本文展示了AIACC-AGSpeed(简称AGSpeed)的部分性能数据,相比较通过PyTorch原生Eager模式训练模型后的性能数据,使用AGSpeed训练多个模型时,性能具有明显提升。
背景信息
本文通过测试不同场景下的模型,展示AGSpeed的不同性能提升效果。如果您想了解更多模型的性能测试效果,请联系我们。
性能数据
本示例数据以hf_GPT2、hf_Bert、resnet50,timm_efficientnet等50多个模型为例,通过FP32精度和AMP混合精度两种场景进行训练,不同场景下各模型训练后的性能数据如下所示:
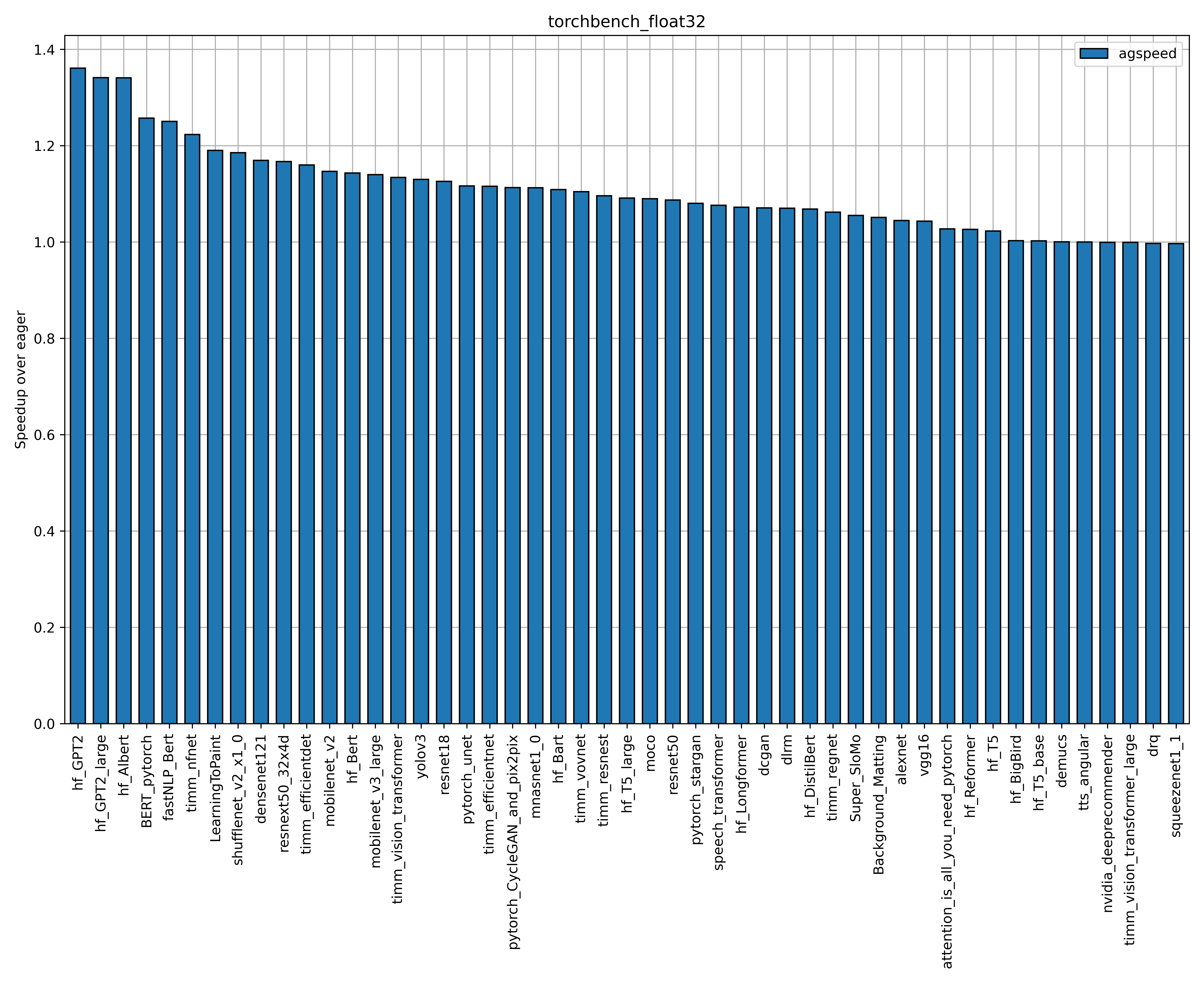
FP32精度训练场景
AMP混合精度场景
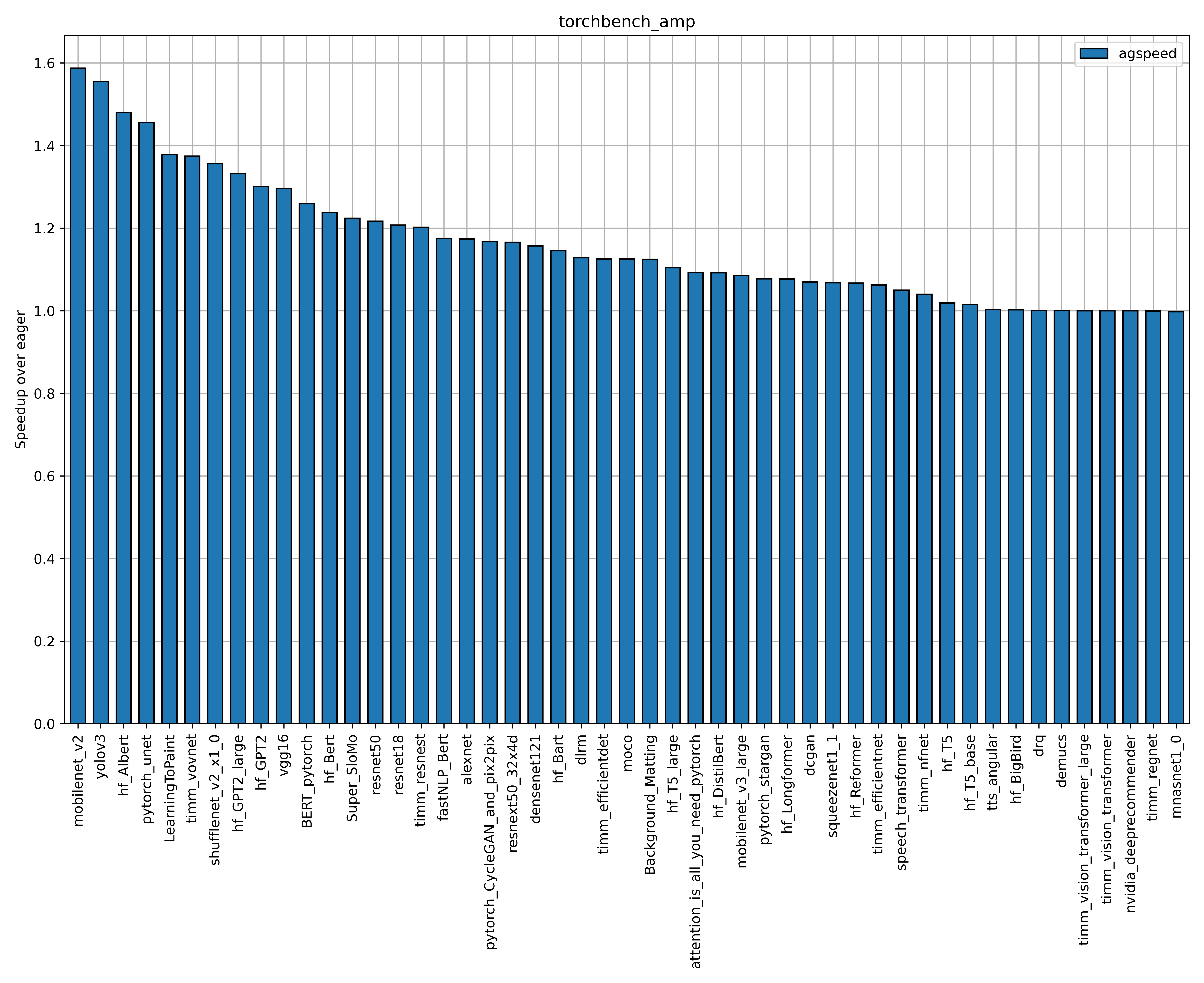
上述性能数据图中,横坐标和纵坐标的含义如下所示:
横坐标:代表所有参加训练的模型。
纵坐标:代表相比PyTorch原生Eager模式,模型使用AGSpeed训练后的加速比。加速比大于1.0表示性能提升有所提升。
性能效果
相比PyTorch原生的Eager模式,通过AGSpeed训练模型后,性能提升率如下所示。以吞吐量作为性能指标来展示AGSpeed的性能效果,性能提升率=(吞吐量(AGSpeed)-吞吐量(Eager))/吞吐量(Eager)。
下图中的数据仅展示部分典型模型,如果您想了解更多模型的性能提升效果,请联系我们。
模型 | 精度 | 吞吐量(Eager) | 吞吐量(AGSpeed) | 性能提升率 |
resnet50 v1.5 | TF32 | 8195 images/s | 9222 images/s | 提升12.5% |
AMP | 17160 images/s | 17592 images/s | 提升2.5% | |
SSD | TF32 | 2282 images/s | 2427 images/s | 提升9.9% |
AMP | 3312 images/s | 3679 images/s | 提升11.1% | |
BERT | TF32 | 2464 sequences/s | 2589 sequences/s | 提升5.1% |
AMP | 4689 sequences/s | 5031 sequences/s | 提升7.3% | |
nnUnet3D | TF32 | 89.21 images/s | 98.42 images/s | 提升6.8% |
AMP | 151.27 images/s | 161.52 images/s | 提升6.8% |