
在DataWorks中,您可按照工作空间粒度指定各模块使用的SPARK参数,后续各模块将默认使用对应SPARK参数执行任务。您可参考Spark官方文档自定义全局Spark参数,并配置全局Spark参数的优先级是否高于指定模块内(数据开发、数据分析、运维中心)的SPARK参数。本文为您介绍如何设置全局Spark参数。
背景信息
Apache Spark是用于进行大规模数据分析的引擎。在DataWorks中,您可通过如下方式配置调度节点运行时使用的Spark参数:
方式一:配置全局Spark参数
设置工作空间级别某DataWorks功能模块运行EMR任务时使用哪个Spark参数,并定义此处配置的Spark参数优先级是否高于指定模块内配置的Spark参数。详情请参见设置全局Spark参数。
方式二:配置产品模块内Spark参数
数据开发(DataStudio):对于Hive、Spark节点,可在节点编辑页面右侧导航栏的高级设置,设置单个节点任务设置Spark属性。
其他产品模块:暂不支持在模块内单独设置Spark属性。
使用限制
仅以下角色可配置全局Spark参数:
阿里云主账号。
拥有AliyunDataWorksFullAccess权限的子账号(RAM用户)或RAM角色。
拥有空间管理员角色的子账号(RAM用户)。
Spark参数仅针对EMR Spark节点、EMR Spark SQL节点、EMR Spark Streaming节点生效。
您可在DataWorks的管理中心及阿里云E-MapReduce控制台中更新Spark相关配置,若相同Spark参数在两者中的配置不同,则通过DataWorks提交的任务将采用DataWorks管理中心中的配置。
目前仅支持对数据开发(DataStudio)、数据质量、数据分析、运维中心模块设置全局Spark参数。
前提条件
已注册EMR集群至DataWorks,详情请参见注册EMR集群至DataWorks。
设置全局Spark参数
进入全局Spark参数配置页面。
进入管理中心页面。
登录DataWorks控制台,切换至目标地域后,单击左侧导航栏的管理中心,在下拉框中选择对应工作空间后单击进入管理中心。
单击左侧导航栏的开源集群,进入集群管理页面。
找到目标E-MapReduce集群,单击SPARK参数,进入全局SPARK参数配置页面。
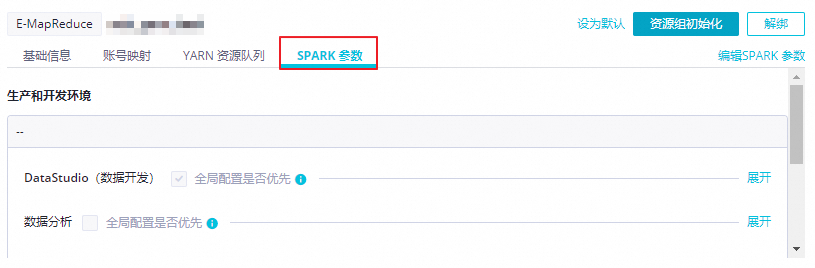
设置全局Spark参数。
单击Spark参数页面右上角的编辑SPARK参数,配置各模块的全局SPARK参数及优先级。
说明该配置为工作空间全局配置,请在配置前确认所使用的工作空间是否正确。
参数
步骤
Spark属性
配置各模块运行EMR任务时使用的Spark属性。您可参考Spark Configurations、Spark Configurations on Kubernetes配置。
全局配置是否优先
勾选后,表示全局配置将比产品模块内配置优先生效;此时将按照全局配置的Spark属性来统一运行任务。
全局配置:表示在的SPARK参数页面配置的Spark属性。
说明目前仅支持对数据开发(DataStudio)、数据质量、数据分析、运维中心模块设置全局Spark参数。
产品模块内配置:
数据开发(DataStudio):对于Hive、Spark节点,可在节点编辑页面右侧导航栏的高级设置,设置单个节点任务设置Spark属性。
其他产品模块:暂不支持在模块内单独设置Spark属性。