
DataWorks的数据集成为您提供MongoDB Reader插件,可从MongoDB中读取数据,并将数据同步至其他数据源。本文以一个具体的示例,为您演示如何通过数据集成将MongoDB的数据离线同步至MaxCompute。
背景信息
本实践的来源数据源为MongoDB,去向数据源为MaxCompute。在进行数据同步前,您需要参考下文的数据准备,将待同步的MongoDB数据准备好,并创建一个用于同步数据的MaxCompute表。
前提条件
本实践进行操作时,需满足以下条件。
已开通DataWorks并创建MaxCompute数据源。
本实践使用独享数据集成资源组进行离线任务运行,因此您需先购买并配置独享数据集成资源组。操作详情请参见新增和使用独享数据集成资源组。
说明您也可以使用新版资源组(通用型资源组),更多信息,请参见新增和使用新版资源组。
准备示例数据表
本实践需准备一个MongoDB数据集合、一个MaxCompute表,用于后续进行离线数据同步。
准备MongoDB数据集合。
本实践使用阿里云云数据库MongoDB作为示例。以下为准备MongoDB数据集合的主要代码示例。
创建一个名称为
di_mongodb_conf_test的数据集合。db.createCollection('di_mongodb_conf_test')向数据集合中插入本实践的示例数据。
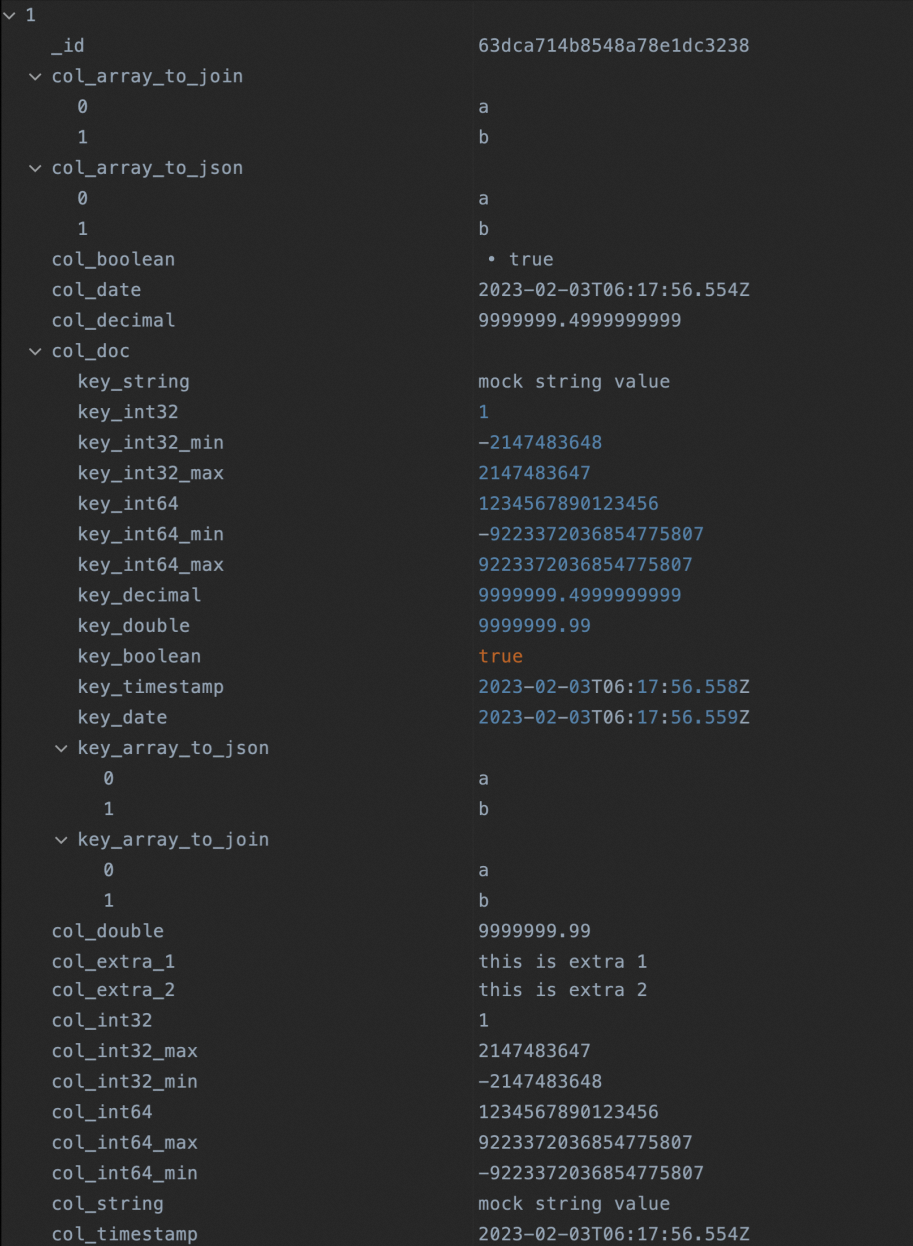
db.di_mongodb_conf_test.insertOne({ 'col_string':'mock string value', 'col_int32':NumberInt("1"), 'col_int32_min':NumberInt("-2147483648"), 'col_int32_max':NumberInt("2147483647"), 'col_int64':NumberLong("1234567890123456"), 'col_int64_min':NumberLong("-9223372036854775807"), 'col_int64_max':NumberLong("9223372036854775807"), 'col_decimal':NumberDecimal("9999999.4999999999"), 'col_double':9999999.99, 'col_boolean':true, 'col_timestamp':ISODate(), 'col_date':new Date(), 'col_array_to_json':['a','b'], 'col_array_to_join':['a','b'], 'col_doc':{ 'key_string':'mock string value', 'key_int32':NumberInt("1"), 'key_int32_min':NumberInt("-2147483648"), 'key_int32_max':NumberInt("2147483647"), 'key_int64':NumberLong("1234567890123456"), 'key_int64_min':NumberLong("-9223372036854775807"), 'key_int64_max':NumberLong("9223372036854775807"), 'key_decimal':NumberDecimal("9999999.4999999999"), 'key_double':9999999.99, 'key_boolean':true, 'key_timestamp':ISODate(), 'key_date':new Date(), 'key_array_to_json':['a','b'], 'key_array_to_join':['a','b'], }, 'col_extra_1':'this is extra 1', 'col_extra_2':'this is extra 2', })查询插入MongoDB中的数据。
db.getCollection("di_mongodb_conf_test").find({})查询结果为:
准备MaxCompute表。
创建一个名称为
di_mongodb_conf_test的分区表,分区字段为pt。CREATE TABLE IF NOT EXISTS di_mongodb_conf_test ( `id` STRING ,`col_string` STRING ,`col_int32` INT ,`col_int32_min` INT ,`col_int32_max` INT ,`col_int64` BIGINT ,`col_int64_min` BIGINT ,`col_int64_max` BIGINT ,`col_decimal` DECIMAL(38,18) ,`col_double` DOUBLE ,`col_boolean` BOOLEAN ,`col_timestamp` TIMESTAMP ,`col_date` DATE ,`col_array_to_json` STRING ,`col_array_to_join` STRING ,`key_string` STRING ,`key_int32` INT ,`key_int32_min` INT ,`key_int32_max` INT ,`key_int64` BIGINT ,`key_int64_min` BIGINT ,`key_int64_max` BIGINT ,`key_decimal` DECIMAL(38,18) ,`key_double` DOUBLE ,`key_boolean` BOOLEAN ,`key_timestamp` TIMESTAMP ,`key_date` DATE ,`key_array_to_json` STRING ,`key_array_to_join` STRING ,`col_doc` STRING ,`col_combine` STRING ) PARTITIONED BY ( pt STRING ) LIFECYCLE 36500 ;添加一个分区取值
20230202。alter table di_mongodb_conf_test add if not exists partition (pt='20230202');检查分区表是否正确创建。
SELECT*FROM di_mongodb_conf_test WHEREpt='20230202';
离线任务配置
step1:添加MongoDB数据源
添加一个MongoDB数据源,保障数据源与独享数据集成资源组之间网络连通。操作详情请参见配置MongoDB数据源。
step2:创建离线同步节点,并配置离线同步任务
在DataWorks的DataStudio中创建一个离线同步节点,并配置离线同步的来源与去向等任务配置参数,核心配置要点如下,其他参数可保持默认值即可。详细操作请参见通过向导模式配置离线同步任务。
配置同步网络连接。
选择上述步骤中创建的MongoDB、MaxCompute数据源和对应的独享数据集成资源组,测试完成连通性。
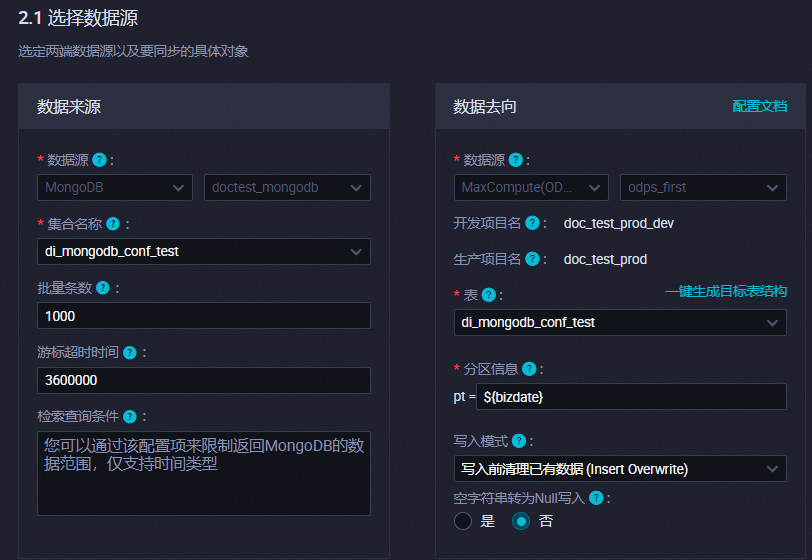
配置任务:选择数据源。
选择上述准备数据步骤中准备的MongoDB数据集合和MaxCompute分区表。
配置任务:字段映射。
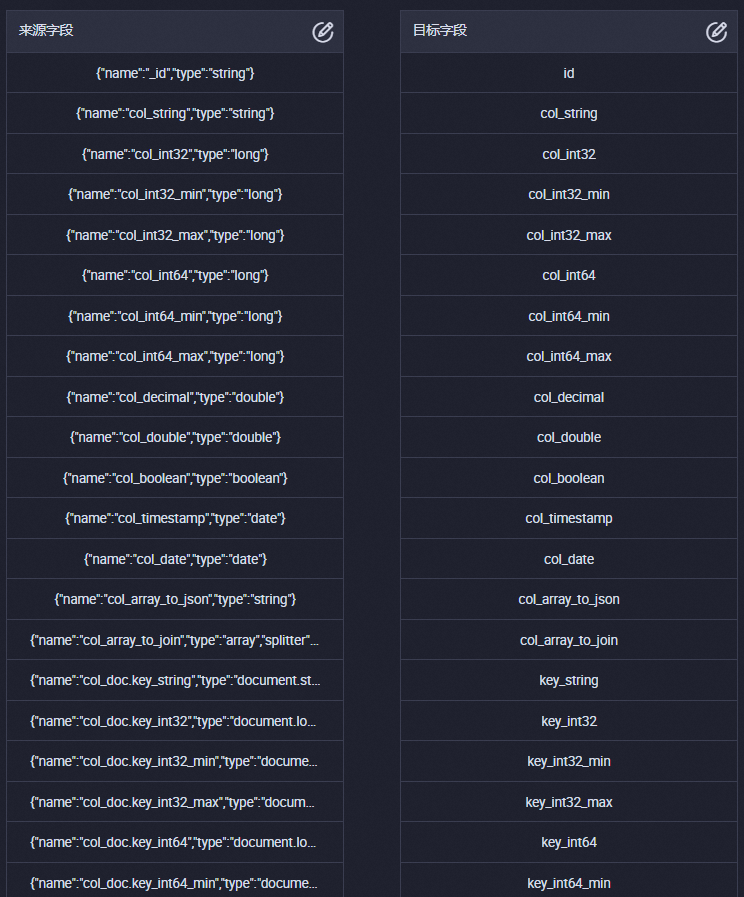
数据源为MongoDB时,默认使用同行映射。您也可以单击
 图标手动编辑源表字段,手动编辑的示例如下。
图标手动编辑源表字段,手动编辑的示例如下。{"name":"_id","type":"string"} {"name":"col_string","type":"string"} {"name":"col_int32","type":"long"} {"name":"col_int32_min","type":"long"} {"name":"col_int32_max","type":"long"} {"name":"col_int64","type":"long"} {"name":"col_int64_min","type":"long"} {"name":"col_int64_max","type":"long"} {"name":"col_decimal","type":"double"} {"name":"col_double","type":"double"} {"name":"col_boolean","type":"boolean"} {"name":"col_timestamp","type":"date"} {"name":"col_date","type":"date"} {"name":"col_array_to_json","type":"string"} {"name":"col_array_to_join","type":"array","splitter":","} {"name":"col_doc.key_string","type":"document.string"} {"name":"col_doc.key_int32","type":"document.long"} {"name":"col_doc.key_int32_min","type":"document.long"} {"name":"col_doc.key_int32_max","type":"document.long"} {"name":"col_doc.key_int64","type":"document.long"} {"name":"col_doc.key_int64_min","type":"document.long"} {"name":"col_doc.key_int64_max","type":"document.long"} {"name":"col_doc.key_decimal","type":"document.double"} {"name":"col_doc.key_double","type":"document.double"} {"name":"col_doc.key_boolean","type":"document.boolean"} {"name":"col_doc.key_timestamp","type":"document.date"} {"name":"col_doc.key_date","type":"document.date"} {"name":"col_doc.key_array_to_json","type":"document"} {"name":"col_doc.key_array_to_join","type":"document.array","splitter":","} {"name":"col_doc","type":"string"} {"name":"col_combine","type":"combine"}手动后,界面可展示来源字段与目标字段的映射关系。
step3:提交发布离线同步节点
如果您使用的是标准模式的DataWorks工作空间,并且希望后续在生产环境中周期性调度此离线同步任务的话,您可以将离线同步节点提交发布到生产环境。操作详情请参见发布任务。
step4:运行离线同步节点,查看同步结果
完成上述配置后,您可以运行同步节点,待运行完成后,查看同步至MaxCompute表中的数据。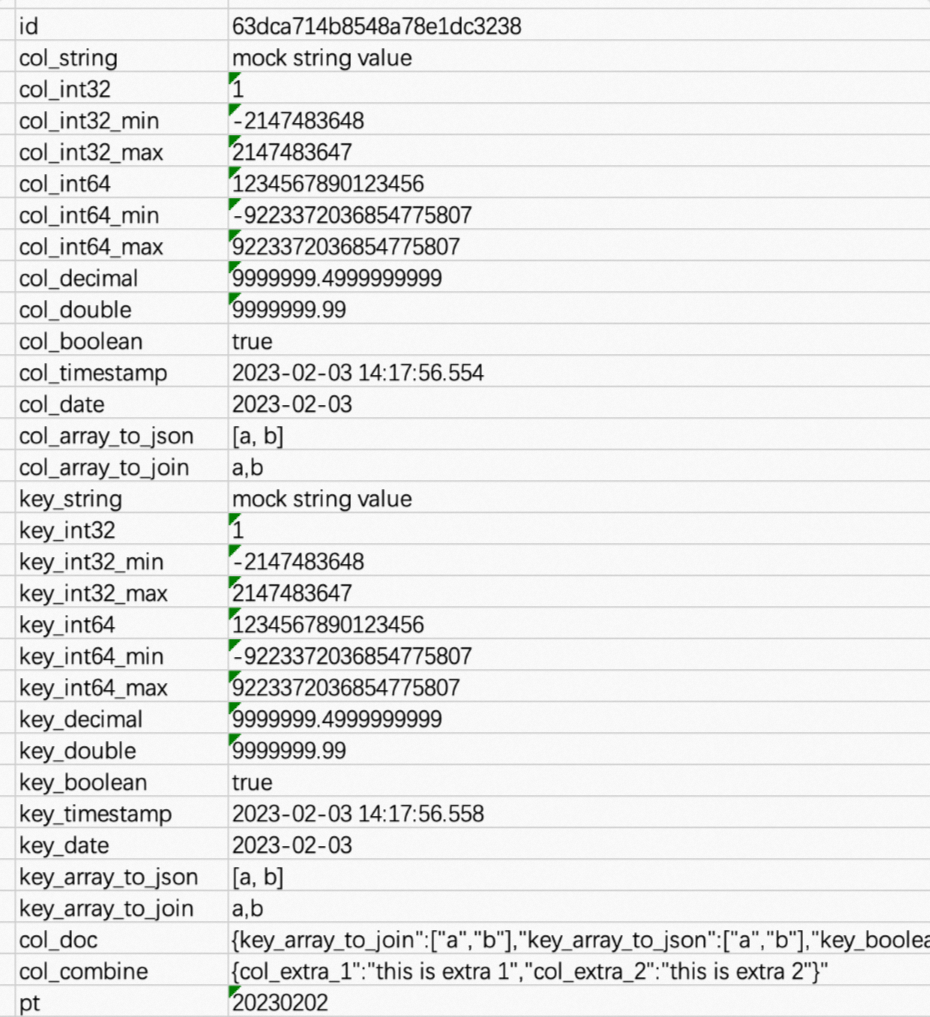 其中:
其中:
col_doc字段内容如下。
col_combine字段内容如下。
关于decimal类型输出问题,参考下文附录2:关于document中Decimal类型输出问题。
附录1:同步过程中的数据格式转换说明
数组类型数据转换为JSON格式输出:col_array_to_json
MongoDB原始数据 | 字段映射配置 | 输出至MaxCompute的结果 |
| 字段映射配置时, | |
数组类型数据转换为拼接字符串格式输出:col_array_to_join
MongoDB原始数据 | 字段映射配置 | 输出至MaxCompute的结果 |
| 字段映射配置时, | |
Document数据存在多层嵌套时,读取嵌套中的指定字段同步
MongoDB原始数据 | 字段映射配置 | 输出至MaxCompute的结果 |
|
| |
Document数据作为json序列化输出
MongoDB原始数据 | 字段映射配置 | 输出至MaxCompute的结果 |
| 字段映射配置时, | |
Document数据除去已配置字段外,其他字段整体进行json序列化输出
MongoDB原始数据 | 字段映射配置 | 输出至MaxCompute的结果 |
| document共有字段4个,任务已配置非combine类型字段2个(col_1、col_2),同步任务运行时,会将col_1、col_2两个字段外的其他字段按json序列化输出。 | |
附录2:关于document中Decimal类型输出问题
关于document序列化为JSON格式输出时,Decimal128类型默认情况下,会输出为:
{
"key_decimal":
{
"finite": true,
"high": 3471149412795809792,
"infinite": false,
"low": 99999994999999999,
"naN": false,
"negative": false
}
}如果需要按数字类型输出,则可以按如下步骤处理:
在配置离线同步任务时,单击等不转脚本按钮,转换为脚本模式。
修改Reader任务配置,在parameter中增加参数
decimal128OutputType,value固定填写bigDecimal。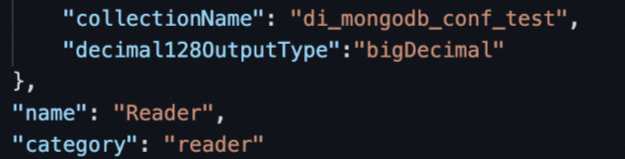
重新运行离线同步任务,查看结果。
{ "key_decimal": "9999999.4999999999" }