
在排序配置中我们选择添加一个“精排”:
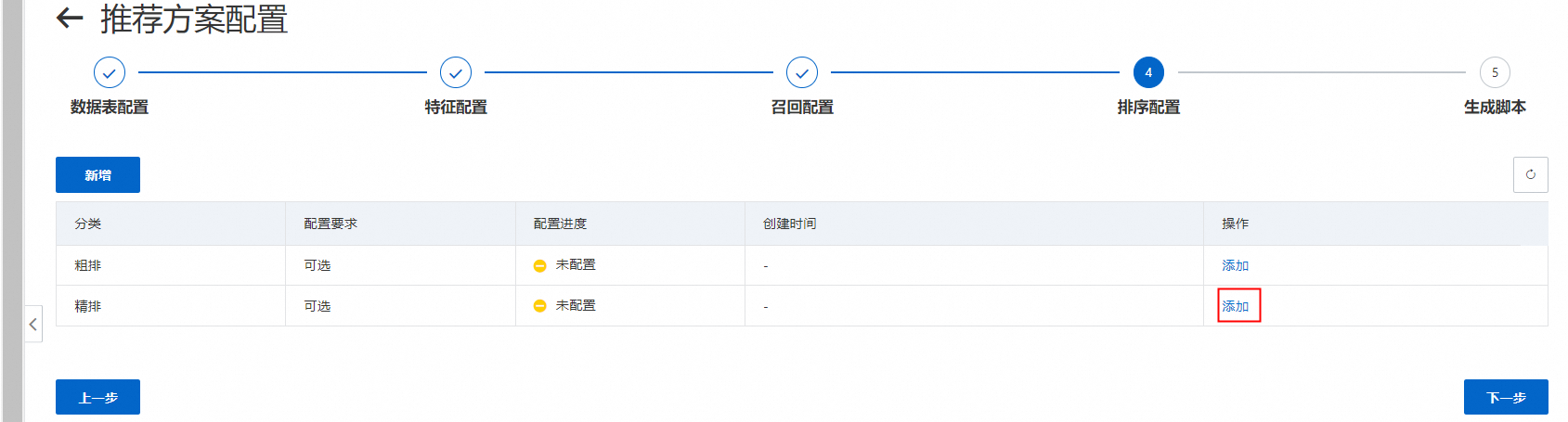
精排模型名称:字母加下划线,推荐用:${场景名称}_${模型名称}_rank
精排目标设置:精排目标可以设置多个目标,包含分类和回归目标,详情如下:
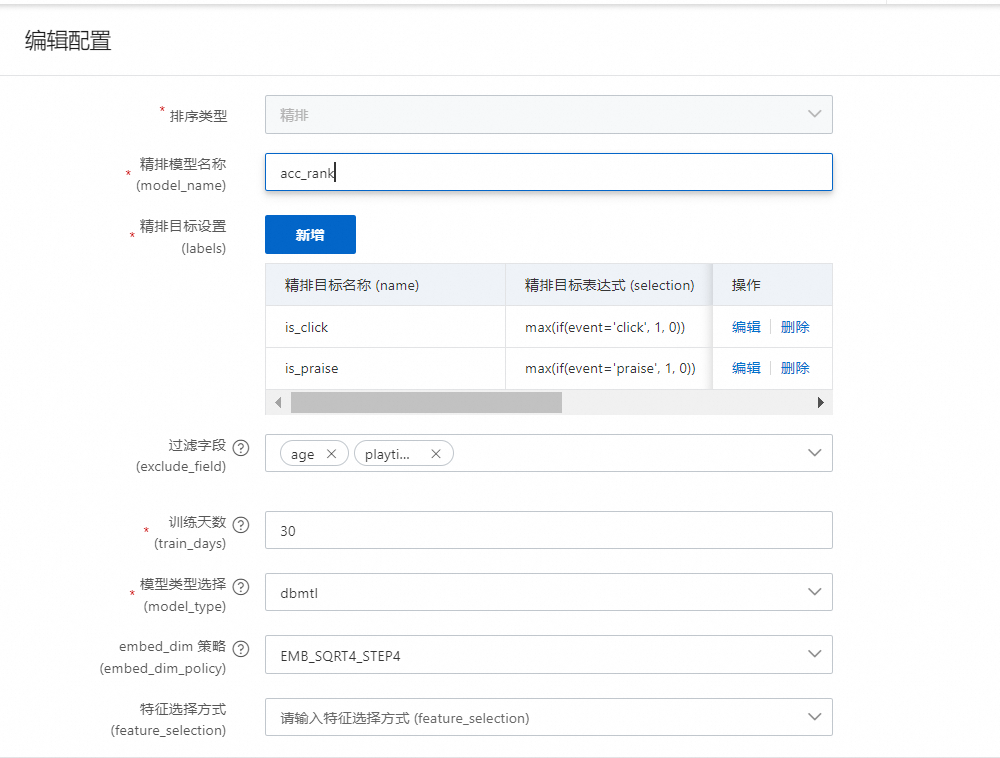
分类目标
精排目标名称自定义;精排目标表达式,一般我们是二分类目标,根据聚合条件做对应的聚合;目标类型分类就是classification,如下图:
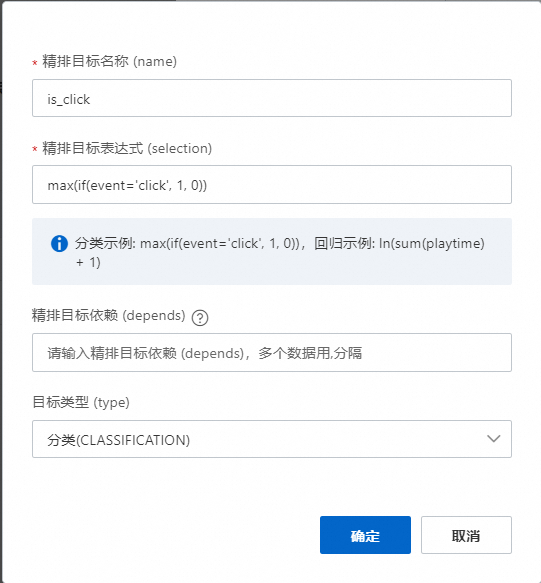
回归目标
精排目标名称可自定义;
精排目标表达式:对于回归目标,我们需要对行为表目标数值做sum聚合加和,然后取log变换;
目标类型:选择回归目标regression;
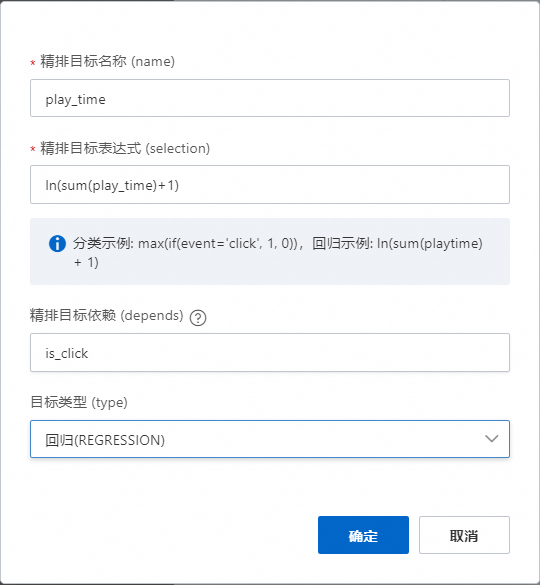
精排目标依赖:如果某目标(x)需要依赖另外一个目标(y),可以在目标依赖处填写。例如:在视频中我们只有点击之后才会播放,播放的观看时长是play_time,那么play_time目标可以依赖点击目标(注意这里选择的是上面注册的分类任务名称is_click)。同理,其他分类任务也适用。如下图:
过滤字段:可以选择我们不需要参与训练的特征,或者不能在曝光之前获取到的特征,如play_time是曝光之后用户的观看时长。这些字段放在训练特征里面会导致特征穿越。其他如是否点击、是否付费的字段都要去掉。
训练天数:表示我们用多少天的数据集进行训练精排模型。
模型选择:如果是单任务则结合EasyRec选择单任务的模型,是多任务的选择多任务的模型,此处我们是多任务,选择DBMTL。
特征选择方式,特征选择的目标列:特征选择方式如果有配置,将对所有的特征进行筛选,选择重要的特征进行训练,目标列则配合其选择方式,选择重要的特征。由于这个方案增加了复杂性,建议第一个模型版本不使用。
是否增量训练:false表示全量训练,建议默认选择false。true则表示增量训练,我们后一天的训练会在前一天训练好的模型上继续训练。
是否异步训练:在分布式训练中是否异步训练。
样本权重:如果配置,则会对不同样本根据表达式获得权重,进而影响模型训练精度,一般不用。
场景数据筛选:是否用某特定场景下的数据进行训练。
使用特征平台:是否会使用配置好的FeatureStore,如果在推荐方案的环境配置中有配置FeatureStore,则会启用FeatureStore。
自动特征工程:会根据现有的特征,利用算法挖掘更有用的特征来进行训练。建议第一个版本不用autofe,当需要调优效果的时候再使用自动特征工程挖掘更多的特征。