AC2(Alibaba Cloud AI Containers )是阿里云官方推出的一系列AI容器镜像的合集。通过内置多种硬件加速库、AI运行时和AI框架等满足了您在不同场景的部署需求。同时,AC2与Alibaba Cloud Linux操作系统深度集成,显著提升系统的性能。本文将介绍以Alibaba Cloud Linux 3作为操作系统,运行AC2维护的vLLM容器镜像,采用多机多卡的方式进行DeepSeek-R1的分布式部署。
背景信息
DeepSeek-R1
DeepSeek-R1模型是DeepSeek推出的第一代推理模型,在后训练阶段大规模使用了强化学习技术,即使在标注数据极少的情况下,也显著提升了模型的推理能力。经过验证表明,DeepSeek-R1在数学、代码、自然语言等任务上接近或超越了OpenAI-o1系列模型。DeepSeek-R1-Distill-Qwen是基于DeepSeek-R1的输出,结合Qwen大语言模型,通过模型蒸馏得到的小型模型。其中,32B和70B的模型在多项性能指标上达到了与OpenAI o1-mini相当的效果。
vLLM容器镜像
AC2维护的vLLM容器镜像为DeepSeek-R1等大型语言模型的推理服务部署提供了全面集成和优化支持,显著简化了复杂的环境配置流程,使开发者能够更加专注于核心业务逻辑的创新与实现。
部署DeepSeek-R1
DeepSeek-R1全量模型包含671B参数,整个模型文件所需存储空间为642 GiB。由于模型规模较大,推理服务需要采用多机多卡方式进行分布式部署。为实现多机共享存储,需创建NAS存储服务,并通过NFS进行挂载。
步骤一:准备环境
- 重要
挂载同一NAS文件系统的GPU实例的总显存不低于1400 GB,实例数量根据GPU实例显存大小来确定。
在所有GPU实例的
/mnt目录下挂载同一NFS协议文件系统。在主节点执行以下命令,安装ModelScope SDK并下载模型到
/mnt/deepseek-r1目录下。sudo dnf install -y python38 sudo python3.8 -m pip install -U pip sudo python3.8 -m pip install modelscope modelscope download --model deepseek-ai/DeepSeek-R1 --local_dir /mnt/deepseek-r1执行以下命令,为所有GPU实例安装NVIDIA和CUDA驱动。
sudo dnf install -y anolis-epao-release sudo dnf install -y kernel-devel-$(uname -r) nvidia-driver{,-cuda}执行以下命令,为所有GPU实例安装Docker运行环境和NVIDIA Container Toolkit。
sudo dnf config-manager --add-repo=https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo sudo dnf install -y docker-ce nvidia-container-toolkit sudo systemctl restart docker执行以下命令,为所有GPU实例安装运行依赖的系统组件。
sudo dnf install -y curl wget jq
步骤二:部署DeepSeek-R1
在主节点执行以下命令,将脚本下载到NAS挂载目录
/mnt下。sudo wget -O /mnt/run_cluster.sh https://raw.githubusercontent.com/vllm-project/vllm/refs/tags/v0.6.6.post1/examples/run_cluster.sh使用脚本启动分布式集群。
确认主节点主网卡的IP地址。
Ray集群启动需要确定主节点主网卡的IP地址,您可以通过执行
ip addr命令查看所有网卡的地址,并确保其他节点可以访问主节点主网卡的IP地址。
在主节点执行以下命令,启动运行容器。
<head_node_internal_ip>需替换为主节点主网卡的IP地址。sudo bash /mnt/run_cluster.sh \ ac2-registry.cn-hangzhou.cr.aliyuncs.com/ac2/vllm:0.6.6.post1-pytorch2.5.1.6-cuda12.1.1-py310-alinux3.2104 \ <head_node_internal_ip> \ --head \ /mnt \ --ipc host \ --privileged \ --ulimit memlock=-1 \ --ulimit stack=67108864 \ -e TRANSFORMERS_OFFLINE=1 \ -e GLOO_SOCKET_IFNAME=eth0,eth1 \ -e NCCL_SOCKET_IFNAME=eth0,eth1 \ -e NCCL_IB_DISABLE=0 \ -e NCCL_DEBUG=INFO \ -w /root/.cache/huggingface在工作节点执行以下命令,启动运行容器并加入主节点集群。
<head_node_internal_ip>需替换为主节点主网卡的IP地址。sudo bash /mnt/run_cluster.sh \ ac2-registry.cn-hangzhou.cr.aliyuncs.com/ac2/vllm:0.6.6.post1-pytorch2.5.1.6-cuda12.1.1-py310-alinux3.2104 \ <head_node_internal_ip> \ --worker \ /mnt \ --ipc host \ --privileged \ --ulimit memlock=-1 \ --ulimit stack=67108864 \ -e TRANSFORMERS_OFFLINE=1 \ -e GLOO_SOCKET_IFNAME=eth0,eth1 \ -e NCCL_SOCKET_IFNAME=eth0,eth1 \ -e NCCL_IB_DISABLE=0 \ -e NCCL_DEBUG=INFO \ -w /root/.cache/huggingface
在任意节点重新打开一个终端。

执行以下命令,查看容器ID。
sudo docker ps如下图所示。

执行以下命令,进入容器。
<CONTAINER ID>替换为容器ID。sudo docker exec -it <CONTAINER ID> /bin/bash执行以下命令,进入容器并启动vLLM服务。
<GPUs>需替换为单节点GPU数量。<Nodes>需替换为节点数量。
vllm serve deepseek-r1 \ --trust-remote-code \ --tensor-parallel-size <GPUs> \ --pipeline-parallel-size <Nodes> \ --max-num-batched-tokens 8192 \ --max-model-len 8192 \ --enable-prefix-caching \ --host 0.0.0.0例如,使用了两台显存为
8*96 GB的GPU实例作为节点,执行的命令如下:vllm serve deepseek-r1 \ --trust-remote-code \ --tensor-parallel-size 8 \ --pipeline-parallel-size 2 \ --max-num-batched-tokens 8192 \ --max-model-len 8192 \ --enable-prefix-caching \ --host 0.0.0.0等待模型加载。
加载过程中,NCCL组件会输出
Using [x]erdma字样,表明节点之间使用eRDMA通信。
如下图所示,表明模型加载成功。
步骤三:模型运行测试
在启动vLLM服务的节点上重新打开一个终端。
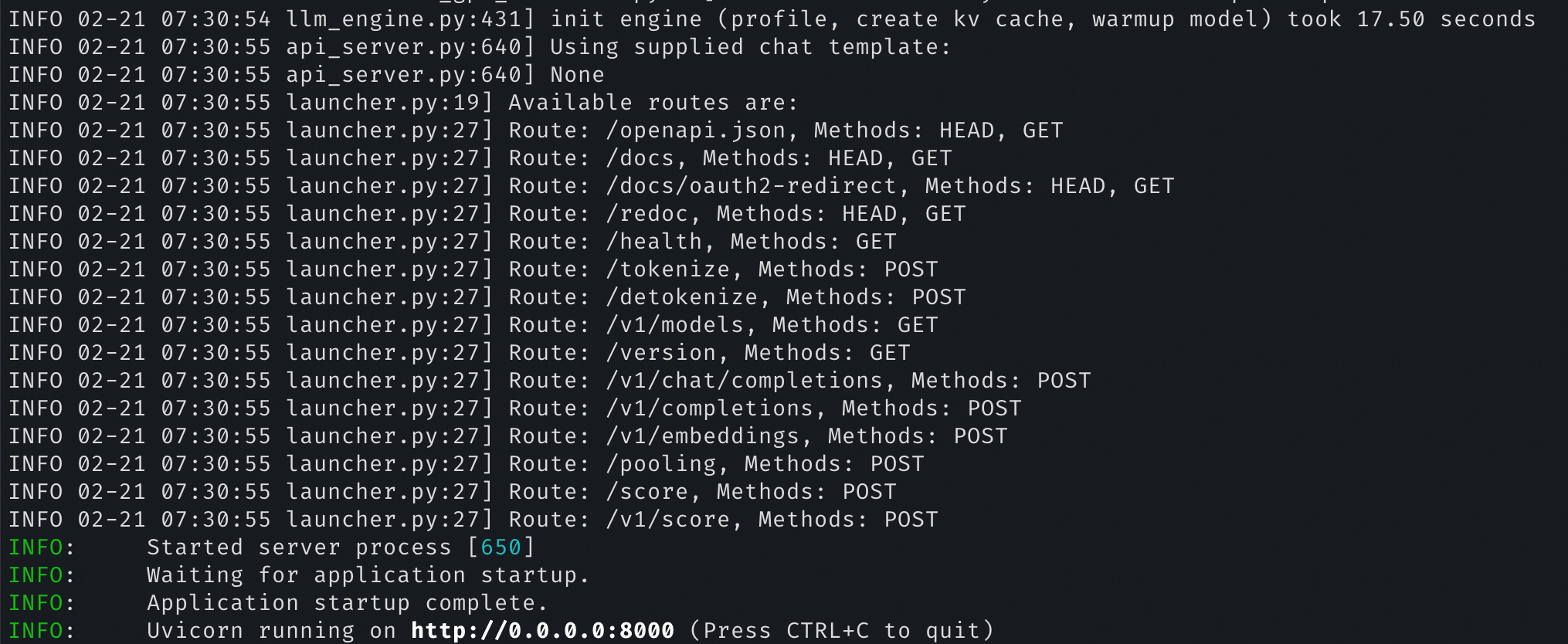
执行以下命令,使用cURL调用vLLM服务API。
curl -s http://localhost:8000/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{"model": "deepseek-r1", "messages": [{"role": "user", "content": "9.9和9.11哪个大?"}]}' | \ jq '.choices[0].message.content' | \ xargs echo -e结果如下图所示。