接下来需要做“特征配置”。特征配置在推荐方案配置中是一个核心的部分,我们期望通过界面配置出想要的特征,然后自动生成计算的MaxCompute 和Flink的SQL代码,生产出常见的统计特征、序列特征、MinMax特征、偏好KV统计特征,最终输出给向量召回、粗排和精排模型样本。
1.常用周期行为类型配置
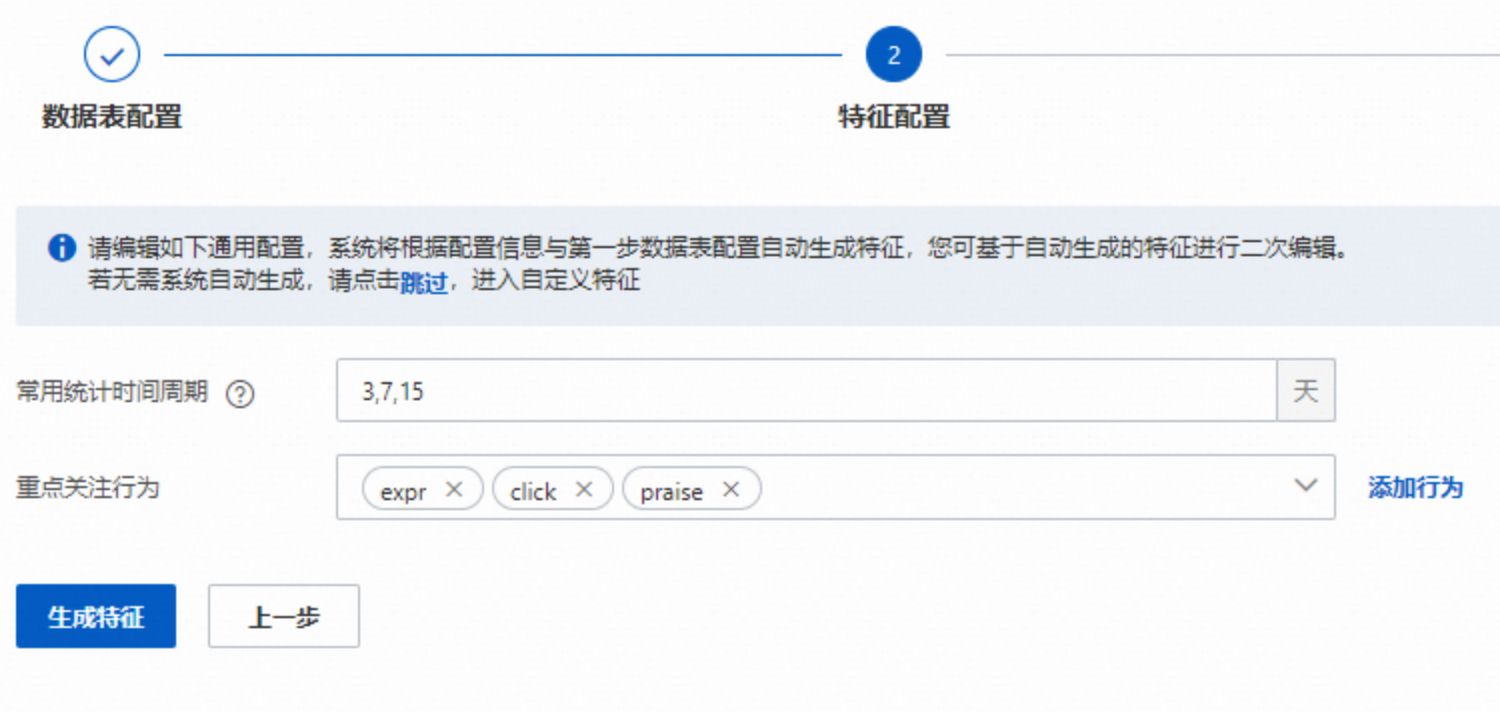
常用周期:可以自定义配置,一般我们配置短、中、长周期,不可过多,过多可能引起过多的特征(如在一个周期统计200个特征,通常3个周期就有600个特征,如果是6个周期就会超过1200个特征)。
重点关注行为:即行为表填写的行为枚举值,一般在5个以下(和行为周期一样,太多会引起过多的特征)。如果有过多的行为类型,可以在上游准备表的时候合并一些不重要的,或者含义一样的行为类型。注意此处一般按照行为发生的先后次序,如次序应该是"曝光、点击、点赞"(对应expr、click、praise,来自于event字段里面的枚举值)这种顺序,次序混乱会影响下面比率特征的生成,会给下游更改造成一些手动工作。
此处会根据统计周期以及行为类型,还有上游3张表提供的类目,数值,tag等类型的基础特征,点击【生成特征】,会自动在用户和物品侧衍生出多种统计特征。
2.基础衍生特征
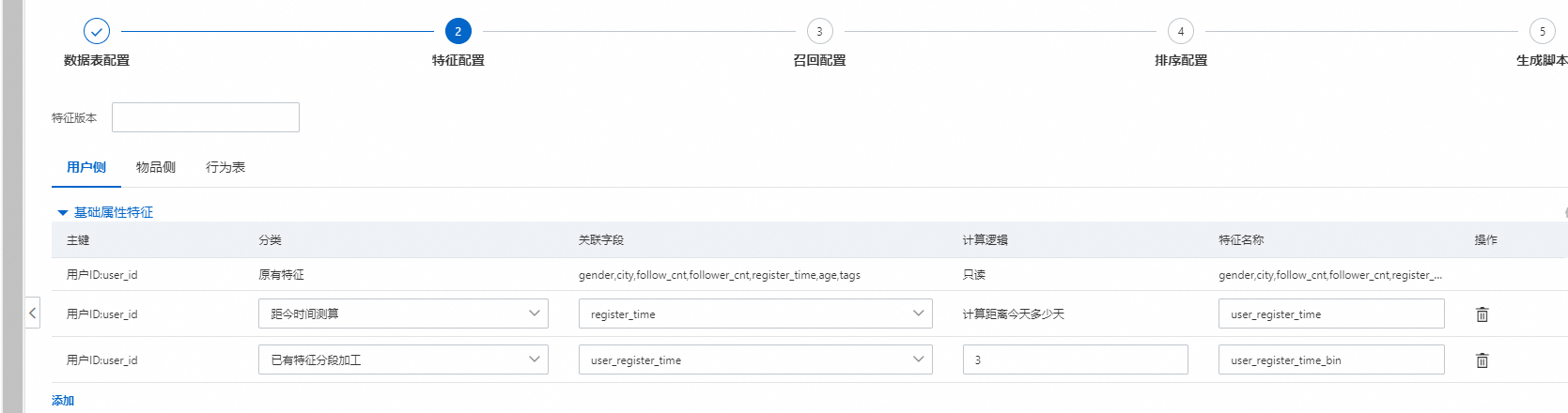
一般根据上游对3张表的配置,下游对应的基础属性特征已经有一些自动的衍生特征,不过此处我们还可以点击添加,继续增加基础衍生特征。注意用户侧,物品侧,和行为侧都有基础属性特征的衍生。
IP衍生:配置IP衍生特征,只能在上游对应表配置的IP字段上进行衍生,我们可以根据配置,解析出IP的省份、城市、国家三种特征,注意解析结果有一定的误差。
距今时间测算:根据用户或者商品的注册时间,计算距今多少天。
已有特征分段加工:只能针对数值字段,根据填写的分割点进行分割,分割后则是类目特征。
特征组合:表示多种类目字段的组合,可以是类目和类目,类目和tag,tag和tag字段组合,此种组合要求属于当前表,且要么都属于user侧,要么都属于item侧。
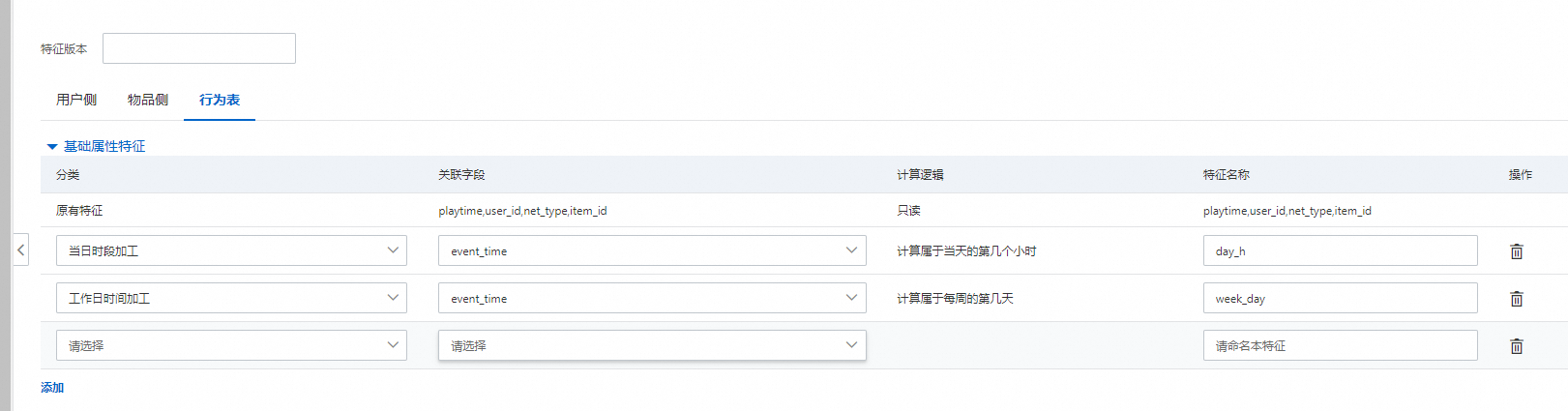
点击行为表,还有其余的2种基本衍生
当日时段加工:根据行为日志会衍生出属于日志发生于当天第几个小时
工作日时段加工:根据行为日志解析出日志发生于每周的第几天
如果手动增加完基础的衍生特征,需要点击右上角的保存,手动增加的基础衍生特征才会生效
3.行为偏好统计
如下图所示,我们已经自动衍生了多种统计特征,用户侧和物品侧都有对应的统计特征,其中自动以用户ID和物品ID作为聚合主键。目前有以下6种类型的统计:
行为统计计数
转化率统计
Top偏好属性类特征的行为计数
Top偏好属性类特征的行为占比
偏好数值类特征
Top类目与数值组合特征计算
如果觉得某些特征不需要,可以点击右侧的删除按钮,或者点击编辑对某个属性进行删除。如果需要添加特征可以点击右下角的【添加】按钮,继续添加多种类型的统计特征。以下是几种统计特征的介绍

行为统计计数
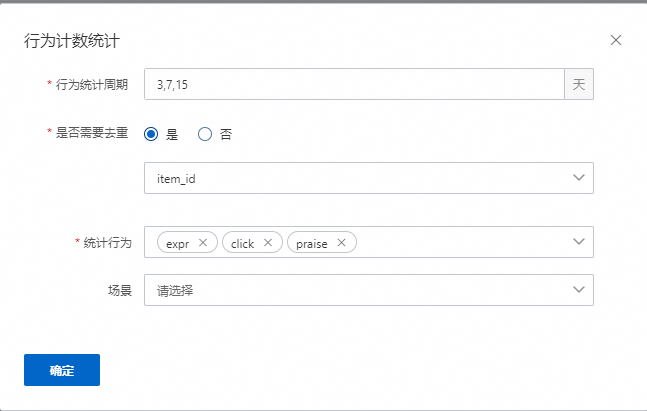
表示会统计用户在对应的周期,如3、7、15天中,统计对应的行为,如expr、click、praise发生的次数,如果带有去重ID,则表示依照ID去重之后的次数,如果有配置场景,则表示这些特征会统计发生在某个场景的行为。该示例配置会产生9个特征,即统计周期数量乘上统计行为数量(3*3=9)。
转化率统计

为统计行为的转化率,表示会统计用户,在对应的周期,如3、7、15天中,统计对应的行为相除,如click的次数除以expr的次数,praise的次数除以click的次数,如果不符合要求还可以继续修改、增加、删除。如果有配置场景,则表示只会统计发生在该场景的行为。该示例配置产生6个特征,统计周期数量乘以转化率公式数量。
Top偏好属性类特征的行为计数
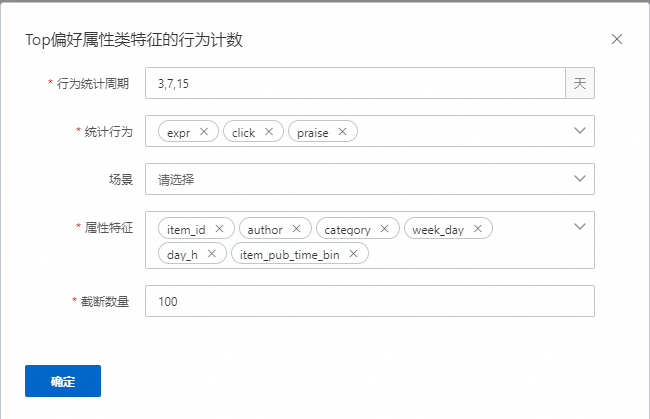
表示会统计用户在对应的周期,如3、7、15天中,对属性特征类目或者多值类目,统计对应的行为,如expr,click,praise。每种属性值发生的次数,最终生成kv特征。如以类目day_h,行为是点击举例,生成特征"12:27.0,8:26.0,1:1.0"表示该用户在当前周期内,在12点的点击发生27次,8点的点击发生26次,1点的点击发生1次。如果有配置场景,则表示这些特征会统计发生在某个场景的数据下,如果key的数量过多,默认截断100个。该示例配置生成54个特征,数量=统计周期数量*统计行为数量*属性特征数量。
Top偏好属性类特征的行为占比

表示会统计用户在对应的周期,如3、7、15天中,对属性特征类目或者多值类目,统计对应的行为比率,如click/expr (ctr),praise/click(cvr)比率特征。最终生成kv特征。如以类目cate为列,公式是click/expr,生成特征"12:0.27,8:0.26"表示该用户在当前周期内,在12类目的点击率是0.27,在类目8的点击率0.26。如果有配置场景,则表示这些特征会统计发生在某个场景的数据下,如果key的数量过多,默认截断100个。该示例配置生成36个特征,数量=统计周期数量*转化率公式数量*属性特征数量
偏好数值类特征
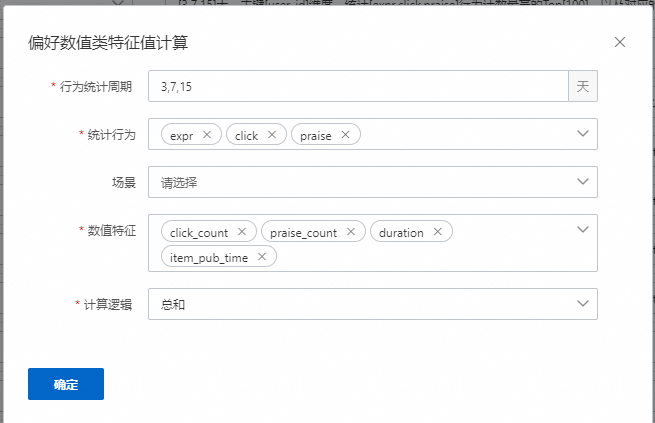
表示会统计用户在对应的周期,如3、7、15天中;在对应的行为中,如expr、click、praise;对选择的数值属性,根据计算逻辑进行统计。计算逻辑可以是总和,最大值,最小值,均值等。如果有配置场景,则表示这些特征会统计发生在某个场景下的数据。该示例配置生成36个特征,数量=统计周期数量×行为数量×数值特征数量。
Top类目与数值组合特征计算
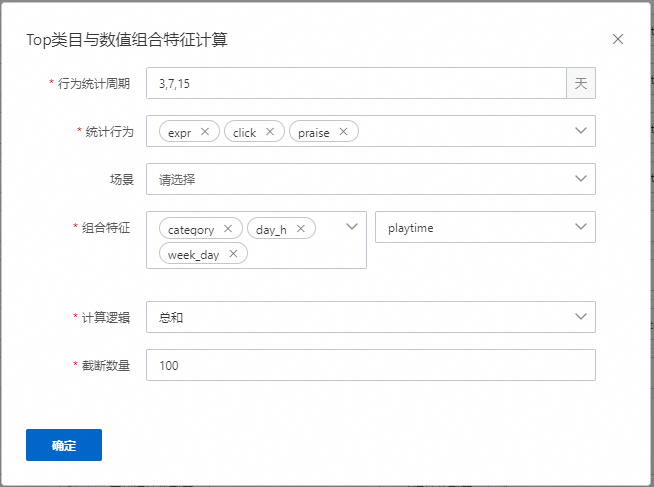
表示会统计用户在对应的周期,如3、7、15天中;在对应的行为中,如expr、click、praise;根据计算逻辑,如总和,最大值,最小值,均值等;计算用户在对应类目特征下对某数值的偏好。如果有配置场景,则表示这些特征会统计发生在某个场景的数据下。该示例配置生成27个特征,数量=统计周期数量*行为数量*组合特征的类目特征数量。
4.序列特征
序列特征只会发生在用户侧。序列特征刚开始我们都是依靠现有的数据模拟实时序列特征,节省线上落下序列特征的时间,加速上线。其中模拟事件一般都是曝光事件;防穿越时间是指最近n秒的行为不会算入当前行为序列(因为推理的时候,日志回流链路原因会导致部分数据有延迟,如果模拟得过于实时,会导致训练有穿越);序列特征分隔符,是指构造序列的时候,序列之间的分隔符;子特征分隔符,是指在一个序列中,子特征之间的分隔符。

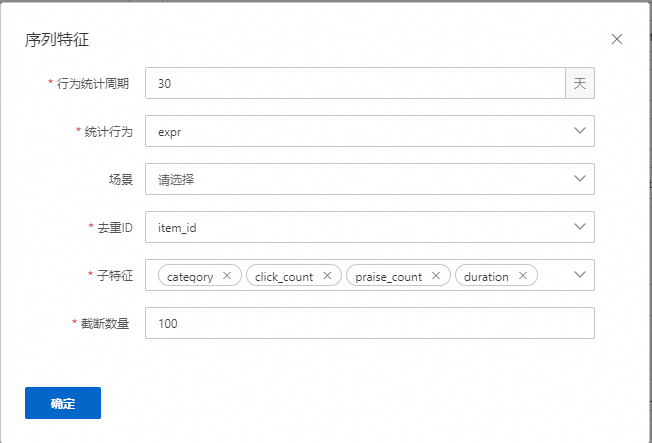
行为周期:表示统计最近多少天内的行为,如果有多组序列,则最大的周期起作用。
统计行为:表示要统计的行为类型。
场景:表示只统计该场景下的行为,不选择则统计所有场景。
去重ID:表示在序列中会依据该子特征去重,保留当前时刻最后一次该行为发生。
子特征:表示序列特征的子特征,一般都是属于商品侧的非统计特征,包括类目、多值类目以及数值特征。
阶段数量:表示序列特征最大保留的序列数量。
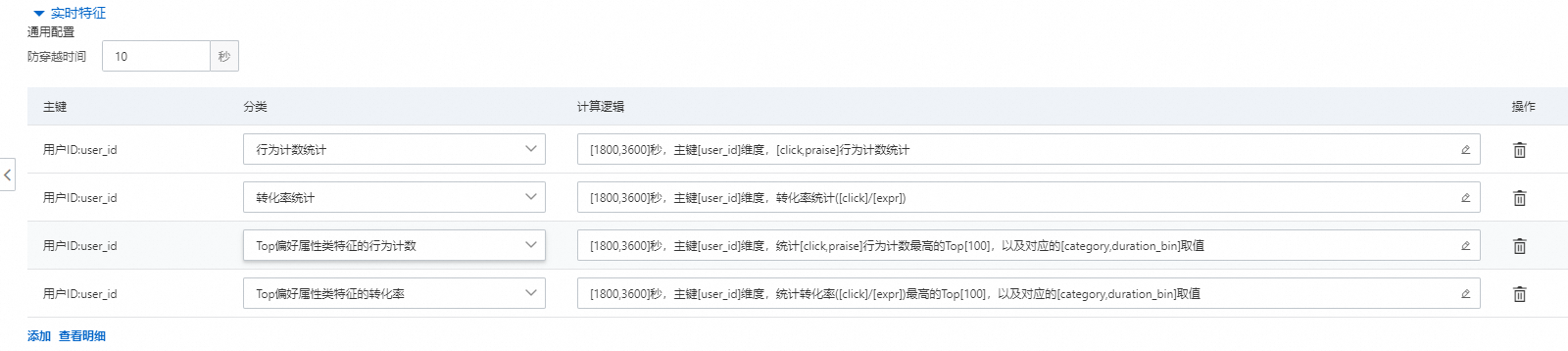
5.实时特征
以用户ID和物品ID为主键都可以创建实时特征,其中防穿越时间和序列特征的防穿越时间的功能一样,表示在目标行为的最近多少秒内的行为不会进入计数统计(因为行为日志从客户端传输到消息中间件,再统计写入到在线存储服务会有一段时间差;如果不设置防穿越时间,会导致线上统计不到理想的数据)。其中实时特征统计周期单位是秒。统计类型包含以下四种类型:
行为统计计数
转化率统计
Top偏好属性类特征的行为计数
Top偏好属性类特征的行为占比
该四种类型和行为偏好统计的四种含义一样,只是周期不同。
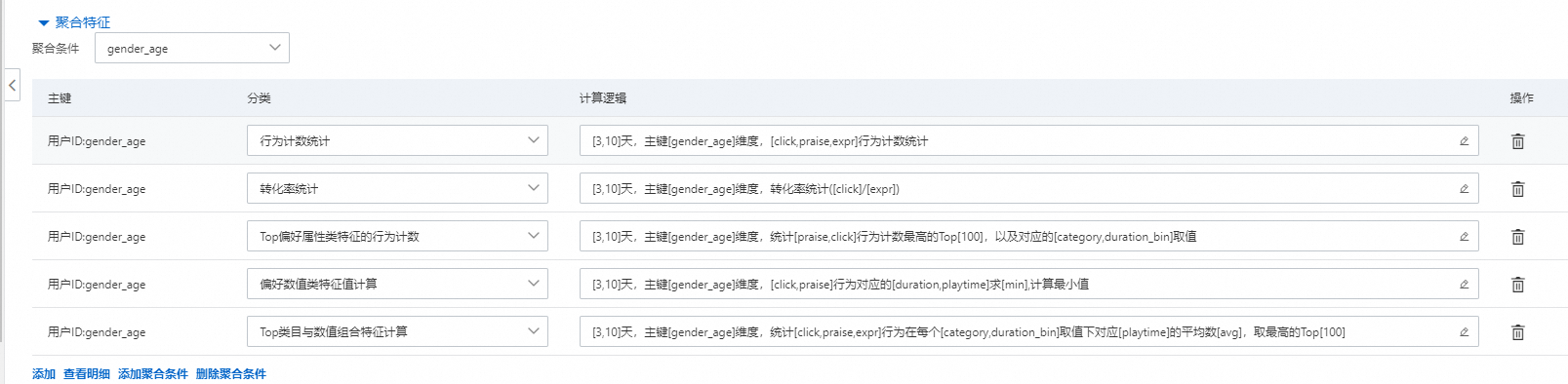
6.聚合特征
聚合特征在用户侧和物品侧都可以发生。需要选择聚合条件,只能选择类目特征作为聚合条件,并且可以配置多组。
会根据当前的聚合条件统计对应的特征。可以统计的类型和行为偏好的统计类型一样,含义也一样。例如下图第一行的含义:是统计在不同性别下“点击、点赞、曝光”的次数总计。以“口红”这种商品为例,是女性点击的次数明显会多一些。