
DataWorks支持基于EMR(E-MapReduce)计算引擎创建Hive、MR、Presto和Spark SQL等节点,实现EMR任务工作流的配置、定时调度和元数据管理等功能,保障数据生产及管理的高效稳定。本文为您介绍在DataWorks上使用EMR的基本开发流程,以及相关费用说明、环境准备、权限控制等内容。
背景信息
开源大数据开发平台E-MapReduce(简称EMR),是运行在阿里云平台上的一种大数据处理的系统解决方案。
EMR基于开源的Apache Hadoop和Apache Spark,让您可以方便地使用Hadoop和Spark生态系统中的其他周边系统分析和处理数据。阿里云EMR提供了on ECS、on ACK和Serverless形态,以满足不同用户的需求。详情请参见E-MapReduce产品概述。
支持的集群类型
使用限制
-
权限限制:仅拥有以下身份的RAM用户或RAM角色,可注册EMR集群,操作详情请参见为RAM用户授权。
-
阿里云主账号。
-
同时具有DataWorks
空间管理员角色、AliyunEMRFullAccess策略的RAM子账号或RAM角色。 -
同时具有
AliyunDataWorksFullAccess、AliyunEMRFullAccess策略的RAM子账号或RAM角色。
-
-
地域限制:目前仅华东1(杭州)、华东2(上海)、华北2(北京)、华北3(张家口)、华北6(乌兰察布)、华南1(深圳)、西南1(成都)、中国香港、日本(东京)、新加坡、印度尼西亚(雅加达)、德国(法兰克福)、美国(弗吉尼亚)支持使用EMR Serverless Spark。
-
任务类型:DataWorks暂不支持执行EMR的Flink任务。
-
任务执行:DataWorks支持使用Serverless资源组(推荐)或旧版独享调度资源组进行EMR任务执行。
-
任务治理:
-
仅EMR Hive、EMR Spark及EMR Spark SQL节点中SQL任务支持产出血缘关系。当集群版本为5.9.1或3.43.1及以上版本时,以上节点均支持查看表级血缘与字段级血缘。
说明对于Spark类型节点,当EMR集群版本为5.8.0和3.42.0及以上版本时,支持查看表级血缘与字段级血缘,当EMR集群版本低于5.8.0和3.42.0版本时,仅Spark 2.x支持查看表级血缘。
-
DataLake或自定义集群若要在DataWorks管理元数据,需先在集群侧配置EMR-HOOK。若未配置,则在DataWorks中无法实时展示元数据、生成审计日志、展示血缘关系,EMR相关治理任务将无法开展。目前仅EMR Hive、EMR Spark SQL服务支持配置EMR-HOOK,配置详情请参见配置Hive的EMR-HOOK、配置Spark SQL的EMR-HOOK。
-
-
开启Kerberos认证的EMR集群的安全组需要对资源组绑定的交换机网段放开UDP协议端口的入方向权限。
说明您需单击EMR集群基础信息中集群安全组的
 图标,进入安全组详情页签,单击访问规则的入方向,选择手动添加,协议类型选择自定义UDP,端口范围配置详情请查看EMR集群中的
图标,进入安全组详情页签,单击访问规则的入方向,选择手动添加,协议类型选择自定义UDP,端口范围配置详情请查看EMR集群中的/etc/krb5.conf文件中对应的kdc端口,授权对象设置为资源组绑定的交换机网段。
前提条件
已开通DataWorks并创建工作空间,详情请参见开通DataWorks服务、配置工作空间。
已创建EMR集群,详情请参见创建集群。
说明在DataWorks运行EMR任务时可选择多种EMR组件,不同组件运行任务时的最优配置存在差异,您在创建EMR集群时请参考EMR集群配置建议,根据实际情况进行选择。
已购买DataWorks的Serverless资源组。
DataWorks资源组购买后,默认与其他云产品网络不连通。在对接使用EMR时,需先保障EMR集群和资源组间网络连通,才可进行后续相关操作。
说明Serverless资源组(推荐)为通用型资源组,可满足多种任务类型(例如,数据同步、任务调度)的场景应用,购买详情请参见使用Serverless资源组。新用户仅支持购买Serverless资源组。
若您已购买过旧版独享资源组,也可使用该资源组运行EMR任务。旧版独享资源组需根据待运行的任务类型选择相应资源组。例如,运行数据同步任务,需使用独享数据集成资源组;运行数据调度任务,需使用独享调度资源组。详情请参见使用旧版资源组。
使用说明
DataWorks on EMR的相关开发说明如下。
序号 | 说明 |
DataWorks上进行EMR任务开发,除DataWorks侧产品费用外,还会产生其他产品侧费用。 | |
DataWorks上进行EMR任务开发前,您需根据业务需求购买相应DataWorks版本及所需资源组,并完成相关EMR集群注册及开发环境的准备工作。 | |
DataWorks为您提供了产品级与模块级的权限控制,您可根据业务需求对不同用户授权不同权限,实现权限的精细化管理。 | |
DataWorks数据集成提供EMR Hive数据的读取与写入的能力,并提供离线同步、全增量同步任务等多种数据同步场景。 | |
DataWorks提供数据建模服务,将无序、杂乱、繁琐、庞大且难以管理的数据,进行结构化有序的管理。还提供数据开发(DataStudio)功能,用于调度任务的开发,并与运维中心配合使用,进行调度任务的监控运维。 | |
DataWorks提供EMR元数据管理与数据治理能力。 | |
DataWorks数据分析提供EMR数据分析与服务共享能力。 | |
DataWorks支持开放能力,帮助您快速实现各类应用系统对接DataWorks,并进行数据流程管控、数据治理和运维,及时响应各应用系统对接DataWorks的业务状态变化。 |
费用说明
一、DataWorks相关费用
以下费用会体现在DataWorks产品相关账单中。DataWorks计费详情请参见计费简介。
费用 | 说明 |
DataWorks版本费用 | 进行任务开发前,您需先开通DataWorks。如果开通的是DataWorks标准版、专业版、企业版,则在开通时需支付相应版本的版本费用。 |
任务调度的调度资源费用 | 任务开发完成后,进行任务调度需使用调度资源。您可使用Serverless资源组(推荐)或旧版独享调度资源组,支付相应资源组费用。 说明 购买的Serverless资源组可满足任务调度、数据同步共同使用。 |
数据同步的同步资源费用 | 运行数据同步任务时,除调度资源外,还需使用数据同步资源。您可使用Serverless资源组(推荐)或旧版独享数据集成资源组,支付相应资源组费用。 |
二、非DataWorks相关费用
以下费用不会体现在DataWorks产品相关账单中。
涉及其他产品的费用,收费情况以对应产品的收费逻辑决定,您可查看对应产品的计费文档了解详情。以EMR为例,计费详情请参见产品计费。
费用 | 说明 |
数据库费用 | 数据同步时,读写上下游数据库中的数据时,可能会产生数据库费用。 |
计算和存储费用 | 运行计算引擎任务时,可能会产生计算引擎的计算和存储费用。 |
网络服务费用 | 连通DataWorks和其他相关产品的网络环境时,可能会产生网络服务费用。例如,使用高速通道、共享带宽、EIP等产品连通网络时,会产生相应产品的服务费用。 |
环境准备
一、资源准备
类别 | 描述 | 相关文档 |
版本选择 | DataWorks基础版服务可满足EMR基本的数据上云、数据开发与调度生产、简单的数据治理工作,若需获取更专业的数据治理、数据安全解决方案,可选择相应的标准版、专业版、企业版服务。 | |
资源组选择 | EMR集群目前仅支持使用Serverless资源组(推荐)或旧版独享资源组执行任务。 |
二、开发环境准备
您需先在DataWorks工作空间注册EMR集群,才可在数据开发(DataStudio)进行数据开发工作,并以工作空间为单位管理空间成员以便进行协同开发。
类别 | 描述 | 相关文档 |
数据同步环境准备 | 基于集群的组件执行数据同步任务前,需先将该组件创建为相应的DataWorks数据源。 | |
数据开发、数据分析环境准备 | 基于DataWorks进行计算引擎任务周期性调度前,您需先将集群添加至DataWorks。添加后,才可使用该集群进行相关数据开发、数据分析、周期性调度运行任务等操作。 | |
协同开发环境准备 | 为保障RAM用户以工作空间为单位进行协同开发,您需执行如下操作:
|
权限控制
DataWorks为您提供了产品级与模块级的权限控制,您可根据业务需求对不同用户授权不同权限。权限控制相关介绍如下。
一、数据访问权限控制
加入至DataWorks工作空间进行EMR任务开发的RAM用户,可通过为其配置集群账号映射的方式,使空间成员(RAM用户)拥有该集群映射账号所拥有的权限。集群账号映射,详情请参见:设置集群身份映射。
DataWorks提供DLF可视化权限申请、权限审批及权限审计等功能,可实现数据湖全托管的统一权限管理,当EMR已将DLF设置为元数据服务时,您可以在DataWorks安全中心进行数据权限申请与控制,详情请参见DLF数据访问权限控制。
二、功能模块权限控制
进行数据开发前,您可参考为RAM用户授权指引,让其拥有不同的操作权限。权限类型如下:
通过全局级模块权限控制,管理DataWorks功能模块(例如,不允许用户访问数据地图)与DataWorks控制台的权限(例如,允许用户删除工作空间)。
通过空间级模块权限管控,管理DataWorks空间级模块(例如,允许用户进入数据开发执行相关开发操作)与全局模块的使用权限(例如,禁止用户访问数据保护伞模块)。
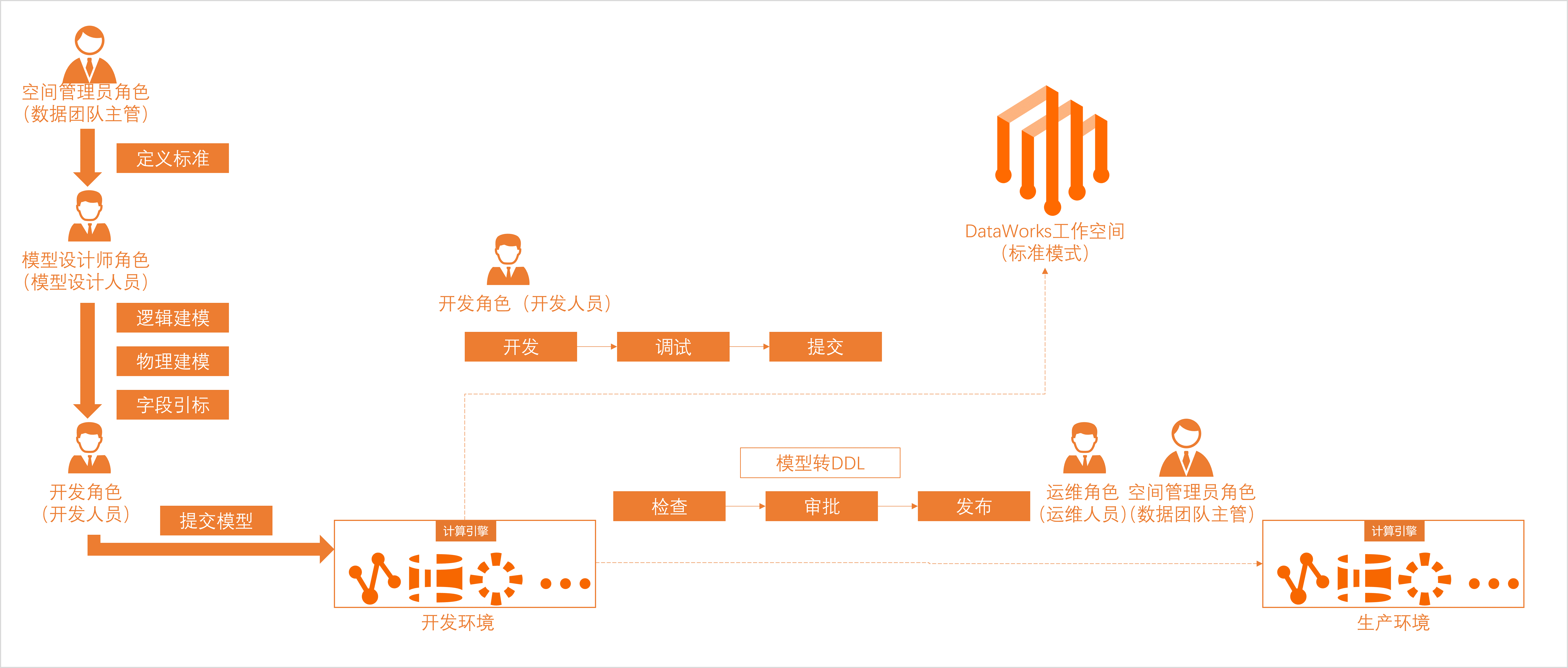
开始使用
DataWorks为您提供了多个功能模块,您可在数据开发(DataStudio)中进行调度任务的开发,并在开发完成后进入生产运维中心进行调度任务的监控运维。同时,提供了任务开发与发布的流程管控,助力您规范开发操作,保障开发过程的安全性。
一、数据集成
DataWorks的数据集成模块为您提供读取和写入数据至EMR Hive的能力,您需要将Hive组件创建为DataWorks的Hive数据源,实现将其他数据源的数据同步至Hive数据源,或将Hive数据源的数据同步至其他数据源。同时,可根据需要选择离线同步、全增量同步任务等场景执行相关数据同步操作。详情请参见数据集成。
二、数据开发与运维
模块 | 说明 | 相关文档 |
数据建模 | 数据建模是全链路数据治理的第一步,沉淀阿里巴巴数据中台建模方法论,从数仓规划、数据标准、维度建模、数据指标四个方面,以业务视角对业务的数据进行诠释,让企业内部实现“数同文”的快速理解与流通。 | |
数据开发 | DataWorks将EMR计算引擎的能力进行了封装,支持您执行EMR相关的数据同步、数据开发任务。
| |
您可结合DataWorks的通用类型节点和引擎计算节点进行复杂的逻辑处理。 主要节点如下:
| ||
节点任务开发完成后,可根据需要执行如下操作:
| ||
运维中心 | 运维中心是一站式大数据运维、监控平台,支持实时查看任务的运行状态,并为异常任务提供智能诊断、重跑等运维操作。它提供智能基线功能,帮助您解决重要任务产出时间不可控、海量任务监控难等问题,保障任务产出的时效性。 | |
数据质量 | 数据质量针对数据研发的全链路,保障数据可用性。通过对数据质量规则的高效校验,以及与任务调度流程的紧密结合,可以帮助用户第一时间发现质量问题、有效防止数据质量问题扩散,为业务提供高效、可靠、可信赖的数据。 |
三、数据治理
注册EMR集群至DataWorks后,DataWorks将自动采集您引擎下的元数据,您可前往数据地图概述进行查看;同时,也可进入数据治理中心概述,查看DataWorks检测的待治理问题,进行相关数据治理操作。
模块 | 说明 | 相关文档 |
数据地图 | DataWorks数据地图提供了企业级数据管理平台,能够基于统一元数据的底层建设,提供数据对象的管理和盘点的能力,以及数据对象的快速查找和深度理解的能力。 | |
安全中心 数据保护伞 审批中心 | 安全中心是集数据资产分级分类、敏感数据识别、数据授权管理、敏感数据脱敏、敏感数据访问审计、风险识别与响应于一体的一站式数据安全治理界面,帮助用户落地数据安全治理事项。 | |
数据治理中心 | 数据治理中心针对多个治理领域,通过数据领域规则沉淀、自动识别资产待优化问题项、覆盖事后及事前的治理优化策略等方式帮助用户主动式、体系化完成数据治理工作。 |
四、数据分析与服务
DataWorks的数据分析与服务提供数据处理和分析功能,支持通过统一管理的API高效共享和访问数据。
模块 | 说明 | 相关文档 |
数据分析 | 帮助您实现在线SQL分析、业务洞察、编辑和分享数据;并支持将查询结果保存为图表卡片,快速搭建可视化数据报告便于日常汇报。 | |
数据服务 | DataWorks数据服务旨在为企业提供全面的数据服务及共享能力,帮助企业统一管理面向内外部的API服务。 |
五、开放平台
DataWorks支持开放能力,帮助您快速实现各类应用系统对接DataWorks、方便快捷地进行数据流程管控、数据治理和运维,及时响应应用系统对接DataWorks的业务状态变化。
类别 | 描述 | 相关文档 |
OpenAPI | DataWorks开放平台的OpenAPI功能,为您提供开放API能力,通过开放API实现本地服务和DataWorks服务的交互,提升企业大数据处理效率,减少人工操作和运维工作,降低数据风险和企业成本。 | |
开放事件 | DataWorks开放平台的开放事件(OpenEvent)功能,为您提供消息订阅服务,通过订阅DataWorks事件状态、应用系统对接DataWorks、实时获取相关内容的状态变化,帮助您及时响应相应事件,满足个性化决策需求。 | |
扩展程序 | DataWorks通过OpenEvent为您提供消息推送订阅功能,您可将服务程序注册为DataWorks的扩展程序,通过扩展程序来卡点并响应订阅的事件消息,实现通过扩展程序对特定事件进行消息通知与流程管控。 |
附录:EMR集群配置建议
在DataWorks运行EMR任务时可选择多种EMR组件,不同组件运行任务时的最优配置存在差异,您在配置EMR集群时请参考下文,根据实际情况选择。
Kyuubi组件
在生产环境配置Kyuubi组件时,建议将
kyuubi_java_opts内存大小调整至10g及以上;将kyuubi_beeline_opts内存大小调整至2g及以上。Spark组件
由于Spark组件内存默认值较小,您可在
spark-submit命令行中添加设置内存大小的命令,修改内存默认值为合适大小。您可根据所使用的EMR集群规模情况调整Spark组件以下配置项:
spark.driver.memory、spark.driver.memoryOverhead、spark.executor.memory至合适大小。
重要仅DataWorks的EMR Hive、EMR Spark及EMR Spark SQL节点支持血缘功能。其中,EMR Hive节点支持表及列血缘,Spark类型节点仅支持表血缘。
更多Spark组件的配置详情,请参见Spark Memory Management。
HDFS
您可根据所使用的EMR集群规模情况调整HDFS的以下配置项:
hadoop_namenode_heapsize、hadoop_datanode_heapsize、hadoop_secondary_namenode_heapsize、hadoop_namenode_opts至合适大小。