AIACC-ACSpeed(AIACC 2.0-AIACC Communication Speeding)是阿里云推出的AI分布式训练通信优化库AIACC-Training 2.0版本。相比较于分布式训练AIACC-Training 1.5版本,AIACC-ACSpeed基于模块化的解耦优化设计方案,实现了分布式训练在兼容性、适用性和性能加速等方面的升级。
AIACC-ACSpeed介绍
AIACC-ACSpeed(本文简称ACSpeed)作为阿里云自研的AI训练加速器,具有其显著的性能优势,在提高训练效率的同时能够降低使用成本,可以实现无感的分布式通信性能优化。
ACSpeed在AI框架层、集合算法层和网络层上分别实现了与开源主流分布式框架的充分兼容,并实现了软硬件结合的全面优化。ACSpeed的组件架构图如下所示: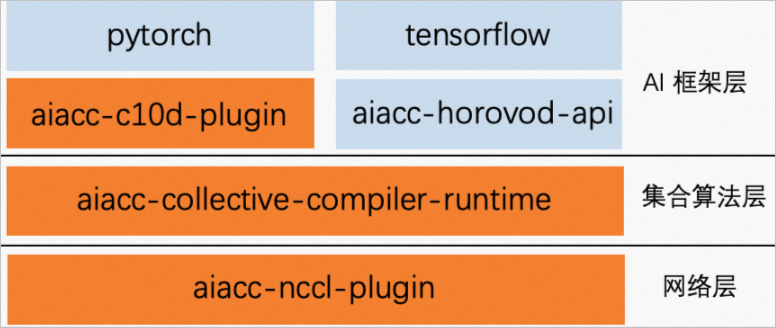
架构层 | 说明 |
AI框架层 | 在AI框架层,ACSpeed通过aiacc-c10d-plugin实现了PyTorch框架的充分兼容和无感分布式训练性能优化。 |
集合算法层 | 在集合算法层,ACSpeed通过集合通信编译技术,针对不同的机型构建自适应拓扑算法,实现NCCL Runtime充分兼容的无感集合通信拓扑优化。 |
网络层 | 在网络层,ACSpeed通过对阿里云的VPC、RDMA或者eRDMA网络基础设施进行适配优化,实现网络层无感的通信优化。 |
AIACC-ACSpeed使用说明
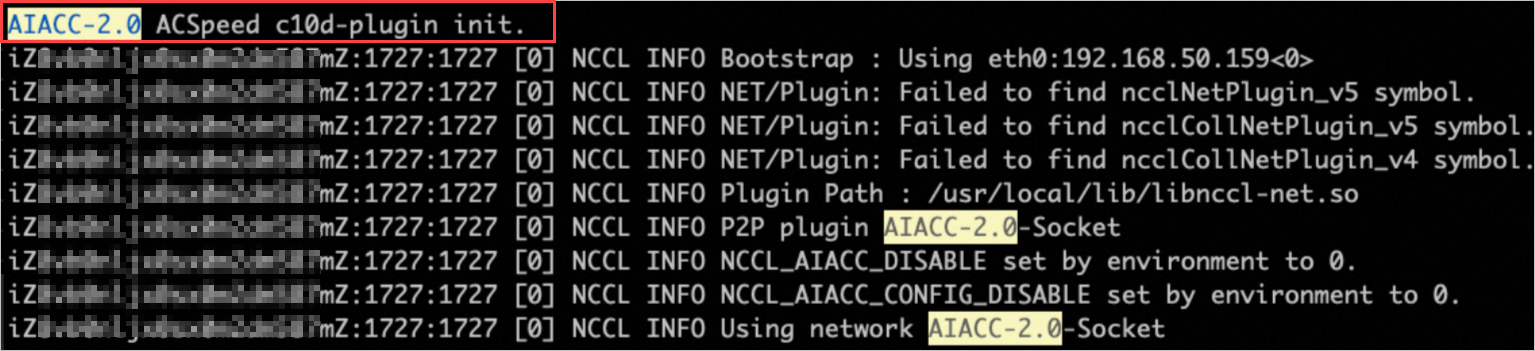
当使用ACSpeed启动训练出现AIACC-2.0 ACSpeed c10d-plugin init字段Log时,表示已成功初始化ACSpeed的aiacc-c10d-plugin组件。如下图所示:
NCCL组件的AIACC-2.0-Socket的字段需要开启NCCL_DEBUG=INFO才会显示AIACC-2.0字段。
ACSpeed在训练模式、启动方式、提升空间方面的说明如下所示:
功能 | 说明 |
训练模式 | ACSpeed的c10d组件仅针对PyTorch特定优化,需要您的训练模式选择原生DDP( |
启动方式 | 默认情况下,ACSpeed对启动方式没有要求,支持包括Torch的launch/run/spawn以及其他脚本等任意自定义启动方式。 在使用CPU-Affinity特性的时候存在限制,即目前仅支持torch 1.8~1.12版本的官方torch.distributed.run/launch的启动方式。 |
提升空间 | ACSpeed主要针对通信进行优化,通信瓶颈越大,性能提升越大。 如果机器本身是多卡或多机的加速比接近高线性度(即线性度接近于1),说明通信不是瓶颈,则ACSpeed的性能提升空间就会比较小。 |
使用ACSpeed训练时,您需要了解以下特性含义。
autotuner:ACSpeed默认开启autotuner功能,可以对通信算法进行自适应调优,大约在200~400个iteration(ACSpeed v1.1.0版本默认开启bucket-tuning大约会在950左右)时打印如下提示,表示关闭bucket-tuning时AIACC tuning结束后的显示信息。

ACSpeed v1.1.0版本默认开启bucket-tuning时最终autotuning结束后的显示信息如下所示:
 说明
说明因为训练过程中涉及到额外的context消耗,为了确保性能测试的准确性,建议模型训练的
warmup_iteration设置为400,具体参考上图中的Cost xxx steps。perf_mode:ACSpeed在autotune过程中会对每个iteration进行性能分析,支持不同的性能统计方式(默认为time),您可以通过环境变量来进行切换。取值范围:
AIACC_AUTOTUNE_PERF_MODE=time,为默认配置,适合带有端到端数据预处理、数据加载、梯度累计等额外操作的场景。AIACC_AUTOTUNE_PERF_MODE=filter,能够相对稳定地输出perf_time,适合带有checkpoint、logging等额外处理操作的场景。AIACC_AUTOTUNE_PERF_MODE=profile,相比前面两种方式,可以额外输出当前模型的一次iteration的通信占比。
单机优化:目前单机优化仅支持torch 1.6~1.9版本。
CPU-Affinity:默认为关闭状态,如果需要开启CPU-Affinity优化可以设置如下环境变量,在某些机型上提升空间较大。
AIACC_CPU_BINDING_ENABLE=1如果程序本身存在问题,例如负载不均衡导致性能波动,开启CPU-Affinity功能后可能会出现性能损失,所以该特性作为优化选项进行使用。
Bucket-Tuning:ACSpeed默认开启Bucket-Tuning,可以对梯度的融合进行自适应调优,提高计算和通信的overlapping性能的优化上限,但需要更长的warmup_steps(大约950 steps左右)。目前支持torch 1.8~1.13版本。
说明如果需要关闭Bucket-Tuning优化可以设置如下环境变量:
AIACC_BUCKET_TUNE_DISABLE=1Cache机制:为了减少Tuning的warmup时间,避免相同环境下同一模型的重复autotune,Cache机制以机型、模型名字、模型大小、集群规模为键值进行区分。
使用
AIACC_CONFIG_CACHE_DISABLE=0可以开启Cache,本轮训练的最优config将保存在rank=0机器上。说明后续在相同键值的训练场景下开启cache后,会自动读取cache并加载,从而跳过autotune步骤。
首次开启cache会显示如下信息:

cache保存后会显示如下信息:

第二次运行会显示如下信息:

在已保存最优config且具有相同键值的训练场景下,可以使用
AIACC_CONFIG_CACHE_UPDATE_DISABLE=0开启config更新,启动cache更新会显示如下信息。
AIACC-ACSpeed优化原理
场景说明
使用单机多卡或多机多卡进行AI分布式训练时,分布式通信的线性度可作为单卡训练扩展到多卡的性能指标,线性度的计算方式如下:
单机内部扩展性:线性度=多卡性能/单卡性能/单机卡数
多机之间扩展性:线性度=多机性能/单机性能/集群数
线性度的取值范围为0~1,数值越接近于1,其性能指标越好。当线性度不高(例如小于0.8)并且排除了数据IO和CPU的本身因素影响后,可以判断此时分布式通信存在瓶颈。在该场景下使用ACSpeed进行分布式训练,可以加速分布式训练的整体性能,并且原始基线的线性度越差,ACSpeed的提升空间越大。
单机内优化
以PCIe-topo和NVLink-topo机型为例,展示通过ACSpeed优化原理和优化性能效果。具体说明如下:
PCIe-topo机型
问题分析
以没有P2P互联的8卡机型的GPU拓扑结构为例,GPU0~GPU7的各卡连接如下图所示。由于卡与卡之间没有P2P互联,且多卡共用PCIe带宽,在涉及多卡通信的分布式训练中,特别是通信数据量较大的场景,容易出现因物理带宽限制而造成的通信占比过高的现象。
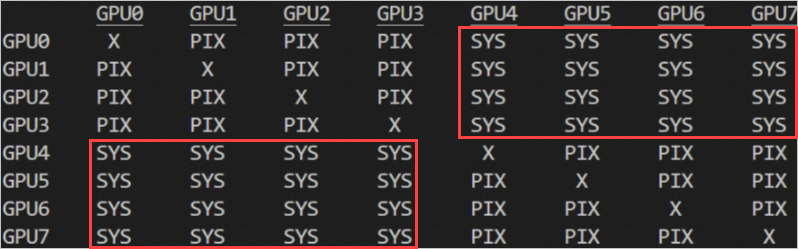
上图中,GPU0~GPU3或者GPU4~GPU7的各卡之间相互通过PCIe Bridge连接(PIX),而GPU0到GPU4~GPU7、GPU1到GPU4~GPU7、GPU2到GPU4~GPU7、GPU3到GPU4~GPU7之间需要通过socket之间的QPI/UPI接口连接(SYS)。
优化方法
在原生NCCL通信库中,默认使用
ncclAllReduce函数来进行集合通信。在PCIe-topo机型的带宽限制下,性能指标存在待提升的空间。ACSpeed通过降低集合通信过程的相对次数来达到性能提升的目的,实现CPU与GPU之间的异步流水线通信,从而提升通信性能,其主要特点是在CPU上完成数据的AllReduce操作,该优化也称为CPU-Reduce。优化效果
在PCIe-topo类型的单机下,遇到因通信占比较高而引起的低线性度加速时,可选择启用CPU-Reduce优化方法。该方法在4 MB及以上通信量上相对于原生NCCL具有20%左右的性能提升,进而将训练过程中的梯度同步时间整体降低,以获取端到端的性能提升。例如,在典型Resnet50和Transformer-based的模型训练场景中,通过该方法可实现10%以上的性能提升。
NVLink-topo机型
问题分析
以V100 8卡机型的GPU拓扑结构为例,不同的GPU之间连接的nvlink通道数是有区别的(例如NV1或NV2),如下图所示。NCCL经常使用的一种算法是binary-tree(即2-tree),在不同机型拓扑下并不能达到最优。
说明NCCL是NVIDIA GPU的集合通信库,能实现集合通信和点对点通信,基本上所有AI开源框架通信底层都是NCCL。

优化方法
基于上述问题,ACSpeed充分利用高带宽的nvilnk互联来实现AllReduce算法(例如GPU0与GPU3等),可以在单机通信出现瓶颈时,额外带来性能增益。针对上述V100实例的nvlink组合,ACSpeed实现一套n-trees算法,扩展单机内部不同tree的拓扑结构组合以及分布式多机多卡支持,从而实现拓扑调优。
优化效果
通过针对性设计的n-trees组合,能够充分利用多个nvlink通道的收发能力,在数据通信量128 MB以上具有20%性能提升。
多机间优化
通过ACSpeed优化,可以实现多机之间通信的性能提升,主要体现在高效的AllReduce算法和多流通信优化方面。
高效AllReduce算法
问题分析
以V100实例为例,单机内部利用nvlink做P2P通信,带宽高达300 GB/s,而多机网络性能在100 Gbps以下,吞吐性能较差,采用传统的ring-allreduce算法因跨机问题性能受限制,从而导致整体性能下降。
优化方法
相比较传统的ring-allreduce算法,ACSpeed设计的hybrid-allreduce算法实现了单机和多机的分层训练,充分利用单机内部高速带宽同时降低多机之间低速网络的通信量,并且针对阿里云不同机型的网卡和GPU距离的拓扑特点,实现多种不同算法组合(例如ps/tree/butterfly),充分发挥特定机型下的网络结构优势。
优化效果
在V100 16 G或者32 G实例的多机上,性能提升明显。例如典型的VGG16两机具有20%以上的性能提升。
多流通信优化
问题分析
通常情况下,单流通信无法打满TCP网络带宽(使用iperf工具可以快速验证这一现象),导致上层allreduce集合通信算法的跨机性能无法达到最优。
优化方法
ACSpeed设计实现了基于tcp/ip的多流功能,提升分布式训练中并发通信能力,充分利用网络带宽。
优化效果
使用多流通信优化,对整体多机的性能大幅提升5%到20%不等。
多机CPU-Reduce优化
问题分析
针对PCIe-topo机型,在机器内部通信带宽受限的场景下,相比较原生NCCL,单机内CPU-Reduce的优化效果较明显。因此,基于PCIe-topo机型搭建的多机训练环境下,您可以将单机CPU-Reduce扩展到多机,充分释放单机的性能,同时解决以Socket连接为主的跨机通信的扩展性问题。
优化方法
多机CPU-Reduce的实现继承了单机CPU-Reduce高效的异步流水线,将跨机通信过程也设计为流水线形态,同时避免存储在CPU侧的中间数据在CPU和GPU之间往返拷贝。为进一步提升跨机通信的性能,可使用闲置资源增加相应跨机流水线的个数。
优化效果
在通信量较大的VGG16或Transformer-based模型的PCIe-topo多机训练场景下,可将端到端性能进一步提升20%以上。
整体架构层优化
通过ACSpeed优化,可以实现整体架构层通信的性能提升,主要体现在通信算法autotuner、自适应cpu-affinity和全链路优化方面。
通信算法autotuner
问题分析
一次模型的训练在不同的实例、网络环境下具有不同的最优通信算法,采用先验的方式无法做到实时网络环境下的最优性能。
优化方法
针对上述通信算法实现autotuner,包括warmup、多维度perf_time统计以及top_k_algo的retuning等机制,从而实现在实时训练过程中,针对特定网络选择最优通信算法,保证端到端的性能最优。
优化效果
该算法在多机型的不同模型上,均能得到最优算法,并且99%的情况下没有性能损失的问题。
自适应cpu-affinity
问题分析
受到不同numa-node架构、不同Linux调度策略的影响,单机内部的多个进程可能会发生资源争抢,一方面导致额外调度的context等消耗,另一方面导致单机内部多个进程之间性能不一致的发生。而分布式训练大多是同步训练,会导致整体性能的下降。
优化方法
ACSpeed引入CPU亲和性机制,将训练进程与CPU核心进行绑定,控制进程与CPU核心的亲和性,消除NUMA效应和调度消耗。
优化效果
该方法对某单机8卡机型VGG16模型的性能提升3%。
全链路优化
问题分析
模型训练包括计算、通信、参数更新的完整过程,不同模型还会有不同的梯度(即通信量),会导致不同通信算法的性能差异。不同粒度的overlapping会导致整体性能表现的差异,计算和通信的耦合会导致全局非最优的情况发生,需要一个系统化的全方面优化。
优化方法
使用ACSpeed针对PyTorch框架的深度优化,覆盖forward、backward、overlap等操作的整体调优。例如,通过Bucket-Tuning可将端到端性能进一步提升2%~10%左右。
优化效果
不局限于纯通信的优化上限,实现性能的全面超越,并通过无感插件化的实现,您可以无缝使用,快速上手。
联系我们
如果您有分布式训练相关的问题或需求,欢迎使用钉钉搜索群号33617640加入阿里云神龙AI加速AIACC外部支持群。(钉钉通讯客户端下载地址)