
如何在Serverless Spark访问Paimon虚拟文件系统(PVFS)。
使用限制
仅支持使用esr-3.5.0、esr-2.9.0、esr-4.6.0及以上版本。
创建DLF Catalog
详情请参见DLF 快速入门。
在Serverless Spark中绑定DLF Catalog
您可以新建Serverless Spark工作空间并绑定使用DLF Catalog,也可以在已有的Serverless Spark工作空间中绑定使用DLF Catalog。
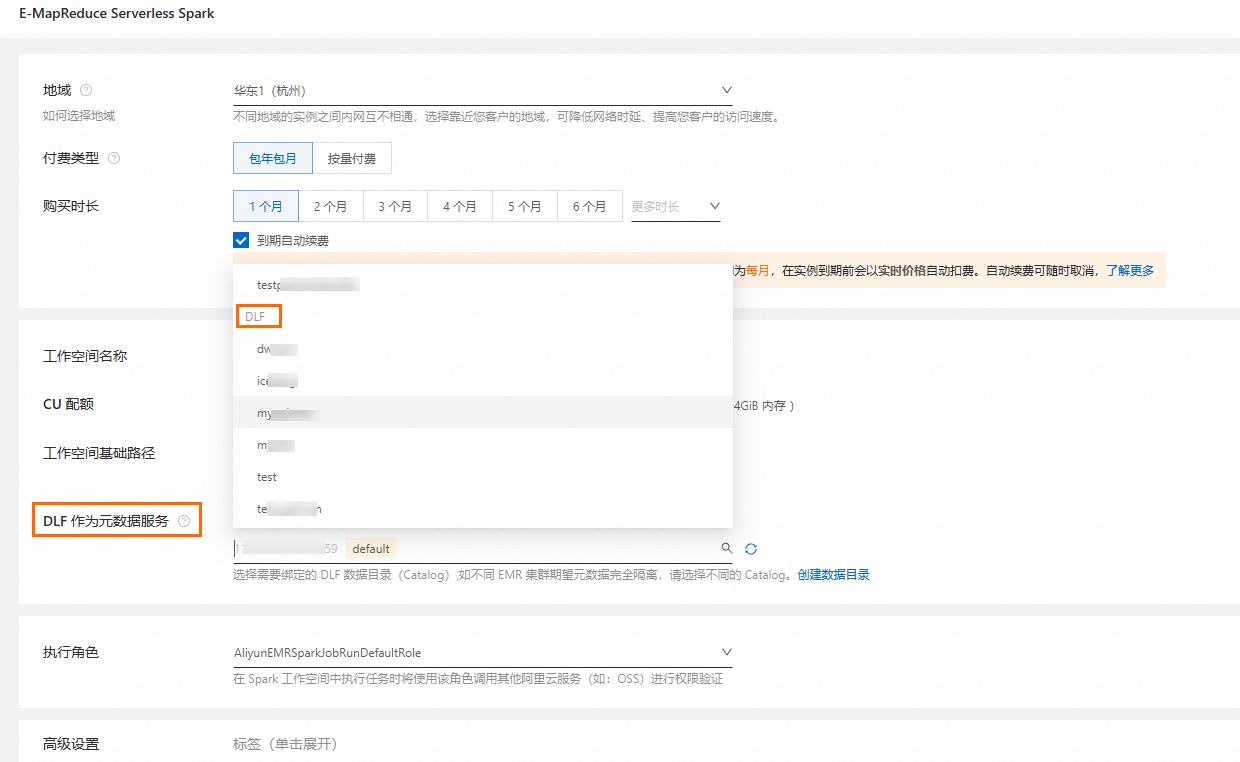
在新建Serverless Spark工作空间时绑定
创建Serverless Spark工作空间,详情请参见创建工作空间。
重要
创建时,开启DLF作为元数据服务,并选择上述步骤中创建的DLF Catalog。
在已有Serverless Spark工作空间中绑定
进入Serverless Spark工作空间数据目录页面,并添加上述步骤中创建的DLF Catalog,详情请参见管理数据目录。
说明
单个工作空间不支持同时添加多个版本的DLF数据目录,如果您当前工作空间已经添加了DLF-Legacy数据目录,使用DLF数据目录时可以重新创建工作空间,或先移除DLF-Legacy数据目录再重新添加DLF数据目录,移除前请确保当前工作空间内没有线上任务使用被移除的数据目录。
通过Serverless Spark访问DLF文件
登录 数据湖构建控制台 。
在绑定的DLF Catalog的default数据库下,创建一个名为
object_table的Object表。单击新建的表,进入表详情页,在上方选择文件列表页签。
单击上传文件:employee.csv。
返回EMR控制台,在左侧导航栏,选择,进入EMR Serverless Spark的工作空间。
在左侧导航栏选择数据开发,
在开发目录页签下,单击
 图标,在弹出的对话框中,输入名称,类型使用Notebook,然后单击确定。
图标,在弹出的对话框中,输入名称,类型使用Notebook,然后单击确定。运行下列代码,访问测试文件。
# 路径需要替换为步骤二中的对应的Catalog Name df = spark.read.option("delimiter", ",").option("header", True).csv("pvfs://catalog_name/default/object_table/employee.csv") # 显示DataFrame的前几行 df.show(5) # 执行一个简单的聚合操作:计算每个部门的总薪资 sum_salary_per_department = df.groupBy("department").agg({"salary": "sum"}).show()
该文章对您有帮助吗?