alibaba-cloud-metrics-adapter组件。具体操作,请参见部署ack-alibaba-cloud-metrics-adapter组件。
说明您可以登录容器服务管理控制台,在页面部署ack-alibaba-cloud-metrics-adapter组件。
功能介绍
默认HPA只支持基于CPU和内存的自动伸缩,并不能满足日常的运维需求。阿里云Prometheus监控全面对接开源Prometheus生态,支持类型丰富的组件监控,提供多种开箱即用的预置监控大盘,且提供全面托管的Prometheus服务。此功能主要分为三个步骤:
在ACK集群中使用Prometheus监控透出监控指标。
依托ack-alibaba-cloud-metrics-adapter组件,负责转换Prometheus监控指标为HPA可消费的Kubernetes聚合指标。更多信息,请参见Autoscaling on multiple metrics and custom metrics。
配置并部署HPA,根据上一步的指标进行弹性扩缩。
指标类型根据场景分为两种:
Custom Metric:根据与要进行扩缩的Kubernetes目标对象(例如Pod)相关的指标进行扩缩,例如Pod自身维度的指标。更多信息,请参见autoscaling-on-multiple-metrics-and-custom-metrics。
External Metric:根据与要进行扩缩的Kubernetes目标对象(例如Pod)不相关的指标进行扩缩。例如,通过整体的业务QPS指标来扩缩某一个Workload的Pod。更多信息,请参见autoscaling-on-metrics-not-related-to-kubernetes-objects。
下文介绍如何配置alibaba-cloud-metrics-adapter,实现将阿里云Prometheus指标转换为HPA可用指标,并实现该指标自动伸缩。
步骤一:获取Prometheus监控数据
示例一:使用ACK默认容器监控指标
您可以直接使用ACK默认安装的阿里云Prometheus中的默认指标进行HPA弹性扩缩。支持的指标包括容器监控cAdvisor指标、节点基础监控Node-Exporter、GPU-Exporter指标,以及您当前已接入到阿里云Prometheus中的所有指标。查看已接入阿里云Prometheus的指标的步骤如下:
登录容器服务管理控制台,在左侧导航栏选择集群列表。
在集群列表页面,单击目标集群名称,然后在左侧导航栏,选择。
单击右上角跳转到Prometheus服务。
在Prometheus监控服务控制台的左侧导航栏,单击设置,查看所有已接入阿里云Prometheus的指标。
示例二:通过Pod自身上报的Prometheus指标
部署测试应用,并通过Prometheus标准方式暴露指标。更多信息,请参见metric_type。下文介绍如何部署sample-app应用,并自身透出http_requests_total的指标用来标识访问次数。
部署应用的工作负载。
登录容器服务管理控制台,在左侧导航栏选择集群列表。
在集群列表页面,单击目标集群名称,在左侧导航栏,单击。
在无状态页面右侧,单击使用YAML创建资源,然后在创建页面,示例模板选择自定义,配置以下YAML,单击创建。
添加ServiceMonitor
登录ARMS控制台。
在左侧导航栏,单击接入管理。在已接入环境的容器环境页签下,选择集群所在地域,然后单击对应环境名称(和所创建集群同名)。
在容器环境页面,单击指标采集页签,在当前页面的左侧导航栏,单击ServiceMonitor,然后在ServiceMonitor页面单击新增,最后在新增ServiceMonitor配置页面,单击YAML编辑添加如下ServiceMonitor,完成后单击创建。
apiVersion: monitoring.coreos.com/v1 kind: ServiceMonitor metadata: annotations: arms.prometheus.io/discovery: 'true' name: sample-app namespace: default spec: endpoints: - interval: 30s port: http path: /metrics namespaceSelector: any: true selector: matchLabels: app: sample-app
确认监控状态。
在自监控页签下,单击Targets页签,如果看到default/sample-app/0(1/1 up),则说明您已成功在阿里云Prometheus监控到了部署的应用。
通过在Prometheus大盘中,查询最近时间范围的
http_requests_total数值,确定监控数据已经正确获取。
步骤二:修改ack-alibaba-cloud-metrics-adapter组件配置
登录容器服务管理控制台,在左侧导航栏选择集群列表。
在集群列表页面,单击目标集群名称,在左侧导航栏,单击。
在Helm页面的操作列,单击ack-alibaba-cloud-metrics-adapter对应的更新。
在更新发布面板,配置如下YAML,然后单击确定。
部分字段说明如下。关于ack-alibaba-cloud-adapter配置文件的详细说明,请参见ack-alibaba-cloud-metrics-adapter组件配置文件详解。
字段
说明
AlibabaCloudMetricsAdapter. prometheus.adapter.rules.custom该字段内容请修改为示例YAML中对应的内容。
alibabaCloudMetricsAdapter. prometheus.url填写阿里云Prometheus监控的地址。关于如何获取Prometheus数据请求URL,请参见如何获取Prometheus数据请求URL。
AlibabaCloudMetricsAdapter. prometheus.prometheusHeader[].Authorization填写Token。关于如何获取Token,请参见如何获取Prometheus数据请求URL。
AlibabaCloudMetricsAdapter. prometheus.adapter.rules.default默认创建预置指标,推荐关闭,配置为
false。
配置Metrics-adapter组件参数,并成功部署Metrics-adapter组件后,可通过如下命令查看K8s聚合API是否已经成功接入数据。
通过Custom Metrics进行容器伸缩。
执行以下命令,通过Custom Metrics指标查询方式,查看HPA可用指标的详情和列表。
kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1/" | jq .执行以下命令,查询
http_requests_per_second指标在default命名空间下的当前数值。# 通过查询container_memory_working_set_bytes_per_second查看kube-system namespace中Pod的工作内存当前每秒大小。 kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1/namespaces/kube-system/pods/*/container_memory_working_set_bytes_per_second" # 通过查询container_cpu_usage_core_per_second查看kube-system namespace中Pod的CPU使用核数每秒大小。 kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1/namespaces/kube-system/pods/*/container_cpu_usage_core_per_second"指标查询结果示例:
{ "kind": "MetricValueList", "apiVersion": "custom.metrics.k8s.io/v1beta1", "metadata": { "selfLink": "/apis/custom.metrics.k8s.io/v1beta1/namespaces/kube-system/pods/%2A/container_memory_working_set_bytes_per_second" }, "items": [ { "describedObject": { "kind": "Pod", "namespace": "kube-system", "name": "ack-alibaba-cloud-metrics-adapter-7cf8dcb845-h****", "apiVersion": "/v1" }, "metricName": "container_memory_working_set_bytes_per_second", "timestamp": "2023-08-09T06:30:19Z", "value": "24576k", "selector": null } ] }
通过External Metrics进行容器伸缩。
执行以下命令,通过External Metrics指标查询方式,查看HPA可用的External指标详情和列表。
kubectl get --raw "/apis/external.metrics.k8s.io/v1beta1/" | jq .执行以下命令,查询
http_requests_per_second指标在default命名空间下的当前数值。kubectl get --raw "/apis/external.metrics.k8s.io/v1beta1/namespaces/default/http_requests_per_second"示例输出:
{ "kind": "ExternalMetricValueList", "apiVersion": "external.metrics.k8s.io/v1beta1", "metadata": {}, "items": [ { "metricName": "http_requests_per_second", "metricLabels": {}, "timestamp": "2022-01-28T08:40:20Z", "value": "33m" } ] }
步骤三:配置并部署HPA,根据获得的指标进行弹性扩缩
部署HPA
当前版本已支持Prometheus Metrics同时透出Custom Metrics与External Metrics。您可以根据需求任选以下方式通过HPA进行容器伸缩。
通过Custom Metrics进行容器伸缩
使用以下内容,创建hpa.yaml文件。
kind: HorizontalPodAutoscaler apiVersion: autoscaling/v2 metadata: name: sample-app-memory-high spec: # HPA的伸缩对象描述,HPA会动态修改该对象的Pod数量。 scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: sample-app # HPA的最小Pod数量和最大Pod数量。 minReplicas: 1 maxReplicas: 10 # 监控的指标数组,支持多种类型的指标共存。 metrics: - type: Pods pods: # 使用指标:pods/container_memory_working_set_bytes_per_second。 metric: name: container_memory_working_set_bytes_per_second # AverageValue类型的目标值,Pods指标类型下只支持AverageValue类型的目标值。 target: type: AverageValue averageValue: 1024000m # 此处1024000m代表1 KB内存阈值,当前指标单位为byte/per second,m为K8s转换精度单位,当出现了小数点,K8s又需要高精度时,会使用单位m或k。例如1001m=1.001,1k=1000。执行以下命令,创建HPA应用。
kubectl apply -f hpa.yaml执行以下命令,查看HPA是否生效。
kubectl get hpa sample-app-memory-high预期输出:
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE sample-app-memory-high Deployment/sample-app 24576k/1024000m 3 10 1 7m
通过External Metrics进行容器伸缩
使用以下内容,创建hpa.yaml文件。
apiVersion: autoscaling/v2 kind: HorizontalPodAutoscaler metadata: name: sample-app spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: sample-app minReplicas: 1 maxReplicas: 10 metrics: - type: External external: metric: name: http_requests_per_second selector: matchLabels: job: "sample-app" # External指标类型下只支持Value和AverageValue类型的目标值。 target: type: AverageValue averageValue: 500m执行以下命令,创建HPA应用。
kubectl apply -f hpa.yaml在Service中开启负载均衡后,执行以下命令,进行压测实验。
ab -c 50 -n 2000 LoadBalancer(sample-app):8080/执行以下命令,查看HPA详情。
kubectl get hpa sample-app预期输出:
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE sample-app Deployment/sample-app 33m/500m 1 10 1 7m
ack-alibaba-cloud-metrics-adapter组件配置文件详解
ack-alibaba-cloud-metrics-adapter通过以下步骤将Prometheus中的指标转换成HPA可用的指标:
Discovery:ack-alibaba-cloud-metric-adapter会从Prometheus发现可用的指标。
Association:将指标与Kubernetes资源(Pod、Node、Namespace)相关联。
Naming:定义转换后的HPA可用指标名称,供 HPA 引用。
Querying:定义如何从Prometheus查询指标数据。
以上文中sample-app容器中暴露出来的http_requests_total指标转换成HPA中的http_requests_per_second为例,完整的ack-alibaba-cloud-metrics-adapter配置文件如下。
- seriesQuery: http_requests_total{namespace!="",pod!=""}
resources:
overrides:
namespace: {resource: "namespace"}
pod: {resource: "pod"}
name:
matches: ^(.*)_total
as: ${1}_per_second
metricsQuery: sum(rate(<<.Series>>{<<.LabelMatchers>>}[2m])) by (<<.GroupBy>>)字段 | 说明 |
| PromQL请求数据。 |
| 对seriesQuery中PromQL请求的数据做聚合操作。 说明
|
| 是PromQL里的数据Label,与 |
| 指根据正则匹配把Prometheus指标名转换为比较可读的指标名。此处将 |
Discovery
指定待转换的Prometheus指标,您可以通过
seriesFilters精确过滤指标。seriesQuery可以根据标签进行查找,示例代码如下。seriesQuery: http_requests_total{namespace!="",pod!=""} seriesFilters: - isNot: "^container_.*_seconds_total"seriesFilters为非必填项,用于过滤指标:is:<regex>:匹配包含该正则表达式的指标。isNot:<regex>:匹配不包含该正则表达式的指标。
Association
设置Prometheus指标标签与Kubernetes中的资源映射关系。
http_requests_total指标的标签包括namespace!=""和pod!=""。- seriesQuery: http_requests_total{namespace!="",pod!=""} resources: overrides: namespace: {resource: "namespace"} pod: {resource: "pod"}Naming
用于将Prometheus指标名称转换成HPA的指标名称,但不会改变Prometheus本身的指标名称。如果使用Prometheus原来的指标,可以不设置。
您可以通过执行命令
kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1"查看HPA可用的所有指标。- seriesQuery: http_requests_total{namespace!="",pod!=""} resources: overrides: namespace: {resource: "namespace"} pod: {resource: "pod"} name: matches: "^(.*)_total" as: "${1}_per_second"Querying
查询Prometheus API的模板。ack-alibaba-cloud-adapter会根据HPA中的参数,填充参数到此模板中,然后发送给Prometheus API请求,并将获得的值最终提供给HPA进行弹性扩缩。
- seriesQuery: http_requests_total{namespace!="",pod!=""} resources: overrides: namespace: {resource: "namespace"} pod: {resource: "pod"} name: matches: ^(.*)_total as: ${1}_per_second metricsQuery: sum(rate(<<.Series>>{<<.LabelMatchers>>}[2m])) by (<<.GroupBy>>)
如何获取Prometheus数据请求URL
场景一:阿里云Prometheus监控
登录容器服务管理控制台,在左侧导航栏选择集群列表。
在集群列表页面,单击目标集群名称,然后在左侧导航栏,选择。
单击右上角跳转到Prometheus服务。
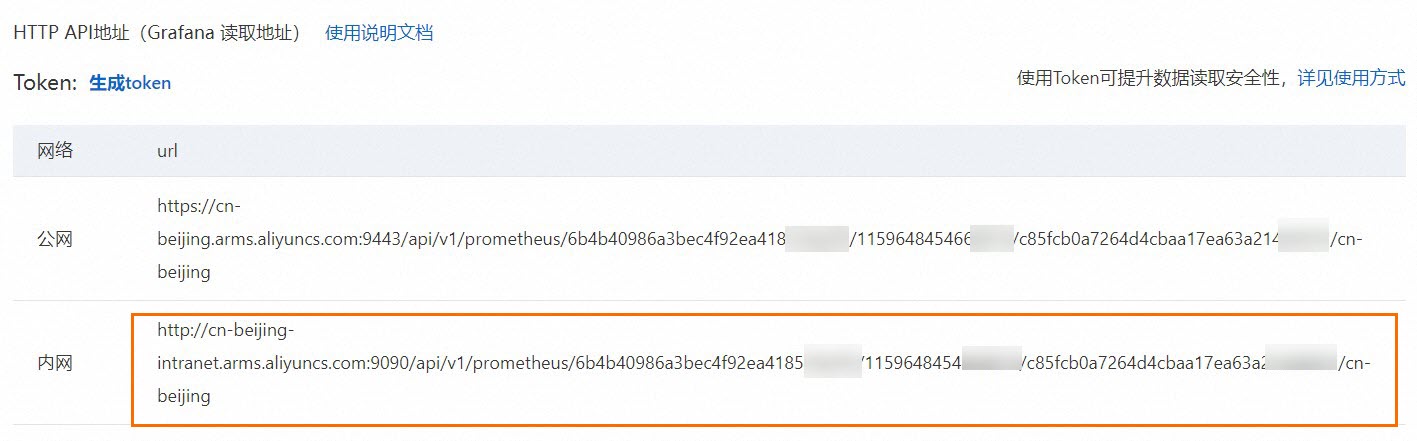
在Prometheus监控服务控制台的左侧导航栏,单击设置,然后单击设置页签,获取HTTP API地址(Grafana 读取地址)。
推荐使用内网,如无法使用内网时,可使用公网。
场景二:开源Prometheus监控
针对开源自建Prometheus方案,您需要通过Service暴露Prometheus的标准访问API,然后将其配置在metrics-adapter组件的Prometheus数据源URL参数中,即可完成基于开源Prometheus数据的HPA数据源配置。
下文以ACK应用市场提供的ack-prometheus-operator社区版应用Helm Chart为例。更多信息,请参见开源Prometheus监控。
部署Prometheus监控方案,并暴露标准Prometheus API。
登录容器服务管理控制台,在左侧导航栏选择。
在应用市场页面,搜索并单击ack-prometheus-operator,然后在页面右侧,单击一键部署。
在创建页面,选择集群和命名空间,按需修改发布名称,然后单击下一步,按需修改参数,然后单击确定。
查看部署结果。
通过Service暴露Prometheus的标准API,当前以ack-prometheus-operator的Service:ack-prometheus-operator-prometheus为例。
在浏览器中访问ServiceIP:9090,如需为Service开通公网访问SLB,查看Prometheus控制台。
在页面上方菜单栏,单击,查看所有采集任务。
如果所有任务的状态为UP,表示所有采集任务均已正常运行。
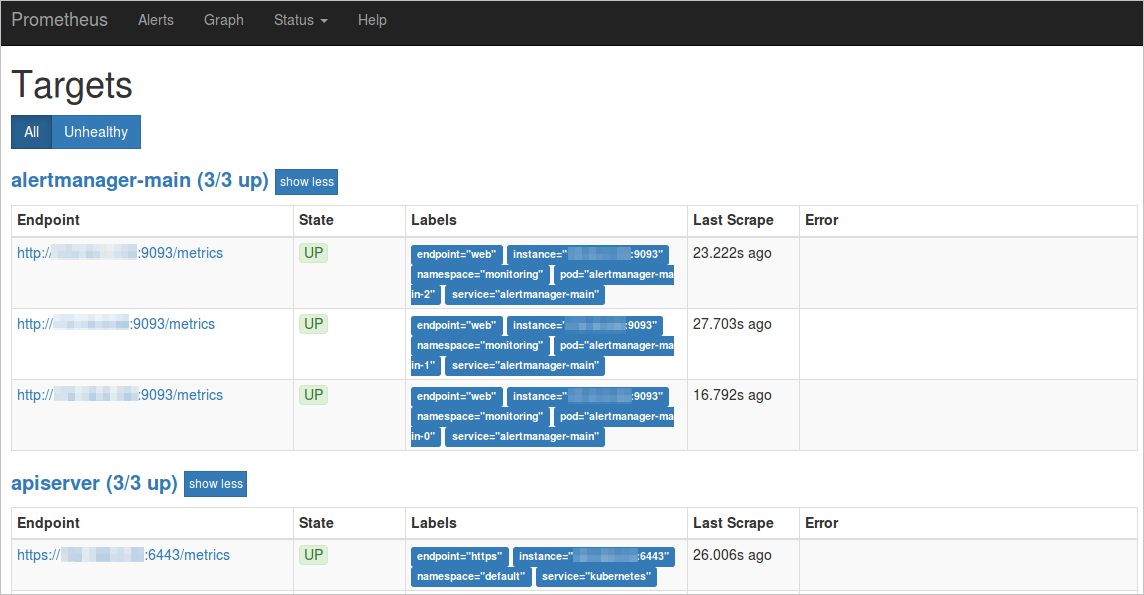
查看Labels中对应的service和namespace。
本示例以ServiceName为ack-prometheus-operator-prometheus,ServiceNamespace为monitoring为例说明该开源Prometheus数据请求的URL。
http://ack-prometheus-operator-prometheus.monitoring.svc.cluster.local:9090
配置组件的Prometheus数据源URL参数中,以确保组件与Prometheus之间的通信正常。
如果选择通过公网访问Prometheus的标准API,可参见以下示例进行配置。
AlibabaCloudMetricsAdapter: ...... prometheus: enabled: true url: http://your_domain.com:9090 # 请将your_domain.com替换为您的公网IP以ack-prometheus-operator方案为例,此时
url值为http://ack-prometheus-operator-prometheus.monitoring.svc.cluster.local:9090。
相关文档
如需通过外部指标(External Metrics),例如HTTP请求率、Ingress QPS等指标实现HPA,请参见基于阿里云组件指标的容器水平伸缩。
如需通过Nginx Ingress对多个应用进行HPA,以根据应用的负载情况动态调整Pod副本数量,请参见基于Nginx Ingress流量指标的多应用水平伸缩。