
通过EMR+DLF数据湖方案,可以为企业提供数据湖内的统一的元数据管理,统一的权限管理,支持数据湖的多种管理如数据生命周期、湖格式自动优化、存储分析等。同时支持多源数据入湖以及一站式数据探索的能力。本文为您介绍EMR+DLF数据湖方案具体实践步骤。
背景信息
采用EMR+DLF数据湖解决方案,相对传统EMR数据湖方案有下列优点:
DLF提供数据湖跨引擎的统一的,全托管免运维的元数据服务。
支持可视化的元数据管理,以及多版本管理和回退。
支持可视化一键元数据迁移。
支持元数据全文检索。
支持元数据DataProfile,如文件大小、行数、访问频次、小文件数量、文件冷热度、有效文件数等。
支持除EMR开源引擎外的更多计算引擎,如MaxCompute、Flink、Hologres等多种引擎。
DLF提供丰富的细粒度数据权限控制。
支持按照数据目录、数据库、数据列、函数等资源的各种细粒度权限点的可视化配置。
支持与EMR中多种计算引擎集成,包括Spark、Hive、Presto、Impala多种计算引擎。
提供丰富的数据湖管理能力。
支持多种维度的数据生命周期管理,可以对数据按照冷热、更新时间等自动化归档,节省存储成本。
支持针对Delta数据湖格式的自动化存储优化策略,节省存储成本。
EMR+DLF数据湖解决方案整体架构
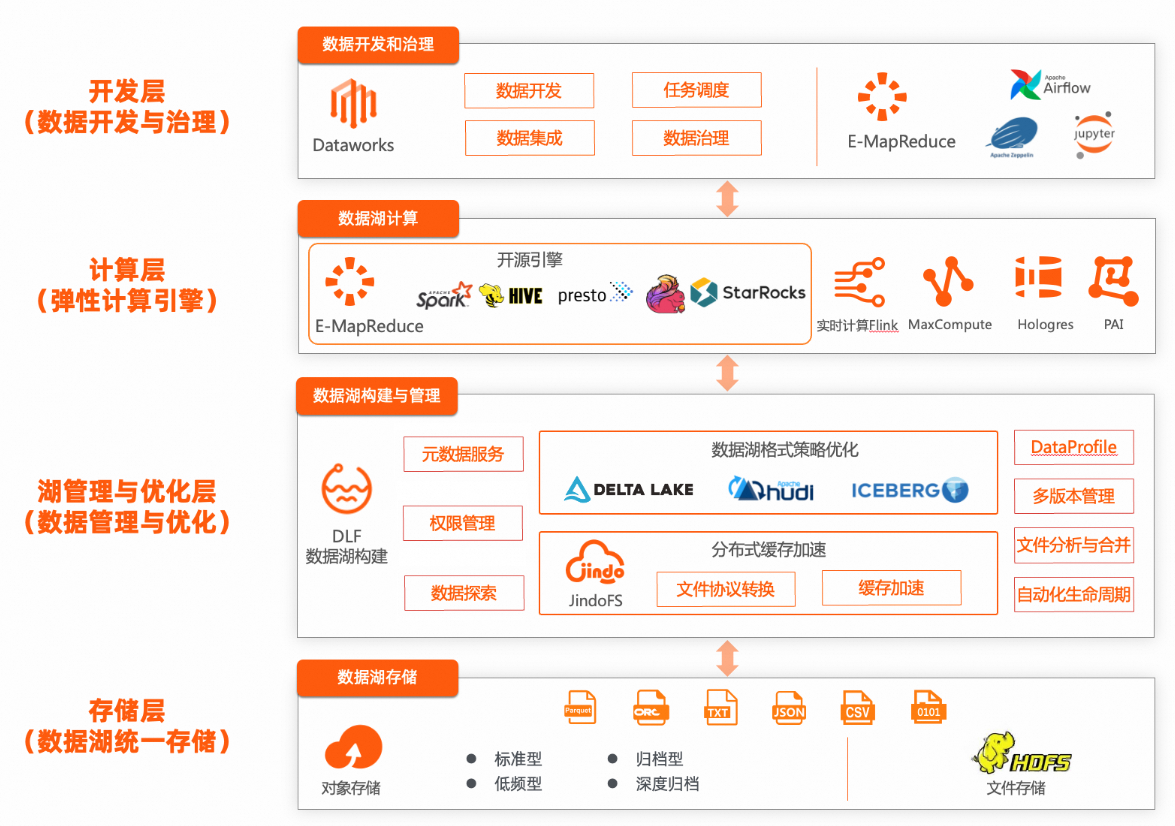
其他说明
目前DLF服务已开通的地域,请参见已开通的地域和访问域名。
关于DLF收费,请参见计费模式。
操作流程
步骤一:创建DLF统一元数据的EMR DataLake集群
创建EMR集群,并使用DLF作为元数据。
创建E-MapReduce集群,输入选项如下:
业务场景:选择数据湖。
可选服务:需要至少选中Hive组件,其他组件根据业务需要选择。
元数据:选择DLF 统一元数据。
DLF数据目录:选择默认的DLF Catalog,或者新建一个数据目录(Catalog)。如果您没有开通DLF,会提醒您先开通DLF产品。
继续其他配置完成EMR集群创建。详情请参见创建集群。
步骤二:初始化元数据
初始化元数据分为以下三种情况:
原有EMR集群(内置MySQL或自建RDS做元数据),需要将原集群的元数据迁移到DLF中。相关内容请参见EMR元数据迁移DLF最佳实践。
新建EMR集群,没有历史元数据。您可以通过DLF来可视化创建元数据,或者使用Hive、Spark SQL来创建数据库和数据表等。
登录数据湖构建控制台,选择与OSS相同的地域,例如华东1(杭州)。
在左侧导航栏,选择。
单击数据库页签,单击新建数据库。
在新建数据库页面,配置元数据库参数,单击确定。
新建EMR集群,已有数据存在OSS中,但没有元数据信息。可以使用元数据抽取来识别OSS上数据的元数据信息,并存储在DLF中。最佳实践,请参见DLF数据探索快速入门-淘宝用户行为分析。
步骤三:初始化数据
初始化数据一般常见的几种情况如下:
原有EMR集群,需要进行数据迁移。此时可以考虑通过JindoDistCp工具将原集群的数据迁移到OSS中。
从RDS、MySQL、Kafka等业务系统接入数据。此时可以考虑通过实时计算Flink实现数据入湖到DLF中。可参考如何在Flink中管理DLF Catalog。
步骤四:通过Spark/Presto引擎查询DLF表
通过SSH方式登录到EMR集群的Master-1-1节点,详情请参见登录集群。
通过spark-sql查询表。
执行以下命令,启动spark-sql。
spark-sql输入SQL,查询表数据。
SELECT * FROM <database>.<table>;
通过presto查询表。
执行以下命令,进入Presto命令行。
presto --server master-1-1:8889输入SQL,查询表数据。
SELECT * FROM <catalog>.<database>.<table>;命令中的参数说明如下:
参数名称
说明
<catalog>待连接的数据源的名称。
您可以通过
show catalogs;命令查看所有的Catalog;或者在EMR控制台Presto服务的配置页签,查看所有的Catalog。<database>待查询的数据库的名称。
<table>待查询的数据表。
例如,如果要查看Hive数据源中默认数据库中的
test表的数据,您可以使用SELECT * FROM hive.default.test;命令。
步骤五(可选):开启数据权限控制
有些业务场景对数据安全要求较高,需要对数据湖内的数据权限进行合理控制。此时您需要以下两步来完成数据权限的开启:
以上两个步骤完成后,您的整个EMR集群的数据访问将会受到数据权限控制,如果没有权限的用户访问集群数据,将会被拒绝。
此时可以参考DLF的数据授权,为相应用户配置合理的数据权限。相关内容请参见DLF+EMR之统一权限最佳实践。
步骤六(可选):生命周期管理
您可以通过生命周期管理对数据湖中的数据库、数据表配置数据管理规则,可以基于分区/表创建时间、分区/表最近修改时间、分区值三种规则类型,对数据定期进行OSS存储类型转换,从而节省数据存储成本。具体操作和说明请参考生命周期管理。