
SDK Release Note
PPU SDK v2.0.0 Release Note
1. 版本概述
PPU SDK 是平头哥独立自主开发的 AI 软件栈,拥有自主可控的软件知识产权,PPU 软件生态设计上由应用层、接口层和 SDK 层组成,具备统一的编程接口,支持平头哥自研软件生态。用户既可以基于 PPU APIs 开发应用, 也可以很方便地兼容基于 CUDA APIs 开发的应用程序。
本文重点介绍 PPU SDK 软件栈的主要功能和软件生态。
1.1 软件栈介绍
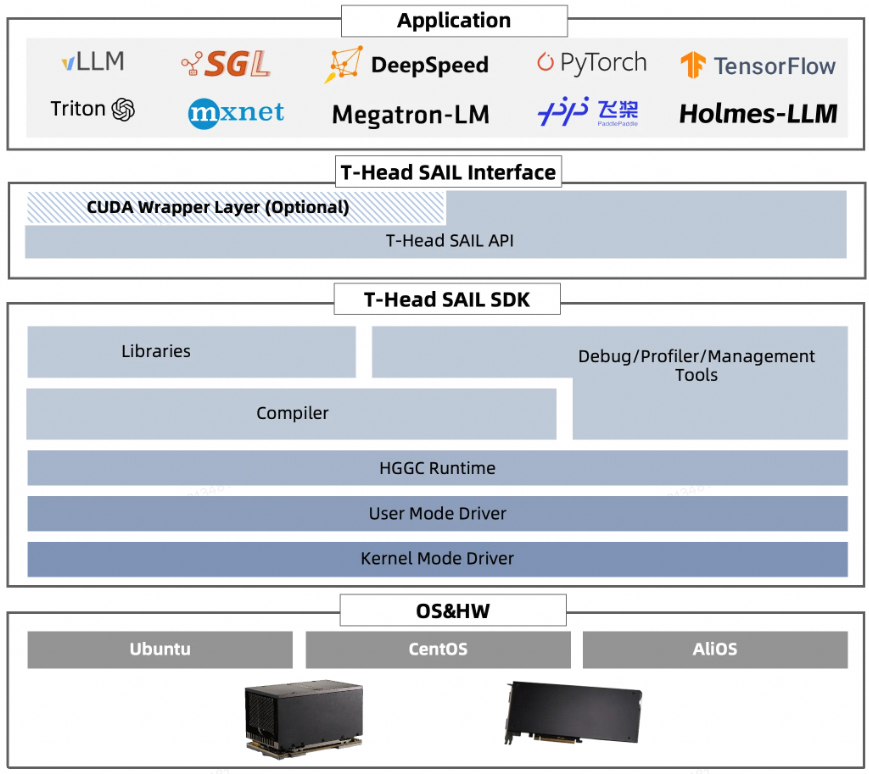
1.2 核心组件
组件名称 | 概要说明 |
Firmware | PPU 固件 |
KMD | PPU 内核驱动 |
UMD / HGGC | PPU 用户态驱动和运行时 |
Compiler | PPU 编译器工具链 |
Acompute | PPU 计算加速库 |
Acext | PPU 量化加速库 |
PCCL | PPU 通信加速库 |
PPU SMI | PPU 设备管理工具 |
PPU DCGM | PPU 在线监控工具 |
Asight System | PPU 性能分析工具 |
Asight Compute | PPU 性能分析工具 |
PPU GDB | PPU 调试工具 |
PPU MemCheck | PPU Sanitizer工具 |
PPU hgobjdump | PPU Device Binary工具 |
CUDA SDK Wrapper | CUDA API 兼容库 |
1.3 主要功能
1.3.1 Firmware
支持二进制包安装(rpm或deb)。
支持动态电源管理功能,缺省模式下PPU固件会根据实时的工作负载、温度和功耗等信息动态调节核心频率(200MHZ~最大工作频率)和工作电压。
支持PPU锁频功能,详情请参见设备管理工具PPU-SMI。
支持固件安全签名和固件双备份功能,确保固件内容的安全性和可靠性。
支持电源芯片固件升级功能。
支持BMC带外管理功能,包括设备状态监控和固件带外升级等。
1.3.2 内核驱动
支持二进制包安装(rpm或deb)和runfile包安装两种方式,用户可根据需要自由选择。
支持内核驱动和PPU SDK解耦,v1.0版本之后的内核驱动和PPU SDK可任意组合使用。
支持单机单卡、单机8卡/16卡(ICN互联)、多机多卡(ICN互联)和多机多卡(GDR)多种灵活的机器形态,使用GDR功能之前需确保系统已安装
alixpu-peermem内核模块(随PPU内核驱动一起发布)。支持PPU故障上报和故障处理。
支持
auto-reset功能,驱动在检测到kill overtime或cp invalid cmd错误之后会自动进行PPU设备复位,无需用户手动复位即可恢复正常。该功能默认打开,用户可通过ppu-smi查询状态或关闭该功能。支持MPS(Multi Pipe Service)功能。
支持MPS模式下小模型和大模型任务的潮汐场景使用。
支持nvml GPM指标采集功能,包括:sm利用率、sm occupancy、tensor core利用率、显存带宽利用率、pcie读写速率、icn link读写速率;
支持整卡直通虚拟化功能,用户可以在宿主机上解绑PPU驱动直通进虚拟机内使用,此时需要注意不同VM之间的ICN隔离。
支持MIG (Multi Instance GPU)多实例功能,PPU最多支持8个实例,需注意使用MIG功能时ICN互联功能不可使用。
支持 SRIOV 虚拟化功能,PPU最多支持8个VF (Virtual Function),需注意SRIOV和ICN互联同时开启时,只允许一个VF拥有ICN互联能力。
支持SRIOV虚拟化模式下宿主机驱动的热升级功能,即可以在虚拟机内业务运行的同时对宿主机PPU驱动进行更新。
支持16卡真武810E设备按照模组编号排序以获取更好的互联性能。
支持通过ppu-smi工具查询Xid关键错误信息功能。
支持ppu-smi显示容器内的pid而不是host的pid。
支持Linux系统Hibernate&Resume电源管理特性。
1.3.3 用户态驱动和运行时
兼容绝大多数cuda runtime api (cudaXXX) 和cuda driver api (cuXXX)。
新增发生xid 896错误时输出更多错误日志方便定位问题。
支持stream memory operation v2版本API。
支持graph management中edge data相关API。
支持graph management中batch memory op node相关API。
支持texture基本功能。
支持cuCtxCreate_v3 api。
支持在发生异常之后正确输出device code printf的内容。
支持HGGC_EXCLUSIVE_STREAMS环境变量指定stream group映射到不同的硬件队列。
支持cudaLaunchKernelExC接口。
支持通过asys工具采集stream对应的hardware channel信息。
支持AD扩展API接口。
支持cudaGetDriverEntryPointByVersion接口。
支持cudaLaunchAttributeLaunchCompletionEvent特性。
1.3.4 编译器
用户可以通过option来指定具体的编译产物,默认情况下编译产物为全系列支持的混合fatbin产物。
基于clang/llvm的编译框架,实现面向PPU架构的、host/device混合编程风格的C/C++扩展语言编译器,完整兼容cuda c/c++的编程语言规范;
提供丰富的编译功能模块,方便开发者通过API的调用方式,灵活构建编译流程,方便集成JIT编译的能力;
实现inline ptx指令的支持,其中包括部分支持的dense mma指令、sparse mma指令、texture相关指令; 同时针对ppu tensor core扩展了ptx指令的定义;
实现CUDA device API的支持,本次扩展
Compiler Optimization Hint Function : __builtin_assume_uniform();支持system level reserved shared memory特性;
gcc host compiler的版本支持范围在[5.5 - 14.2],clang host compiler的支持范围在[clang 9 - clang 18];
支持triton 2.3.x、3.0.x、3.1.x、3.2.x、3.3.x、3.4x;扩展triton.lang的语法,引入对AIU的支持;
Device ELF binary格式默认打开split section选项,减少运行时module load开销;
丰富的开发库和二进制工具:hgobjdump、memcheck、ppu-gdb、sanitizer library、hgprune、hgfatbin、hglink & hgJitlink,可以让用户更加方便地开发和调试
运行时JIT编译库hgrtc, 详细介绍请参考。最新更新:
支持对编译产物的caching能力,减少JIT编译过程时间。
支持Precompiled Header(PCH),减少JIT编译过程时间。
发布了PPU 调试工具PPU-GDB,允许在同一个应用程序中同时调试GPU和CPU代码。
发布了PPU Memcheck,是一组用于功能性正确检查的工具套件。该套件中包含了一系列的检查工具,包括memcheck、initcheck、synccheck、racecheck。
发布了PPU Binary 工具hgobjdump,用于提取binary中的device相关信息。
发布了PPU Prune 工具hgprune,用于提取binary中的device相关信息。
发布了PPU Fabin开发库hgfatbin,支持运行时对fabin文件的各类操作。
支持使用zstd作为fatbin默认压缩算法。
支持通过
--compress-mode调整压缩等级,默认启用快速压缩等级兼顾压缩效率和加载性能。
发布了PPU Link 工具hglink,用于对PPU device code的link操作。
发布了PPU JitLink开发库hgjitlink,支持运行时对PPU device code的link操作。
1.3.5 加速库
计算加速库
闭源计算库支持:acdnn、acblas、acfft、acsolver、acrand、acsparse
acdnn支持算子
Conv
BatchNorm
Pooling
Softmax
Activation
CTCLoss
Dropout
LRN
LSTM
GRU
MultiHeadAttn
Tensor Ops
SpartialTransform
Backend fusion
acblas支持算子
Level1 系列 Op
Gemv
Gemm
Matmul + epilogue
MatrixTransform
trsm
getrfBatched
getrsBatched
geqrfBatched
gelsBatched
geam
acfft支持:R2C/C2R/C2C/D2Z/Z2Z + FFT/iFFT 变换;
acsolver支持:矩阵LU分解/求解,cholesky分解/求解,QR分解,SVD分解,特征值分解;
acrand支持:
伪随机生成器XORWOW、MRG32K3A、PHILOX4_32_10;
数据分布:Default/Uniform/Normal/LogNormal;
acsparse支持:
支持大部分generic API及部分legacy API;
cusparse 13.0中表明为[DEPRECATED] 的API未支持;
acext量化库支持:
支持A16W8/A16W4以及PerChannel/GroupWise的各种Kernel变种;
支持A8W8以及PerChanel/PerToken的各种Kernel变种;
支持WeightonlyBatchedGemv对小batchsize的加速kernel;
支持以下类型 MoE:FP16/BF16,a8w8 PerChanel/PerToken;
开源项目支持:
PPU FlashMLA 1v5;
PPU FlashAttention 2.4.2/2.5.6/2.5.7/2.7.2/2.7.4.post1;
PPU cutlass2.5;
PPU cutlass3.3/3.4/3.6;
PPU Xformers 0.0.22/0.0.25/0.0.27/0.0.29.post1/0.0.30;
PPU FasterTransformer;
PPU 扩展库 acext;
目前主要支持高性能 a16w8、a16w4、a8w8 量化、group-gemm、MoE、batch gemv 等实现;
提供 PPU_SDK library 和开源仓库两种方式,供各框架和应用集成;
PPU DeepGemm:
支持 dense gemm、group gemm;
支持 FP16、A8W8 format,不支持 FP8;
支持 PerChanel/PerToken 量化,暂不支持 BlockWise 量化;
关键更新:
完成 DeepGemm 初步支持:EP 典型场景性能达竞对水平;
优化 DPSK/Qwen3 等场景 MoE 性能,相对trition版本平均提升50%以上;
blaslt:增强 desc 跨版本支持;完善通信计算并行方案支持;
conv:完善不同format组合的支持;增加对 strided channel 的支持;
solver:新增 gesvda 支持;
增强计算库对 Driver/Runtime 调用错误信息的处理;
优化 deconv 性能:部分场景性能提升40%;
优化 LSTM 性能,部分场景性能提升30%;
互联加速库
由于对外云产品使用的网卡为EIC,对客界面可使用的加速库为ACCL-P(替代PCCL)和ACCLEP-P(替代DeepEP)。
PCCL:
兼容支持绝大多数 nccl api (ncclXXX) 和环境变量;
支持 AllReduce、AllGather、ReduceScatter、Broadcast、Reduce、Send、Recv 等典型互联算子;
支持单机内多卡通过 ICN、PCIE、ShareMemory 通信;
支持多机之间通过 RDMA (GDR & non GDR) 、Socket、ICN 通信;
支持使用 VMM 的方式进行显存分配,优化显存用量并做到了整体与 legacy mode 用量近似;
完善 'CE collective' 功能支持与优化性能;
主要 API 对齐到了 nccl 2.27.1;
Debug 功能增强:
完成 pccl RAS 与 hang monitor 两种不同类型的 debug 功能整合 ,默认打开了 pccl RAS 功能;
pccl tools:
pccl perf:
支持 AllReduce、AllGather、ReduceScatter、AlltoAll、Broadcast 及 Reduce;
p2pBandwidthAndLatencyPerf 工具增强,具体可见:
支持真武810E 等产品在各种多卡互联 topo server 下的 icn p2p 互联带宽与延迟性能评估;
DeviceOrderSearch tool:
用于 Megatron 框架模型训练任务上基于并行训练配置得到真武810E 机器上的最佳 visible device order 设置;
pccl check tools:
支持 真武810E 等产品在多卡或多机多卡等场景下的功能 readiness 检查;
sailbandwidth:
完成首个版本支持, 关键 P2P 性能可达到预期水平;
sailSHMEM:
兼容支持所有 nvshmem pt2pt 相关 api;
支持单机内与多机节点间的 PPU 卡 pt2pt 操作像 thread/warp/block 级别的 put/get bw、 latency 与 signal 及 wait 等同步操作;
支持 icn link p2p 传输与 rdma ibrc 与 ibgda 网络传输;
支持 nvshmem4py;
DeepEP:
兼容支持 DeepEP 绝大多数 python API 用法;
支持单机内与节点间的 dispatch 与 combine intranode、internode 与 internode low latency 三种类型 kernel 实现;
支持通过 icn link 及节点间的 rdma ibgda 或 ibrc 等传输方式进行通信;
支持 low latency kernel 传输的 int8 groupwise 与 channelwise 量化实现;
优化了部分 kernels 的性能;
1.3.6 Video/Image codec硬件加速
兼容 Nvidia Video Codec SDK,包括cuvid decode, nvenc(up to v13.0)和nvjpeg(up to v13.0);兼容NPP(up to v13.0)接口。基于此,可以直接支持ffmpeg(up to v8.0), OpenCV4,DALI(up to v1.50),PyNvVideoCodec, PyAV,TorchCodec 等上层框架的Codec硬件加速能力。
Video Decode:
Support Nvidia cuvid decoder。
Codecs:
HEVC (H.265) - ITU-T Rec. H.265 (04/2013), ISO/IEC 23008-2
Main Profile, Level 5.1, High Tier
Main10 Profile, Level 5.1, High Tier
Main Still Profile
VP9 - vp9-bitstream-specification-v0.6-20160331-draft
Profile 0, 8-bit
Profile 2, 10-bit
AVC (H.264) - ITU-T Rec. H.264 (03/2010) / ISO/IEC 14496-10
Main Profile, levels 1 - 5.2
High Profile, levels 1 - 5.2
High 10 Profile, levels 1 - 5.2
Baseline Profile, levels 1 - 5.2
AV1 Bitstream & Decoding Process Specification Version 1.0.0 with Errata 1
Main Profile, Level 5.1
AVS2
Resolution Up to 8192x8192
Video Encode:
Support nvenc
Codecs:
AVC(H.264):Spec Version 12:ISO/IEC 14496-10 / ITU-T Rec. H.264 (03/2010)
Baseline Profile, levels 1 – 5.2
Main Profile, levels 1 - 5.2
High Profile, levels 1 – 5.2
High 10 Profile, levels 1 - 5.2
HEVC(H265):ITU-T Rec. H.265 (04/2013), ISO/IEC 23008-2
Main Profile, Level 5.1, High Tier
Main10 profile, Level 5.1, High Tier
Main Still Profile
AV1 Bitstream Specification Version 1.0.0 with Errata 1
Main Profile, Level 5.1
Resolution up to 4K support
Support input RGB format (converted to YUV420 via inlinePP)
Support crop, scale, rotate with inlinePP
JPEG:
Support nvjpeg decoder & encoder
Resolution up to 32Kx32K
Support RGB format input and output with inlinePP
Support crop, scale, rotate with inlinePP
Image Process:
Support Nvidia 2D Image NPP
Performance:
FHD 160 streams
FHD 32 streams
UHD 960FPS
1.3.7 软件工具
PPU-SMI:
为了满足云计算大规模集群监控需求,我们发布了如下 PPU 管理和监控工具和库文件,以便集成到客户集群运维监控系统中。
PPU-SMI(PPU System Management Interface)是一个基于HGML(HanGuang Management Library)的命令行工具,用于辅助用户管理和查看PPU设备。
通过PPU-SMI命令行工具,用户可以:
修改设备配置 / 特性开关
查询指定设备运行参数和特性使能状态
收集运行数据 / 特定事件,导出至表格供后续分析
分析各个应用程序的设备资源使用情况
查询多个PPU设备的拓扑信息
详细介绍请参考:设备管理工具PPU-SMI
Asight Compute v2.0新功能主要包含:
Roofline Chart扩展支持多种计算指令类型以及多级缓存和内存层次结构
Metric Details支持显示metrics的throughput和suffix信息
Memory Chart中鼠标悬停在箭头上时会高亮显示,对应的利用率图例标记也会同步高亮
Source Page支持heatmap,帮助快速发现热点代码行
PPU DCGM:
PPU DCGM是一套用于在集群和数据中心环境中管理和监控PPU的工具,基于开源的DCGM。包括如下组件:
dcgmi命令行工具
nv-hostengine命令行工具
dcgm共享库
dcgm-exporter工具
详细介绍请参考:管理监控工具DCGM
DCGM v2.0新功能主要包括:
更新DCGM 4.2.3版本Field Id支持状态
更新dmon和group usage information
更新query usage information
更新config usage information
Asight Systems:
发布了 PPU 性能分析工具 Asight Systems 和 Asight Compue(类似 Nvidia Nsight Systems/ Compute),可以支持用户进行单机、多机训练、推理等场景的性能分析;
Asight Systems 是一款低开销的系统级的性能分析工具,用来采集系统各种事件,CPU 和 PPU 的活动,API 执行时间以及相关调用栈,NVTX,CPU/PPU activity关联关系等,在 Timeline View 上统一的可视化呈现。 通过 Timeline View,开发人员可以方便地分析 CPU/PPU 的负载和关联关系,找到性能瓶颈,确保 CPU 和 PPU 能够协调的工作,确保最大的并行度。Asight支持统计系统方便对报告进行后处理。详细介绍请参考程序性能分析套件Asight Systems。
Asight Systems v2.0新功能主要包含:
asys支持在CUDA GPU平台采集跟踪,支持投影CUDA graph创建阶段NVTX到graph执行阶段
asys支持采集HGTX payload跟踪,支持HGTX range关联C结构体数据
Timline View增强: 支持高亮显示返回非0的HGGC API时间线;鼠标悬停在采样点上时,采样点会放大显示,方便定位采样点位置
专家/统计系统支持搜索rule名称
Asight Compute:
Asight Compute是一款kernel性能分析工具,通过采集PPU硬件 perf counter,组合成为一系列性能指标,我们称为metrics。GUI通过各种维度,把这些metrics呈现出来,帮助用户深入分析和优化kernel。详细介绍请参考Kernel分析器Asight Compute。
Asight Compute v2.0新功能主要包含:
Roofline Chart扩展支持多种计算指令类型以及多级缓存和内存层次结构
Metric Details支持显示metrics的throughput和suffix信息
Memory Chart中鼠标悬停在箭头上时会高亮显示,对应的利用率图例标记也会同步高亮
Source Page支持heatmap,帮助快速发现热点代码行
1.4 支持的操作系统
类别 | 操作系统 | 架构 | GCC |
Ubuntu | Ubuntu 24.04 LTS | x86_64 | 13.3.0 |
Ubuntu 22.04 LTS | 11.4.0 | ||
Ubuntu 20.04 LTS | 9.5.0 | ||
Ubuntu 18.04 LTS | 7.5.0 |
1.5 SDK版本兼容性说明
1.5.1 KMD兼容性
V2.0 版本SDK向前兼容V1.6.x、V1.5.x 、V1.4.x版本的 KMD驱动。
v2.0 SDK推荐搭配 KMD 2.0.0使用,以获得最全的功能和最佳性能。
驱动版本详情请参见PPU 驱动 Release Note。
1.5.2 Firmware兼容性
真武810E需要使用 V1.2.1 以上的 Firmware 版本。
1.5.3 SDK兼容性
SDK V2.0编译器具备在编译过程中产生多代Device Binary的能力,device Fatbin的文件格式版本随之迭代,在兼容性方面存在一些变化。
SDK V2.0 同 SDK V1.7、V1.6、V1.5之间,保持在编程API接口的兼容性。但在Device二进制格式和库文件的兼容性方面:
后向兼容
在旧版本SDK(v1.7、v1.6、v1.5)上编译的产物能够在SDK v2.0的环境中正常执行;
前向兼容
在SDK v2.0上编译的产物不能在旧版本SDK(v1.7、v1.6、v1.5)的环境中正常执行;
SDK V2.0 同 SDK V1.4及之前的版本不兼容。
2. CUDA生态兼容
2.1 介绍
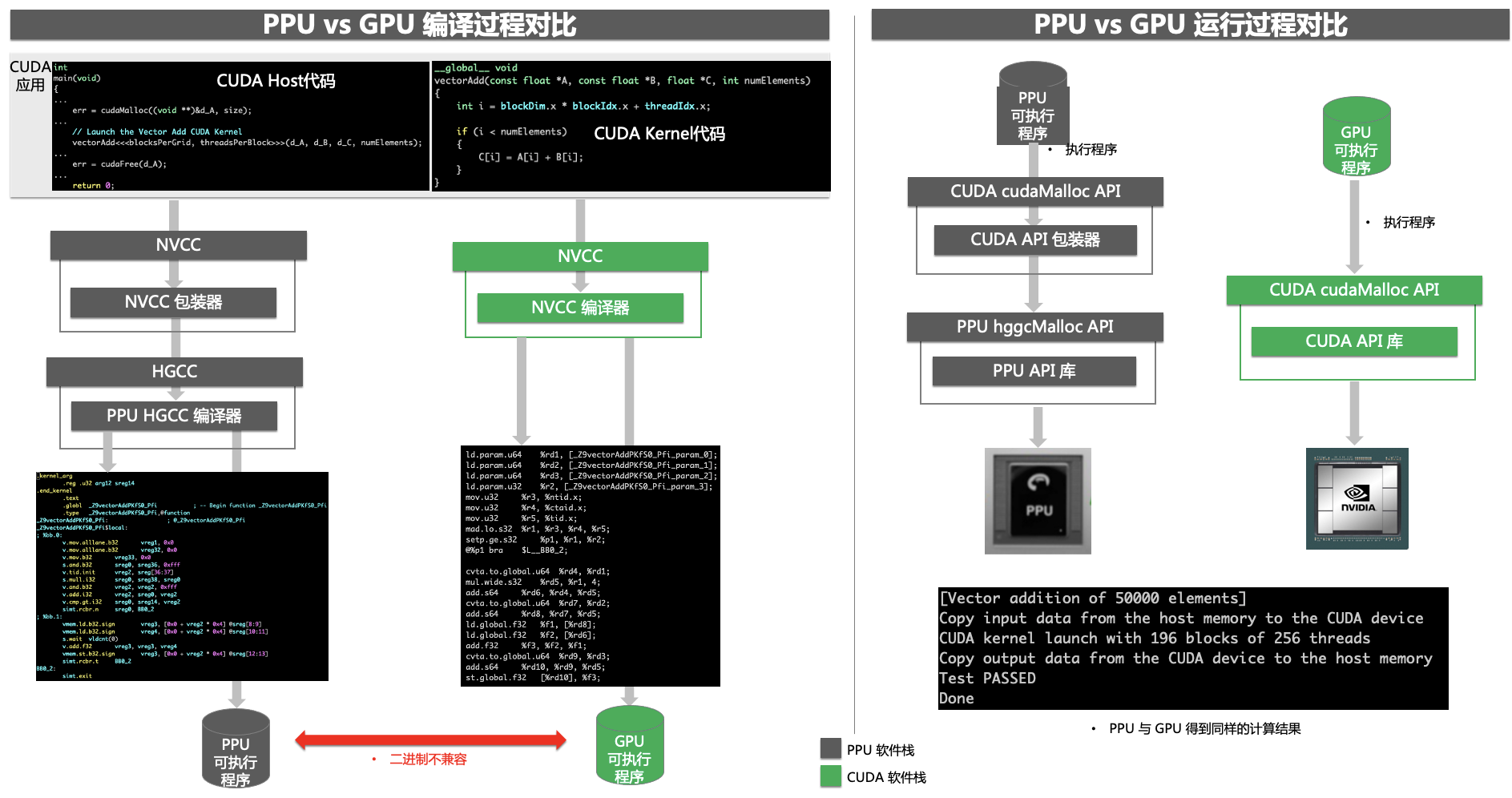
在PPU平台上开发应用程序,用户既可以基于PPU SDK API开发应用程序,也可以使用CUDA语言编写应用程序,经过PPU编译器重新编译后在PPU 上运行,下图展示了同样的CUDA应用程序分别在PPU和GPU上编译、运行的差异。
CUDA 生态兼容方法:通过代码自动生成技术生成CUDA SDK Wrapper来自动兼容CUDA不同版本的APIs,从而使得用户的CUDA程序经过PPU编译器重新编译后即可在PPU上运行。
通过CUDA生态系统的兼容方案,PPU与GPU在源代码级别上是编译兼容的,但PPU二进制与GPU二进制不兼容。
2.2 CUDA APIs兼容版本
截至PPU SDK V2.0版本,对CUDA APIs版本支持到12.9.0,但是限于硬件架构的区别,对CUDA APIs兼容主要在DeepLearning范畴,下表是目前支持的版本列表。更多CUDA兼容性内容请参见兼容性。
CUDA Version |
11.1 |
11.2 |
11.3 |
11.4 |
11.5 |
11.6 |
11.7 |
11.8 |
12.1 |
12.2 |
12.3 |
12.4 |
12.5 |
12.6 |
12.8 |
12.9 |
2.3 支持的开源框架/库
请参见:
3. 已知问题
3.1 驱动
不支持的CUDA API列表可参考CUDA APIs不支持列表(v2.0)。
3.2 编译器
不支持大部分的Texture 和 Surface 相关的 Cuda C++ 扩展 API和相关inline PTX,编译会报错;
不支持 Dynamic Parallelism 相关的 Cuda C++ 扩展 API、Inline PTX 指令的功能,编译会报错;
针对ptx 8.7之上的新增指令,会存在因硬件架构不支持的部分功能,不影响编译,但运行时会报错;
不支持 Inline PTX 中 128bit atomic 指令,不影响编译,但运行时会报错;
不支持 Inline PTX 中 multimem 指令,不影响编译,但运行时会报错;
不支持 Inline PTX 中 griddepcontrol 指令,忽略其定义但不影响编译和运行的过程;
不支持 Inline PTX 中 ld/st 相关指令带有 {.level::eviction_priority} 和 {.level::prefetch_size} 的特性,忽略其定义但不影响编译和运行的过程;
不支持 Inline PTX 中 cache eviction policy 相关的指令和操作数,忽略其定义但不影响编译和运行的过程;
Device 文件编译流程包括 Cuda Device C++ 代码 -> llvm(hgvm) IR -> Device Binary的过程, 但不包含输出 ptx 格式的文件过程; 针对其他平台的代码编译(或Codegen)环节,如带有 ptx 格式的编译环节,需要进行代码适配;
兼容CUDA mma及相关数据搬运的ptx指令中大部分,范围包括特定数据类型(.u8/.s8/.tf32/.bf16/.f16)下的dense/sparse mma指令,相比于使用ppu specific tensor core ptx指令实现,性能会存在损失。如果此类kernel的性能在整个端到端中占比重要,则建议对该kernel代码实现进行算法的重构(参考ppu tensor core ptx用户编程手册及算法重构指南);对不支持的数据类型和功能(如u4/f64/sp::ordered_metadata),不影响编译,但运行时会报错;
3.3 加速库
性能:性能泛化能力有待加强。
aublas:
仅支持列表API,详见CUBLAS APIs支持状态(v2.0),更多API持续按需支持中。
不支持复数数据类型。
Gemm: 默认打开FP32 Tensor Core,由于计算顺序等原因导致精度不能和FP32 FMA完全配置,matrixMulCUBLAS实例会因此失败;
Gemv:仅支持host指针模式;
BlasLt:不支持algo/perf等指定属性;
audnn:
仅支持列表API,详见CUDNN APIs支持状态(v2.0),更多API持续按需支持中。
Conv:不支持INT64/BOOLEAN数据类型,不支持输入FP16 + 输出FP32。
3DConv:有限调优,性能待加强;
depthwise:某些dgrad用例性能待加强;
BN:1)仅支持alpha==1和beta==0参数;2)不支持ACDNN_BATCHNORM_PER_ACTIVATION模式。
Pooling:不支持ACDNN_PROPAGATE_NAN。
RNN:仅支持acdnnRNNBiasMode_t DOUBLE;仅支持FP16/F32数据类型;仅支持ACDNN_RNN_ALGO_STANDARD;
Activation:不支持ACDNN_PROPAGATE_NAN;不支持SWISH Op。
Softmax:不支持SoftmaxAlgorithm_t FAST。
TensorOp:acdnnReduceTensor不支持MUL_NO_ZEROS。
MultiHeadAttn:仅支持前向op。
Backend:1)不支持前处理融合;2)仅支持最多4个pointwise后处理融合;3)仅支持fp16/fp32/bf16数据类型;4)融合的pointwise操作仅支持alpha1 = 1和alpha2 = 1。
ausolver:
仅支持列表API,详见CUSOLVER APIs支持状态(v2.0),更多API持续按需支持中。
不支持复数数据类型。
aufft:
仅支持列表API,详见CUFFT APIs支持状态(v2.0),更多API持续按需支持中。
不支持LTO优化;
aurand:
仅支持列表API,详见CURAND APIs支持状态(v2.0),更多API持续按需支持中。
仅支持类型:XORWOW/MRG32K3A/PHILOX4_32_10;
仅支持Legacy order;
仅支持分布类型:default、uniform、uniform double、normal、normal double、lognormal、lognormal double;
acsparse:
仅支持列表API,详见CUSPARSE APIs支持状态(v2.0),更多API持续按需支持中。
3.4 互联库
由于对外云产品使用的网卡为EIC,对客界面可使用的加速库为ACCL-P(替代PCCL)和ACCLEP-P(替代DeepEP)。
尚不支持的 nccl APIs 与环境变量列表可见:PCCL: NCCL APIs及环境变量支持情况(v2.0)。
Collective操作性能:16 x 真武810E服务器采用TP 2/4/8 mode时建议aware自己所用机器的icn topo配置情况以来选择最佳的devices placement;
暂不支持 nccl netplugin v7 及以上的版本;
执行收发 sizes 不均衡的 alltoallV 类型操作会有概率性死锁问题,dmesg 中能看到 "ERR_FAB_REQ_TO" 类型的 exceptions,此时需做 device reset 以恢复为正常状态;
多个 pccl communicators 同时工作在相同 ppu 下面时,会有概率性死锁的问题, 需尽量规避多个 pccl kernels 同时 launch 在同一 ppu device 下的行为; 避免设置 NCCL_MIN_NCHANNELS 为大于 16 的值可帮助规避此问题;
3.5 Video Codec/Image硬件加速
Video decode不支持MPEG1,MPEG2,MPEG4,VC1,VP8等legacy格式;
JPEG不支持lossless,不支持JPEG2000;
NPP目前只支持Image Process接口,不支持Signal Process接口;
3.6 工具
PPU-SMI已知问题,请参考PPU-SMI已知问题。
Asight Systems已知问题,请参考Asight Systems已知问题。
Asight Compute已知问题,请参考Asight Compute已知问题。
管理监控工具DCGM已知问题,请参考DCGM已知问题。
3.7. 框架与模型
开源框架已知问题说明:
框架 | 版本 | 已知问题 |
Pytorch | 2.9 |
|
2.8 |
| |
2.7 |
| |
2.6 |
| |
SGlang | 0.5.5 |
|
0.5.3 | SAIL SGLang v0.5.3 支持的标准量化能力:
目前主要针对 per-token/per-channel w8a8(int8)进行了优化,该方案需要使用 int8 量化模型。PTG 提供量化好的 int8 模型,可通过 Artifactory 下载:
注意事项:
| |
0.4.7 |
| |
VLLM | 0.11.x |
|
0.10.2 |
| |
0.9.1 |
| |
TransformerEngine | 2.8 |
|
Flashinfer | v0.4.0rc3 |
|
0.2.9.rc2 | 1.6.1 release中,Flashinfer的以下模块测试暂不支持
| |
Jax | 0.7.2 |
|