本文展示从高门槛的传统数据开发模式,迈向低门槛、自动化的AI驱动新范式的完整路径,极大地提升数据开发的效率,降低技术门槛,并加速数据价值的实现。
产品介绍
DataWorks深度适配OpenLake架构,通过其核心Agent能力实现数据开发自动化,为用户提供从需求分析、ETL加工、数据分析到资产治理的全链路“Data+AI”管理服务。在开放的OpenLake架构之上,DataWorks支持编排数据开发工作流,并通过MaxCompute、EMR Serverless Spark、Hologres、EMR Serverless StarRocks等多引擎的协同,助您轻松构建并管理现代化的数据湖仓。
实践内容介绍
欢迎来到OpenLake Studio 智能湖仓数据开发动手实践!
在本次实践中,我们将聚焦真实的电商直播场景,带您亲历从原始业务数据到数据洞察的全过程:
第一步:Openlake—电商直播数据处理
首先,您将亲手构建一个现代化的数据湖仓体系。我们将引导您:
将RDS中的业务数据同步至开放数据湖(即数据湖构建DLF)。
通过MaxCompute、Serverless Spark、Serverless StarRocks、Hologres 多引擎协同工作。
完成明细数据构建、轻度汇总、加速查询和 AI 应用的一体化流程。
第二步:DataWorks Agent—自动构建数据工作流
本次动手实践的核心亮点——DataWorks Agent。我们将扮演ETL开发人员的角色,用自然语言下达指令(如“帮我构建直播订单分析工作流”),激活我们的 Agent。看它如何根据需求文档,自动完成需求分析、智能规划、代码生成、工作流编排乃至发布上线的全部工作。通过此环节,我们将体验到Agent为ETL工作带来的效率飞跃。
第三步:Notebook与ChatBI
当 ETL 流程就绪后,我们进入数据消费的新范式:
使用专业的 Notebook 进行交互式探索。
像聊天一样通过 ChatBI 发起即时问答,获取关键业务洞察。
通过这三个步骤,您将全面掌握 OpenLake Studio 如何让复杂的数据开发变得简单、高效且智能化。
注意事项
请务必遵守以下环境部署要求以确保顺利实践:
项目 | 要求 |
DataWorks 工作空间模板 | 选择 OpenLake 模板。 |
地域一致性 | 所有产品(DLF、MaxCompute、Hologres、EMR 等)必须部署在同一地域。 |
DLF 版本 | 使用最新版 DLF 。 |
Hologres 实例版本 | 推荐 R3.2 及以上版本。 |
网络互通性 | 所有资源建议部署在同一个 VPC 内,确保网络连通。 |
准备环境权限要求 | 环境准备阶段,各产品的开通需要是主账号或具备以下 RAM 权限的子用户/角色: |
准备工作
非DataWorks侧环境准备
MaxCompute:创建MaxCompute项目并绑定DLF数据目录。
重要目前创建MaxCompute外部项目,需提交工单联系MaxCompute产品团队创建。
Hologres:开通Hologres并绑定DLF数据目录。
EMR Serverless Spark:开通EMR Serverless Spark,创建工作空间并绑定DLF数据目录 。
EMR Serverless StarRocks:开通Serverless StarRocks并绑定DLF数据目录。
DataWorks侧环境准备
绑定DLF数据目录。
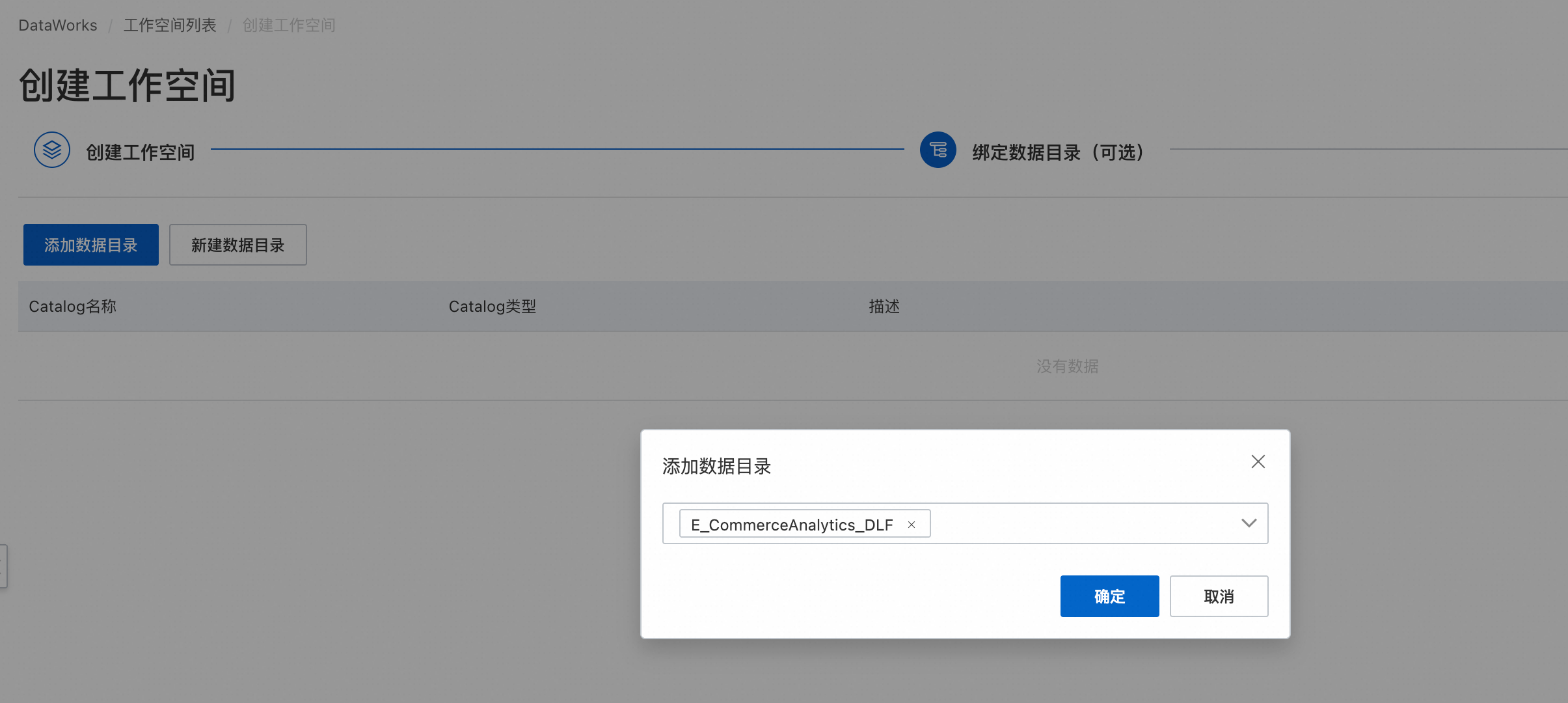
绑定上述计算资源:MaxCompute、Hologres、EMR Serverless Spark、EMR Serverless StarRocks。
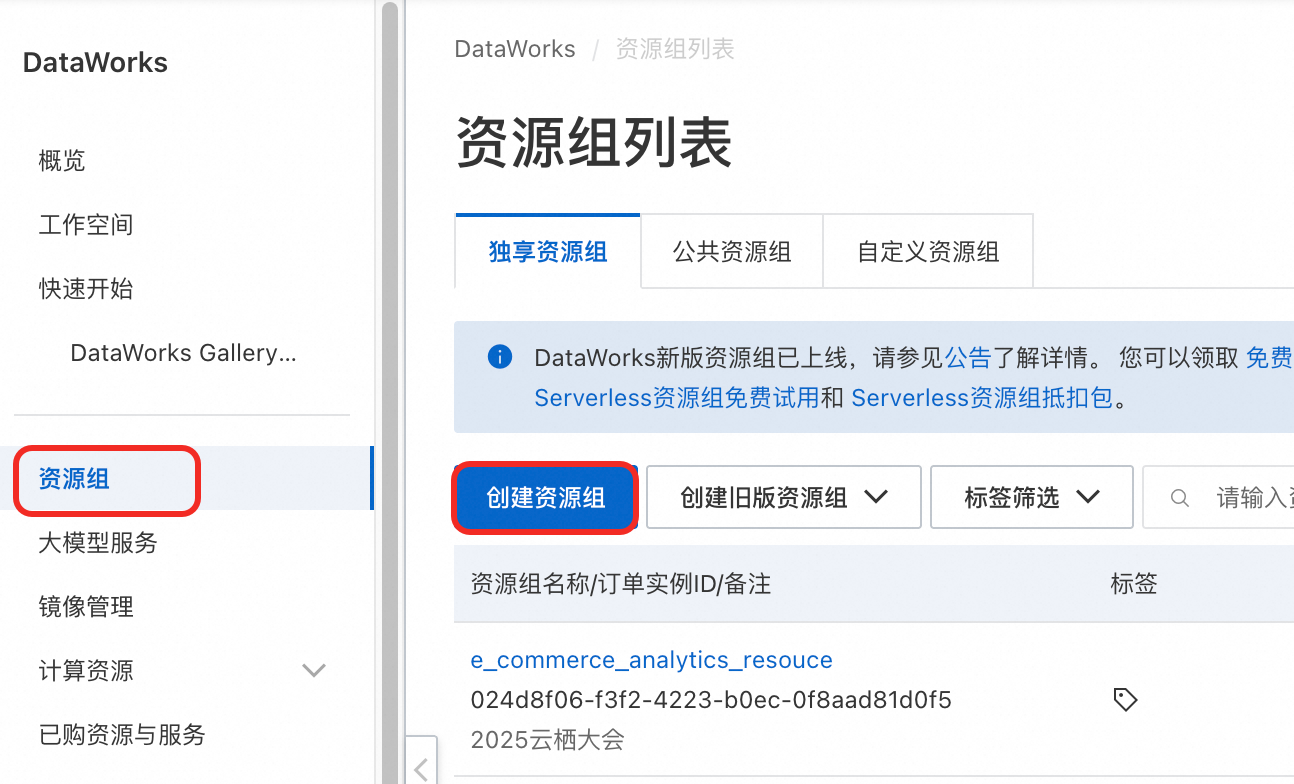
将资源组绑定到OpenLake工作空间。
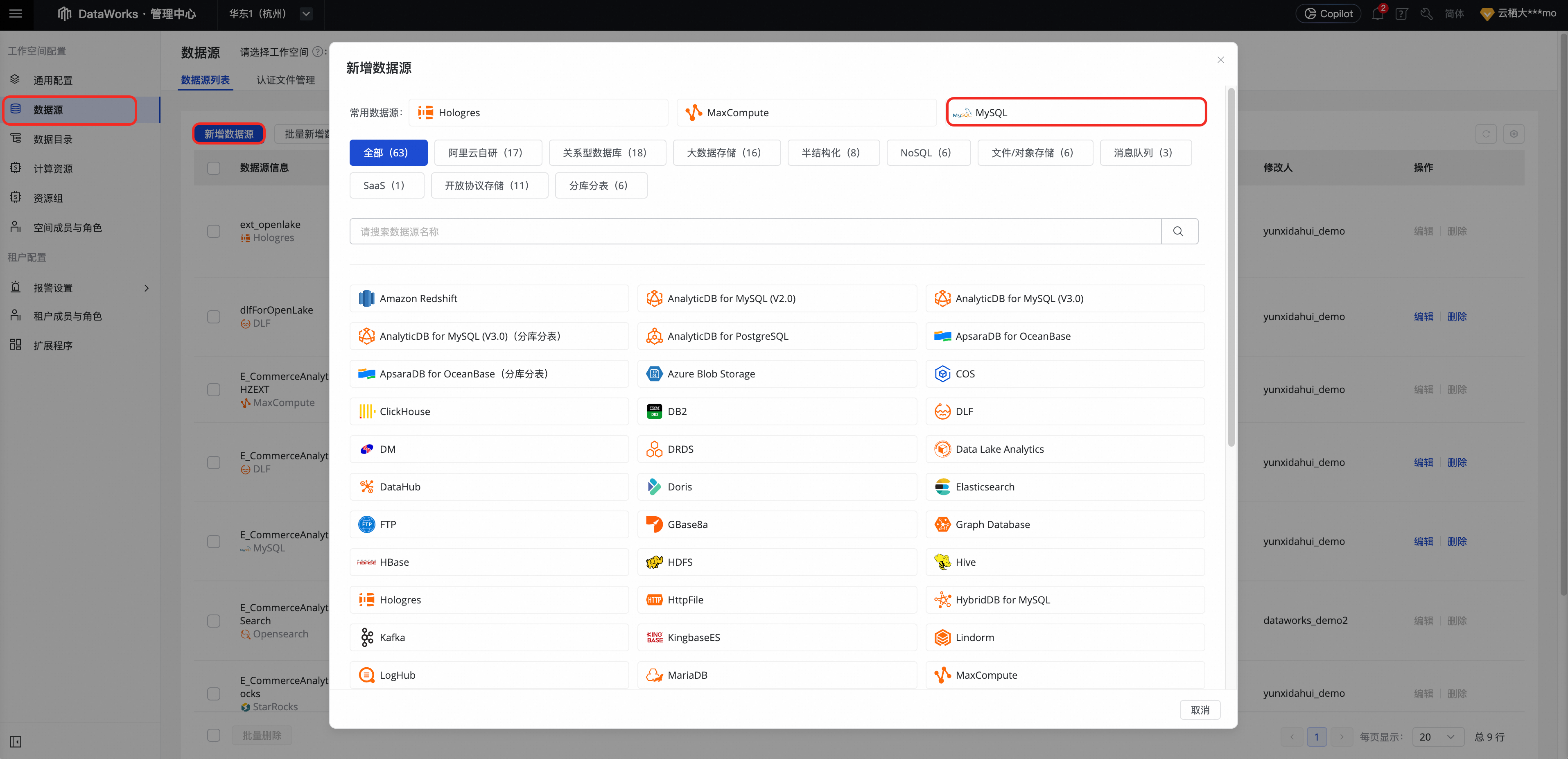
DataWorks侧数据源准备
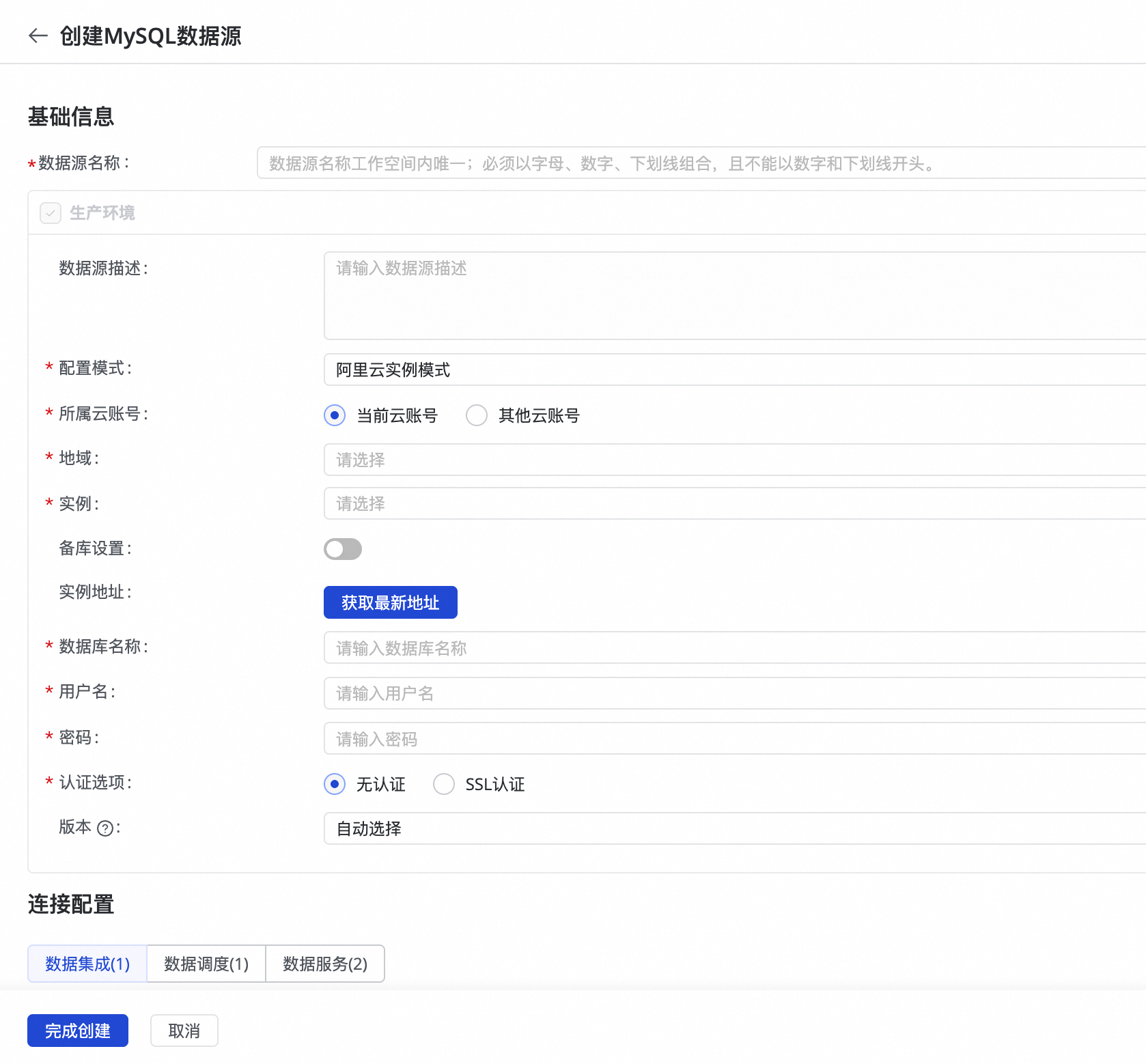
RDS 数据源(MySQL 类型)
在管理中心页面,单击数据源页签下的新建数据源按钮,数据源类型选择MySQL。
填写已开通的 RDS 实例信息进行连接测试。
数据湖构建DLF 数据源
在数据集成页面,单击数据源页签下的新建数据源按钮,数据源类型选择DLF。
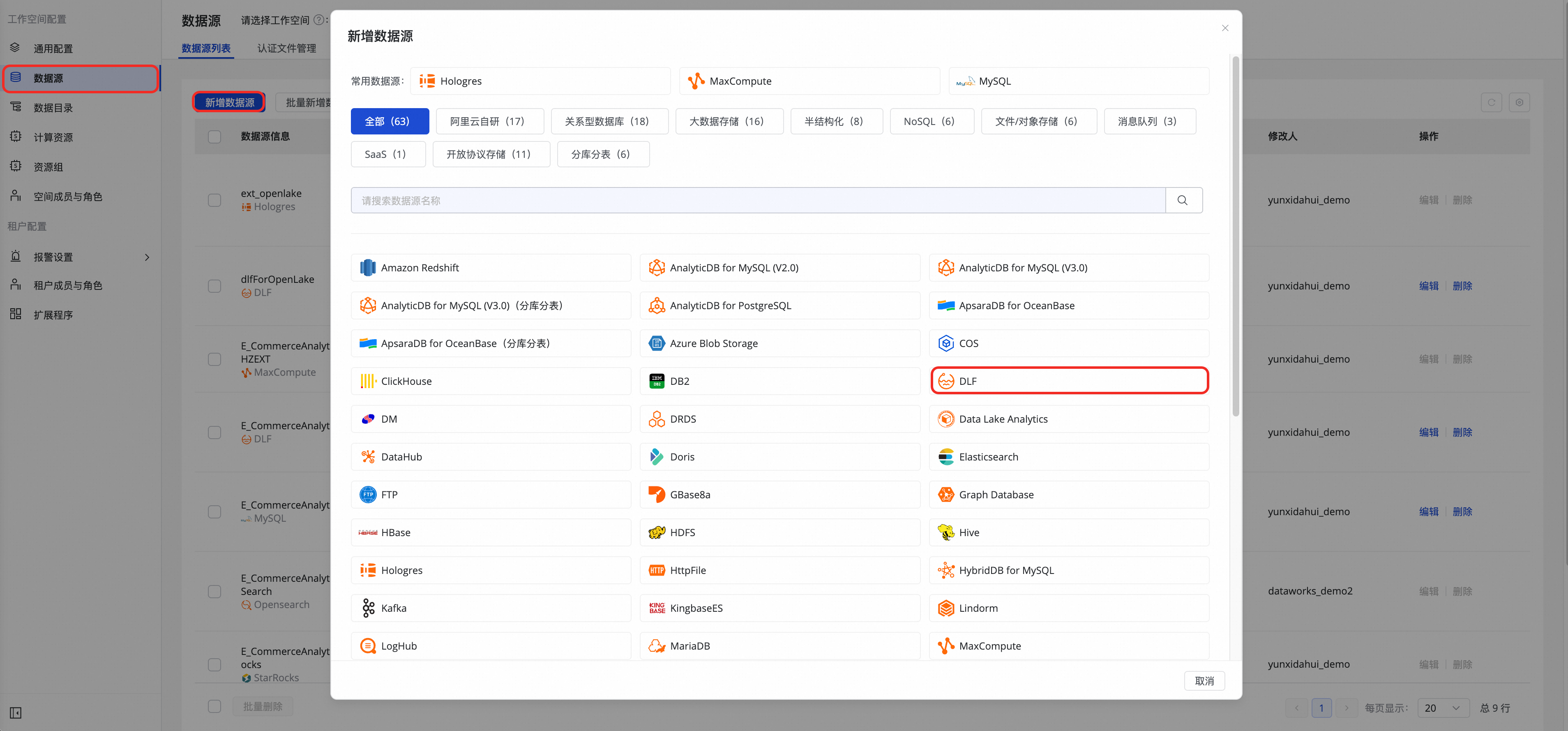
配置对应的 DLF 元数据地址及权限。
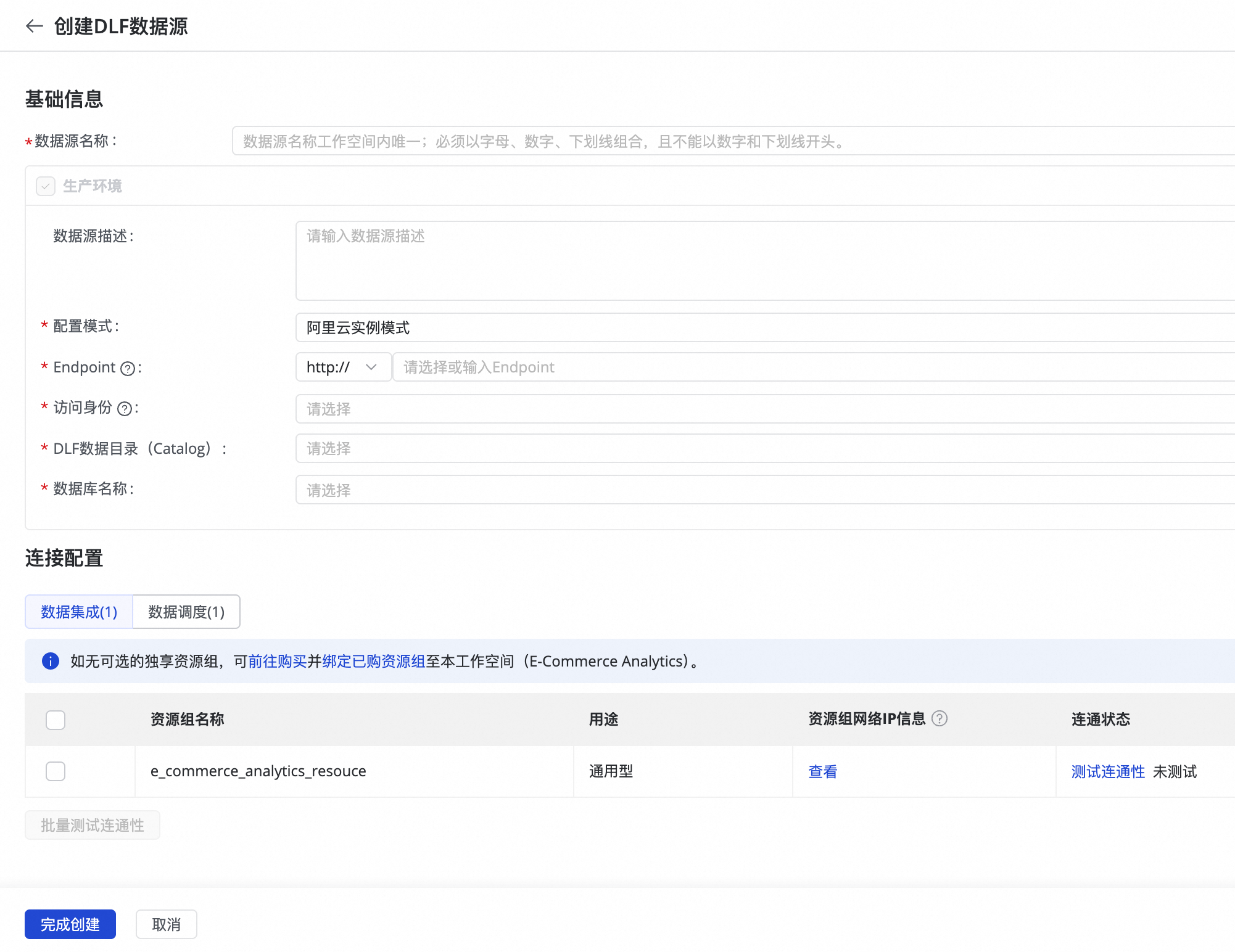
实践入口
单击DataWorks OpenLake解决方案,在OpenLake工作空间列表中找到已创建的工作空间。
单击,进入数据开发页面。
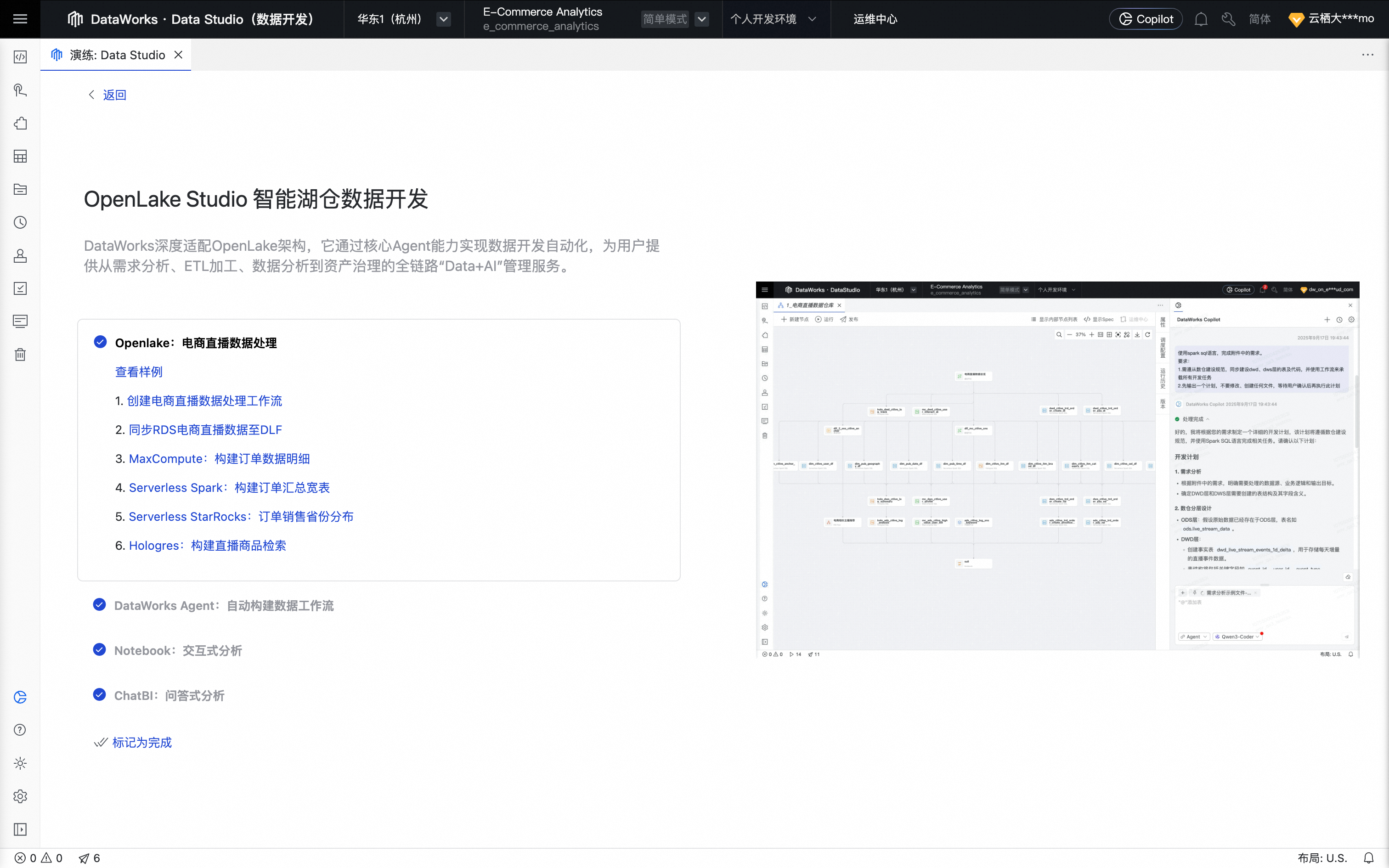
单击演练处的OpenLake Studio 智能湖仓数据开发,开始动手实践 。
实操动手实践
OpenLake:电商直播数据处理
单击查看样例,可预览内置样例工作流:“电商直播数据处理”。
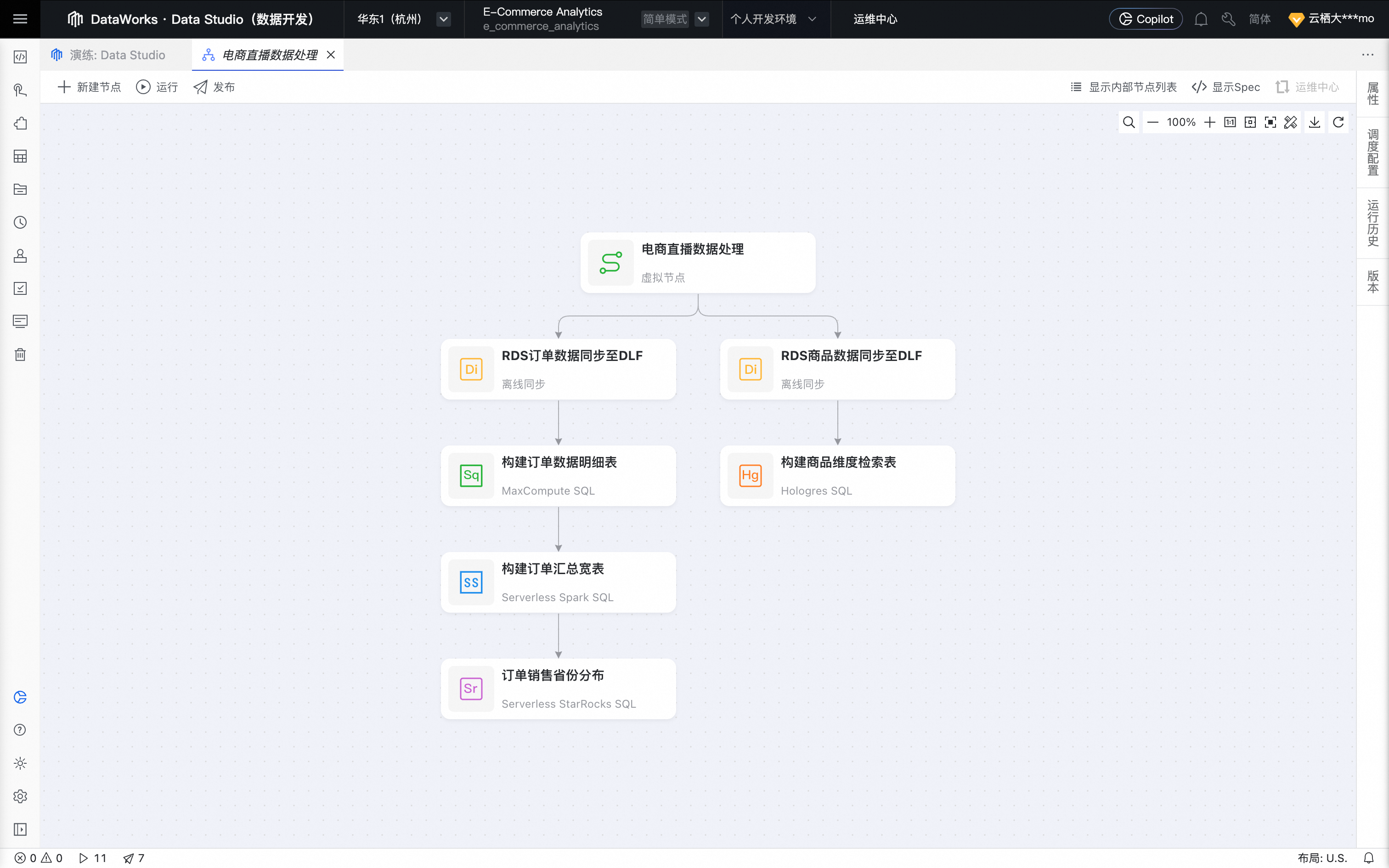
一、创建电商直播数据处理工作流
回到演练页,单击创建电商直播数据处理工作流并确认,系统将为您自动生成一个新的工作流容器。
二、同步 RDS 电商直播数据至 DLF
单击同步RDS电商直播数据至DLF按钮,启动创建数据集成/离线同步节点流程。
单击确认后,节点创建成功。
鼠标移动至该节点上,单击打开节点进入配置页面。
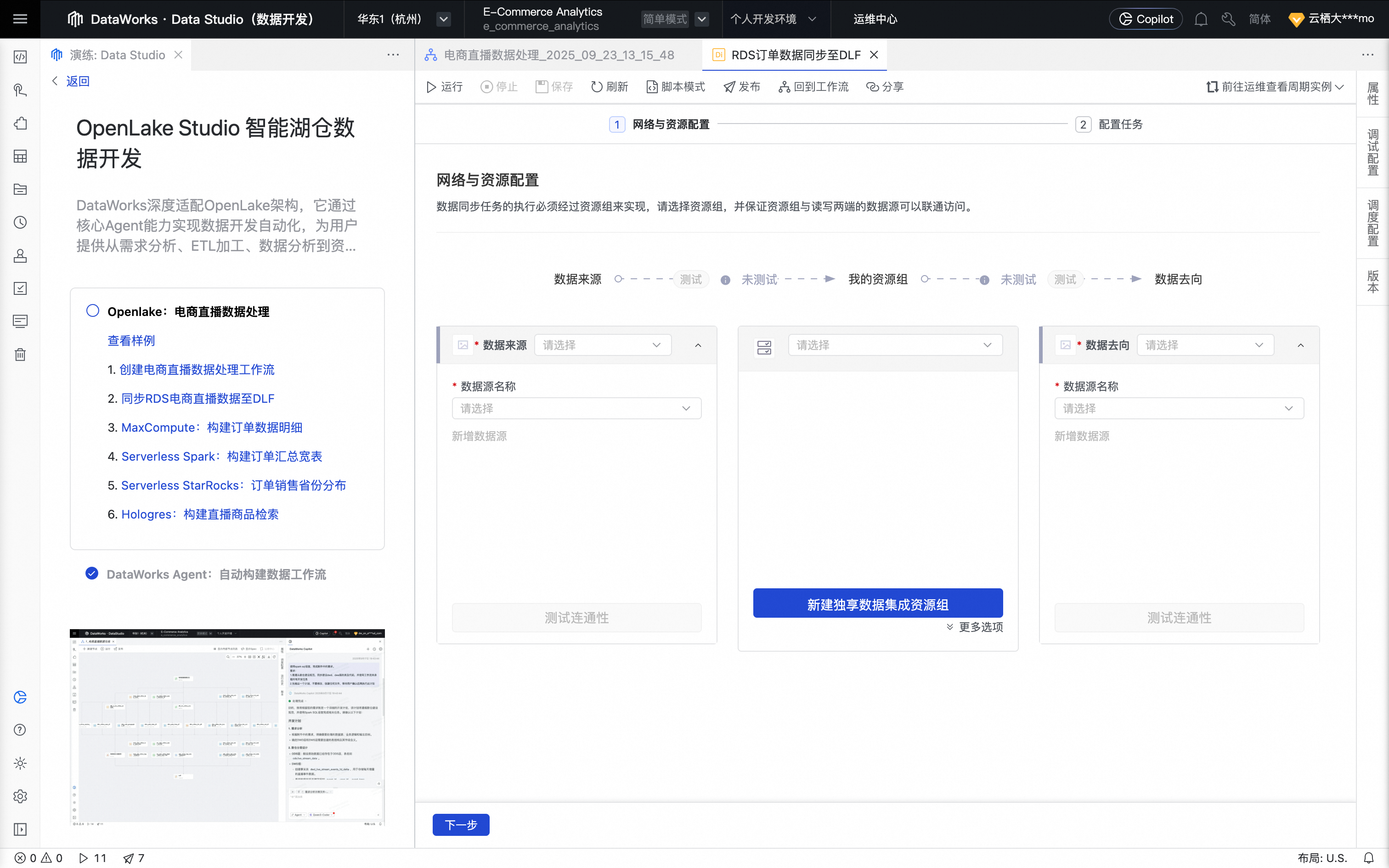
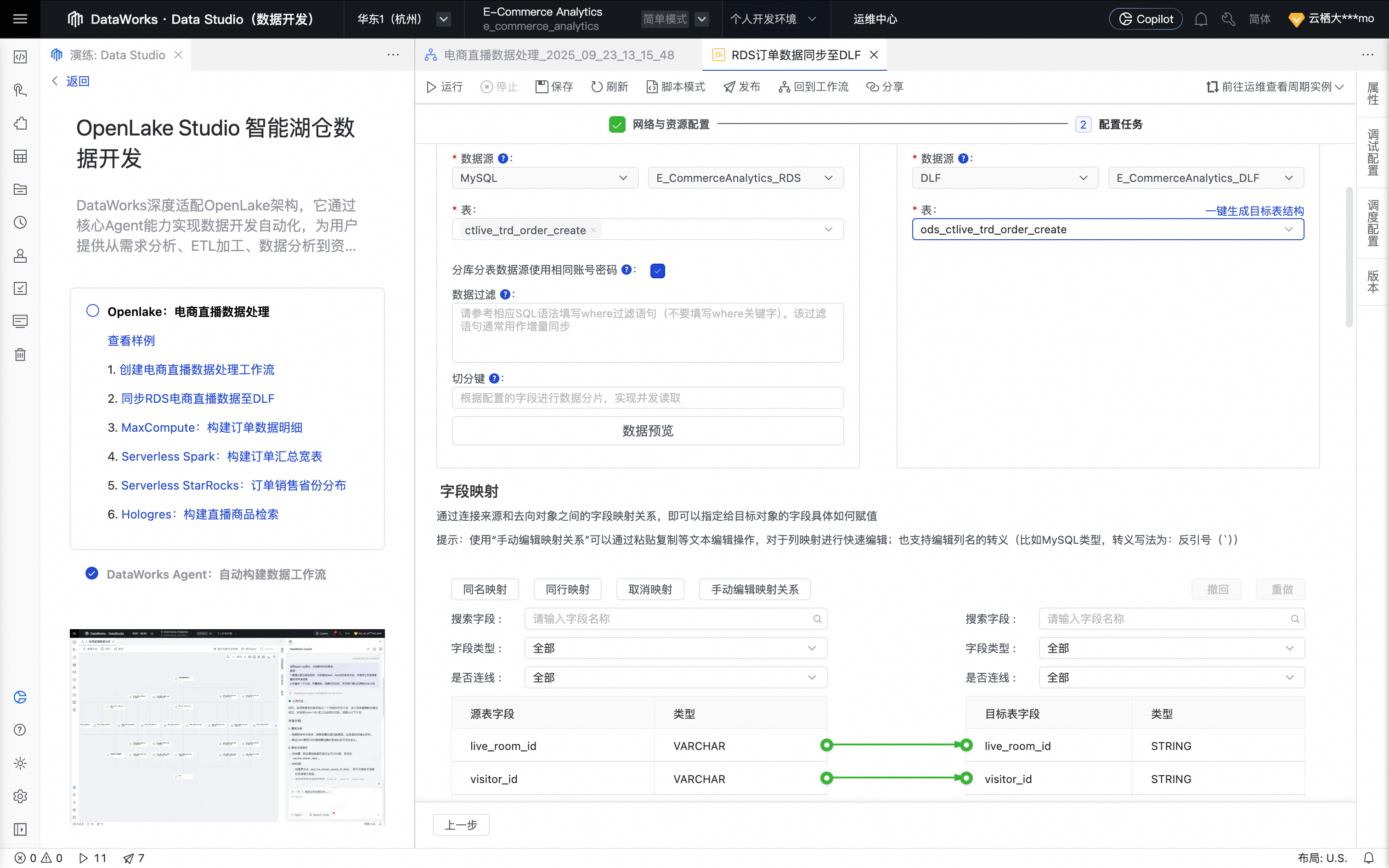
选择数据来源为MySQL,数据去向为DLF,并完成相关数据源及资源组的设置。
选择我们在已创建好的RDS数据源和DLF数据源,以及绑定到当前工作空间的资源组,并保障资源组与数据源可联通。
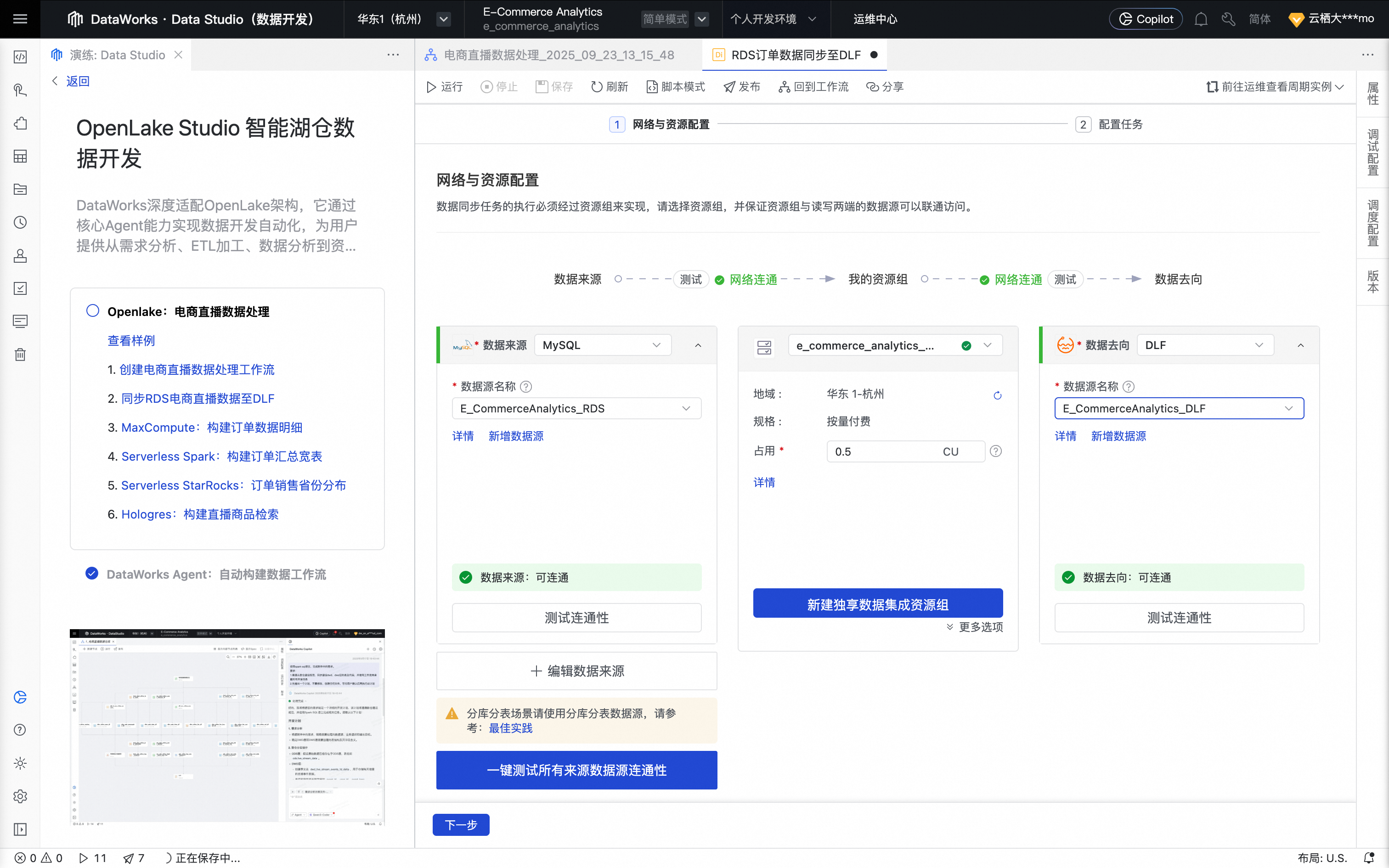
单击下一步,进行任务配置。
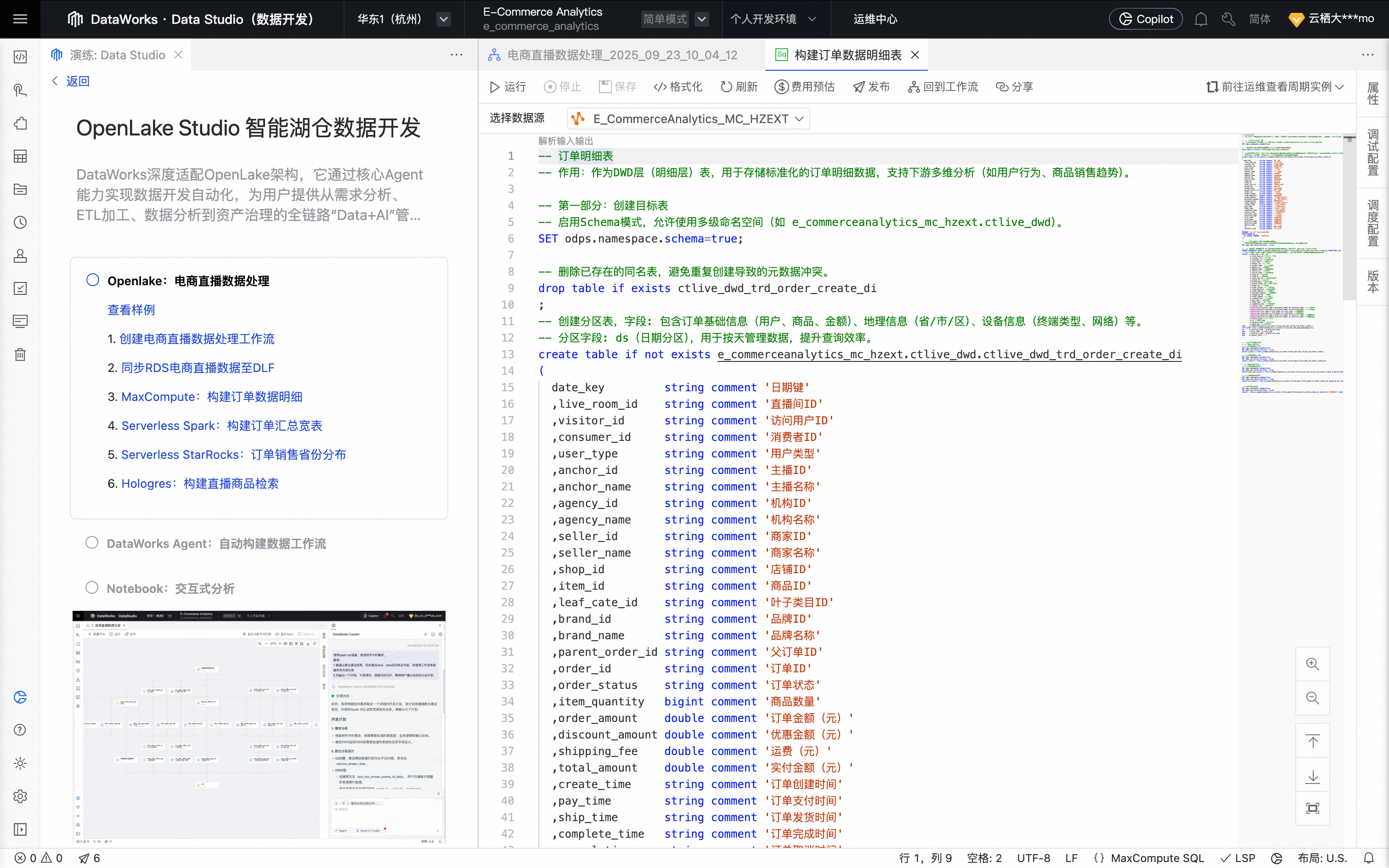
在数据来源处,选择来源表为ctlive_trd_order_create。在数据去向处,单击一键生成目标表结构功能自动建表。
可按需选择更多来源表。
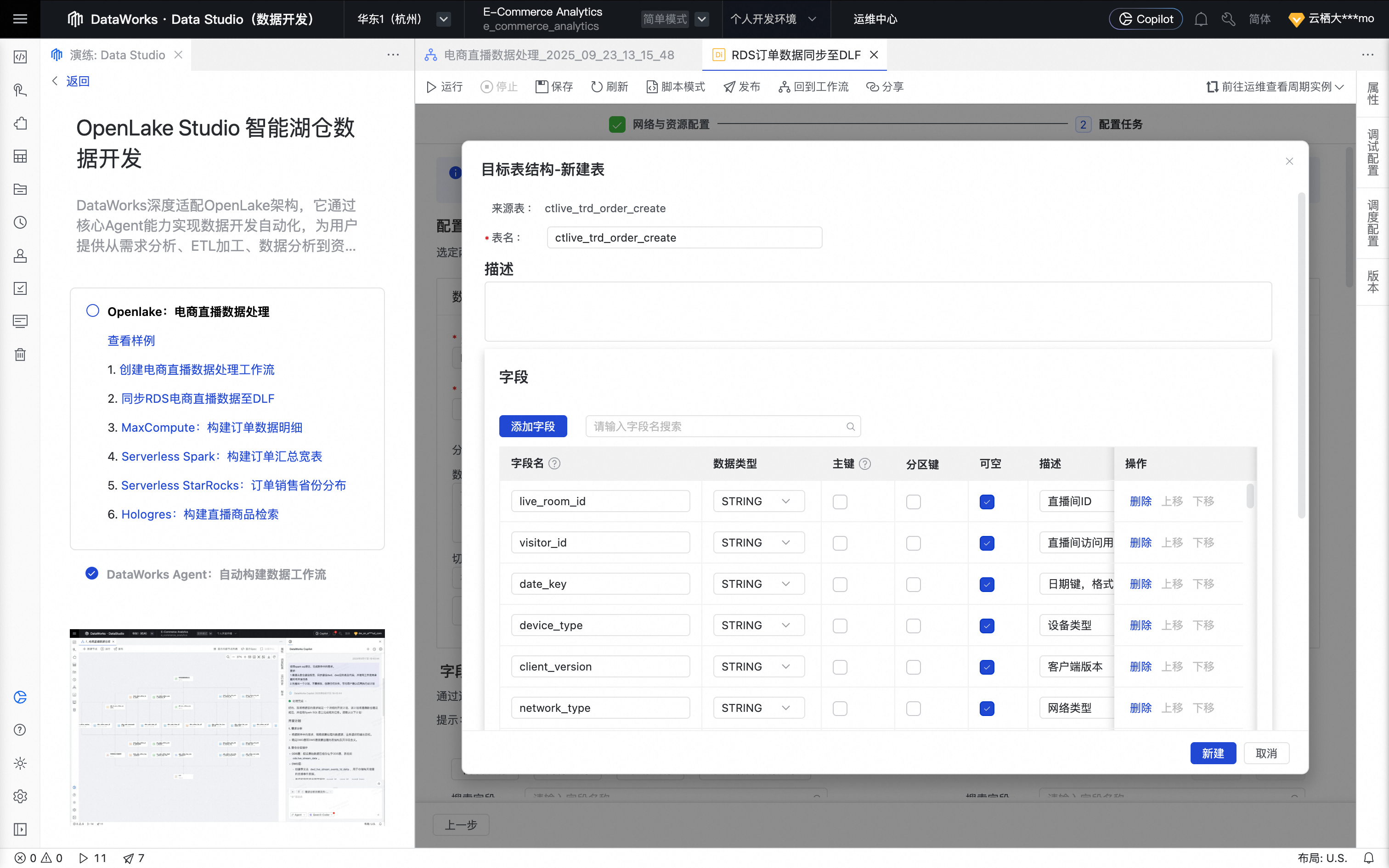
设置字段映射,默认按名称匹配即可。
脏数据策略建议设置为不容忍脏数据。
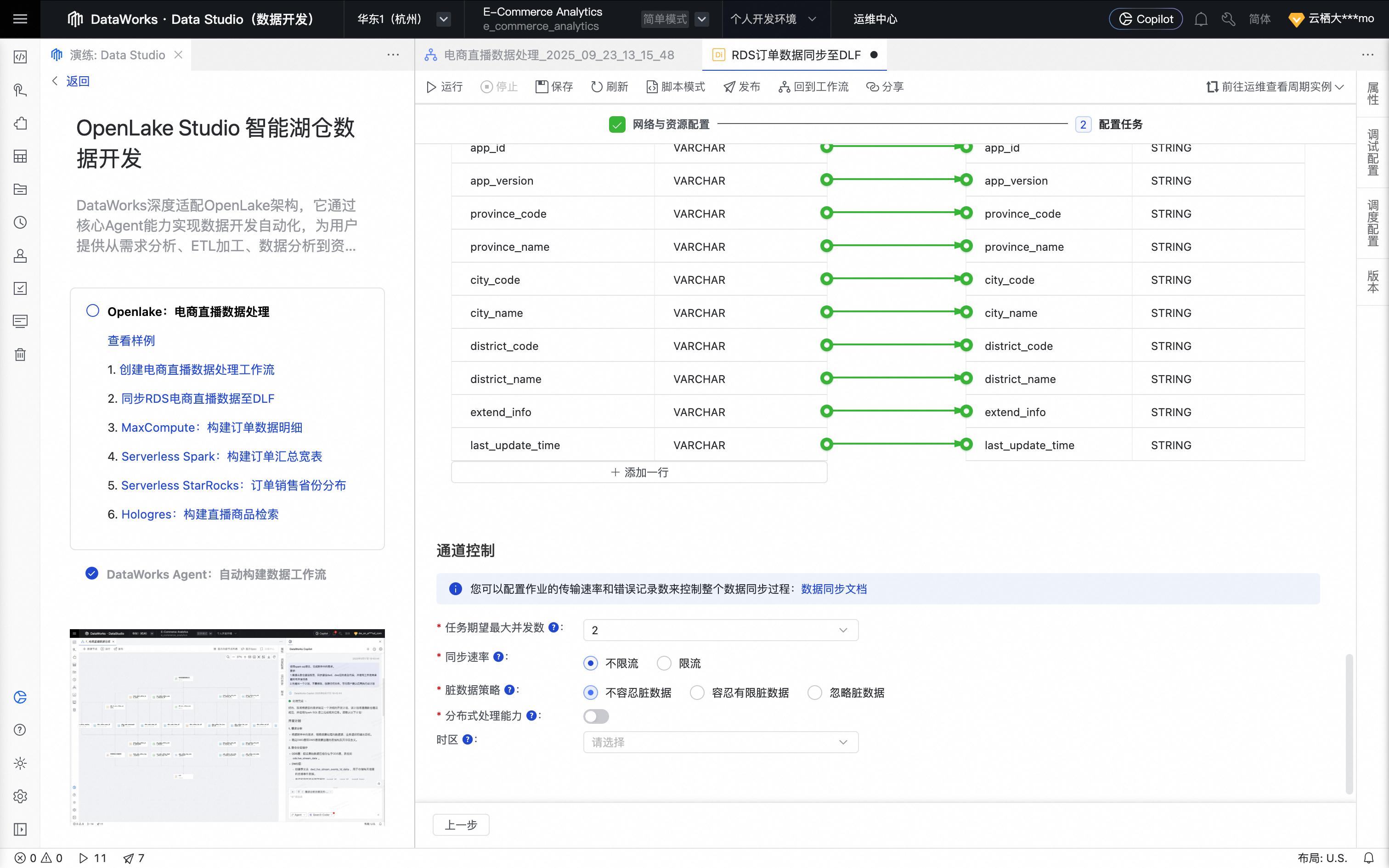
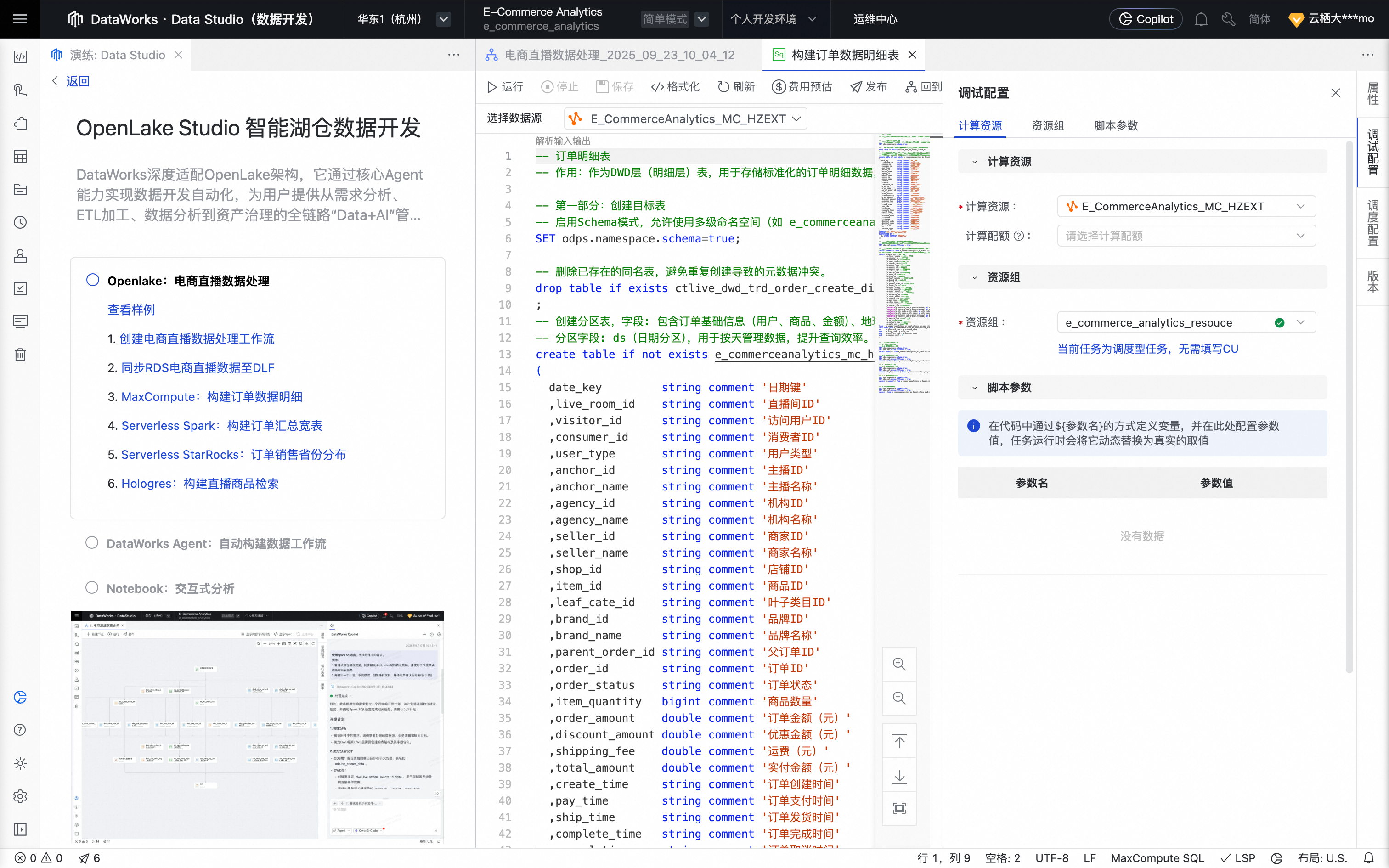
单击右侧工具栏的调试配置,设置预先准备好的计算资源及资源组。
单击节点编辑页面上方的保存和运行按钮,开始数据同步。
三、通过MaxCompute SQL构建订单数据明细
单击MaxCompute:构建订单数据明细按钮,创建 MaxCompute SQL 节点。
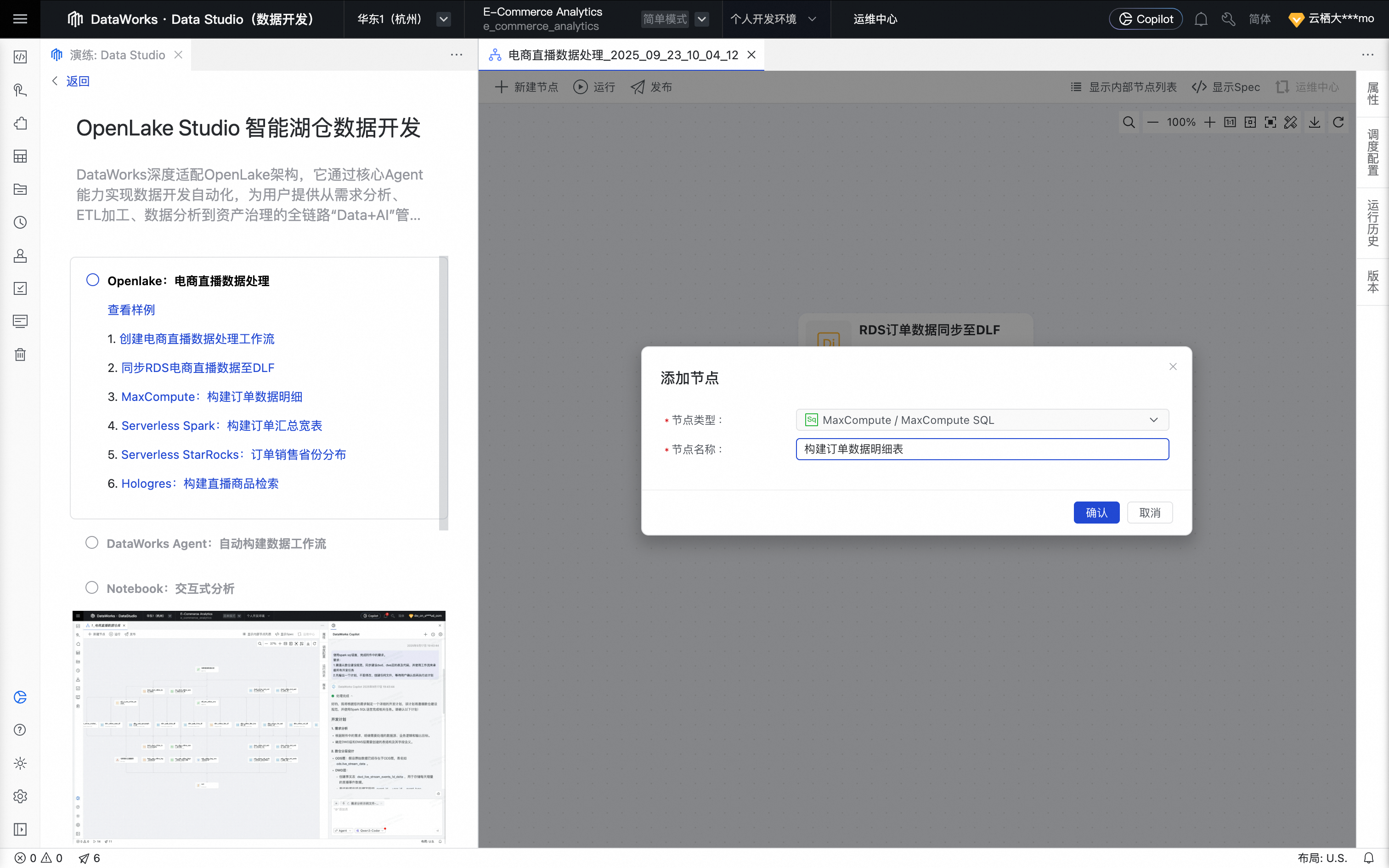
单击确认后,节点创建成功。
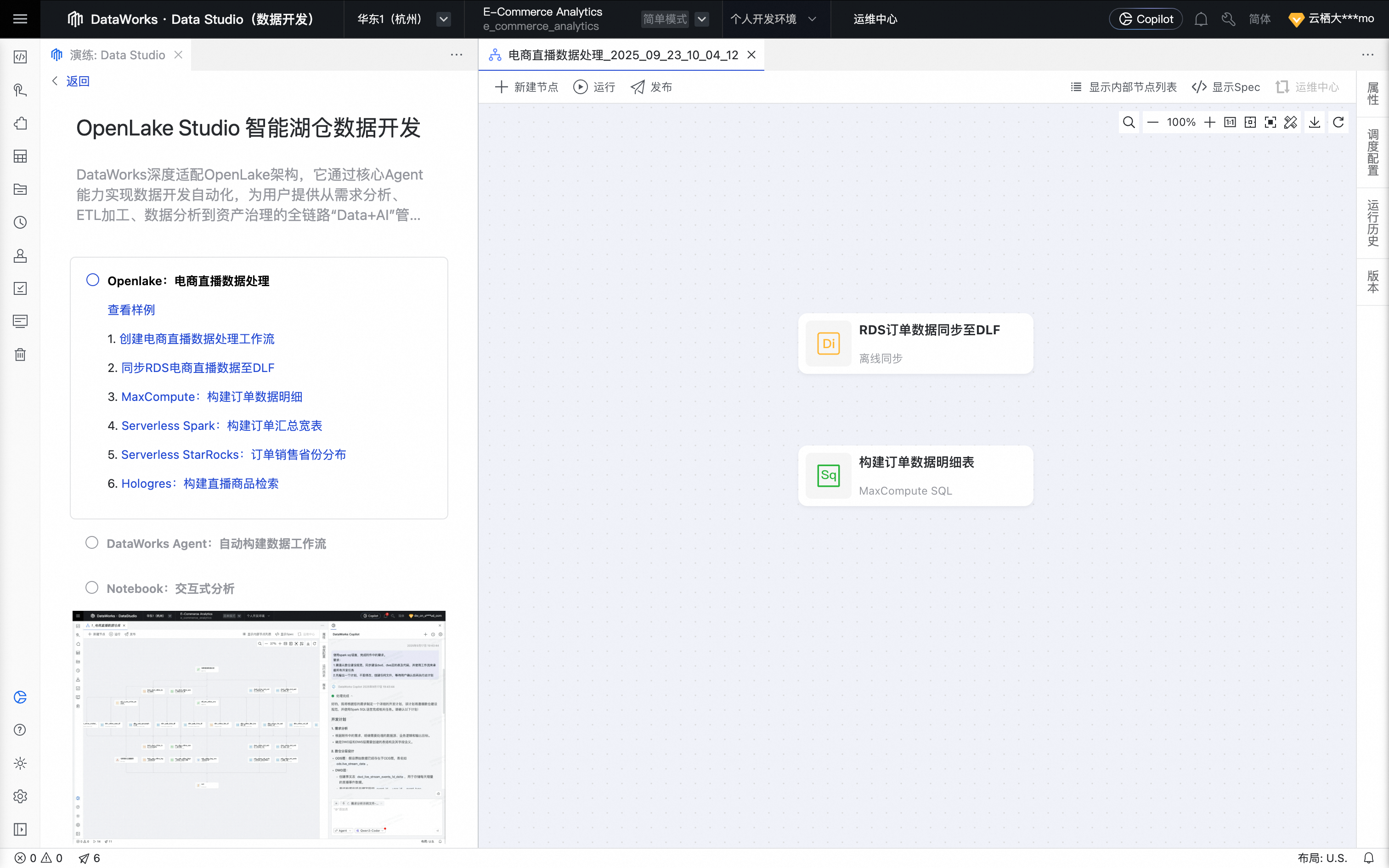
鼠标移动至该节点上,单击打开节点进入配置页面。系统自动填充如下业务处理代码。
单击右侧工具栏的调试配置,设置预先准备好的计算资源及资源组。
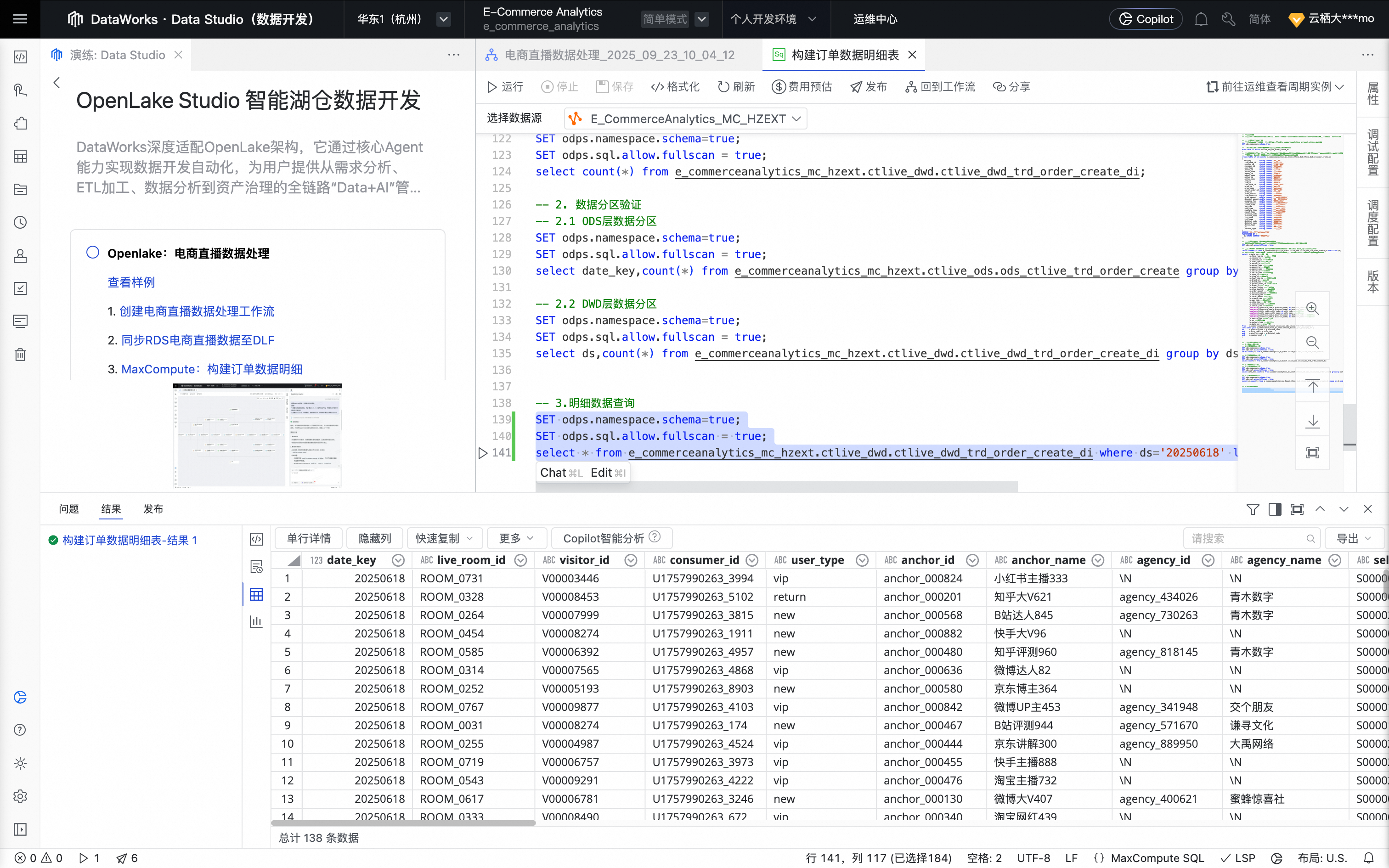
单击节点编辑页面上方的运行按钮,运行任务。
任务运行完成后,可在查询结果区域查看任务执行结果及订单明细数据。
四、通过Serverless Spark SQL构建订单汇总宽表
回到实践方案的工作流页,单击Serverless Spark:构建订单汇总宽表,创建Serverless Spark SQL节点。
单击确认后,节点创建成功。
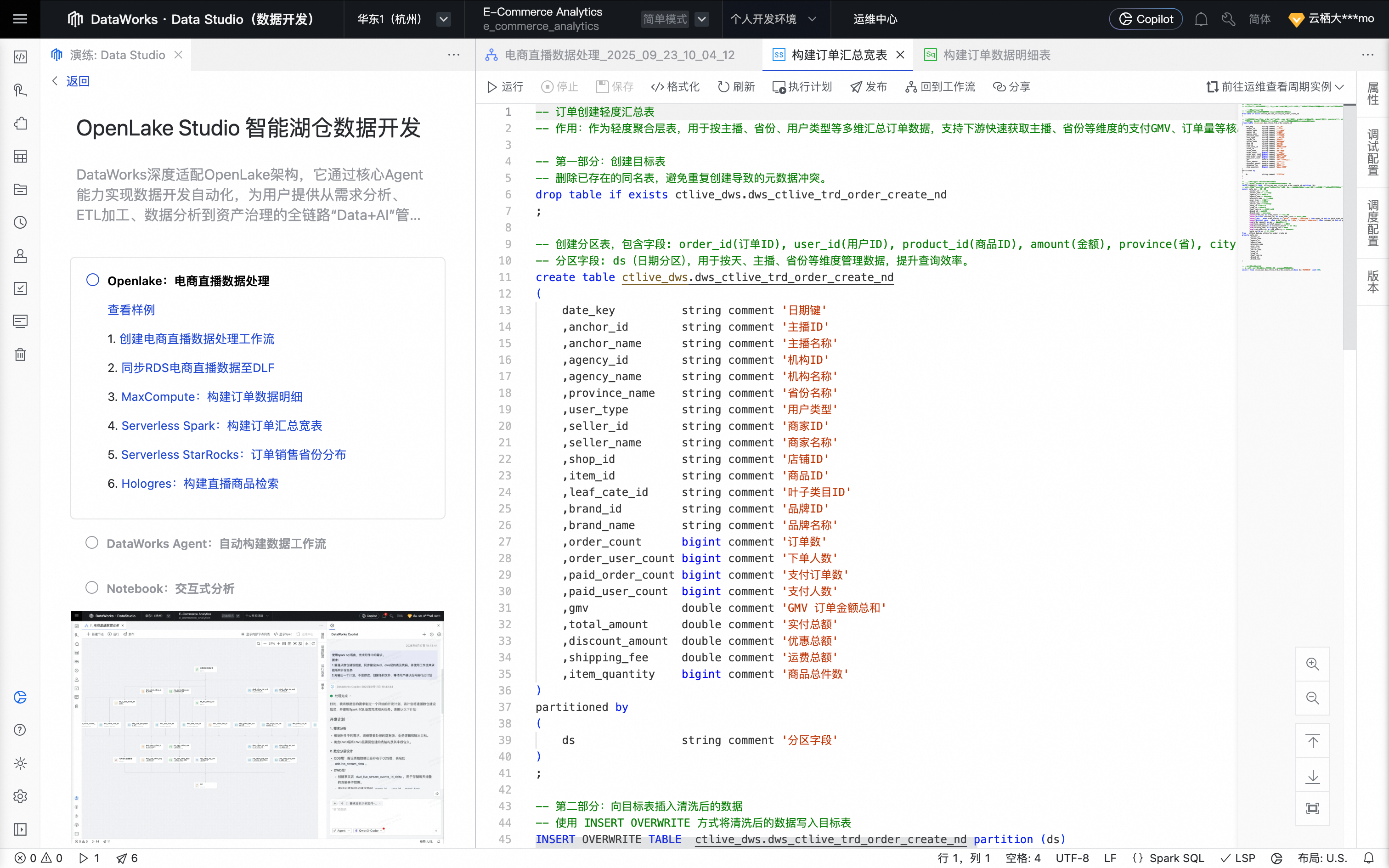
鼠标移动至该节点上,单击打开节点进入配置页面。系统自动填充如下业务处理代码。
单击右侧工具栏的调试配置,设置预先准备好的计算资源及资源组。
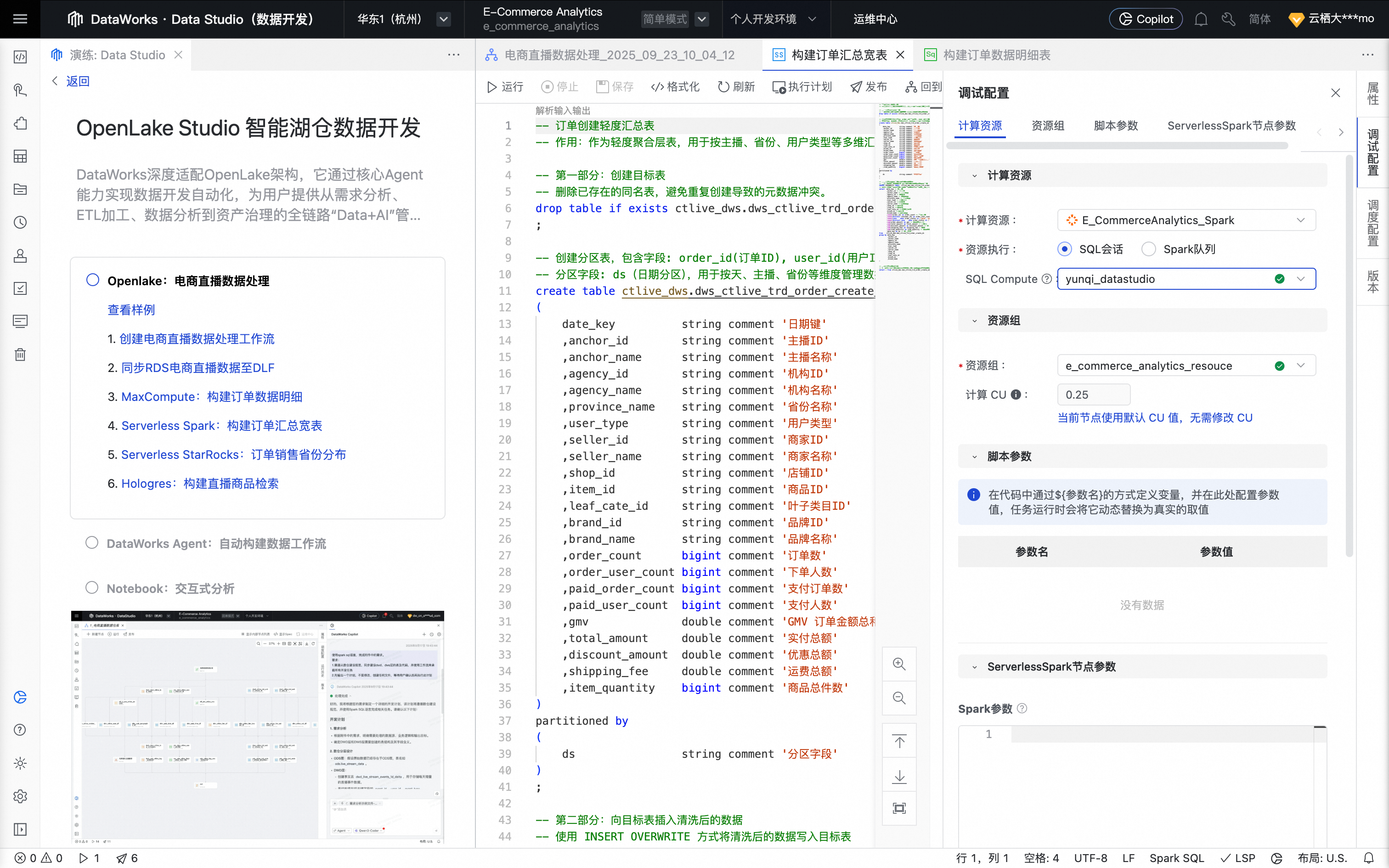
单击节点编辑页面上方的运行按钮,运行任务。
建议只运行代码最后select语句。
任务运行完成后,可在查询结果区域查看任务执行结果及订单汇总宽表数据。
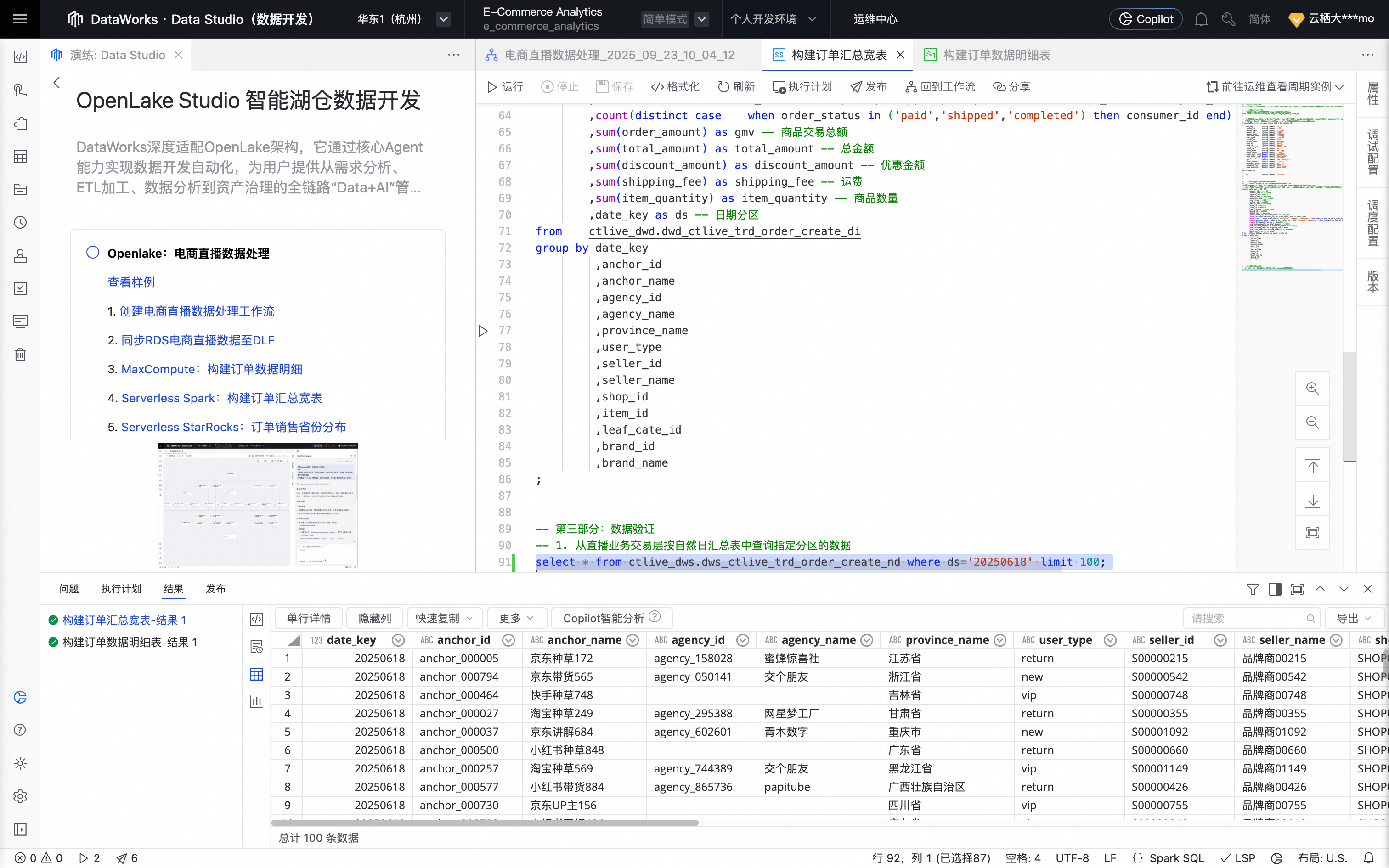
五、Serverless StarRocks SQL:分析订单销售省份分布
回到实践方案的工作流页,单击Serverless StarRocks:订单销售省份分布,创建 StarRocks SQL 节点 。
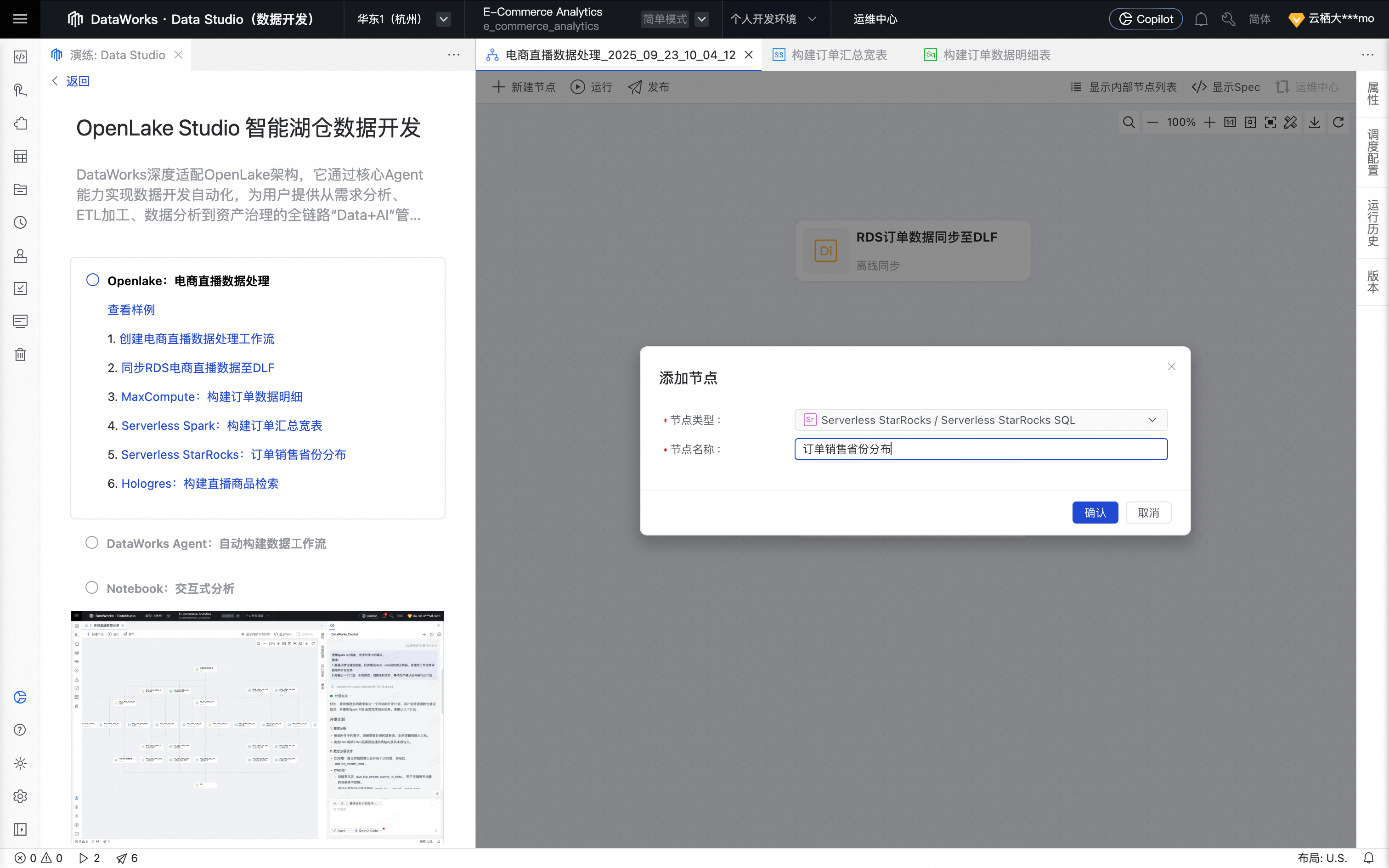
单击确认后,节点创建成功。
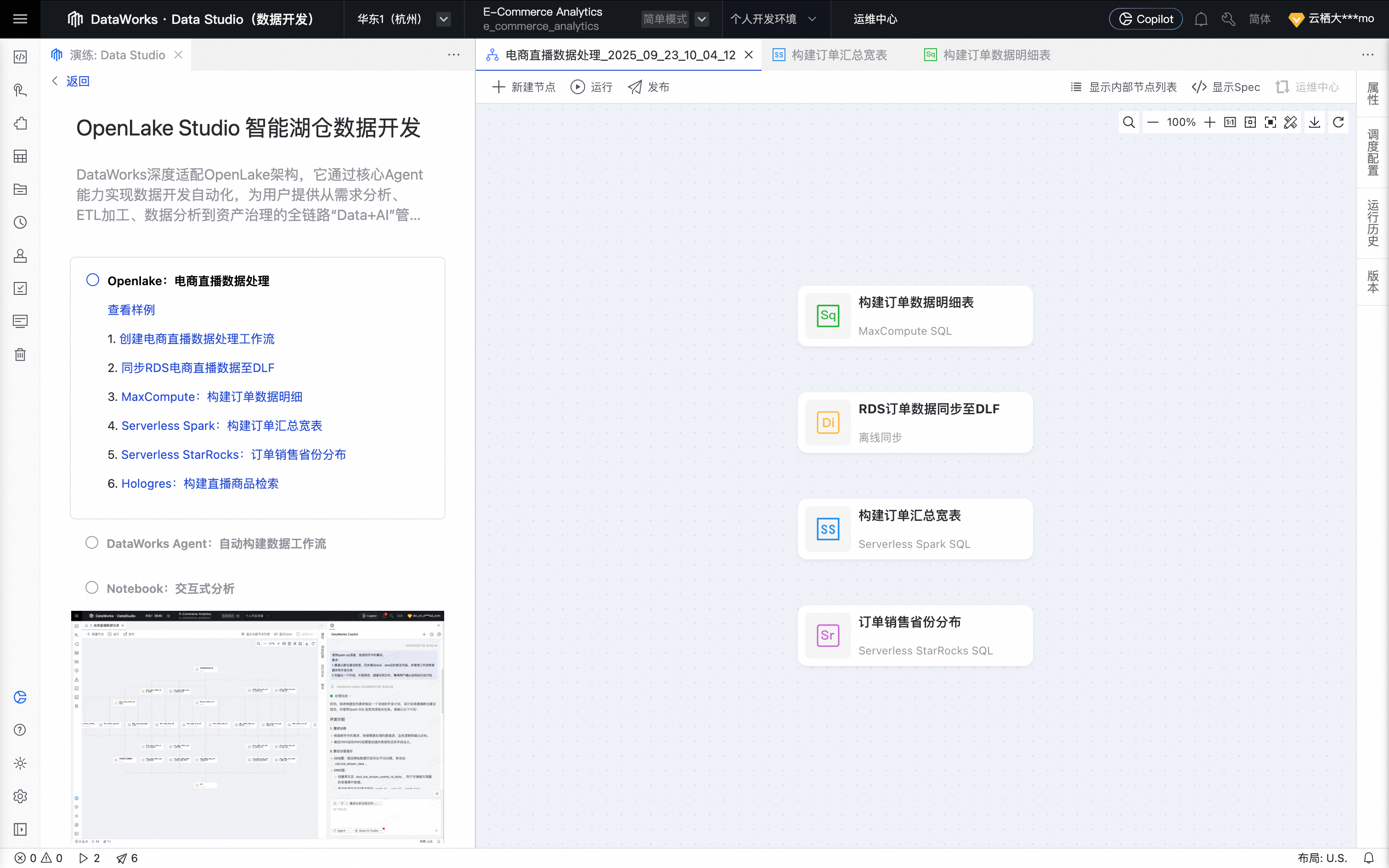
鼠标移动至该节点上,单击打开节点进入配置页面。系统填充如下业务处理代码。
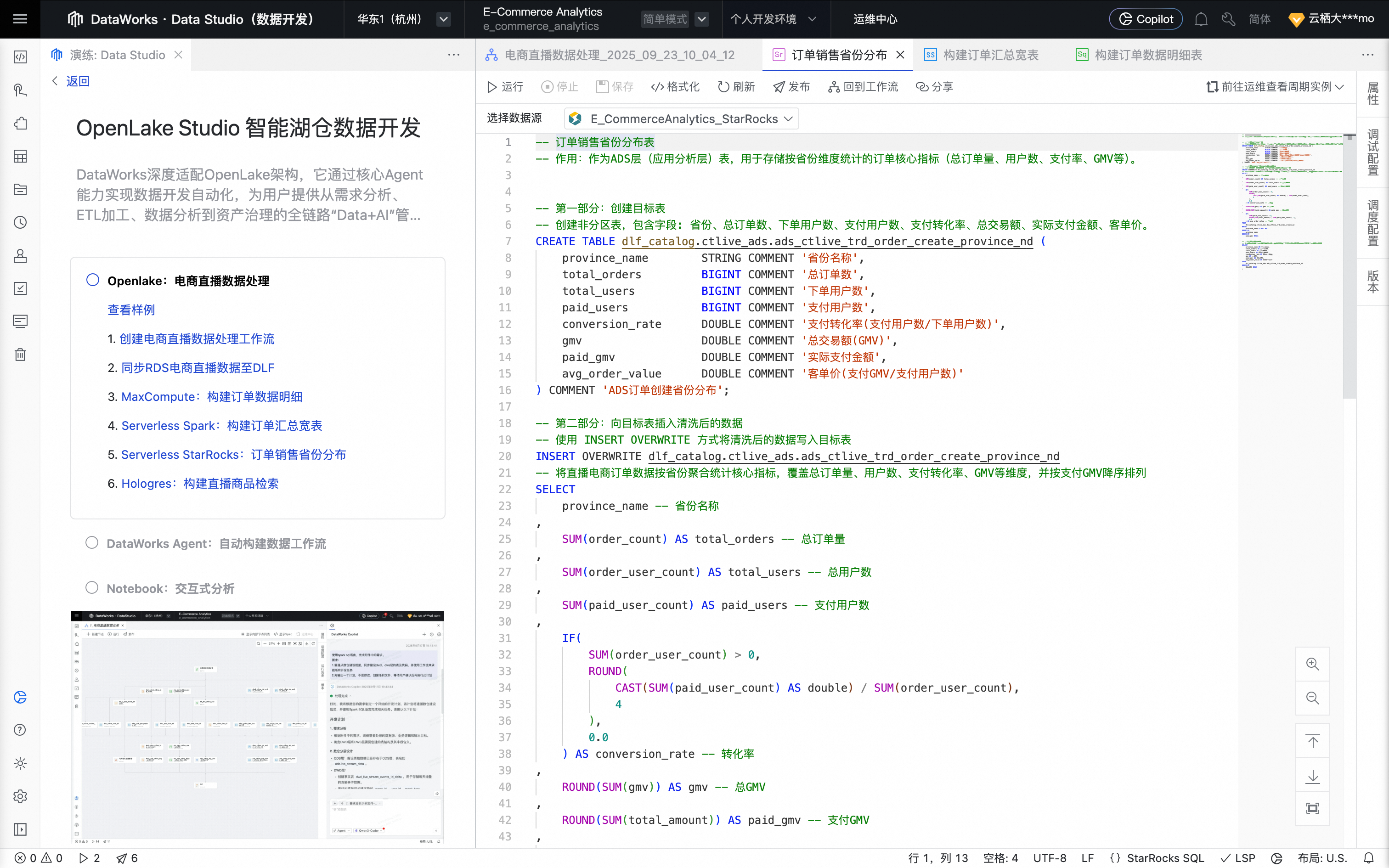
单击右侧工具栏的调试配置,设置预先准备好的计算资源及资源组。
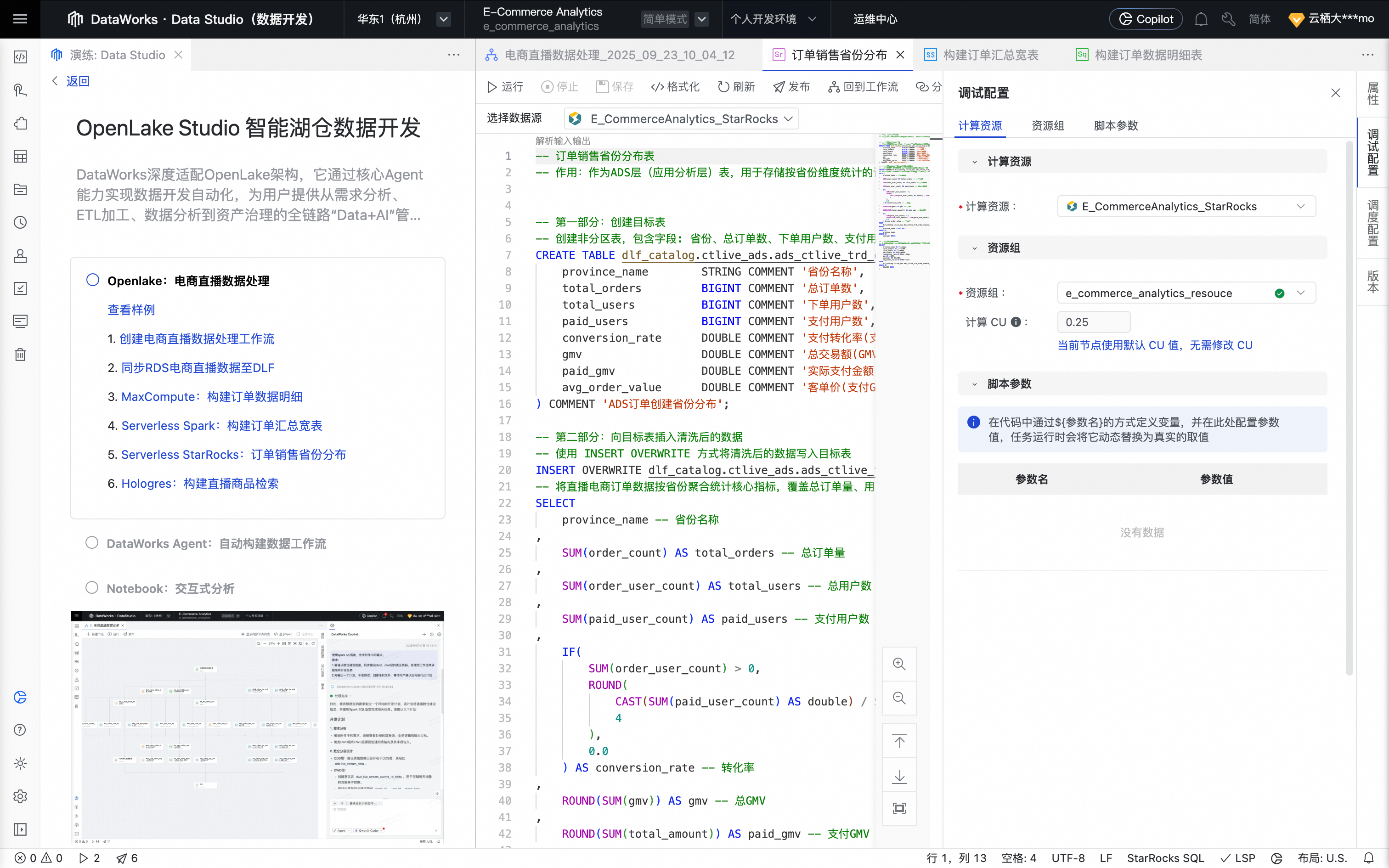
单击节点编辑页面上方的运行按钮,运行任务。
任务运行完成后,可在查询结果区域查看任务执行结果及订单明细数据。
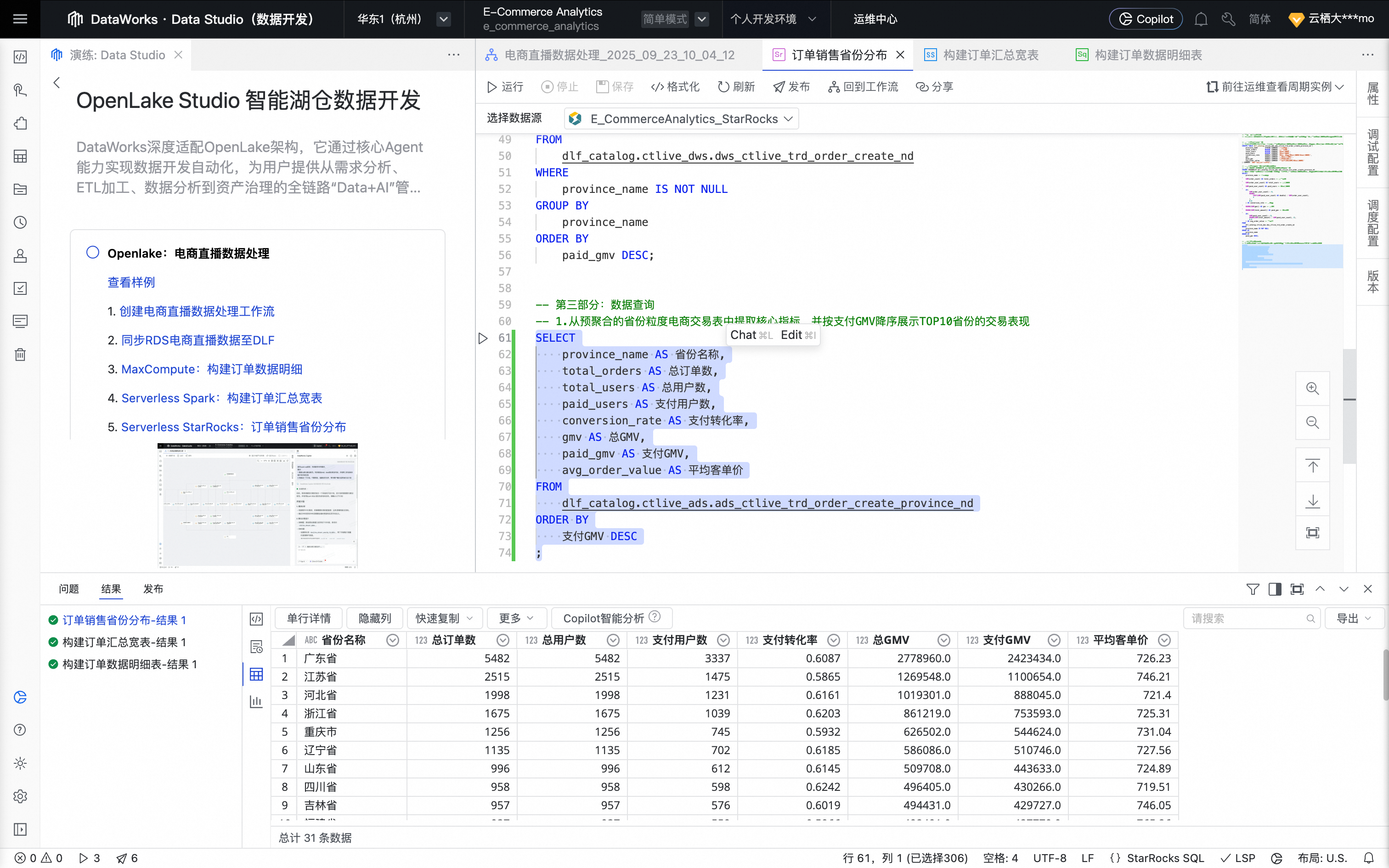
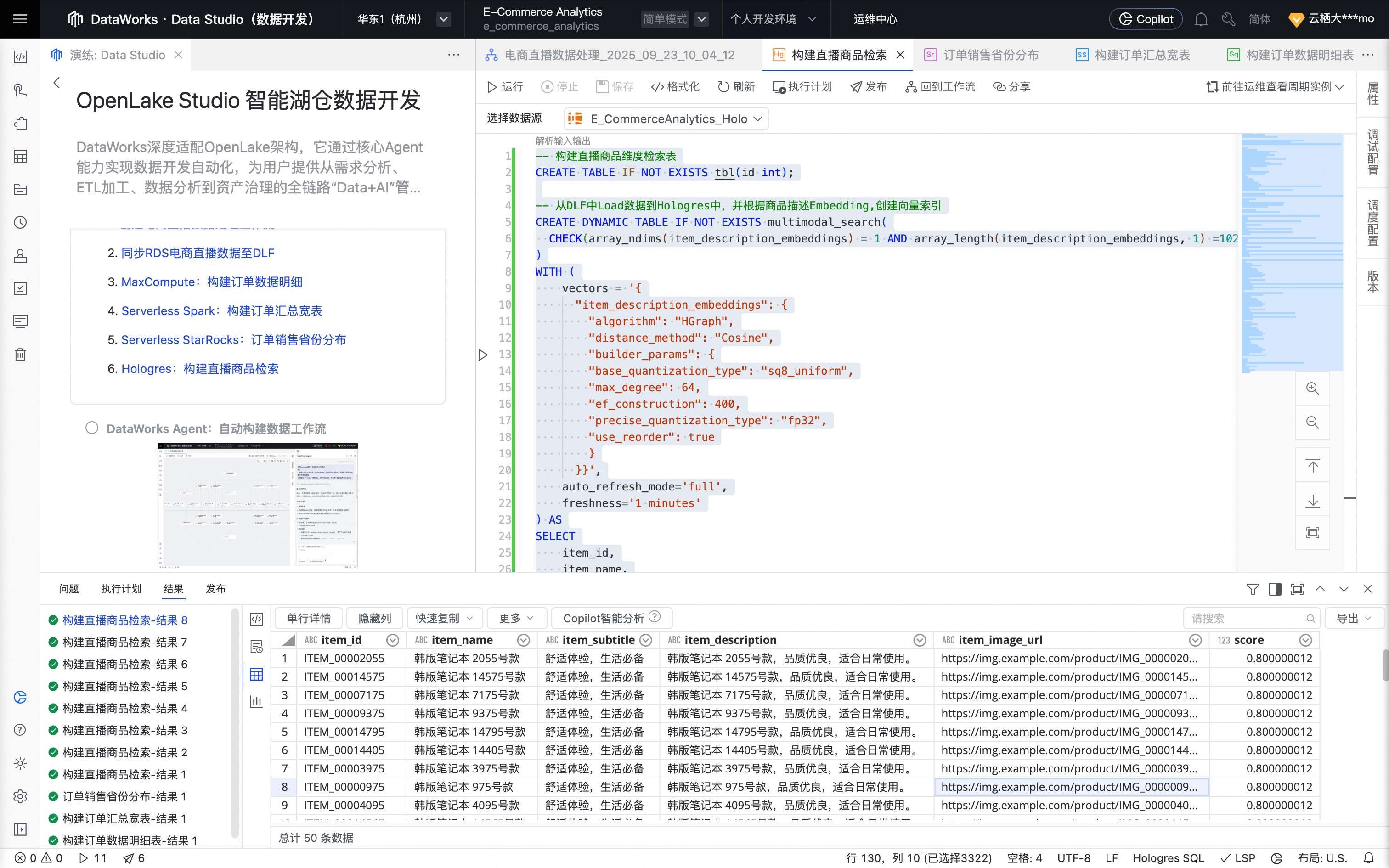
六、Hologres:构建直播商品检索
回到实践方案的工作流页,单击Hologres:构建直播商品检索,创建 Hologres SQL 节点。
单击确认后,节点创建成功。
鼠标移动至该节点上,单击打开节点进入配置页面。系统自动填充如下业务处理代码。
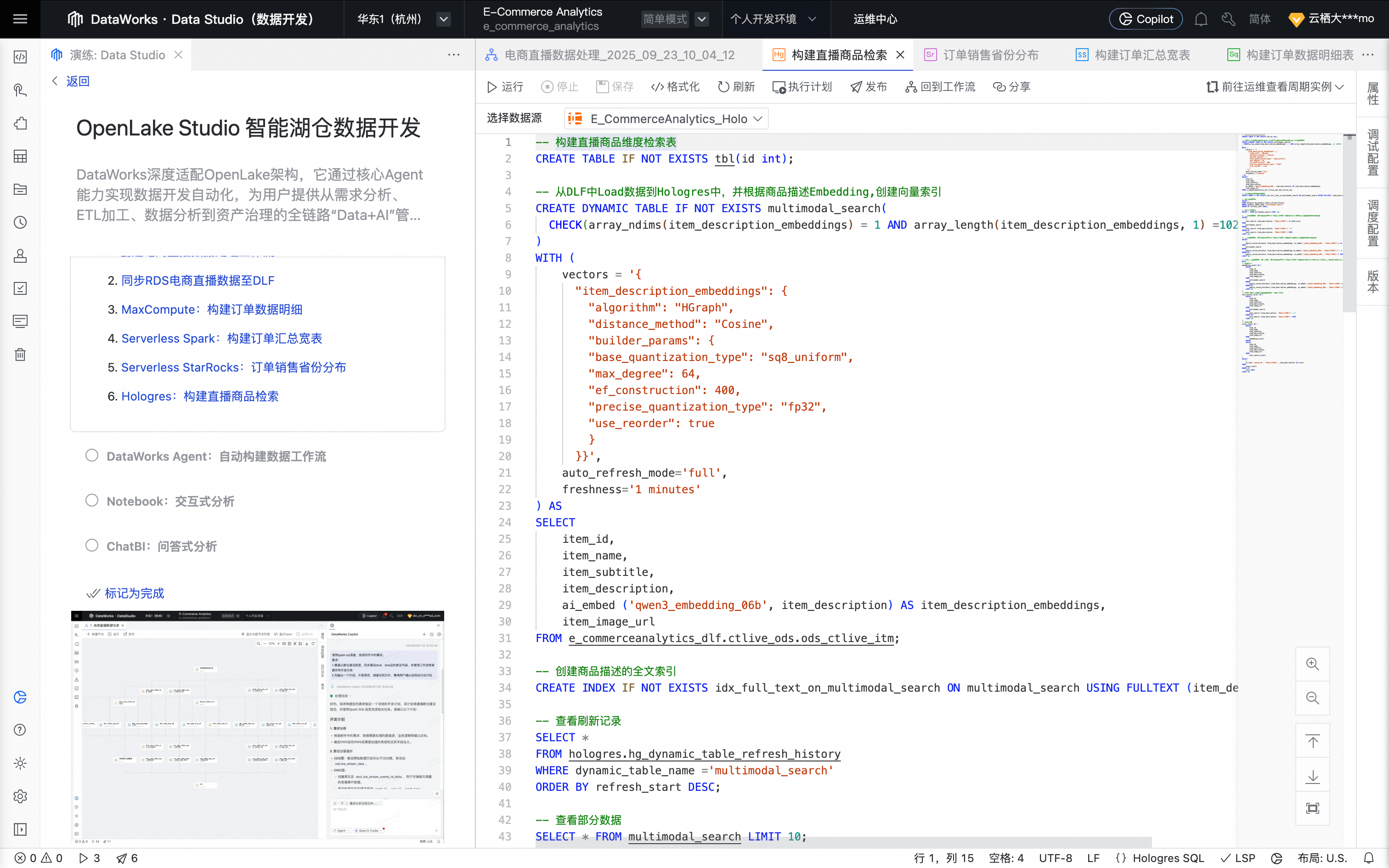
单击右侧工具栏的调试配置,设置预先准备好的计算资源及资源组。

单击节点编辑页面上方的运行按钮,运行任务。
任务运行完成后,可在查询结果区域查看任务执行结果及构建直播商品检索结果。
DataWorks Agent:自动构建数据工作流
回到演练页,单击DataWorks Agent:自动构建数据工作流。
系统自动输入 Prompt 并上传需求文档:
用户 Prompt:
请按照需求文档中的内容,构建“直播间订单数据分析”的ads层。 要求: 1.需遵从数仓建设规范,同步建设dwd、dws层的表及代码,并使用工作流来承载所有开发任务 2.ADS层的表使用 StarRocks 和 Hologres 实现,其余的表使用 Spark SQL 和 MaxCompute 实现 3.先输出一个计划,不要修改、创建任何文件,等待用户确认后再执行此计划需求文档内容:直播订单分析需求.md。
# 数据分析需求文档 ## 背景 **已有表:** - **ods_ctlive_trd_order_create** - 交易订单创建表 - **ods_ctlive_itm_df** 商品维度表 ## 需求 #### 1.1 商品销售分析 - **热销商品分析**:分析哪些商品销量最高、销售额最大 ## 注意事项 - **ADS层的表**:使用 StarRocks 和 Hologres 实现 - **其余的表**:使用 Spark SQL 和 MaxCompute 实现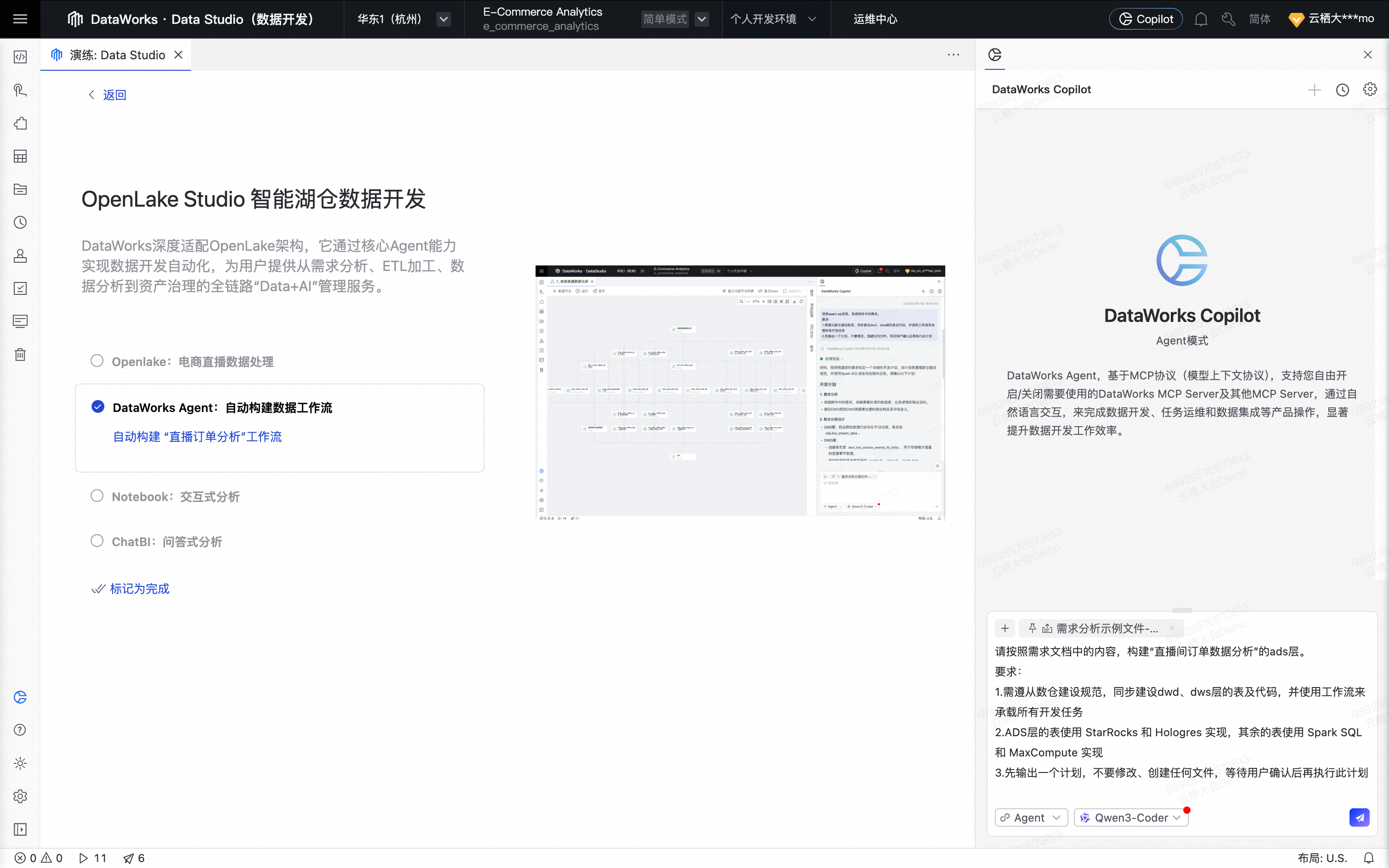
单击右下角对话框的发送按钮,Agent 开始分析需求。
DataWorks Agent按照输入,并结合历史对话记录,准确识别用户意图,开始生成数据开发执行计划;在计划生成过程中,Agent能够智能感知上下文数据,自主查找相关元数据信息,参考大数据最佳实践和用户自定义的企业知识库。
为了更好的呈现Agent的产出内容,手动将中间空间页面拉宽一些。
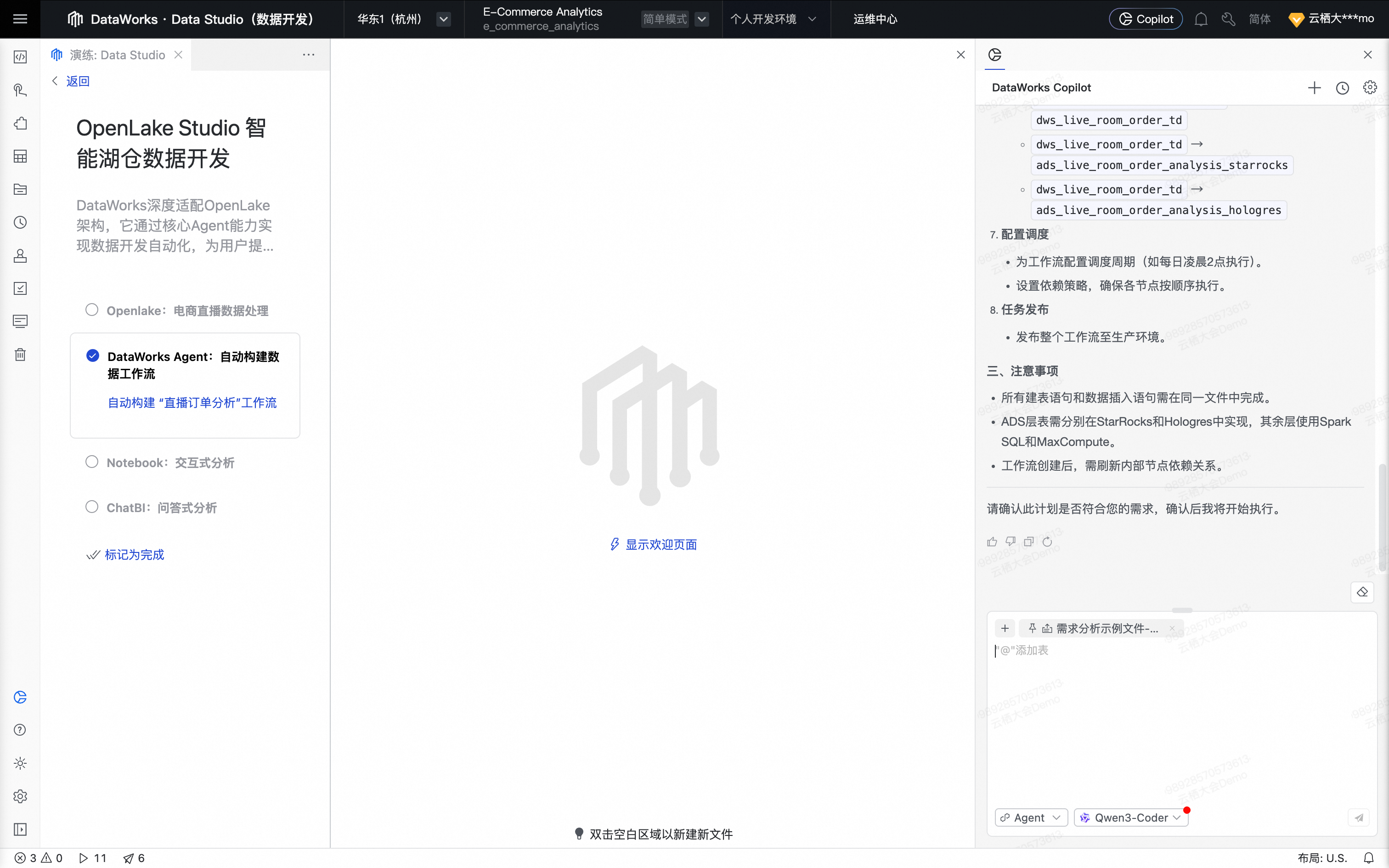
在DataWorks Copilot Prompt 输入框中输入“继续”并发送。
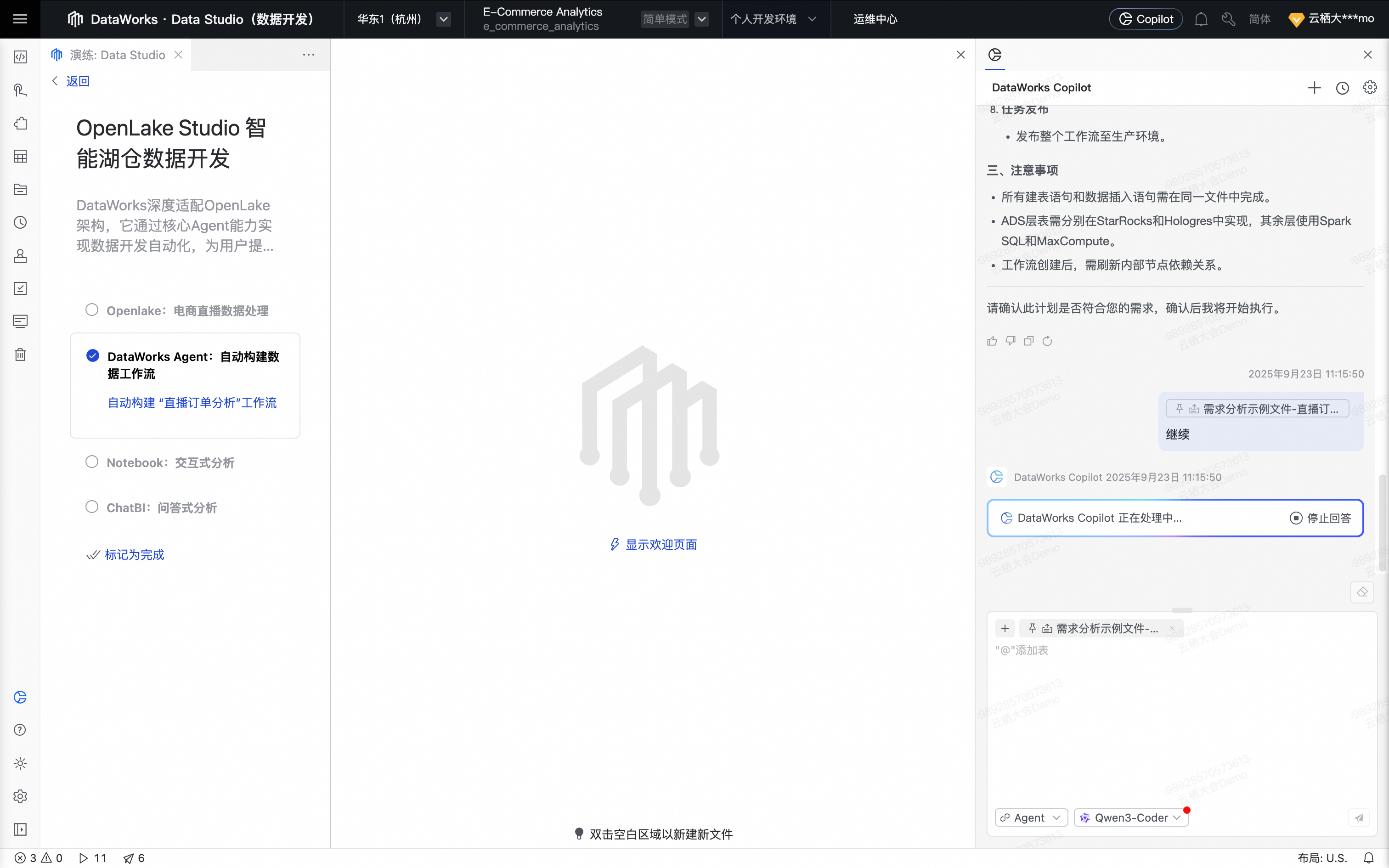
Agent自主调用DataWorks MCP Server中相关工具,依次生成所需数据处理节点,同时根据需求生成对应的SQL代码。
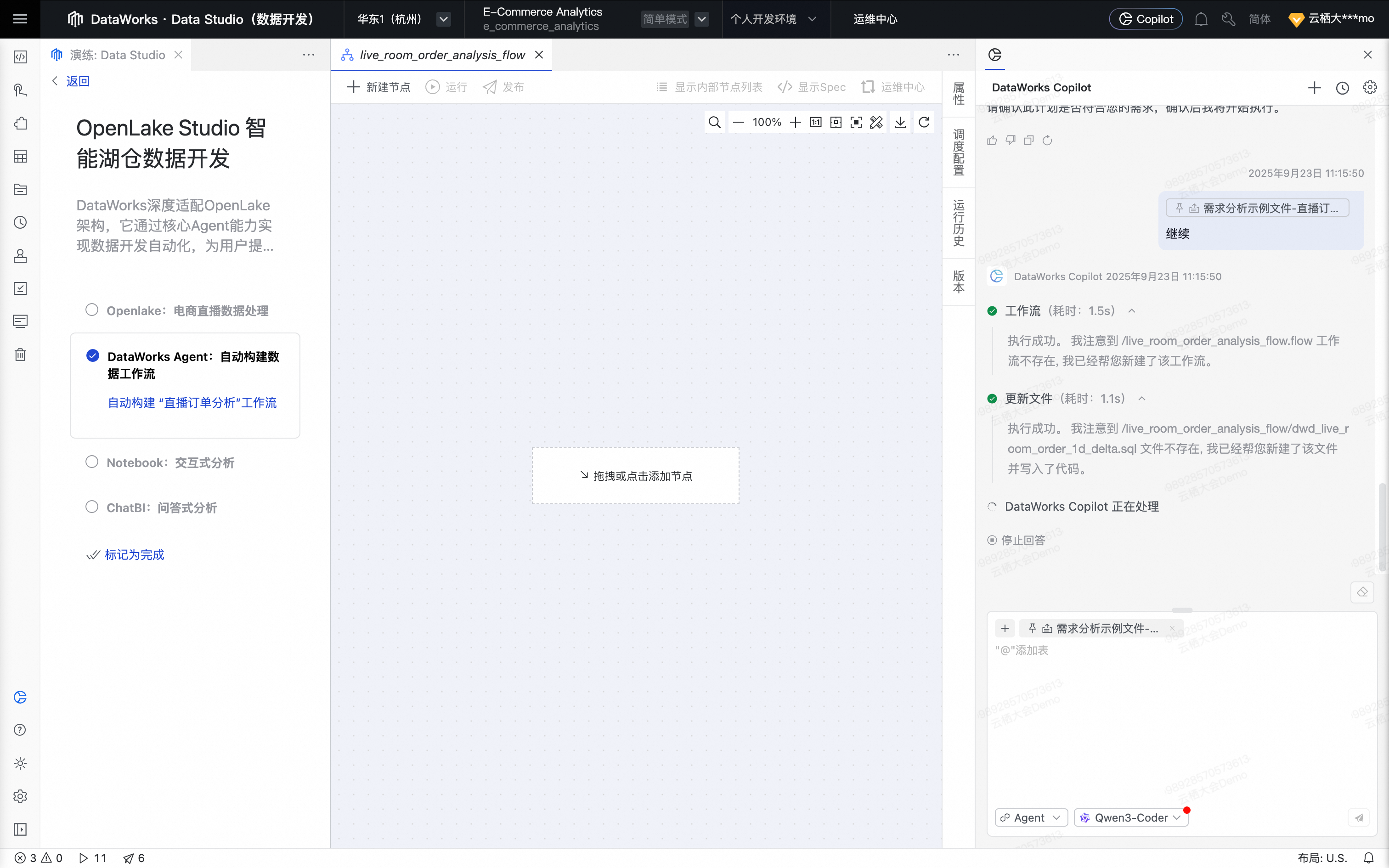
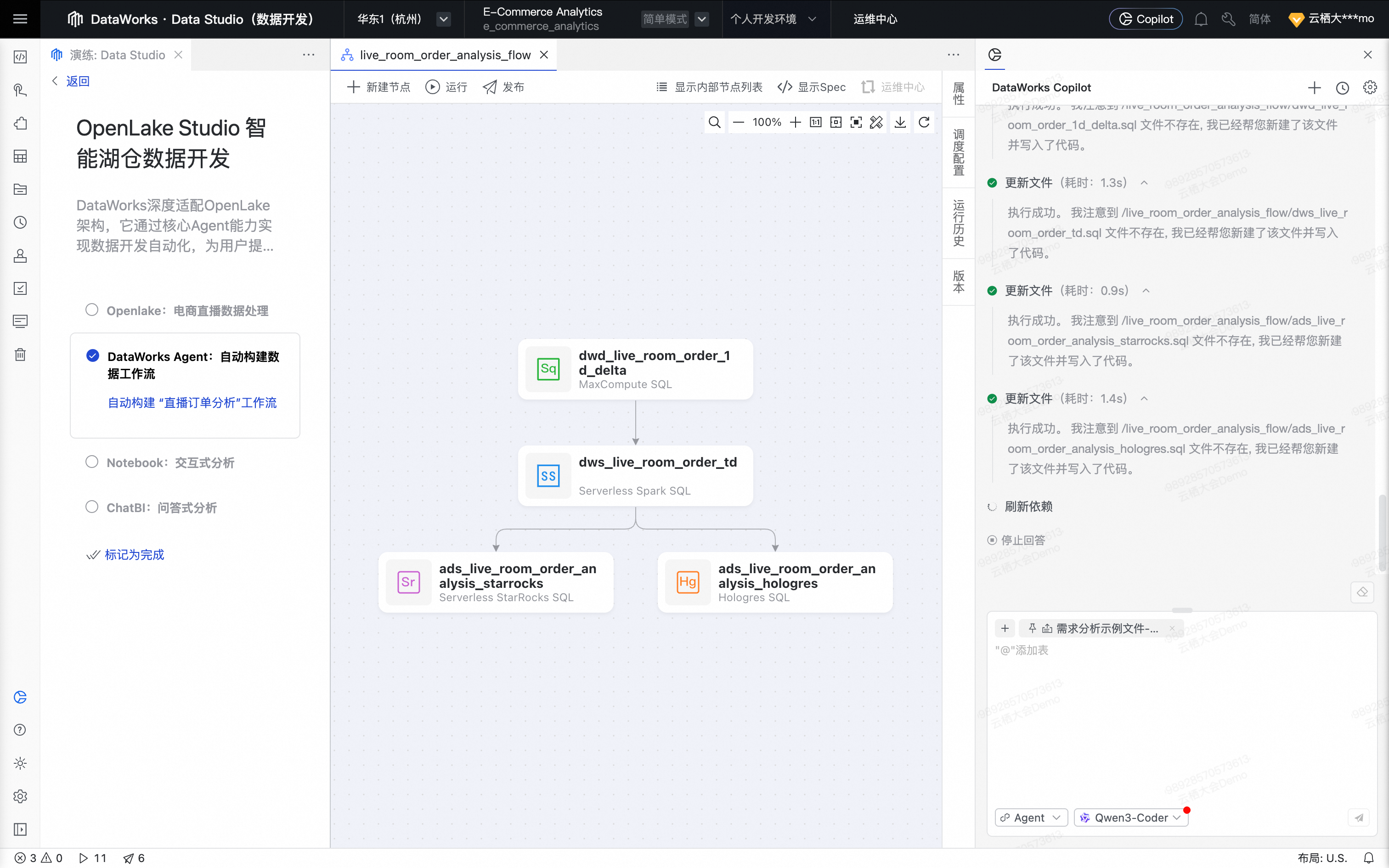
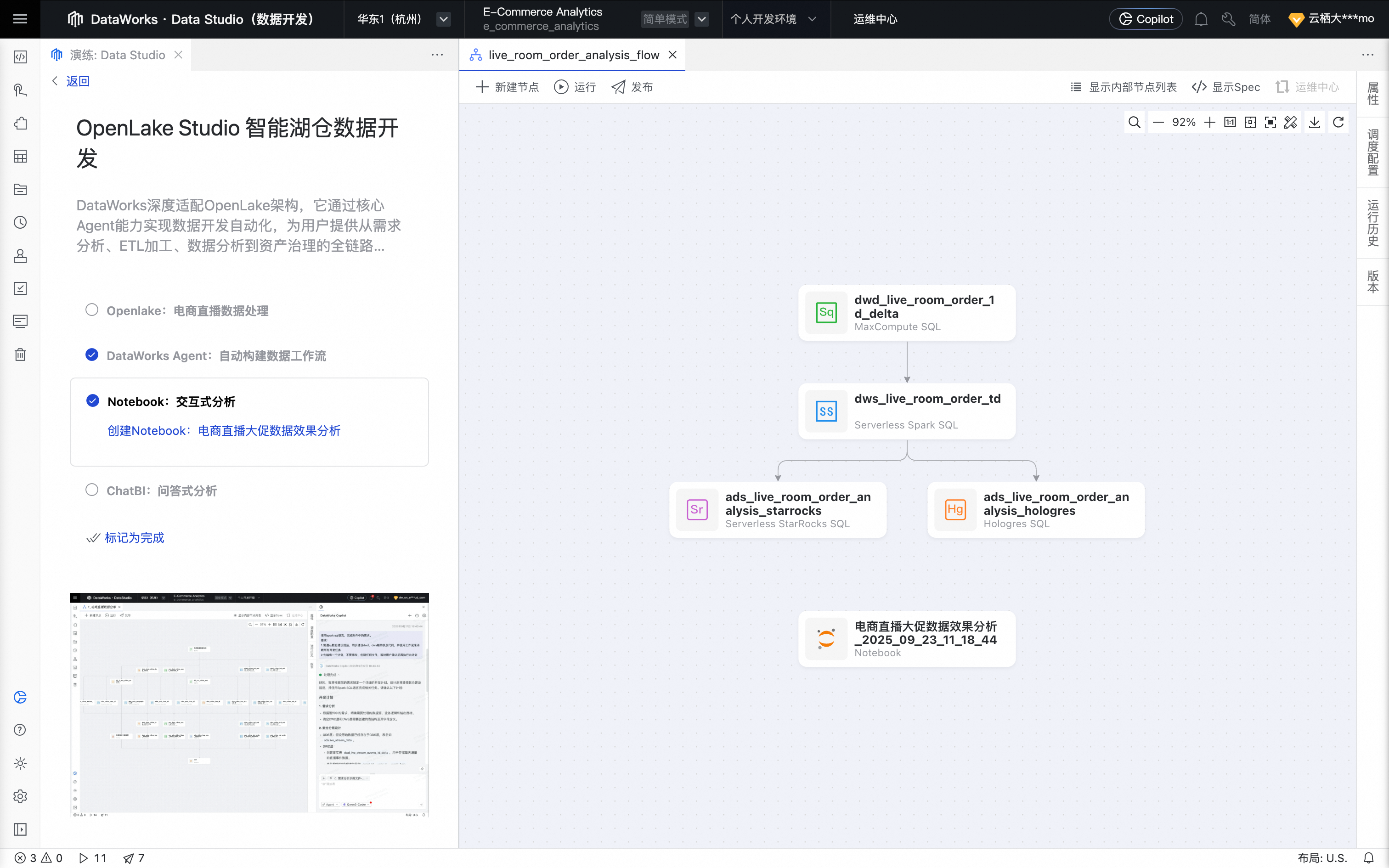
Agent将所有数据处理节点自动编排为一个工作流。
为最优体验,可手动单击工作流格式化及页面居中。
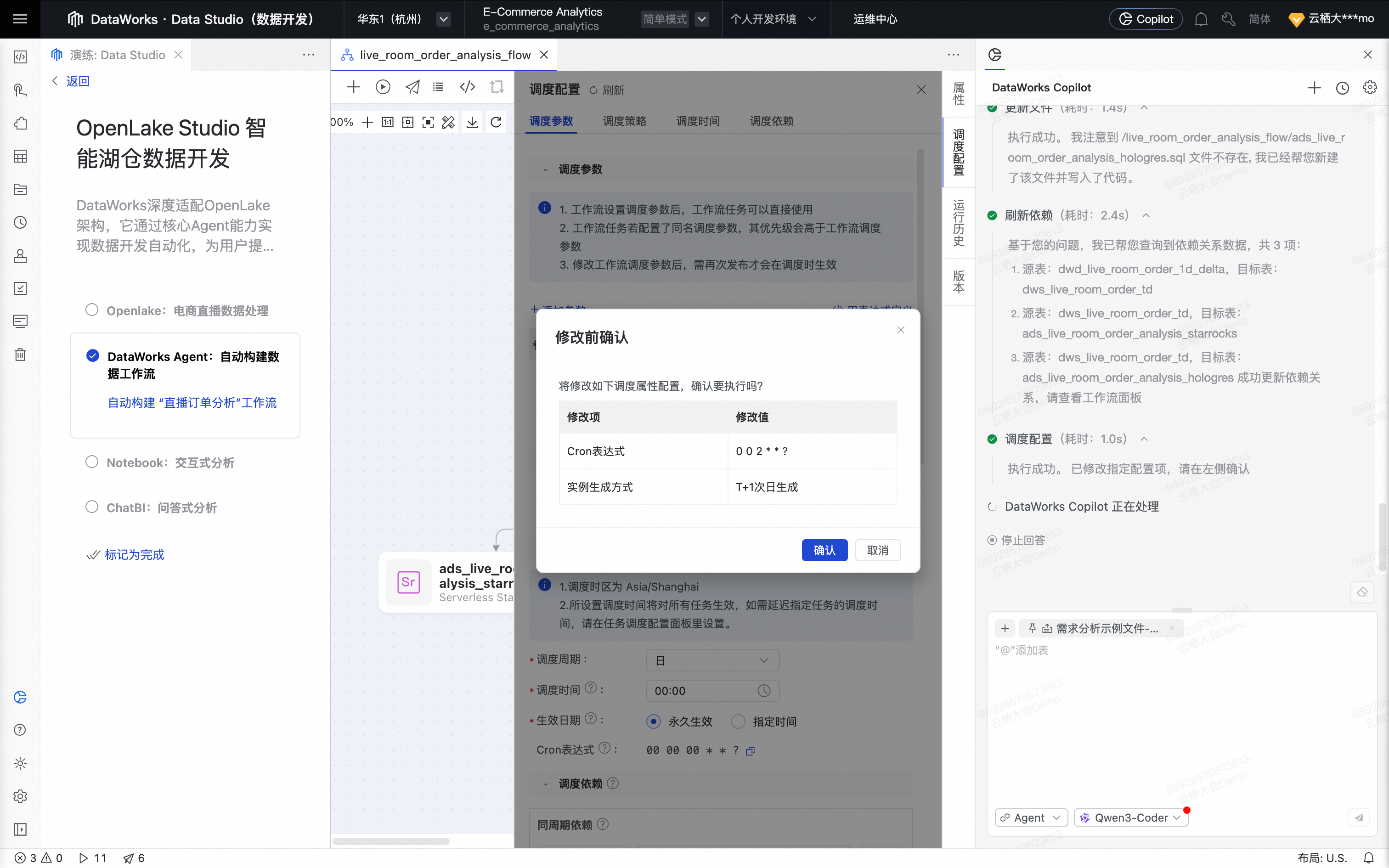
Agent完成工作流生成后,按照要求,配置任务调度。单击确认,确认工作流调度配置。
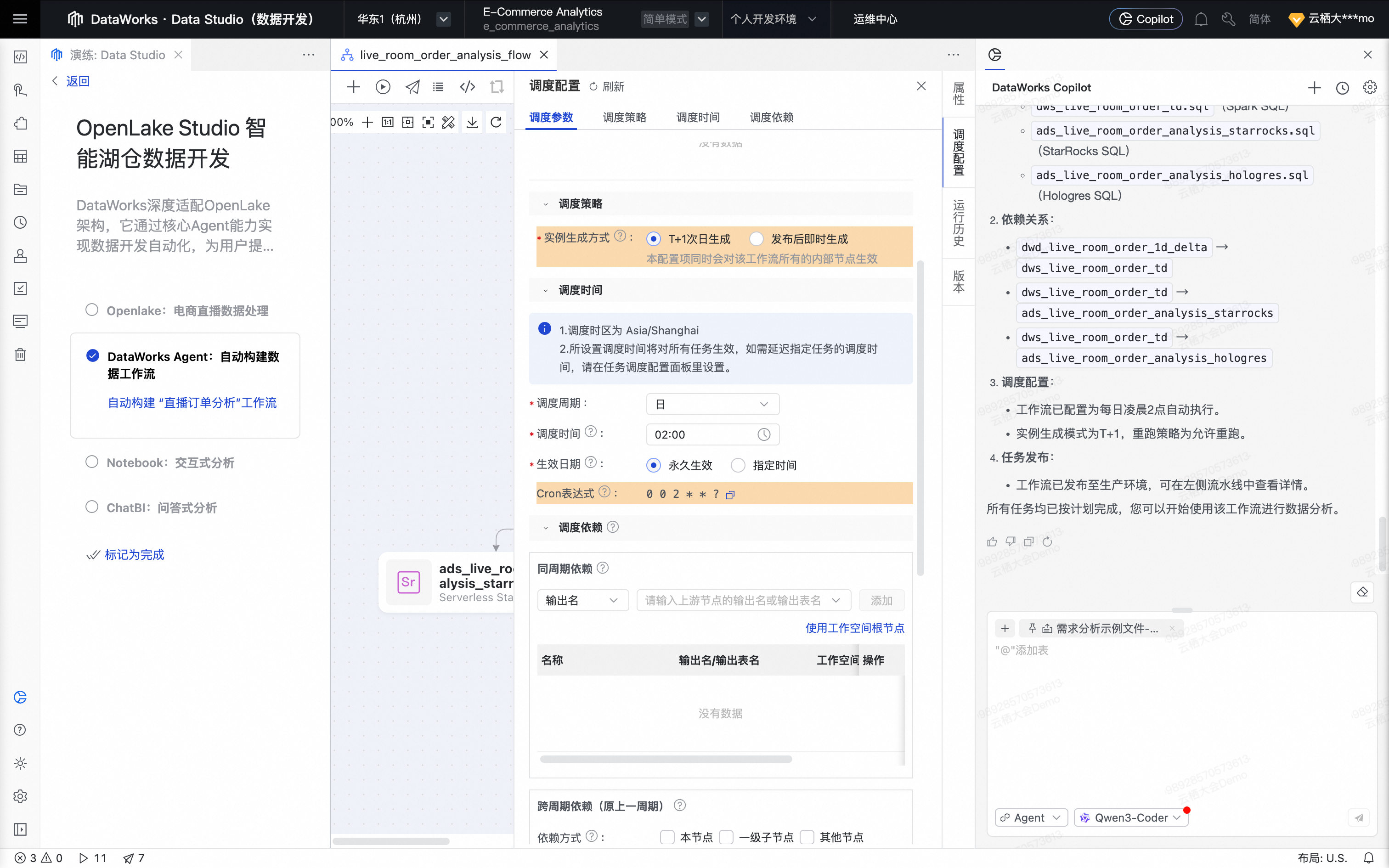
Agent开始发布工作流,用户确认发布方式,单击确认。
为确保小屏幕上的最优体验,关闭调度配置抽屉,拉高发布方式选择框,并将工作流页面居中。
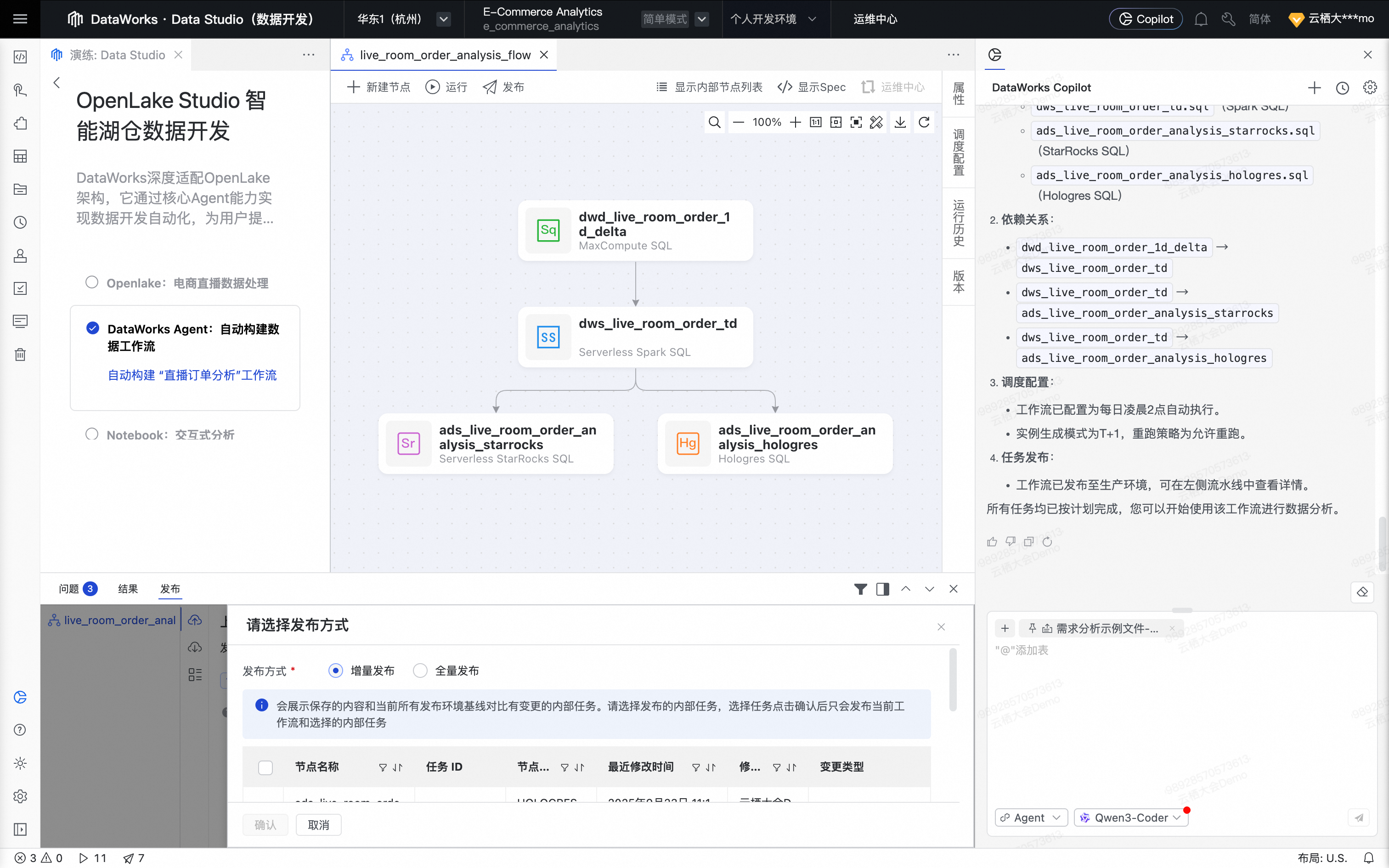
Agent继续发布工作流。
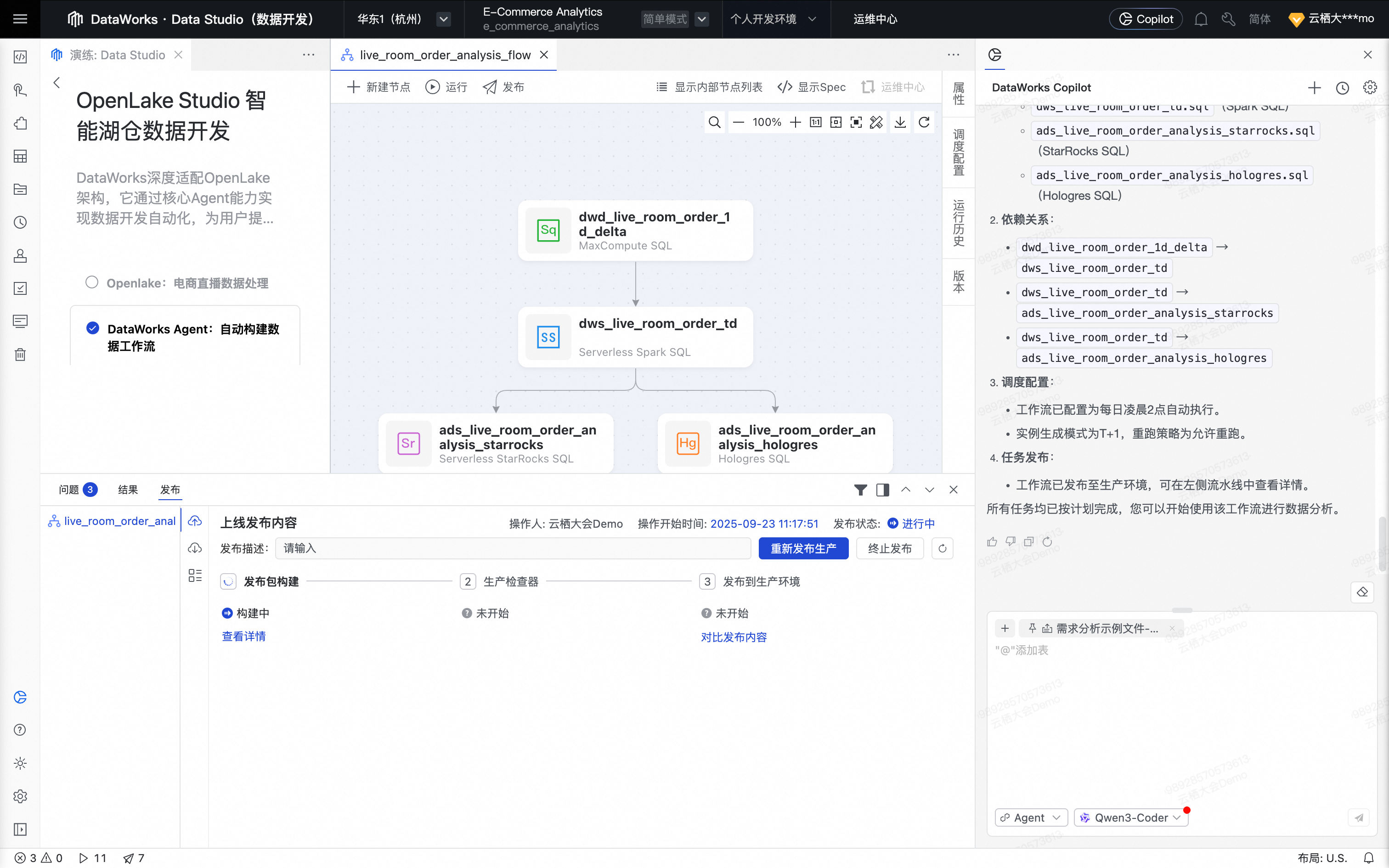
至此,Agent 完成发布,DataWorks Agent就自动完成一个ETL开发需求。
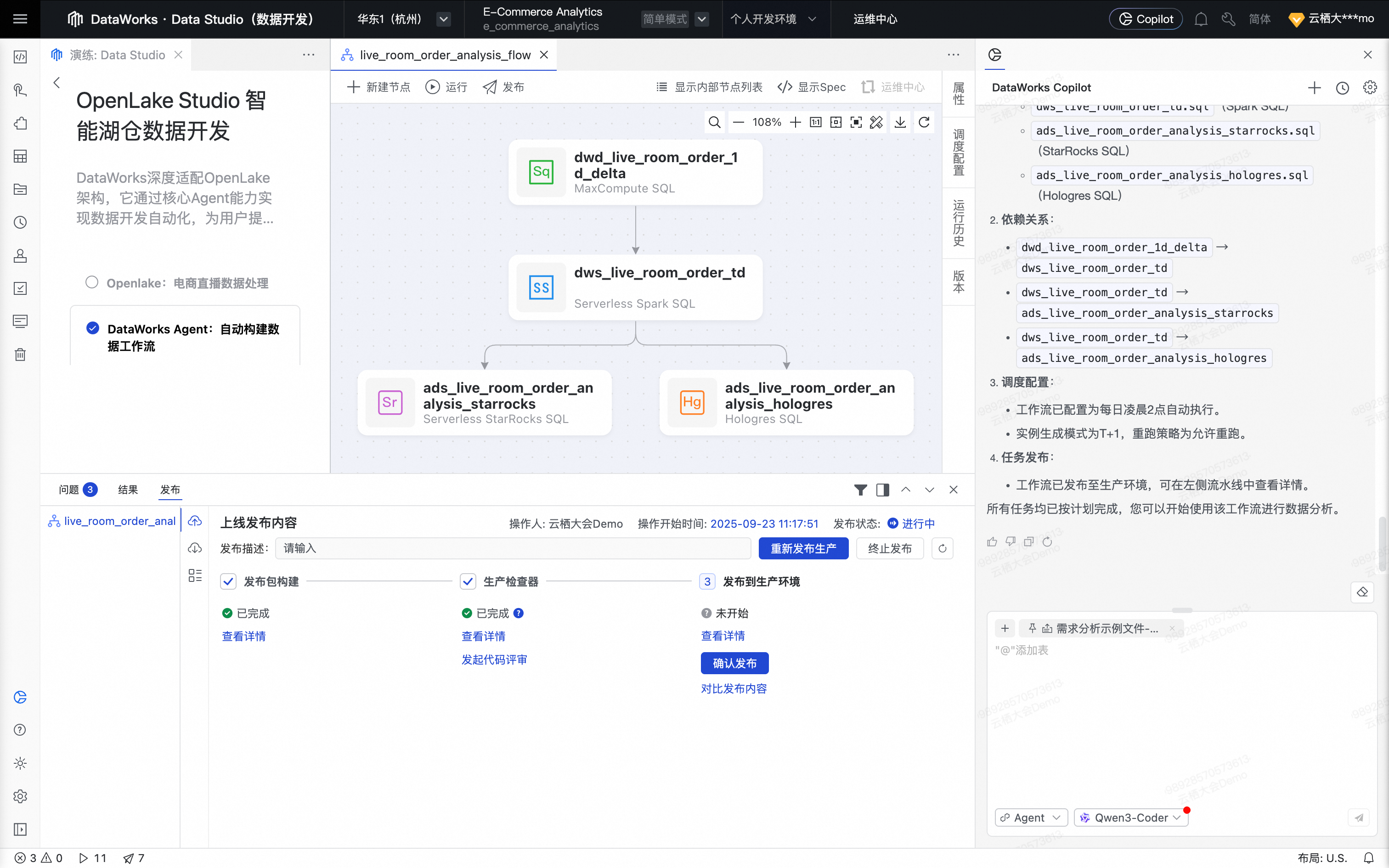
Notebook:交互式分析
回到演练页,单击Notebook:交互式分析。

单击创建Notebook:电商直播大促数据效果分析,此时将在已创建的工作流中出现添加节点的弹窗,单击确认。
鼠标移动至该节点上,单击打开节点进入Notebook节点的编辑页面。
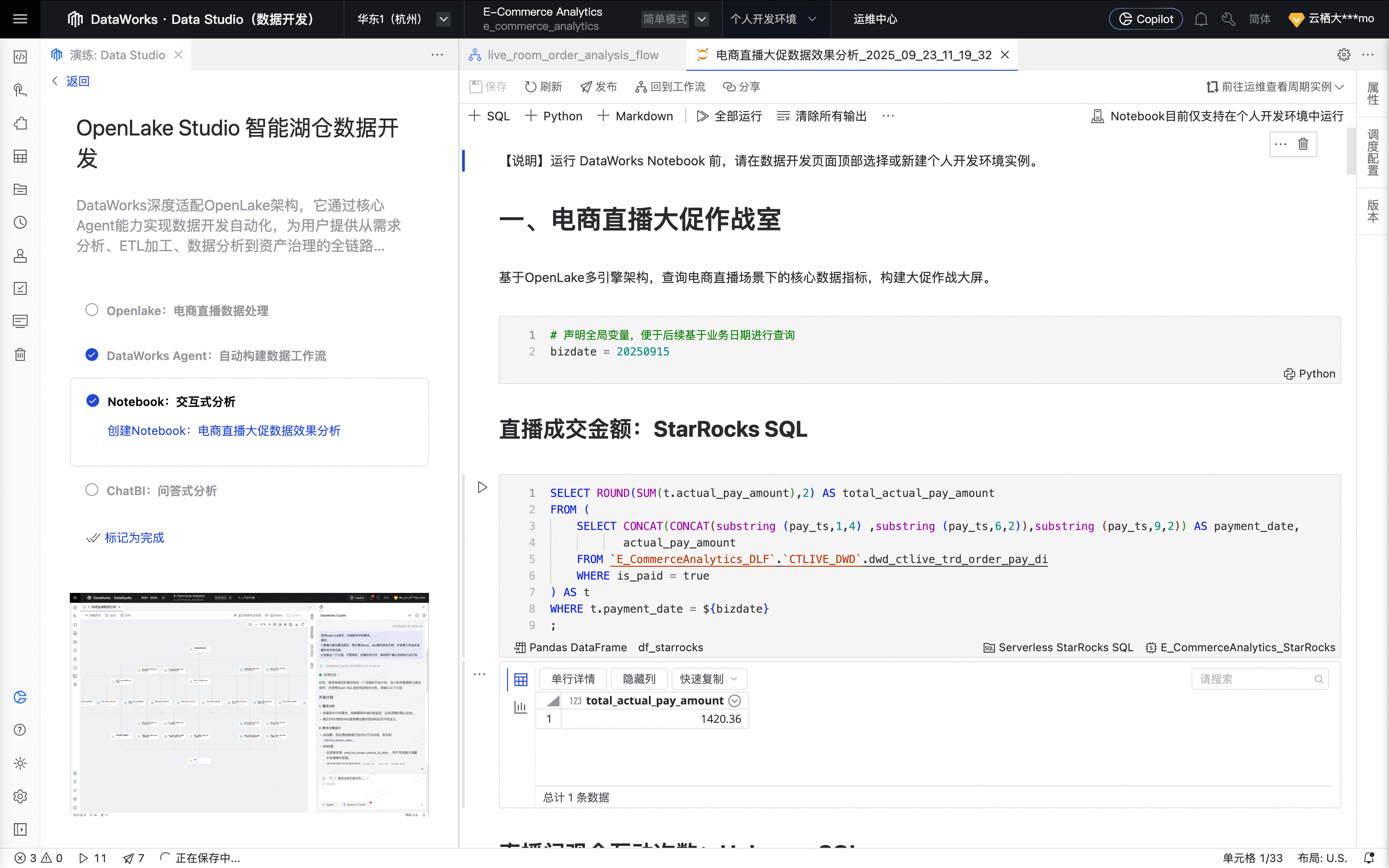
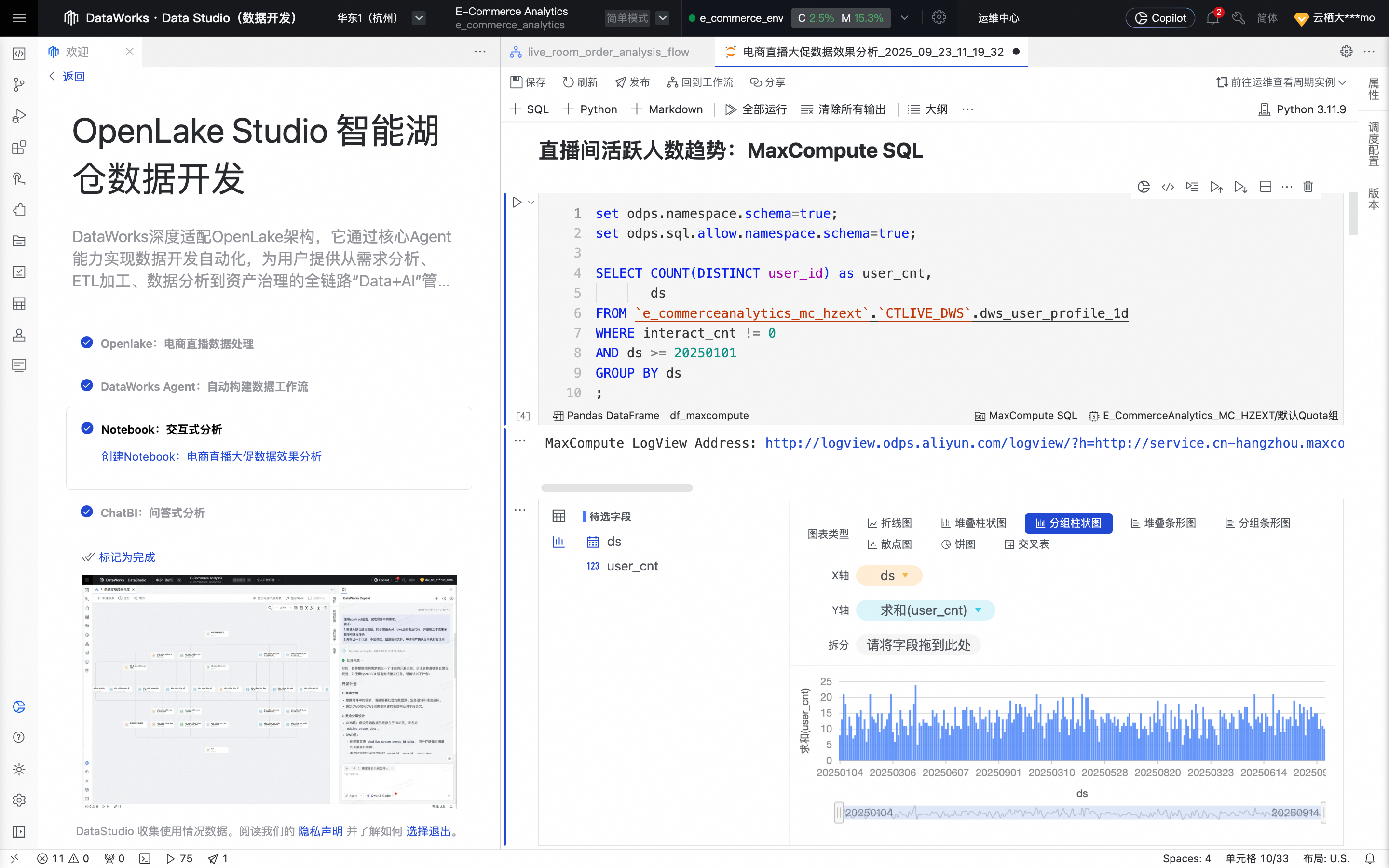
在Notebook节点的编辑页面,浏览“电商直播大促作战室”部分,查看使用不同计算资源SQL进行核心数据指标。
在Notebook节点的编辑页面,浏览电商直播用户的兴趣标签预测部分,查看使用PySpark进行数据处理和机器学习模型训练。
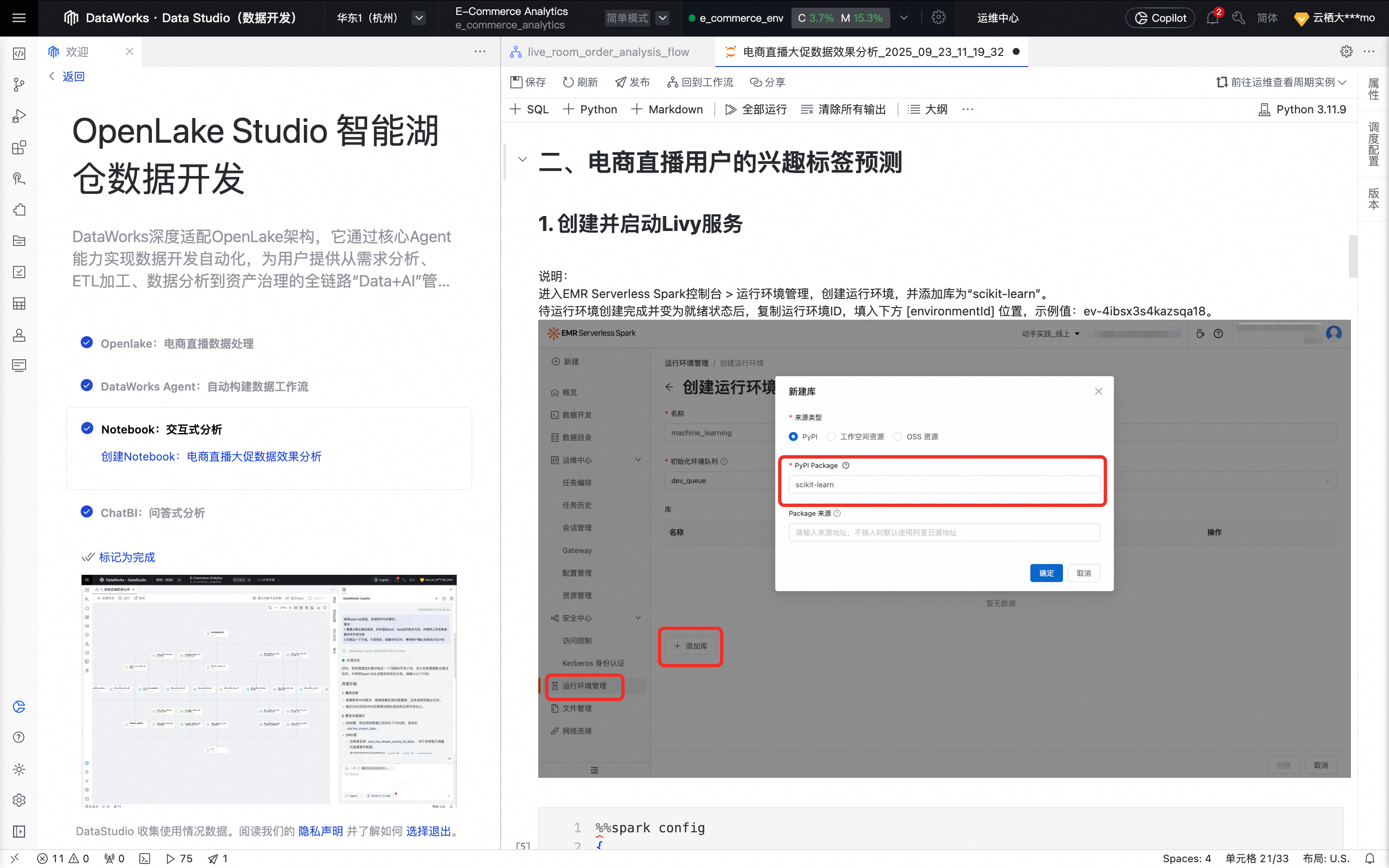
在
"spark.emr.serverless.environmentId": "[environmentId]"部分,使用示例值替换[environmentId]。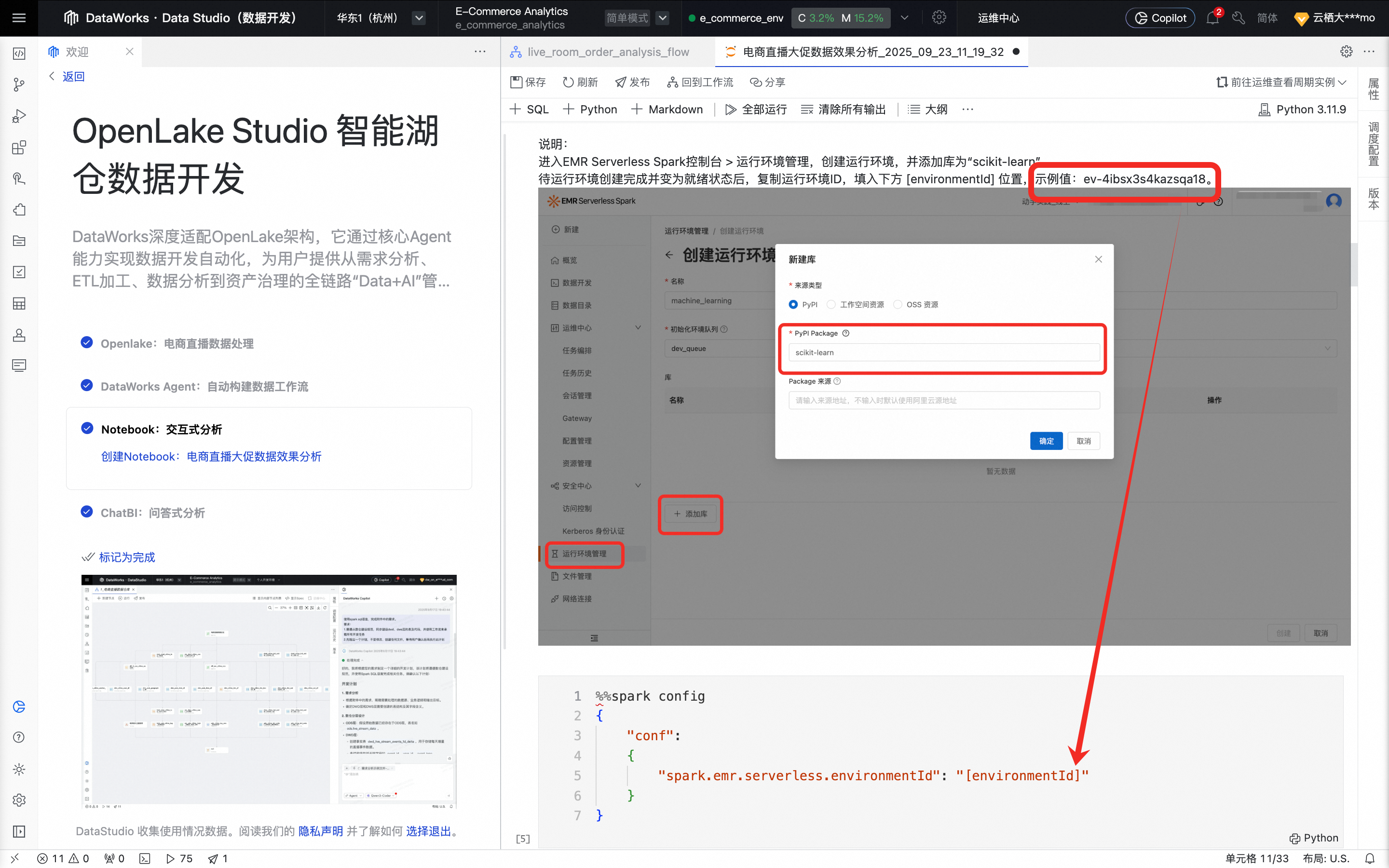
在数据开发的页面顶部,选择个人开发环境实例e_commerce_env。
在Notebook节点的编辑页面,单击全部运行,等待所有Cell顺次运行完成并查看输出结果。
ChatBI:问答式分析
回到演练页,单击Chat:问答式分析。
单击使用ChatBI进行“电商直播销售订单及用户行为分析”,此时跳转进入ChatBI页面并新建会话。
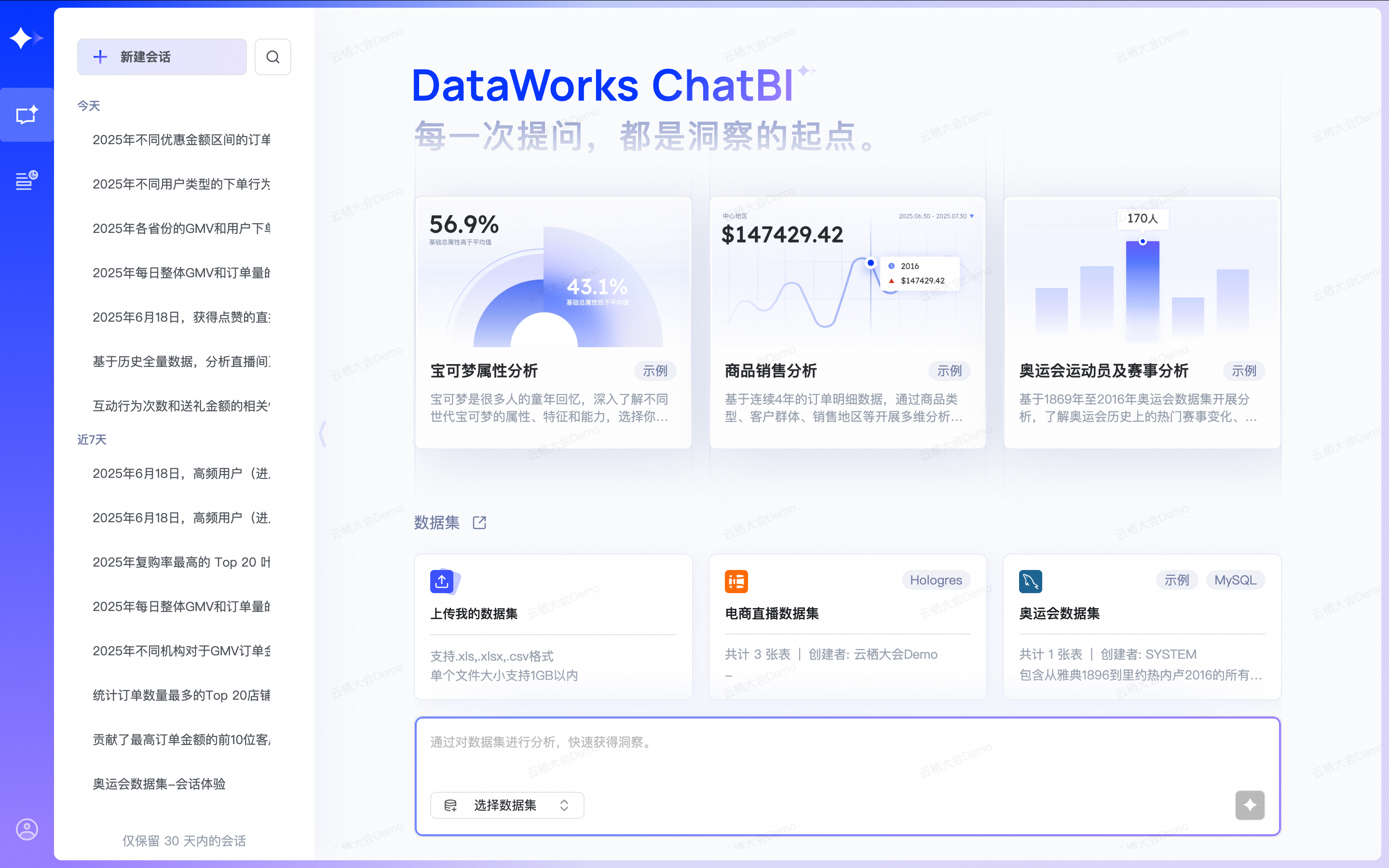
ChatBI将会基于“电商直播数据集”提供预设推荐问题列表:
2025年每日整体GMV和订单量的变化趋势
2025年Top 10 最高GMV主播的平均客单价(GMV / 支付人数)、转化率(支付订单数 / 下单订单数)表现
2025年各省份的GMV和用户下单人数分布情况
2025年不同商家的主播数量与GMV的相关性
2025年不同优惠金额区间的下单用户数情况
2025年不同用户类型的下单行为和消费能力有何差异
2025年每日进入至少1个直播间的独立用户数(DAU)
2025年6月18日,获得点赞与未获得点赞的直播间数量对比情况