
阿里云GPU云服务器具有广阔的覆盖范围、超强的计算能力、出色的网络性能和灵活的购买方式,神行工具包(DeepGPU)是专门为GPU云服务器搭配的具有GPU计算服务增强能力的免费工具集。本文主要介绍GPU云服务器和神行工具包(DeepGPU)的优势。
GPU产品优势
-
覆盖范围广阔
阿里云GPU云服务器在全球多个地域实现规模部署,覆盖范围广,结合弹性供应、弹性伸缩等交付方式,能够很好地满足您业务的突发需求。
-
计算能力超强
阿里云GPU云服务器配备业界超强算力的GPU计算卡,结合高性能CPU平台,单实例可提供高达1000 TFLOPS的混合精度计算性能。
-
网络性能出色
阿里云GPU云服务器实例的VPC网络最大支持450万的PPS及32 Gbit/s的内网带宽。在此基础上,超级计算集群产品中,节点间额外提供高达50 Gbit/s的RDMA网络,满足节点间数据传输的低延时高带宽要求。
-
购买方式灵活
支持灵活的资源付费模式,包括包年包月、按量付费、抢占式实例、预留实例券、存储容量单位包。您可以按需要购买,避免资源浪费。
神行工具包(DeepGPU)优势
神行工具包中的组件主要包括Deepytorch、AI通信加速库DeepNCCL、推理引擎DeepGPU-LLM、集群极速部署工具FastGPU以及GPU容器共享技术cGPU,其各自具有以下核心优势。
Deepytorch
Deepytorch是阿里云自研的AI加速器,为生成式AI和大模型场景提供训练和推理加速功能,在训练和推理方面,具有更好的性能优势和易用性。该AI加速器包含Deepytorch Training和Deepytorch Inference两个软件包。
-
训练和推理性能显著提升
-
Deepytorch Training通过整合分布式通信和计算图编译的性能特点,可以实现端到端训练性能的显著提升,使得模型训练迭代速度更快,成本更低。
-
Deepytorch Inference通过编译加速的方式减少模型推理的延迟,从而提高模型的实时性和响应速度,能显著提升模型的推理加速性能。
-
-
易用性好
-
Deepytorch Training具有充分兼容开源生态等特点,兼容PyTorch主流版本,支持主流分布式训练框架。例如DeepSpeed、PyTorch FSDP或Megatron-LM等。
-
Deepytorch Inference无需您指定精度和输入尺寸,通过即时编译的方式,提供较好的易用性,代码侵入量较少,从而降低代码复杂度和维护成本。
-
AI通信加速库DeepNCCL
DeepNCCL是为阿里云神龙异构产品开发的一种用于多GPU互联的AI通信加速库,在AI分布式训练或多卡推理任务中用于提升通信效率。
-
通信优化效果显著
支持单机优化和多机优化,相比NCCL原生在性能上提升了20%以上。
-
无感加速
多GPU互联通信,无感地加速分布式训练或多卡推理等任务。
推理引擎DeepGPU-LLM
DeepGPU-LLM是阿里云研发的基于GPU云服务器的大语言模型(Large Language Model,LLM)的推理引擎,在处理大语言模型任务中,该推理引擎可以为您提供高性能的大模型推理服务。
-
高性能、低延迟
支持多GPU并行(Tensor Parallel)和多卡之间的通信优化,从而提高多GPU并行计算的效率和速度。
-
支持多种主流模型
支持千问Qwen系列、Llama系列、ChatGLM系列以及Baichuan系列等主流模型,满足不同场景下的模型推理。
集群极速部署工具FastGPU
使用FastGPU构建人工智能计算任务时,您无需关心IaaS层的计算、存储、网络等资源部署操作,简单适配即可一键部署,帮助您节省时间成本以及经济成本。
-
节省时间
-
一键部署集群。无需分别进行IaaS层计算、存储、网络等资源的部署操作,将部署集群的时间缩短到5分钟。
-
通过接口和命令行管理任务和资源,方便快捷。
-
-
节省成本
-
当数据集完成准备工作并触发训练或推理任务后,才会触发GPU实例资源的购买。当训练或推理任务结束后,将自动释放GPU实例资源。实现了资源生命周期与任务同步,帮助您节省成本。
-
支持创建抢占式实例。
-
-
易用性好
-
所有资源均为IaaS层,可访问、可调试。
-
满足可视化和log管理需求,保证任务可回溯。
-
GPU容器共享技术cGPU
GPU容器共享技术cGPU拥有节约成本和灵活分配资源的优势,从而实现您业务的安全隔离。
-
节约成本
随着显卡技术的不断发展和半导体制造工艺的进步,单张GPU卡的算力越来越强,同时价格也越来越高。但在很多的业务场景下,一个AI应用并不需要一整张的GPU卡。cGPU的出现让多个容器共享一张GPU卡,从而实现业务的安全隔离,提升GPU利用率,节约用户成本。
-
可灵活分配资源
cGPU实现了物理GPU的资源任意划分,您可以按照不同比例灵活配置。
-
支持按照显存和算力两个维度划分,您可以根据需要灵活分配。
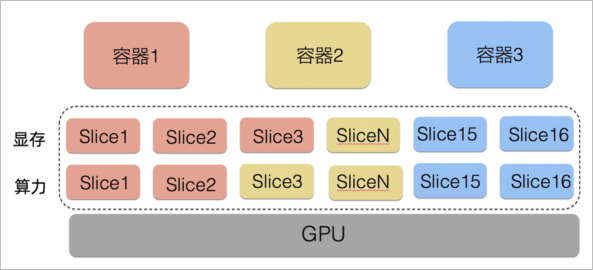
-
cGPU拥有灵活可配置的算力分配策略,支持三种调度策略的实时切换,满足了AI负载的峰谷能力的要求。
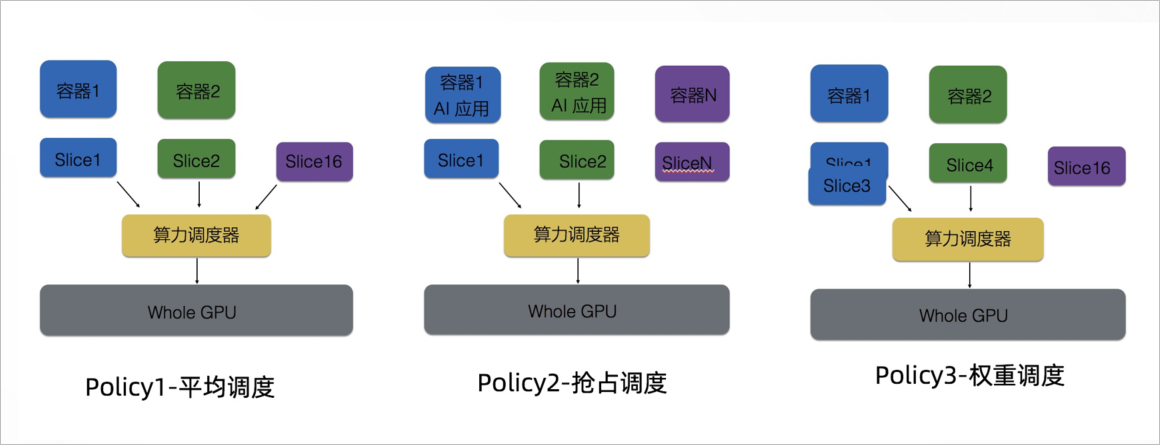
-