数据探索(Beta)
数据探索是一种在线的交互式查询服务,开通即用。它是完全托管的,并且具备了高性能、弹性、易用等特点,无需申请任何资源即可直接使用,且代码运行环境归属于用户。用户可以对入湖后的数据使用Spark SQL快速地进行数据探索,以便对湖内数据进行审核、质量检查、分类等。支持数据湖内多种存储格式,包括Delta、Hudi、CSV、Parquet、JSON、ORC等数据格式。
准备工作
运行查询
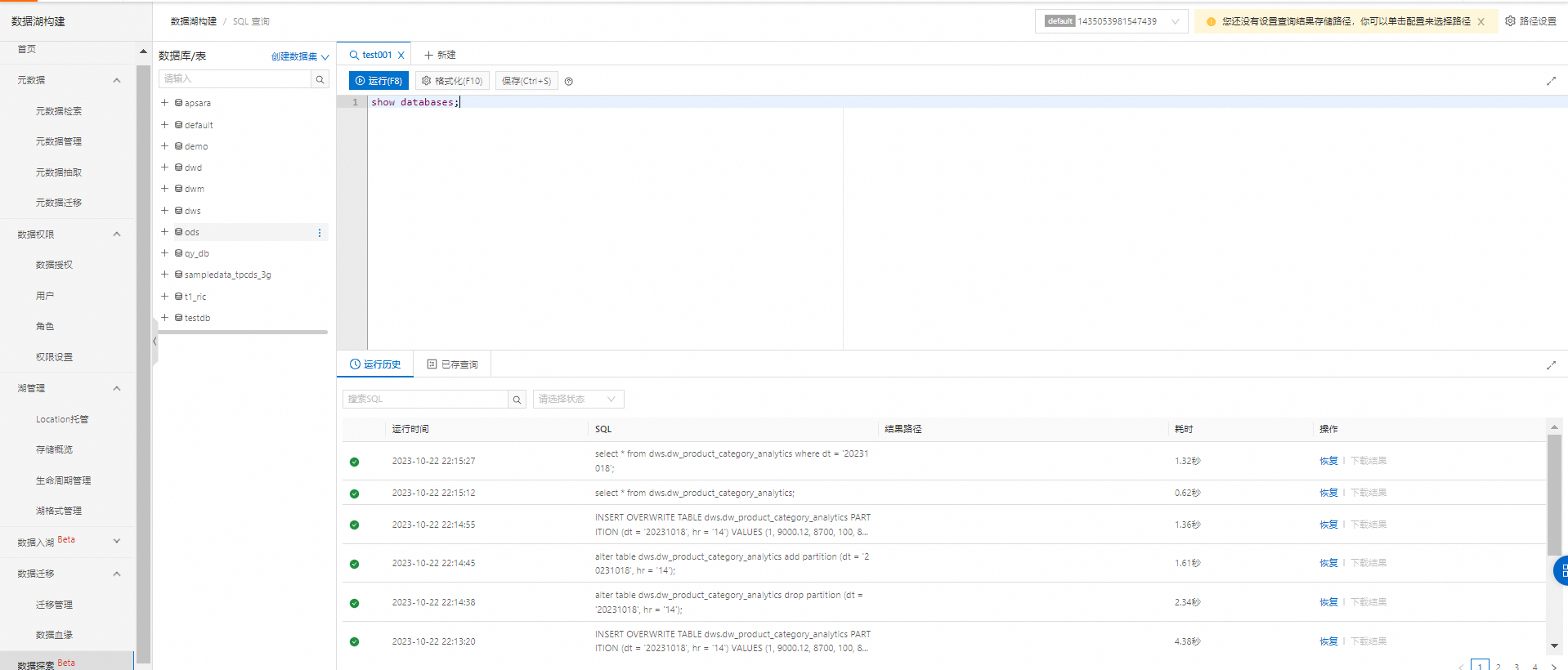
登录数据湖构建控制台,在左侧菜单中选择数据探索。
左侧数据库/表区域,会列举出当前账户下所有元数据库和元数据表。您可以在此区域查看元数据表的基础信息,或者生成数据预览SQL语句。
在右侧SQL编辑器区域,输入SQL语句。本功能基于EMR Spark 2.4版本,更多特性详情请参见Spark SQL Guide。示例如下:
-- SQL语句示例 show databases;单击运行(或快捷键F8),下方会展示查询进度状态,当查询完毕时会直接显示查询结果。查询结果会分页展示,受前端限制目前最多展示10000条数据。如需获取全部查询结果,可以在配置存储路径之后进入OSS查看,或直接点击下载。
重要DLF-Spark SQL不会在您的SQL语句后面自动加limit限制,请避免不必要的全表扫描,以免造成资源浪费。
 说明
说明使用限制:
SQL执行超时时间:60分钟。
SQL长度限制:不超过6000字符。
查询结果展示:最多10000行。
同一个账号,最大使用Spark Driver内存:4G。
同一个账号,最大使用CU限制:200CU (1CU=1核4GB)。
结果路径设置
您可以通过路径设置,把每次查询结果保存在OSS上,以便于全量结果的下载和归档。仅当设置了保存路径之后,才可以使用结果下载功能。保存的结果文件没有时间限制。
在左侧菜单中选择数据探索,单击右上方的路径设置。
在弹出的OSS输入框中,选择用于保存查询结果的OSS路径,单击确定。
设置成功之后,执行的查询结果会自动全量写入您设置的OSS路径中,目前默认以CSV格式保存。如果您的查询结果很大时,下载导出可能需要几分钟,请耐心等待。
保存查询
对于常用的查询,您可以直接保存。
在SQL编辑器中输入SQL语句,单击保存。
在弹出的输入框中,输入本次保存的查询名称。
保存成功后,您可以在下方的已存查询中,恢复保存过的查询。