
为提升Dify应用的高可用性与安全性,用户可通过AI网关代理Dify的入站与出站流量。本文将具体介绍操作步骤并展示部分功能效果。
AI网关能力简介
AI网关作为外部环境与企业AI应用之间、以及企业 AI 应用与大语言模型服务、MCP 服务之间的桥梁,致力于解决模型集成复杂性、安全合规要求高、管理效率不足等问题,提供统一的流量治理与管控入口。其核心特性包括:
协议标准化:将不同模型的异构 API 统一转换为 OpenAI 兼容的标准化接口格式。
可观测体系:支持Token级度量指标监控(如 QPS、成功率、响应耗时)及请求全链路追踪能力。
安全防护层:提供 API-KEY 自动轮转、JWT 身份认证、敏感内容实时检测与拦截机制。
稳定性引擎:集成多级 Fallback 策略、AI 缓存加速、Token 粒度限流等流量治理功能。
在高可用性方面,AI网关提供了一整套面向AI应用与模型优化的高可用保障机制,确保服务的持续性、稳定性与可靠性。
多维度请求限流:支持按应用、模型等维度,基于秒级、分钟级、小时级等时间粒度对请求流量进行精细化控制,有效应对突发流量与高并发场景,防止服务过载,保障系统稳定性。
Token级资源流控:在请求量控制基础上,提供基于Token消耗量的流控能力,实现对大模型资源使用的精准管控,避免个别高消耗请求导致资源池耗尽,提升资源分配的公平性与合理性。
模型Fallback机制:当主模型服务发生故障或响应异常时,网关可自动且透明地将请求路由至预配置的备用模型,确保核心业务连续性,实现秒级故障切换与容灾恢复。
模型负载均衡:面向自建模型集群,支持GPU感知、前缀匹配等智能负载均衡策略,在不增加硬件投入的前提下,提升系统吞吐量、降低响应延迟,最大化GPU资源利用效率。
AI缓存机制:对高频及重复请求的响应结果进行缓存处理,由网关直接返回缓存内容,显著减少对底层大模型的调用次数,有效提升响应速度并降低调用成本。
AI网关代理Dify应用出入流量
使用AI网关提升Dify应用的高可用性、安全性和可观测性,需将AI网关与Dify系统进行集成。集成方案如下:
在原有架构中,Dify内置Nginx作为反向代理处理入口流量,Dify直接调用大模型、RAG服务、Mcp Server等后端服务。
在新架构中,AI网关替代Dify内置Nginx,统一代理Dify应用的所有入站和出站流量。
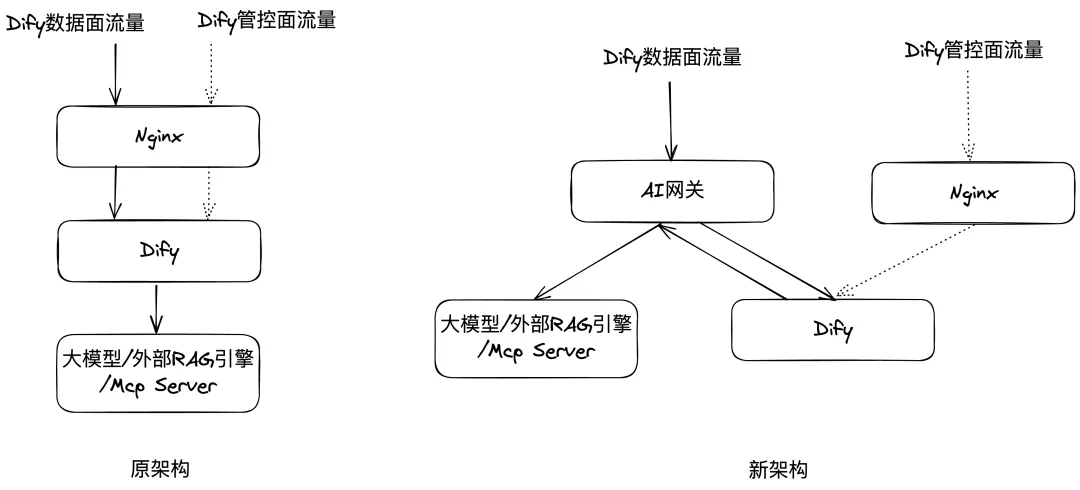
在入流量代理场景中,建议由AI网关直接替代Nginx,而非将AI网关作为Nginx的上游进行路由,主要原因如下:
1. 能力全覆盖:AI网关已全面覆盖Nginx的反向代理功能,并提供超过20项面向AI服务的专用治理策略。Nginx默认启用的缓冲机制会中断SSE流式响应,需手动调优多项参数以支持流式传输,配置复杂且缺乏深度可观测性支持。
2. 架构精简化:由AI网关直接代理流量至Dify服务,可消除额外的代理层级。若采用双网关架构(AI网关>Nginx>Dify),将引入不必要的网络跳转,增加延迟并影响性能;同时故障排查需覆盖Nginx层,延长问题定位周期,降低运维效率。
3. 运维成本优化:Nginx需独立部署并消耗额外计算与内存资源,扩缩容依赖人工干预。流量路由变更需在两套系统间同步配置,易引发配置不一致风险。相比之下,AI网关采用托管部署模式,提供企业级SLA保障,原生集成监控、日志与告警能力,显著降低运维复杂度与总体拥有成本。
操作步骤
Dify应用入流量代理
AI 网关支持创建 Agent API,代理访问 AI 应用,并针对访问 AI 应用的流量提供观测、安全、高可用治理等能力。
步骤一:创建服务来源
在AI网关中为Dify的API组件创建服务来源时,若Dify部署于SAE或ACK环境,可参照以下方式配置服务发现:
SAE(通过SAE或计算巢Dify社区版-Serverless部署)
登录AI网关控制台。
在左侧导航栏,选择实例,并在顶部菜单栏选择地域。
在实例页面,单击目标实例ID。
在左侧导航栏选择服务,单击创建服务,服务来源选择SAE Kubernetes服务,命名空间选择Dify应用所属的命名空间,在服务列表选择
dify-api-{namespace}应用。单击确定完成服务配置。
ACK(通过 ACK Helm 或计算巢 Dify 社区版-高可用版部署)
在服务-来源-创建来源处创建容器来源后,在服务-服务-创建服务处添加对应容器服务中 dify-system 命名空间下的 ack-dify-api。
登录AI网关控制台。
在左侧导航栏,选择实例,并在顶部菜单栏选择地域。
在实例页面,单击目标实例ID。
在左侧导航栏选择服务,单击创建服务,服务来源选择容器服务,命名空间选择Dify应用所属的命名空间,服务列表选择以下服务:
ack-dify-api
单击确定完成服务配置。
步骤二:配置路由
通过AI网关使用Agent API为Dify服务配置路由,操作步骤如下:
在实例页面导航栏左侧,选择Agent API。
单击创建Agent API,根据以下设置完成配置并创建。
域名和Base Path可以根据实际情况配置,用于通过域名访问Dify并且避免和其他服务的路径冲突。
勾选转发至后端服务时移除。
协议选择Dify。
单击创建的Agent API,然后单击创建路由,根据使用场景配置路径(Path),Agent服务选择步骤一创建的服务。
说明如需实现一条路由对应一个Dify应用,可在更多匹配规则中配置请求头或请求参数匹配条件,例如设置
header-key=app-id。需要注意通过AI网关访问Dify应用时,需自行在请求中携带对应的匹配字段。如果Dify存在workflow应用,路径选择
/v1/workflows/run。如果Dify存在agent应用,路径选择
/v1/chat-messages。
路由发布后,可通过配置的域名和路径(Path)访问 Dify 应用以进行验证。若请求能够正常调用,则表明入流量代理配置成功。
Dify应用出流量代理
AI网关支持通过创建LLM API实现代理访问大模型,支持创建Mcp Server实现Mcp代理,支持通过RAG插件实现Rag检索代理,并为不同类型的流量提供可观测性、安全控制及高可用治理等能力。
在Dify应用中,访问大模型和外部知识库是主要使用场景,本节将重点介绍AI网关代理大模型与外部知识库流量的配置方法。
模型流量代理
在AI网关控制台创建Model API,用于访问自建或第三方大模型,参考管理Model API。
前往Dify应用市场,安装OpenAI-API-compatible插件。
前往Dify控制台,在右上角点击设置>模型供应商,为OpenAI-API-compatible添加模型,以LLM模型为例:
模型类型选择LLM。
API endpoint URL填写在AI网关创建的Model API的域名+前缀。
其他参数可按需配置。
在应用中需要选择模型的节点,选择上述步骤创建的模型。
在Dify中运行Workflow或Agent,验证通过AI网关代理访问LLM可以正常返回结果,说明大模型出流量代理配置生效。

外部知识库代理
部分Dify用户在利用Dify的高效构建与编排能力的同时,期望能够连接并访问百炼、RAGFlow等外部知识库,以提升RAG效果。
AI网关提供专为Dify设计的RAG代理插件,支持Dify便捷、高效地对接外部知识库,降低用户自行实现的技术难度与开发成本。
关于RAG代理插件的具体介绍和操作步骤请详见AI RAG 检索代理。
高可用能力效果展示
在完成上述步骤并配置AI网关代理Dify应用的入站与出站流量后,可按需启用AI网关提供的各项能力,对Dify应用的 AI 流量进行观测与治理。本节以高可用治理能力为例,展示部分功能效果。更多AI网关能力请参见什么是AI 网关。
Dify应用入流量治理
通过将AI网关作为Dify应用的流量入口,可在AI网关上配置集群限流策略,实现全局级、应用级等多维度的流量控制。本节以应用级限流为例进行说明。
为支持全局级与应用级限流,需引入Redis实例用于计数。由于Redis是Dify系统存储架构中的必要组件,可直接复用现有Dify系统的Redis实例。
在AI网关中完成Redis实例接入后,可通过插件市场启用基于Key集群限流插件,配置相应规则,实现对不同Dify应用的独立限流策略。该插件的详细配置方法请参见cluster-key-rate-limit插件。
以以下配置为例,对某Dify应用设置1分钟只允许通过一次的请求。
rule_name: dify_higress_demo_rule
rule_items:
- Limit_by_header: x-app-id
limit_keys:
- key: 9a342******************3e1250b5
query_per_minute: 1
redis:
service_name: dify-redis.dns
show_limit_quota_header: true插件启用后,对该应用发起调用时,若在一分钟内发送第2次请求,将触发 AI 网关的限流规则,导致请求失败。而其他未配置流控规则的应用仍可被无限制地调用。

Dify应用出流量治理
请求限流与Token限流
通过AI网关代理Dify应用对模型服务的调用,可实现不同时间粒度的请求数限流,其配置方法与效果与前述内容一致,仅限流策略施加位置不同,此处不再重复说明。
此外在Dify应用调用模型服务的场景中,还可基于token消耗量进行流量控制,详细使用说明请参见限流。
以以下配置为例,设置Model API每分钟限流500Token。

配置生效后,当模型服务整体在1分钟时间范围内超出500Token消耗后,访问模型的请求将会被AI网关直接拒绝。

模型Fallback
为模型访问配置Fallback机制,可在默认模型服务响应异常时,自动切换至备用模型服务,保障模型调用的连续性与高可用性,从而提升Dify应用的整体服务可用性。具体配置步骤及使用方法请参见AI Fallback。
为验证Fallback机制的效果,本示例中将Dify应用所访问的Model API的主模型服务配置为不可达地址,同时配置百炼模型服务作为可正常访问的备用模型服务。运行Dify应用,能够看到LLM节点依然能正常返回结果,工作流运行正常。

配置生效后运行Dify应用,可以观察到LLM节点依然能正常返回结果,工作流运行正常。

通过网关日志可以发现AI网关在访问主模型服务时发生了503异常,于是自动Fallback至百炼模型进行调用,并返回正常调用结果,从而保证Dify应用整体运行正常。
高级负载均衡
针对Dify访问自建模型(例如在阿里云 PAI 上部署的模型)的场景,AI网关提供面向LLM服务的多种负载均衡策略,包括全局最小请求数负载均衡、前缀匹配负载均衡和GPU感知负载均衡。这些策略可在不增加硬件成本的前提下,提升系统吞吐量、降低响应延迟,并实现更公平、高效的任务调度。
以前提取匹配负载均衡为例,使用NVIDIA GenAI-Perf作为压测工具,配置每轮输入平均200 token、输出平均800 token,并发数为20,每个会话包含5轮对话,共执行60个会话。性能测试结果显示,启用该负载均衡策略后,首Token延迟有明显降低,表明合理的负载均衡策略可显著优化响应性能。
指标 | 无负载均衡 | 前缀匹配负载均衡 |
TTFT(首Token延迟) | 240 ms | 120 ms |
平均 RT | 14934.85 ms | 14402.36 ms |
P99 RT | 35345.65 ms | 30215.01 ms |
Token 吞吐 | 367.48 (token/s) | 418.96 (token/s) |
Prefix Cache 命中率 | 40 % + | 80 % + |
以前提取匹配负载均衡为例,针对Dify应用访问的Model API,可通过插件方式便捷配置负载均衡策略,具体配置方式如下所示。插件生效后,Dify应用通过AI网关对LLM服务发起调用,即可实现对自建LLM服务实例的负载均衡。
lb_policy: prefix_cache
Ib_config:
serviceFQDN: redis.dns
servicePort: 6379
username: default
password: xxxxxxxxxxxx
redisKeyTTL: 60