
本文为您介绍离线同步的相关问题。
文档概述
在查看相关问题时,您可以通过匹配关键字来查找常见相似问题及其对应的解决方案。
问题分类 | 问题关键字 | 相关文档 |
离线同步任务运维常见问题 | ||
非插件报错原因及解决方案 | ||
具体插件报错原因及解决方案 | ||
离线同步场景及解决方案 | ||
使用API方式同步的时候,支持使用来源端的(例如MaxCompute)函数做聚合吗?例如源表有a、b两列作为Lindorm的主键 | ||
报错信息及解决方案 | ||
读取OSS数据报错:AccessDenied The bucket you access does not belong to you. | ||
网络通信问题
为什么数据源测试连通性成功,但是离线同步任务执行报错数据源连接失败?
离线同步任务执行偶尔成功偶尔失败
资源设置问题
离线同步任务,运行报错:[TASK_MAX_SLOT_EXCEED]:Unable to find a gateway that meets resource requirements. 20 slots are requested, but the maximum is 16 slots.
离线同步任务,运行报错:OutOfMemoryError: Java heap space
实例运行冲突
离线任务,运行报错:Duplicate entry 'xxx' for key 'uk_uk_op'
运行超时
离线同步任务,源端为MongoDB,运行报错:MongoDBReader$Task - operation exceeded time limitcom.mongodb.MongoExecutionTimeoutException: operation exceeded time limit.
离线同步任务,数据源为MySQL,运行报错连接超时:Communications link failure
如何排查离线同步任务运行时间长的问题?
数据同步任务where条件没有索引,导致全表扫描同步变慢
切换资源组
如何切换离线同步任务的执行资源组?
脏数据
脏数据如何排查和定位?

离线同步传输数据时,脏数据超出限制,已同步的数据是否会保留?
如何处理编码格式设置/乱码问题导致的脏数据报错?
源表默认值是否保留
源表有默认值,通过数据集成创建的目标表,默认值、非空属性等会保留吗?
切分键
离线集成任务配置切分键时,联合主键是否可以作为切分键?
数据缺失
数据同步完成,目标表中的数据与源端表数据不一致
SSRF攻击
任务存在SSRF攻击Task have SSRF attacks如何处理?
日期写入
日期时间类型数据写入文本时,如何保留毫秒或者指定自定义日期时间格式?
同步任务转脚本模式后,在配置任务页面的setting部分增加以下配置项:
"common": {
"column": {
"dateFormat": "yyyyMMdd",
"datetimeFormatInNanos": "yyyyMMdd HH:mm:ss.SSS"
}
}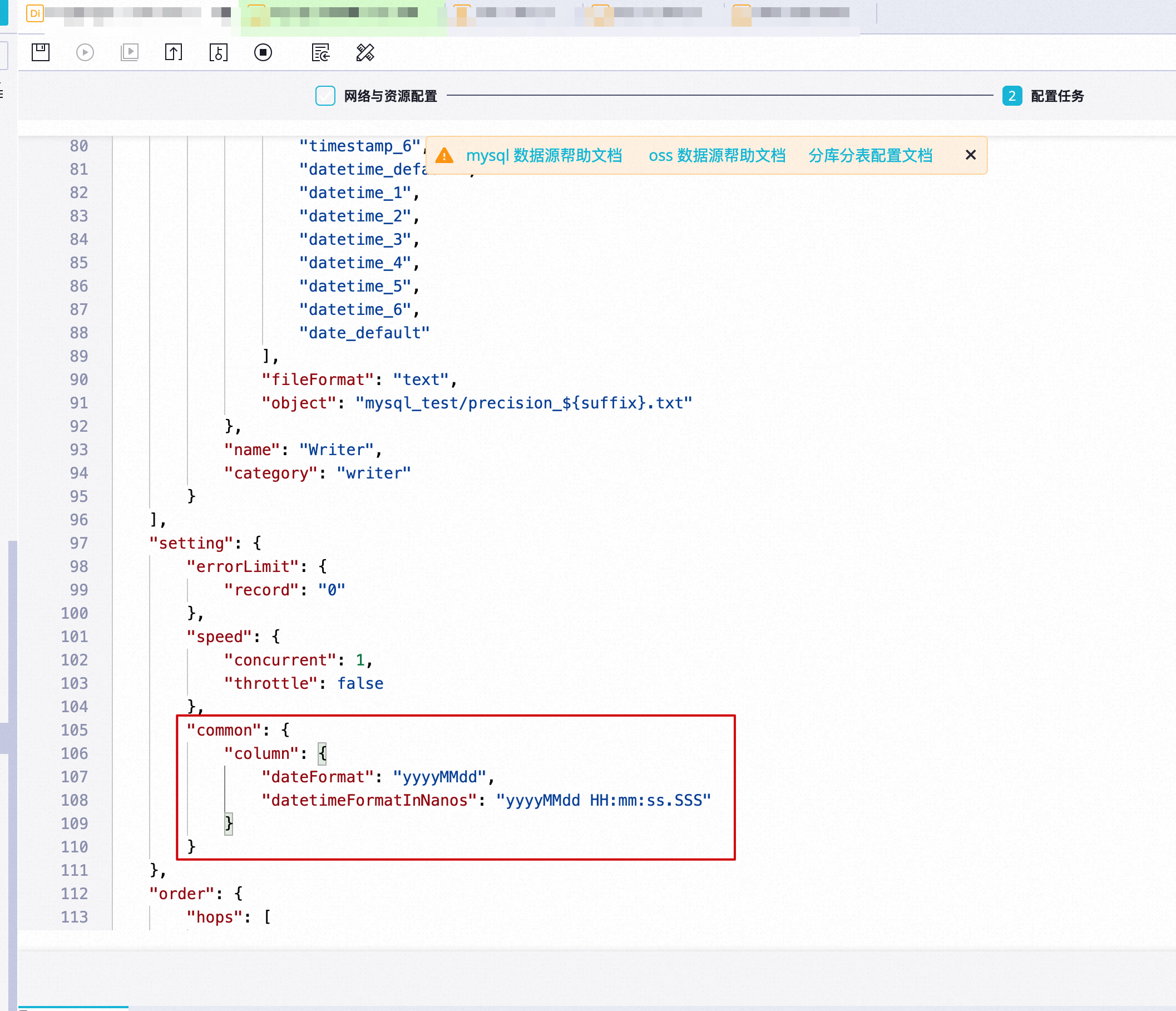
其中:
dateFormat表示源端DATE(不带时分秒)类型转文本时的日期格式。
datetimeFormatInNanos表示源端DATETIME/TIMESTAMP(带时分秒)类型转文本时的日期格式,最多可指定到毫秒。
MaxCompute
读取MaxCompute(ODPS)表数据时,字段映射源表字段「添加一行」或「添加字段」注意事项
读取MaxCompute(ODPS)表数据时,如何同步分区字段?
在字段映射列表的源表字段下单击添加一行或添加字段,输入分区列名,如pt,并与目标表字段配置映射关系。

读取MaxCompute(ODPS)表数据时,如何同步多个分区数据?
MaxCompute如何实现列筛选、重排序和补空等
MaxCompute列配置错误的处理
MaxCompute分区配置注意事项
MaxCompute任务重跑和failover
读取MaxCompute(ODPS)表数据报错:The download session is expired.
写入MaxCompute(ODPS)报错block失败:Error writing request body to server
MySQL
MySQL分库分表如何将分表同步到一张MaxCompute中
目的端MySQL表字符集为utf8mb4时,同步到MySQL中的中文字符出现乱码时,如何处理?
写入/读取MySQL报错:Application was streaming results when the connection failed. Consider raising value of 'net_write_timeout/net_read_timeout' on the server.
报错原因:
net_read_timeout:DataX将RDS MySQL根据SplitPk对MySQL的数据进行拆分成数条等量的取数SQL(SELECT取数语句),执行时某条SQL执行时间超过RDS侧允许的最大运行时间。
net_write_timeout:等待将一个block发送给客户端的超时时间过小导致。
解决方案:
在数据源URL的连接上增加该参数,net_write_timeout/net_read_timeout设置稍微大一些,或者在RDS控制台调整该参数。
改进建议:
如果任务可以重跑建议设置任务自动重跑。
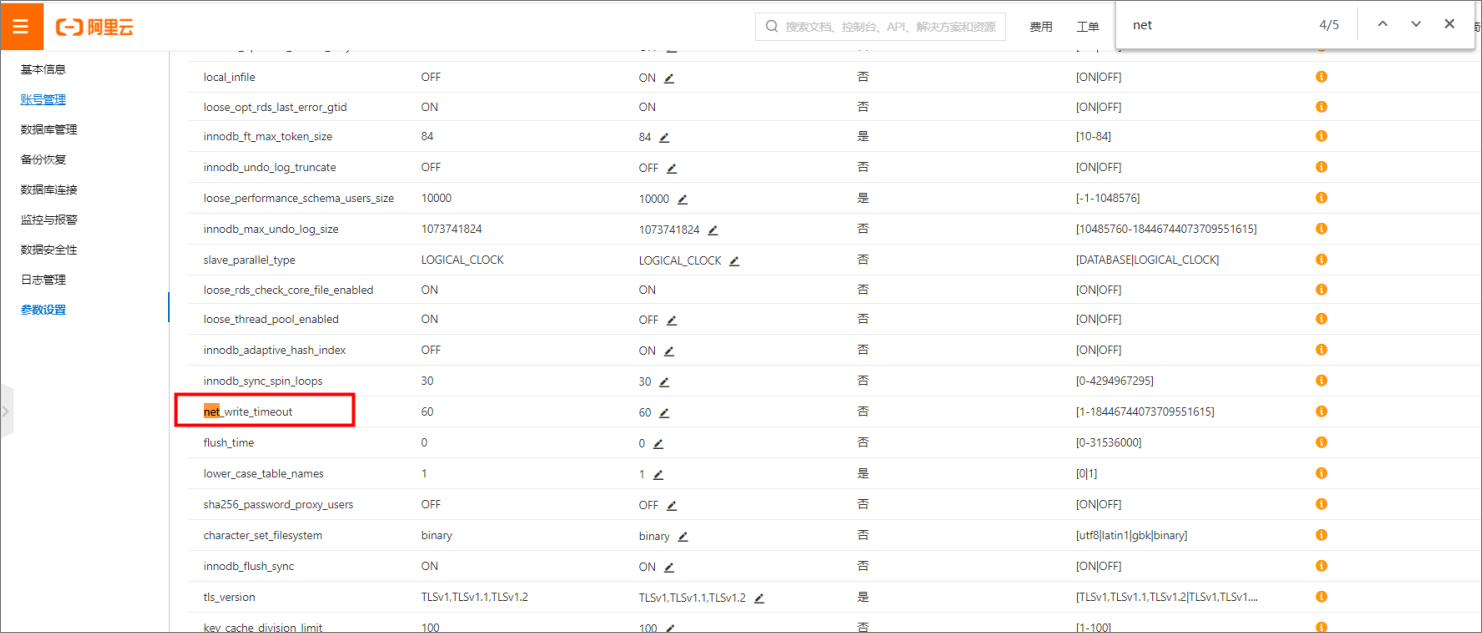
例如:jdbc:mysql://192.168.1.1:3306/lizi?useUnicode=true&characterEncoding=UTF8&net_write_timeout=72000
离线同步至MySQL报错:[DBUtilErrorCode-05]ErrorMessage: Code:[DBUtilErrorCode-05]Description:[往您配置的写入表中写入数据时失败.]. - com.mysql.jdbc.exceptions.jdbc4.MySQLNonTransientConnectionException: No operations allowed after connection closed
读取MySQL数据库报错:The last packet successfully received from the server was 902,138 milliseconds ago
PostgreSQL
读取PostgreSQL数据报错:org.postgresql.util.PSQLException: FATAL: terminating connection due to conflict with recovery
RDS
离线同步源端是亚马逊的RDS时报错:Host is blocked
MongoDB
添加MongoDB数据源时,使用root用户时报错
读取MongoDB时,如何在query参数中使用timestamp实现增量同步?
MongoDB同步至数据目的端数据源后,时区加了8个小时,如何处理?
读取MongoDB数据期间,源端有更新记录,但未同步至目的端,如何处理?
MongoDB Reader是否大小写敏感?
怎么配置MongoDB Reader超时时长?
读取MongoDB报错:no master
读取MongoDB报错:MongoExecutionTimeoutException: operation exceeded time limit
离线同步读取MongoDB报错:DataXException: operation exceeded time limit
MongoDB同步任务运行报错:no such cmd splitVector
可能原因:
在同步任务运行时,默认优先使用
splitVector命令进行任务分片,在部分MongoDB版本中,不支持splitVector命令,进而会导致报错no such cmd splitVector。解决方案:
进入同步任务配置页面后,单击顶部的转换脚本
 按钮。将任务修改为脚本模式。
按钮。将任务修改为脚本模式。在MongoDB的parameter配置中,增加参数
"useSplitVector" : false以避免使用
splitVector。
MongoDB离线同步报错:After applying the update, the (immutable) field '_id' was found to have been altered to _id: "2"
报错现象:
同步任务中,以向导模式为例,当配置了写入模式(是否覆盖)为是,且配置了非
_id字段作为业务主键,可能会出现此问题。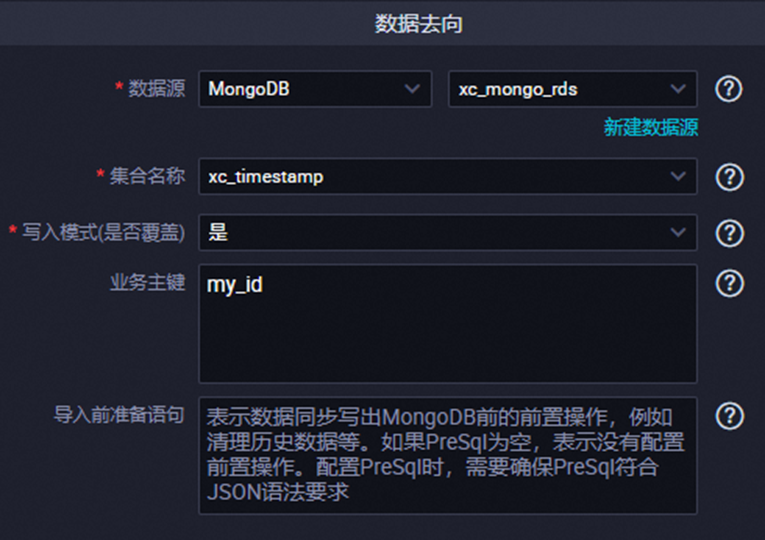
可能原因:
写入数据中,存在_id与配置的业务主键(如上述配置示例的
my_id)不匹配的数据。解决方案:
方案一:修改离线同步任务,确保配置的业务主键与_id一致。
方案二:进行数据同步时,将_id作为业务主键。
Redis
写入Redis使用hash模式存储数据时,报错:Code:[RedisWriter-04], Description:[Dirty data]. - source column number is in valid!
OSS
读取多分隔符的CSV文件,出现脏数据如何处理?
读取OSS文件是否有文件数限制?
写入OSS,文件名出现随机字符串如何去除?
读取OSS数据报错:AccessDenied The bucket you access does not belong to you.
Hive
离线同步数据至本地Hive报错:Could not get block locations.
DataHub
写入DataHub时,一次性写入数据超限导致写入失败如何处理?
LogHub
读取LogHub同步某字段有数据但是同步过来为空
读取LogHub同步少数据
读取LogHub字段映射时读到的字段不符合预期
Lindorm
使用lindorm bulk方式写入数据,是否每次都会替换掉历史数据?
Elasticsearch
如何查询一个ES索引下的所有字段?
数据从ES离线同步至其他数据源中时,每天同步的索引名称不一样,如何配置?
索引配置时可以加入日期调度变量,根据不同的日期计算出索引字符串,实现Elasticsearch Readers索引名的自动变化,配置过程包含如下三步:定义日期变量、配置索引变量、任务发布与执行。
定义日期变量:在同步任务的调度配置中,选择新增参数定义日期变量。如下var1配置表示任务执行时间(当天),var2表示任务的业务日期(前一天)。详情请参见调度参数配置最佳实践。
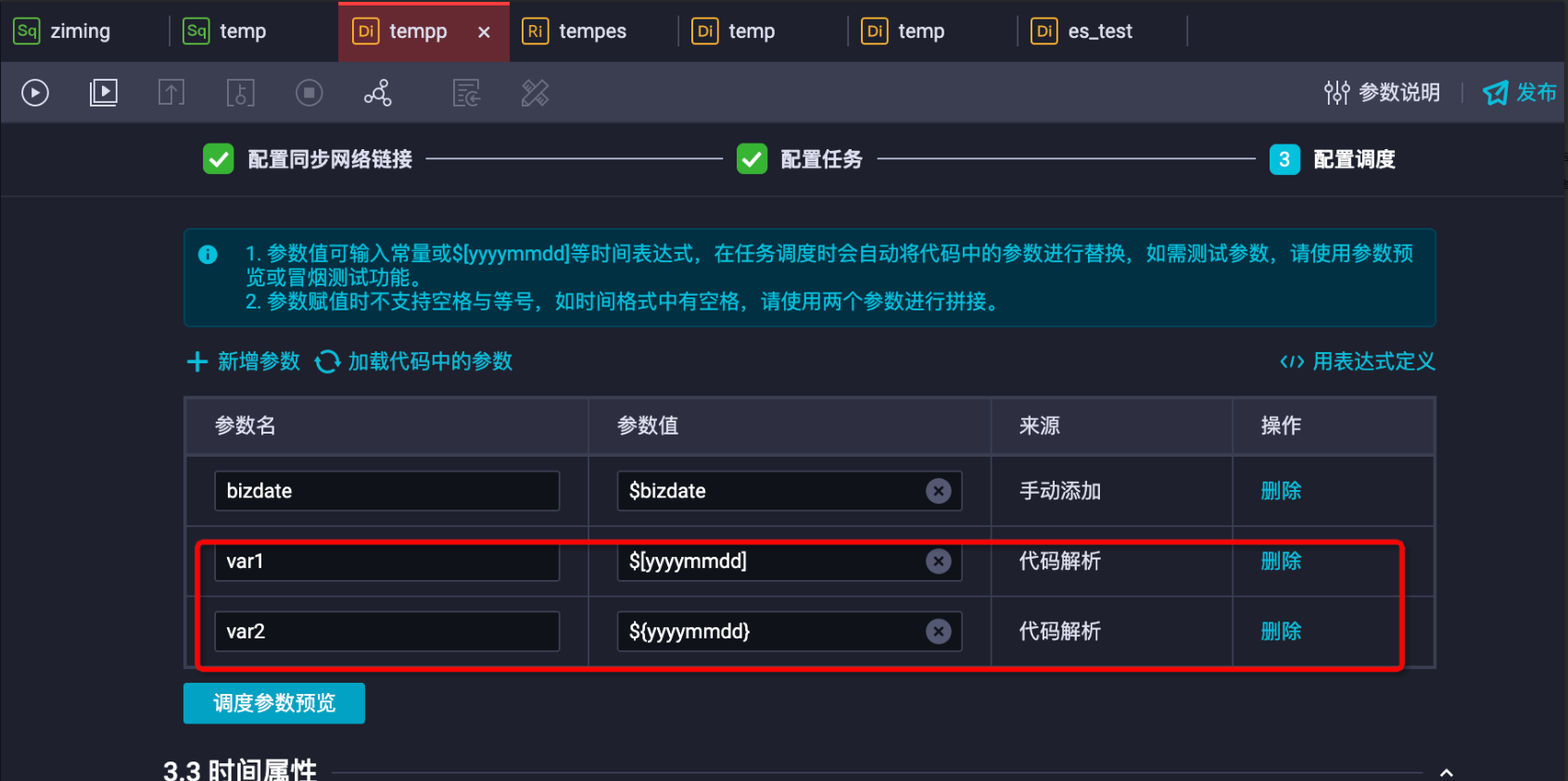
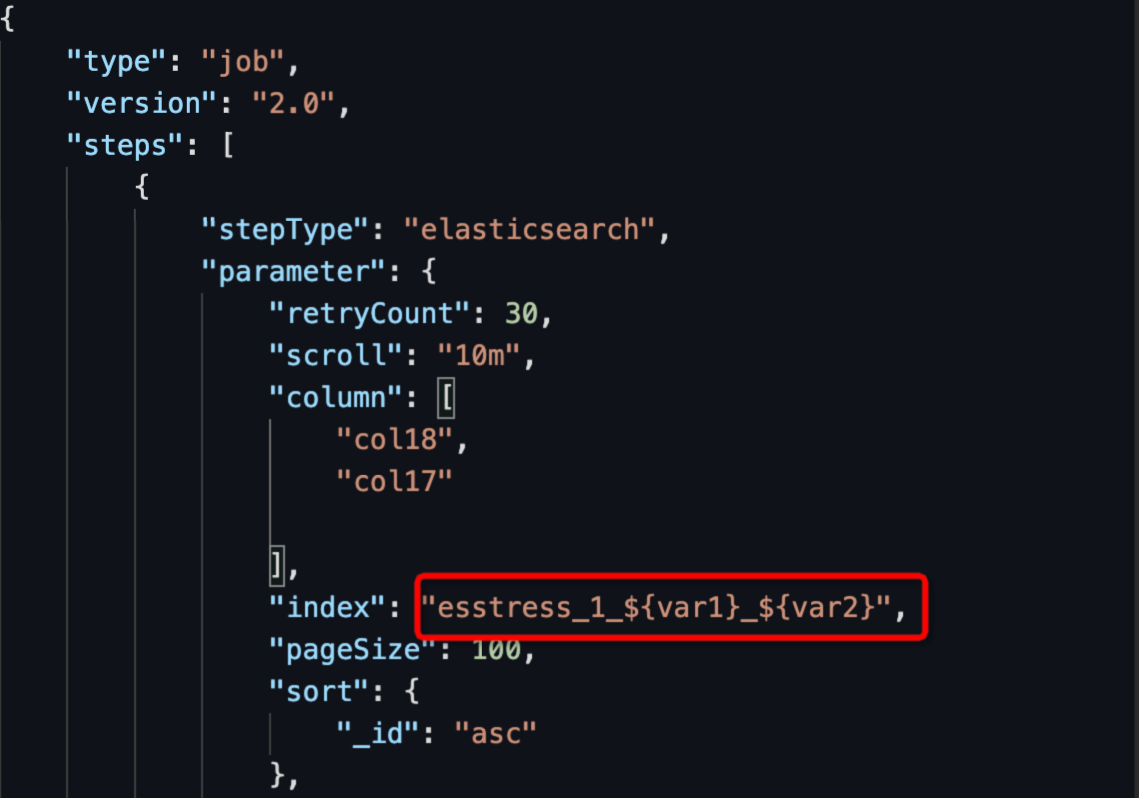
配置索引变量:将任务转为脚本模式,配置Elasticsearch Readers的索引,配置方式为:${变量名},如下图所示。
任务发布与执行:执行验证后,将任务提交发布至运维中心,以周期调度或补数据的方式运行。
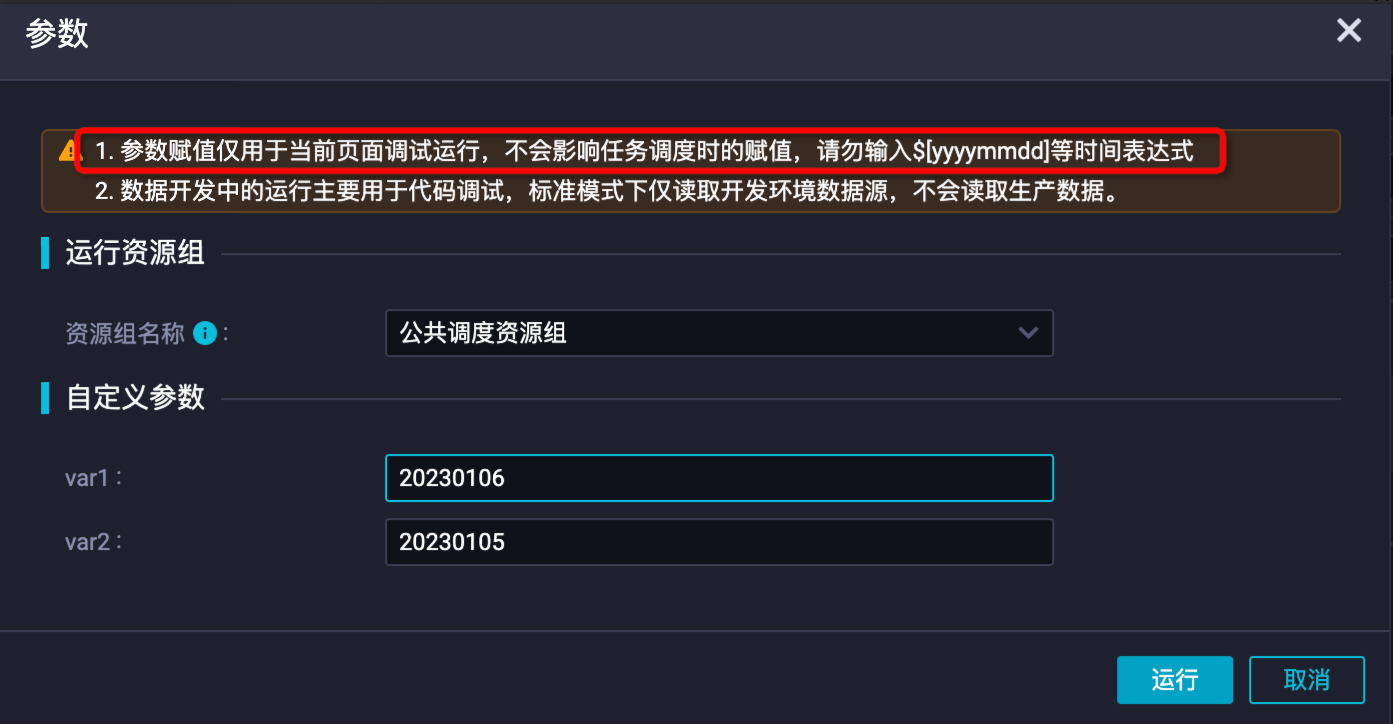
单击带参运行按钮直接运行任务进行验证,带参运行会将任务配置中使用的调度系统参数进行替换,执行后查看日志同步索引是否符合预期。
说明注意在带参运行时直接输入参数值进行替换测试。

如果上一步验证符合预期,则任务配置已经完成,此时可以依次单击保存和提交按钮将同步任务提交到生产环境。
如果是标准项目,需要单击发布按钮进入发布中心才能将同步任务发布到生产环境。

结果:如下是配置与实际运行的索引结果。
脚本索引配置为:
"index": "esstress_1_${var1}_${var2}"。运行索引替换为:
esstress_1_20230106_20230105。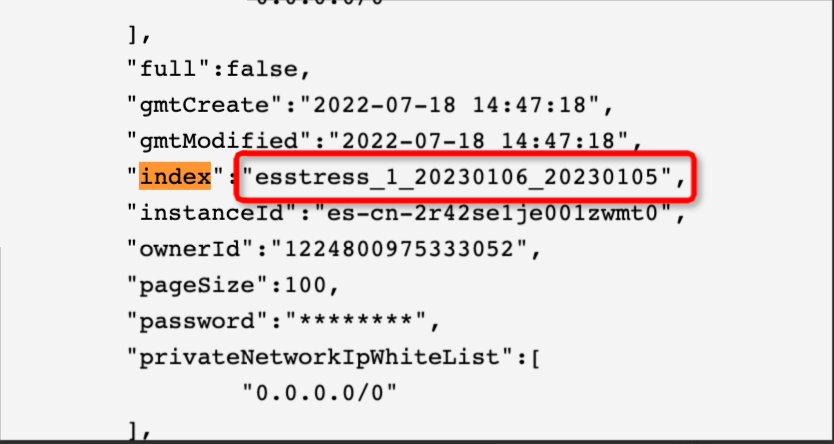
Elasticsearch Reader如何同步对象Object或Nested字段的属性?(例如同步object.field1)
存储在ODPS的string类型同步至ES后,两侧缺少引号,如何处理?源端JSON类型的string是否可以同步为ES中的NESTED对象?
显示字符前后多两个双引号为“Kibana”工具显示问题,实际数据并没有前后双引号,请使用curl命令或Postman查看实际数据情况。获取数据curl命令如下:
//es7 curl -u username:password --request GET 'http://esxxx.elasticsearch.aliyuncs.com:9200/indexname/_mapping' //es6 curl -u username:password --request GET 'http://esxxx.elasticsearch.aliyuncs.com:9200/indexname/typename/_mapping'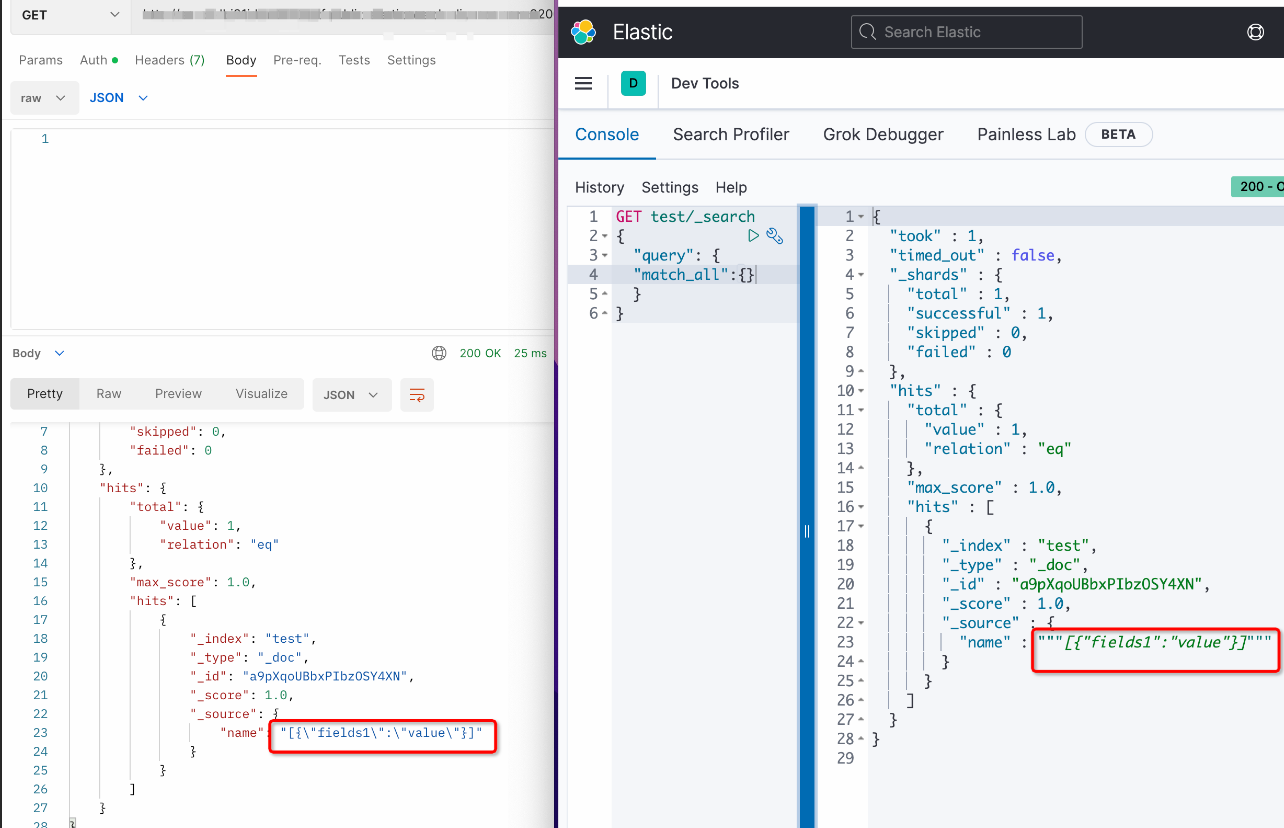
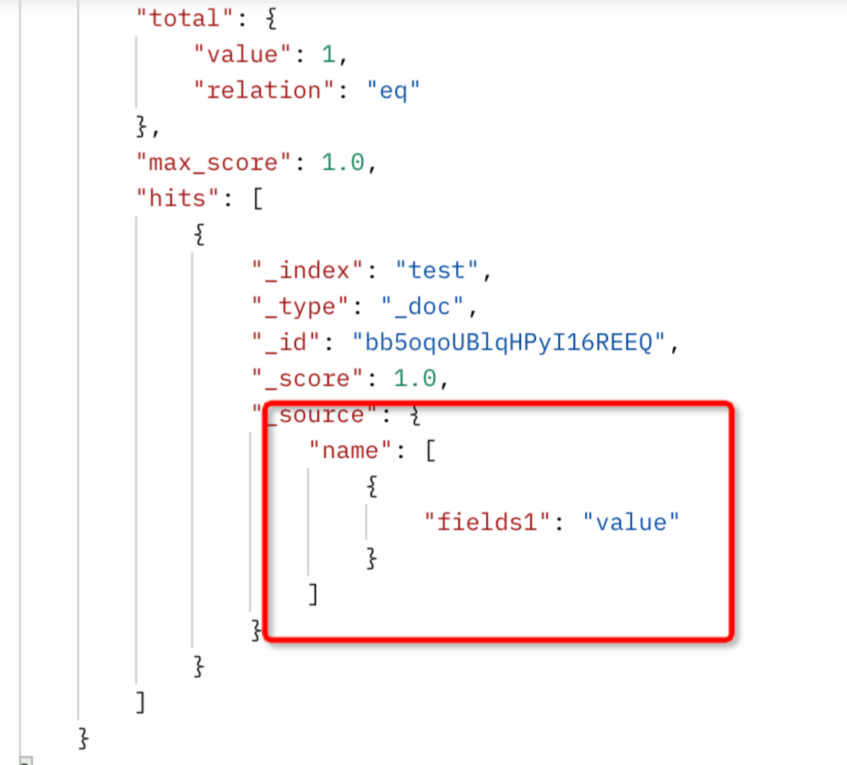
可以配置ES写入字段type为nested类型,以同步ODPS中JSON类型的string数据至ES存储为nested形式。如下同步name字段到ES中为nested格式。
同步配置:配置name的type为nested。
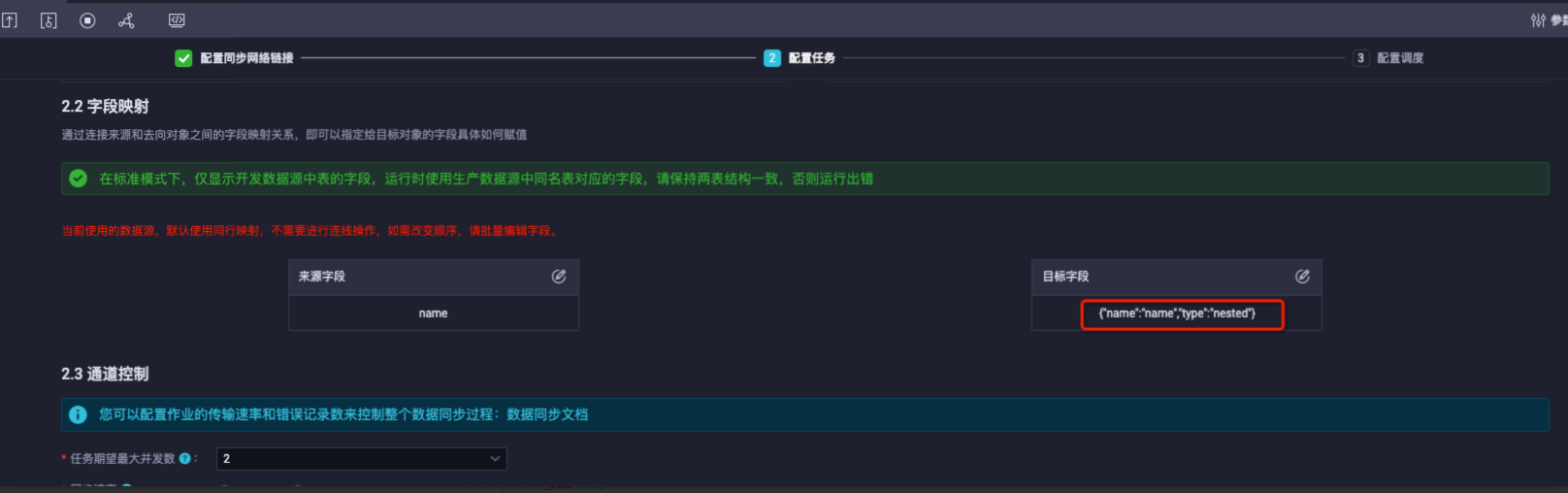
同步结果:name是nested对象类型。
源端数据为string "[1,2,3,4,5]",如何以数组形式同步至ES中存储?
ES期望写入数组类型有两种配置方式,您可以按照源端数据形式,选择对应的同步方式进行配置。
写入ES为数组类型以JSON格式解析源端数据。例如,源端数据为"[1,2,3,4,5]",配置
json_array=true解析源端数据,以数组形式写入ES字段,配置ColumnList为json_array=true。向导模式配置:
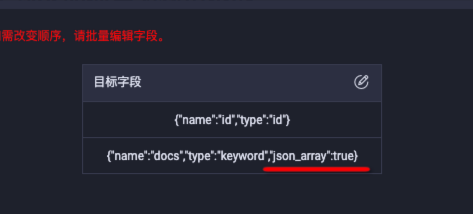
脚本模式配置:
"column":[ { "name":"docs", "type":"keyword", "json_array":true } ]
写入ES为数组类型以分隔符解析源端数据。例如,源端数据为“1,2,3,4,5”,配置分隔符splitter=“,”以数组形式解析并写入ES字段。
限制:
一个任务仅支持配置一种分隔符,分隔符(splitter)全局唯一,不支持多Array字段配置不同的分隔符,例如,源端列
col1="1,2,3,4,5" , col2="6-7-8-9-10",splitter无法针对每列单独配置使用。splitter可以配置为正则,例如,源端列值为"6-,-7-,-8+,*9-,-10",可以配置splitter:".,.",支持向导模式。
向导模式配置:
 splitter: 默认为"-,-"
splitter: 默认为"-,-"脚本模式配置:
"parameter" : { "column": [ { "name": "col1", "array": true, "type": "long" } ], "splitter":"," }
向ES写入数据时,会做一次无用户名的提交,但仍需验证用户名,导致提交失败,因此提交的所有请求数据都被记录,导致审计日志每天都会有很多,如何处理?
如何同步至ES中为Date日期类型?
Elasticsearch Writer指定外部version导致写入失败,如何处理?
离线同步读取Elasticsearch报错:ERROR ESReaderUtil - ES_MISSING_DATE_FORMAT, Unknown date value. please add "dataFormat". sample value:
离线同步读取Elasticsearch报错:com.alibaba.datax.common.exception.DataXException: Code:[Common-00].
离线同步写入Elasticsearch报错:version_conflict_engine_exception.
离线同步写入Elasticsearch报错:illegal_argument_exception.
分析原因:
Column字段在配置similarity、properties等高级属性时,需要other_params才能让插件识别。
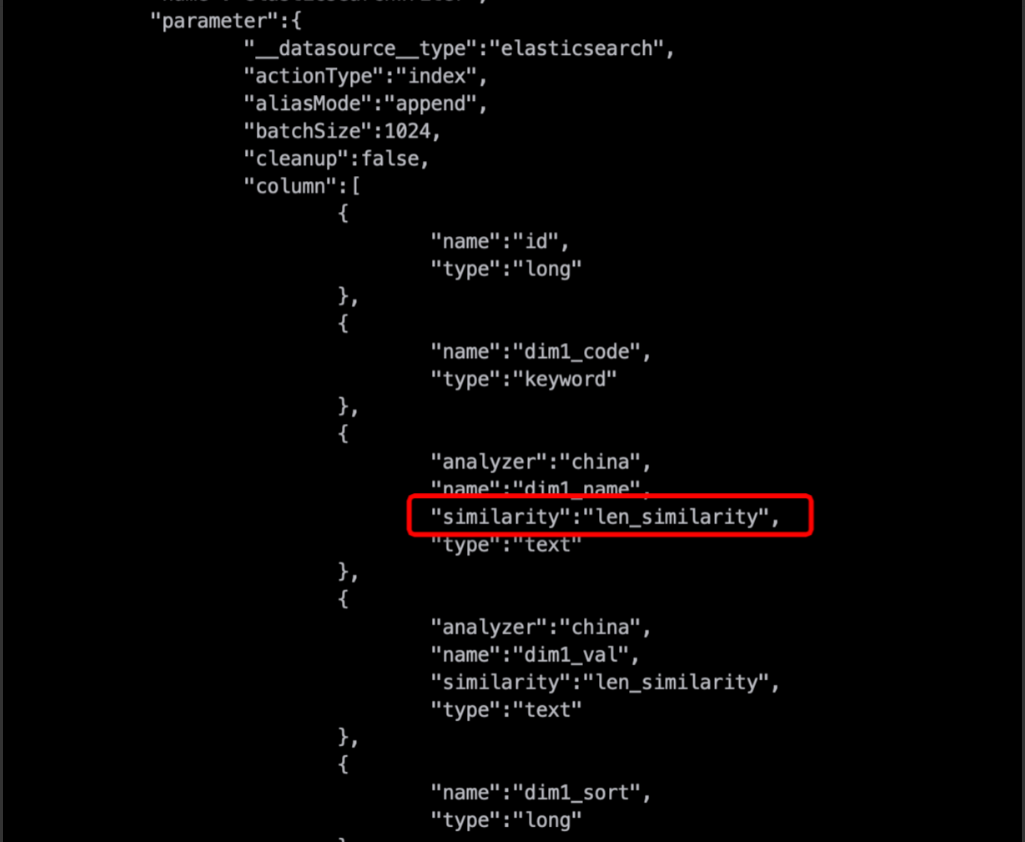
解决方案:
Column里配置
other_params,other_params里增加similarity,如下所示:{"name":"dim2_name",...,"other_params":{"similarity":"len_similarity"}}
ODPS Array字段类型数据离线同步至ElasticSearch报错:dense_vector
Elasticsearch writer配置了Settings,为什么在创建索引时不生效?
自建的索引中nested的属性类型type为keyword,为什么自动生成之后类型会变成 keyword?(自动生成是指配置cleanup=true执行同步任务)
Kafka
读取kafka配置了endDateTime来指定所要同步的数据的截止范围,但是在目的数据源中发现了超过这个时间的数据
Kafka中数据量少,但是任务出现长时间不读取数据也不结束,一直运行中的现象是为什么?
RestAPI
RestAPI Writer报错:通过path:[]找到的JSON串格式不是数组类型
RestAPI Writer提供两种写入模式,当同步多条数据的时候需要将dataMode配置为multiData,详情请参见RestAPI Writer,同时需要在RestAPI Writer脚本中新增参数dataPath:"data.list"。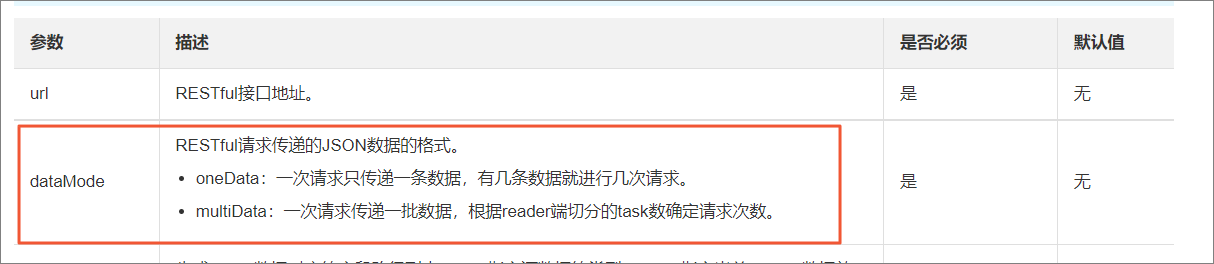
配置Column时不需要加“data.list ”前缀。
OTS Writer配置
向包含主键自增列的目标表写入数据,需要如何配置OTS Writer?
时序模型配置
在时序模型的配置中,如何理解_tag和is_timeseries_tag两个字段?
示例:某条数据共有三个标签,标签为:【手机=小米,内存=8G,镜头=莱卡】。
数据导出示例(OTS Reader)
如果想将上述标签合并到一起作为一列导出,则配置为:
"column": [ { "name": "_tags", } ],DataWorks会将标签导出为一列数据,形式如下:
["phone=xiaomi","camera=LEICA","RAM=8G"]如果希望导出
phone标签和camera标签,并且每个标签单独作为一列导出,则配置为:"column": [ { "name": "phone", "is_timeseries_tag":"true", }, { "name": "camera", "is_timeseries_tag":"true", } ],DataWorks会导出两列数据,形式如下:
xiaomi, LEICA
数据导入示例(OTS Writer)
现在上游数据源(Reader)有两列数据:
一列数据为:
["phone=xiaomi","camera=LEICA","RAM=8G"]。另一列数据为:6499。
现希望将这两列数据都添加到标签里面,预期的在写入后标签字段格式如下所示:
 则配置为:
则配置为:"column": [ { "name": "_tags", }, { "name": "price", "is_timeseries_tag":"true", }, ],第一列配置将
["phone=xiaomi","camera=LEICA","RAM=8G"]整体导入标签字段。第二列配置将
price=6499单独导入标签字段。
自定义表名
离线同步任务如何自定义表名?
如果您表名较规律,例如orders_20170310、orders_20170311和orders_20170312,按天区分表名称,且表结构一致。您可以结合调度参数脚本模式配置自定义表名,实现每天凌晨自动从源数据库读取前一天表数据。
例如,今天是2017年3月15日,自动从源数据库中读取orders_20170314的表的数据导入,以此类推。
在脚本模式中,修改来源表的表名为变量,例如orders_${tablename}。由于按天区分表名称,且需要每天读取前一天的数据,所以在任务的参数配置中,为变量赋值为tablename=${yyyymmdd}。
更多调度参数的使用问题请参考文档调度参数支持的格式
表修改加列
离线同步源表有加列(修改)如何处理?
任务配置问题
配置离线同步节点时,无法查看全部的表,该如何处理?
表/列名关键字
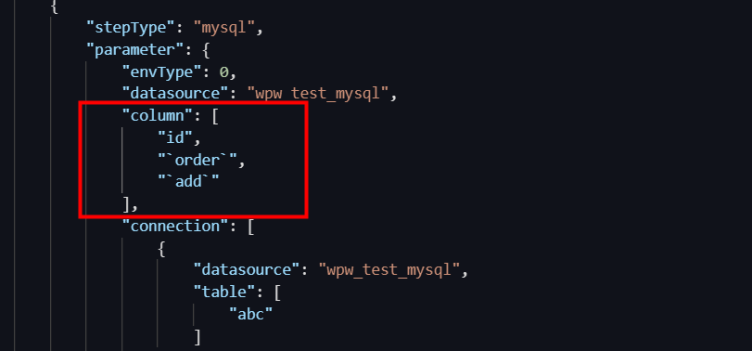
如何处理表列名有关键字导致同步任务失败的情况?
报错原因:column中含有保留字段,或者 column配置中含有数字开头的字段。
解决方法:数据集成同步任务转脚本模式配置,对column配置中的特殊字段进行转义。脚本模式配置任务请参考:脚本模式配置。
MySQL的转义符为
`关键字`。Oracle和PostgreSQL的转义符为
"关键字"。SQL Server的转义符为
[关键字]。
MySQL为场景示例:
以MySQL数据源为例:
执行下述语句,新建一张表aliyun。
create table aliyun (`table` int ,msg varchar(10));执行下述语句,创建视图,为table列取别名。
create view v_aliyun as select `table` as col1,msg as col2 from aliyun;说明table是MySQL的关键字,在数据同步时,拼接出来的代码会报错。因此需要通过创建视图,为table列起别名。
不建议使用关键字作为表的列名。
通过执行上述语句,为有关键字的列取列名。在配置同步任务时,选择v_aliyun视图代替aliyun表即可。
字段映射
离线任务,运行报错:plugin xx does not specify column
非结构化数据源,单击数据预览字段无法映射,如何处理?
问题现象:
在用户单击数据预览时,出现如下提示,大致含义是字段的字节数超长。
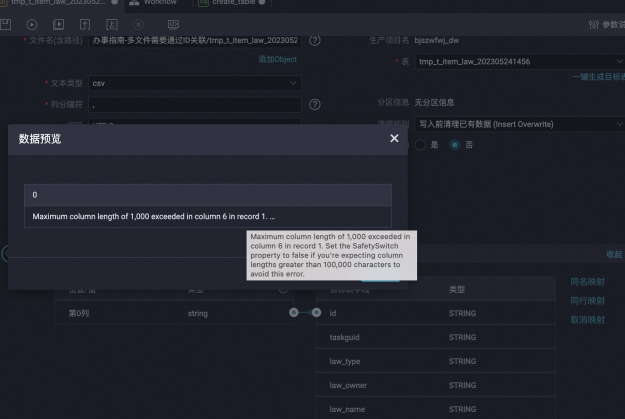
问题原因:为了避免OOM,数据源服务在处理数据预览的请求时会判断字段的长度,如果单个列超过1000字节,就会出现上述提示,此提示并不会影响任务的正常运行,可以忽略该错误直接运行离线同步任务。
说明在文件存在且连通性正常的情况下,导致数据预览失败的情况还有:
文件单行字节数超过限制,限制为10MB。此时不显示数据,类似于上述提示。
文件单行列数超限制,限制为1000列。此时仅显示前1000列,并在第1001列给出提示。