
Serverless Pro模式
AnalyticDB PostgreSQL版 7.0 版本全新推出 Serverless Pro 模式。该模式依托云原生基础设施的资源池化与海量对象存储能力,深度融合 MPP 数据库技术与 Serverless 技术,实现了计算存储分离、秒级弹性伸缩与高效的一写多读能力。Serverless Pro 模式在完全保障 PostgreSQL 核心语义与企业级稳定性的同时,旨在帮助您在海量数据分析与高并发读取场景下,显著降低总体拥有成本。
核心优势
相较于传统的存储弹性模式,Serverless Pro 模式主要带来以下核心收益:
更低的存储成本:数据统一沉淀至成本更低、容量无限的阿里云对象存储,无需为长期增长的数据持续扩容到昂贵的本地云盘,大幅降低海量数据场景下的存储开销。
更强的弹性伸缩:计算与存储解耦,计算资源可根据业务负载按需、独立地进行扩缩容。能够实现秒级快速扩容以应对业务高峰,并在业务低谷时及时回收资源,避免算力浪费。
高效稳定的一写多读:通过虚拟计算集群(Virtual Warehouse)隔离读写负载。主集群处理写入任务,只读业务(如报表、看板、即席分析)由独立的 VW 承载,避免大查询影响写入稳定性。多个 VW 共享同一份底层存储,无需复制数据,避免多套读集群冗余存储带来的额外成本。
架构设计
架构演进
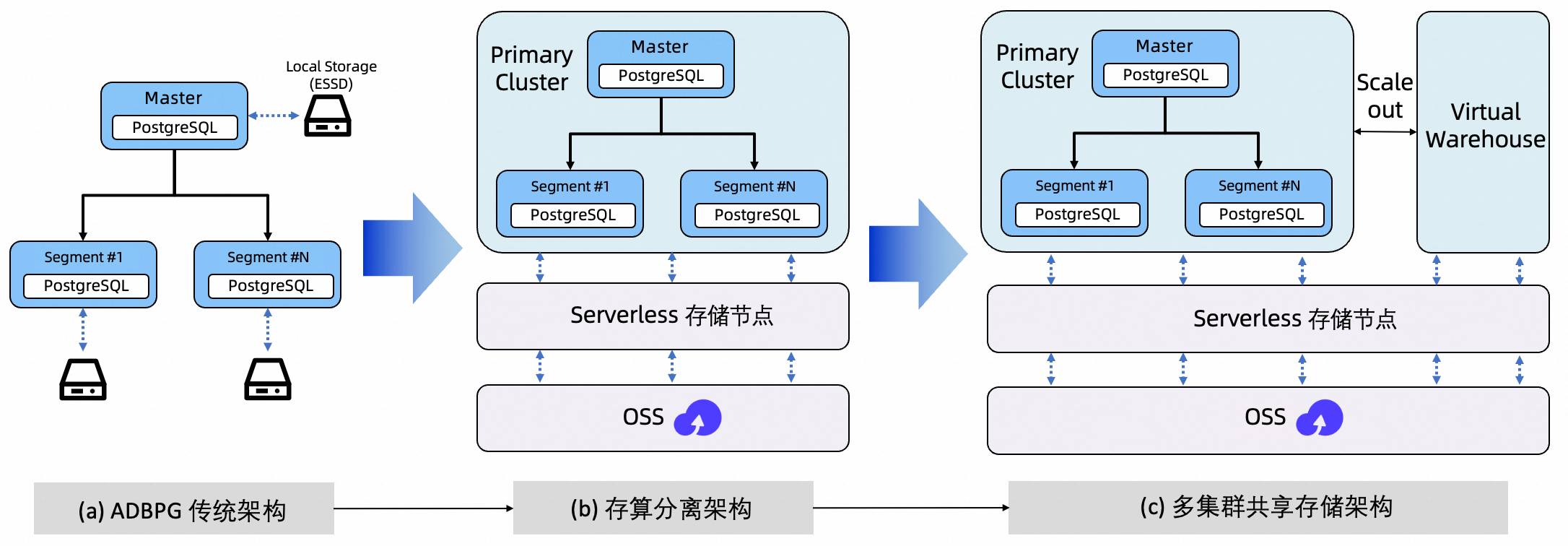
Serverless Pro 模式的架构演进清晰地体现了其“更省、更弹、更稳”的设计哲学。
ADBPG传统架构:Master/Segment 计算节点需要绑定本地 ESSD 承载数据与索引,数据增长会带来本地盘与副本持续扩张,存储成本线性上涨;同时计算节点有状态,扩缩容慢、回收难;当业务需要一写多读时,通常只能通过“新建集群 + 复制数据”扩展读能力,周期长且存储开销成倍增加。
存算分离架构:Serverless Pro 引入“Serverless Pro 存储节点 + OSS”的共享存储底座,将持久化数据统一沉降到OSS,本地盘主要用于缓存与临时数据,使计算更接近无状态。由此计算与存储解耦,算力可独立扩缩,峰值快速拉起、低谷及时回收;存储按需付费,避免被本地云盘容量长期绑定带来的高成本。
多集群共享存储架构:基于共享存储进一步支持“主集群 + 多 Virtual Warehouse(VW)”。主集群负责写入,VW 提供独立只读算力承载报表、看板、临时分析等读负载;创建 VW 无需复制数据,读扩展从传统的“天级数据复制”缩短为“分钟级资源拉起”;同时读写物理隔离,大查询不再抢占主集群资源,混合负载更稳定;多个 VW 共享同一份底层数据,也避免为每个只读集群重复购买存储。
产品架构
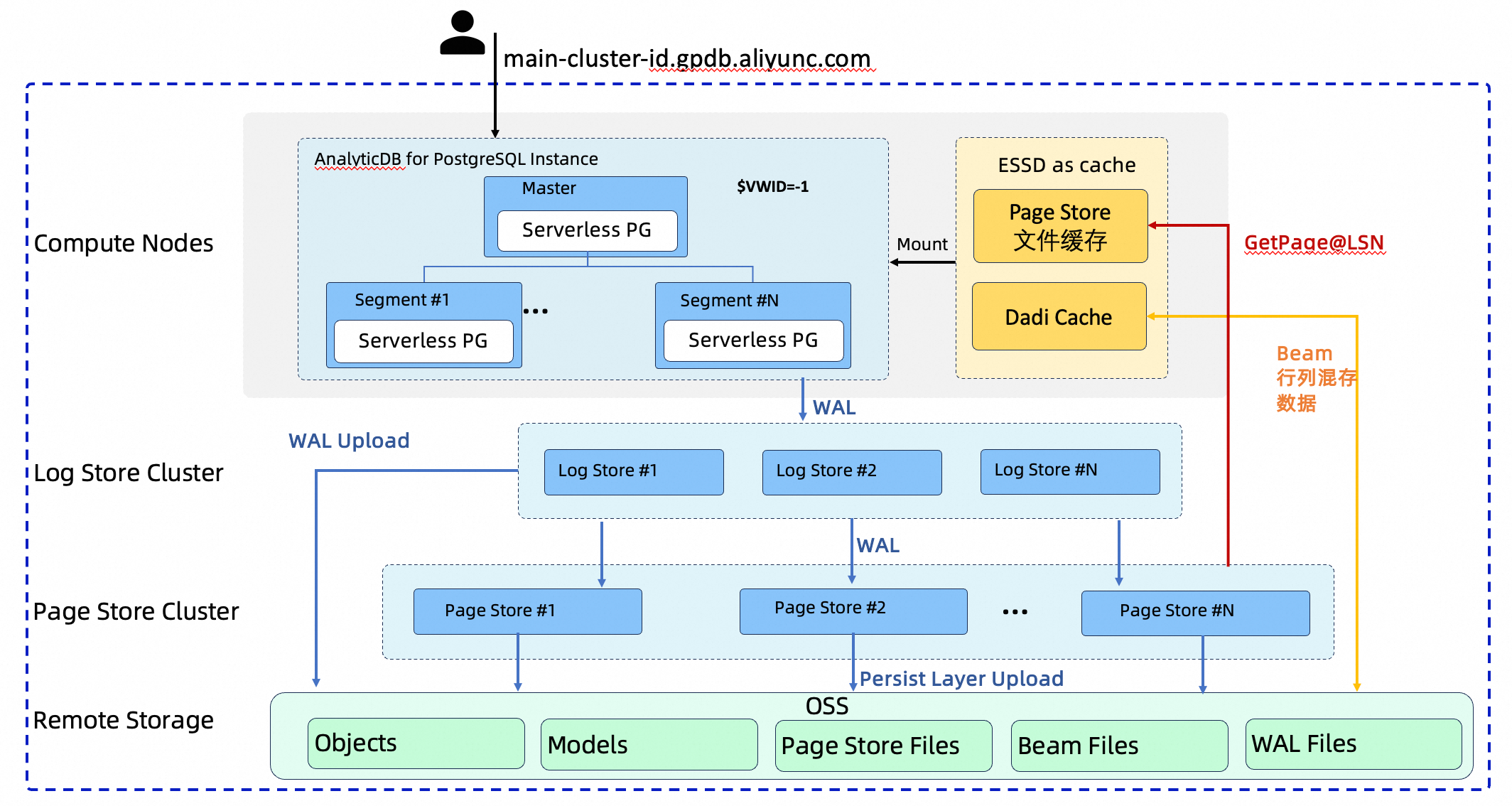
Serverless Pro 的设计基于 Log-as-database 思想,将数据库的“随机写 Page”操作转化为对 WAL (Write-Ahead Logging) 的“顺序写”,由存储侧异步回放 WAL 来生成指定 LSN 下的 Page,从而使最终数据可以长期驻留在 OSS 上。
其架构主要分为四层:
计算节点(Compute Nodes):作为无状态或轻状态的计算层运行,负责执行 SQL。内置 Local File Cache 和 Dadi Cache,利用本地 ESSD 云盘作为高性能热数据缓存。
存储节点(Log Store):作为日志服务层,负责持久化计算节点产生的 WAL 日志,并将其异步推送至 Page Store。
存储节点(Page Store):作为数据页服务层,负责消费 WAL 并将其回放为特定 LSN 下的数据页,为计算节点提供
GetPage服务。对象存储(OSS):作为最终的数据持久化层。所有数据,包括 Page Store 生成的数据页、Beam 列存数据、索引文件及 WAL 日志,最终都将归档并持久化在 OSS 上。
产品形态对比
Serverless模式作为一个新的形态,兼容存储弹性模式的大部分功能,两种模式在产品功能方面的对比如下。
功能分类 | 子功能 | 存储弹性模式 | Serverless 模式 |
实例管理 | 实例基本信息 | 支持 | 支持 |
登录数据库(DMS) | 支持 | 支持 | |
创建实例 | 支持 | 支持 | |
释放实例 | 支持 | 支持 | |
重启实例 | 支持 | 支持 | |
实例升降配 | 支持 | 支持 | |
扩缩 Master 节点 | 支持 | 支持 | |
扩容实例 | 支持 | 支持 | |
缩容实例 | 支持 | 支持 | |
小版本升级 | 支持 | 支持 | |
账号管理 | 创建账号 | 支持 | 支持 |
重置密码 | 支持 | 支持 | |
数据库连接 | 连接基本信息 | 支持 | 支持 |
申请外网地址 | 支持 | 支持 | |
监控与报警 | 监控 | 支持 | 支持 |
报警规则 | 支持 | 支持 | |
数据安全 | 白名单 | 支持 | 支持 |
SQL 审计 | 支持 | 支持 | |
SSL | 支持 | 支持 | |
备份恢复 | 支持 | 支持 | |
配置管理 | 参数设置 | 支持 | 支持 |
功能兼容性与约束
Serverless Pro 模式兼容存储弹性模式 95% 以上的功能。在大多数情况下,您可以按照原有语法使用本产品;JDBC/ODBC 接口以及 psql 等客户端工具的使用方法也与存储弹性模式完全一致。
在使用时,请注意以下功能的约束:
类别 | 功能 | 支持情况 | 约束及说明 |
基本功能 |
| 支持 | — |
索引 | 支持 | 支持 B-tree、Hash、GiST、GIN 等 | |
| 支持 | — | |
| 支持 | — | |
| 支持 | 仅支持 Heap 表,AO/AOCS 表不支持 | |
UNLOG 表 | 支持 | 非日志表,适用于临时数据 | |
触发器 | 支持 | 仅支持 Heap 表 | |
HEAP 表 / Beam 表 | 支持 | 默认行存表类型 | |
AO / AOCS 表 | 不支持 | 列存表在部分场景受限(如不支持触发器、ON CONFLICT) | |
自定义类型 | 支持 | 包括复合类型、枚举、范围类型等 | |
显式游标 | 支持 | — | |
计算引擎 | ORCA 优化器 | 支持 | 默认启用,适用于复杂查询 |
Laser 引擎 | 支持 | 高性能向量化执行引擎 | |
事务能力 | 子事务 | 支持 | 支持 |
事务隔离级别 | 支持 | 仅支持读已提交和可重复读 | |
高级功能 | 备份恢复 | 支持 | 支持 PITR(时间点恢复) |
物化视图 | 支持 | 支持自动/手动刷新 | |
AUTO VACUUM | 支持 | 自动清理死元组,建议保持开启 | |
AUTO ANALYZE | 支持 | 自动收集统计信息 | |
在线扩容 | 支持 | 可动态增加节点,业务不中断 | |
在线缩容 | 支持 | 可动态减少节点(需满足最小节点数要求) | |
GIS / Ganos | 支持 | 内置时空数据处理能力 | |
数据共享 | 不支持 | 暂不支持跨实例或跨集群的数据共享 |
数据迁移
您可以将现有数据迁移至Serverless模式中,AnalyticDB PostgreSQL版存储弹性模式和存储预留模式迁移至Serverless模式请参见AnalyticDB PostgreSQL版间的数据迁移。更多数据迁移支持情况,请参见下表。
迁移类型 | 方案 | Serverless Pro 模式支持情况 |
数据写入 | 支持 | |
支持 | ||
支持 | ||
表级迁移 | 支持 | |
支持 | ||
支持 | ||
支持 | ||
支持 | ||
暂不支持 |
特色功能:Virtual Warehouse
Virtual Warehouse 是 Serverless Pro 模式实现“一写多读”的核心功能。它允许您在共享同一份底层数据的基础上,创建多个相互隔离的、独立的只读计算集群,用于承载不同的读负载。
未来规划:Time Travel & Branching
基于 Serverless Pro 的存算分离与一写多读架构,我们将进一步推出 Time Travel (数据回溯)与 Branching(数据分支)能力。在不复制全量数据的前提下,为您提供历史回溯、快速恢复、隔离验证与低成本数据分支等高级能力。
如图所示,除主集群与 Virtual Warehouse 外,您还可以基于同一份共享存储,按需创建:
Time Travel Read Replica:冻结在指定时间点的只读副本
Branch:基于指定时间点的隔离可写分支环境
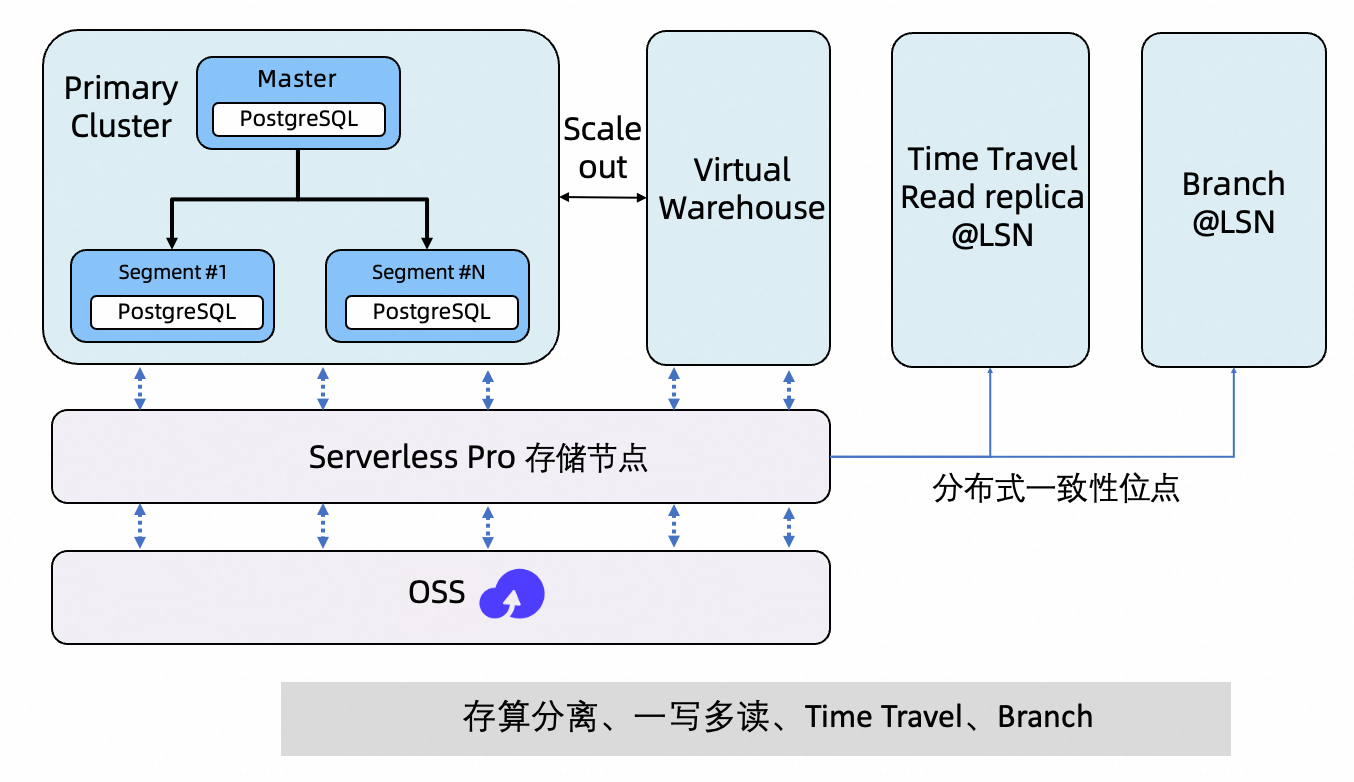
以上为规划中能力,具体上线时间与使用方式请以产品公告与官方文档更新为准。
Time Travel (数据回溯)
允许您基于任意历史时间点(LSN),快速创建一个“冻结在该时刻”的只读副本,并挂载独立的 VW 进行查询,而无需恢复备份或复制全量数据。
典型场景:误操作追溯、审计核对、历史问题复现、数据对账与报表回溯。
Branching (数据分支)
允许您基于生产数据的某个时间点,快速拉起一个隔离的可写环境(分支)。您可以在分支中自由进行变更验证、数据修复演练或算法试跑,验证成功后再受控合并,失败则直接丢弃,全过程不影响主库和其他业务。
典型场景:高危变更演练(DDL/索引/参数)、代码回归验证、数据修复沙箱、AI 算法特征加工与多方案并行对比。