Jupyter交互式作业开发
云原生数据仓库 AnalyticDB MySQL 版Spark支持使用Docker镜像快速启动Jupyter交互式开发环境,帮助您使用本地Jupyter Lab连接AnalyticDB for MySQL Spark,从而利用AnalyticDB for MySQL的弹性资源进行交互测试和计算。
前提条件
注意事项
AnalyticDB for MySQL Spark当前仅支持Python3.7、Scala 2.12版本的Jupyter交互作业。
交互式作业会在空闲一段时间后自动释放,默认释放时间为1200秒(即最后一个代码块执行完毕,1200秒后自动释放)。您可通过
spark.adb.sessionTTLSeconds参数配置交互式作业的自动释放时间。
启动Jupyter交互式开发环境
安装并启动Docker镜像。具体操作,请参见Docker官方文档。
启动Docker镜像后,拉取AnalyticDB for MySQL Jupyter镜像。命令如下:
docker pull registry.cn-hangzhou.aliyuncs.com/adb-public-image/adb-spark-public-image:livy.0.5.pre启动Jupyter交互式开发环境。
命令格式如下:
docker run -it -p {宿主机端口}:8888 -v {宿主机文件路径}:{Docker容器文件路径} registry.cn-hangzhou.aliyuncs.com/adb-public-image/adb-spark-public-image:livy.0.5.pre -d {ADB Instance Id} -r {Resource Group Name} -e {api endpoint} -i {AkId} -k {aksec}参数说明:
参数名称
是否必填
参数说明
-p
否
将宿主机端口绑定为容器端口。格式为
-p 宿主机端口:容器端口。宿主机端口可任意填写,容器端口固定填写为
8888。本文示例为-p 8888:8888。-v
否
在不挂载宿主机文件夹的情况下,关闭Docker容器后编辑的文件会丢失。Docker容器关闭时也会自动尝试终止所有正在运行的Spark交互式作业。您可以选择如下两种方案避免编辑文件丢失:
在启动Jupyter交互式开发环境时,将宿主机文件挂载到Docker容器中,并将作业文件存储在对应的文件路径下。格式为
-v 宿主机路径:Docker容器文件路径。Docker容器文件路径可任意填写,建议填写为/root/jupyter。在关闭Docker容器前保证所有的文件被妥善地复制保管。
本文示例为
-v /home/admin/notebook:/root/jupyter,表示将宿主机/home/admin/notebook路径下的文件挂载到Docker容器的/root/jupyter路径。说明需要注意将编辑中的notebook文件最终另存到
/tmp文件夹,关闭Docker容器后,在宿主机的/home/admin/notebook文件夹下可以看到对应的文件,再次启动Docker容器时可继续执行。更多信息,请参见Docker卷管理文档。-d
是
AnalyticDB for MySQL企业版、基础版及湖仓版集群ID。
您可以登录AnalyticDB MySQL控制台,在集群列表查看集群的ID。
-r
是
AnalyticDB for MySQL Job型资源组名称。
您可以登录AnalyticDB MySQL控制台,在集群管理 > 资源管理页面,单击资源组管理页签,查看所有的资源组信息。
-e
是
AnalyticDB for MySQL集群的服务接入点信息。
详细信息请参见服务接入点。
-i
是
阿里云账号或RAM用户的AccessKey ID。
如何查看AccessKey ID,请参见账号与权限。
-k
是
阿里云账号或RAM用户的AccessKey Secret。
如何查看AccessKey Secret,请参见账号与权限。
示例:
docker run -it -p 8888:8888 -v /home/admin/notebook:/root/jupyter registry.cn-hangzhou.aliyuncs.com/adb-public-image/adb-spark-public-image:livy.0.5.pre -d amv-bp164l3xt9y3**** -r test -e adb.aliyuncs.com -i LTAI55stlJn5GhpBDtN8**** -k DlClrgjoV5LmwBYBJHEZQOnRF7****启动成功后,返回如下提示信息,您将URL
http://127.0.0.1:8888/lab?token=1e2caca216c1fd159da607c6360c82213b643605f11ef291复制到浏览器,即可使用Jupyter服务直连AnalyticDB for MySQL Spark。[I 2023-11-24 09:55:09.852 ServerApp] nbclassic | extension was successfully loaded. [I 2023-11-24 09:55:09.852 ServerApp] sparkmagic extension enabled! [I 2023-11-24 09:55:09.853 ServerApp] sparkmagic | extension was successfully loaded. [I 2023-11-24 09:55:09.853 ServerApp] Serving notebooks from local directory: /root/jupyter [I 2023-11-24 09:55:09.853 ServerApp] Jupyter Server 1.24.0 is running at: [I 2023-11-24 09:55:09.853 ServerApp] http://419e63fc7821:8888/lab?token=1e2caca216c1fd159da607c6360c82213b643605f11ef291 [I 2023-11-24 09:55:09.853 ServerApp] or http://127.0.0.1:8888/lab?token=1e2caca216c1fd159da607c6360c82213b643605f11ef291 [I 2023-11-24 09:55:09.853 ServerApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).说明启动Jupyter环境时如果出现报错,您可以查看
proxy_{timestamp}.log日志记录文件,排查并解决问题。
修改Spark应用配置参数
用Jupyter服务直连AnalyticDB for MySQL Spark后,可直接在Jupyter Notebook开发页面执行Spark作业,此时Spark作业会使用默认的配置参数运行,默认配置参数如下:
{
"kind": "pyspark",
"heartbeatTimeoutInSecond": "60",
"spark.driver.resourceSpec": "medium",
"spark.executor.resourceSpec": "medium",
"spark.executor.instances": "1",
"spark.dynamicAllocation.shuffleTracking.enabled": "true",
"spark.dynamicAllocation.enabled": "true",
"spark.dynamicAllocation.minExecutors": "0",
"spark.dynamicAllocation.maxExecutors": "1",
"spark.adb.sessionTTLSeconds": "1200"
}如果您想修改Spark应用配置参数,可以使用%%configure语句修改。具体操作步骤如下:
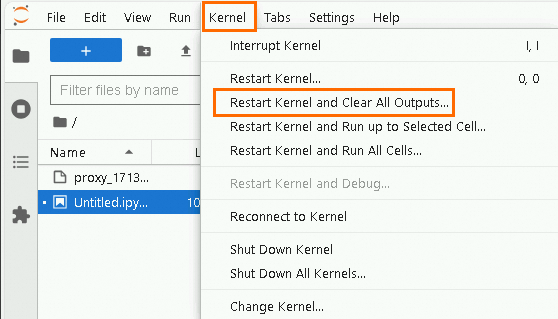
重启kernel。
启动Jupyter交互式开发环境后,使用Jupyter服务直连AnalyticDB for MySQL Spark。
单击页面顶部的,确保当前Notebook开发页面下没有任何运行中的Spark应用。
在代码框中输入自定义的Spark应用配置参数,示例如下:
重要自定义Spark应用配置参数时必须将spark.dynamicAllocation.enabled配置为false。
%%configure -f { "spark.driver.resourceSpec":"small", "spark.sql.hive.metastore.version":"adb", "spark.executor.resourceSpec":"small", "spark.adb.executorDiskSize":"100Gi", "spark.executor.instances":"1", "spark.dynamicAllocation.enabled":"false", "spark.network.timeout":"30000", "spark.memory.fraction":"0.75", "spark.memory.storageFraction":"0.3" }Spark应用配置参数的详细介绍,请参见Spark应用配置参数说明。
单击
 按钮。
按钮。返回结果如下,则代表Spark应用配置参数修改成功。

关闭Jupyter Notebook页面后,自定义配置参数会失效,重新打开Jupyter Notebook页面时,需重新配置Spark应用参数,否则Spark作业会使用默认的应用配置参数运行。
在Jupyter Notebook页面执行Spark作业时,所有配置项都直接写入到JSON结构中,无需像提交Batch类型的作业时写入到
conf的JSON对象中。