
在GPU的实例上安装推理引擎TensorRT-LLM,可以帮助您快速且方便地构建大语言模型(例如Llama模型、ChatGLM模型、百川Baichuan模型或通义千问Qwen模型)的推理环境,主要应用在智能对话系统、文本分析等自然语言处理业务场景。本文为您介绍如何在GPU实例上安装和使用TensorRT-LLM来快速构建大语言模型的高性能推理优化功能。
TensorRT-LLM是NVIDIA推出的一个开源推理加速库,专门用于加速大语言模型推理性能。关于TensorRT-LLM支持的模型和GPU卡等信息,请参见TensorRT-LLM。
使用限制
仅支持在GPU计算型实例上安装TensorRT-LLM,更多信息,请参见GPU计算型实例规格族。本文以在gn6i实例上安装TensorRT-LLM为例。
阿里云的云市场镜像中仅Ubuntu 22.04 64位系统的镜像预装了TensorRT-LLM工具。
阿里云的公共镜像中仅Ubuntu 22.04 64位系统的镜像支持安装TensorRT-LLM工具。
安装TensorRT-LLM
部分云市场镜像中已预装了TensorRT-LLM工具,在创建GPU实例时,您可以一键获取预装TensorRT-LLM的镜像来自动安装TensorRT-LLM;也可以先购买GPU实例,然后手动安装TensorRT-LLM。
自动方式(选择云市场镜像)
获取云市场镜像并创建GPU实例。
云市场镜像中预装了TensorRT-LLM工具,您可以通过以下两个入口获取云市场镜像。
通过ECS购买页面获取
前往实例创建页。
选择自定义购买页签。
按需选择付费类型、地域、网络及可用区、实例规格、镜像等配置。
需要注意的参数项设置如下图所示,其他配置项参数的详细说明,请参见配置项说明。
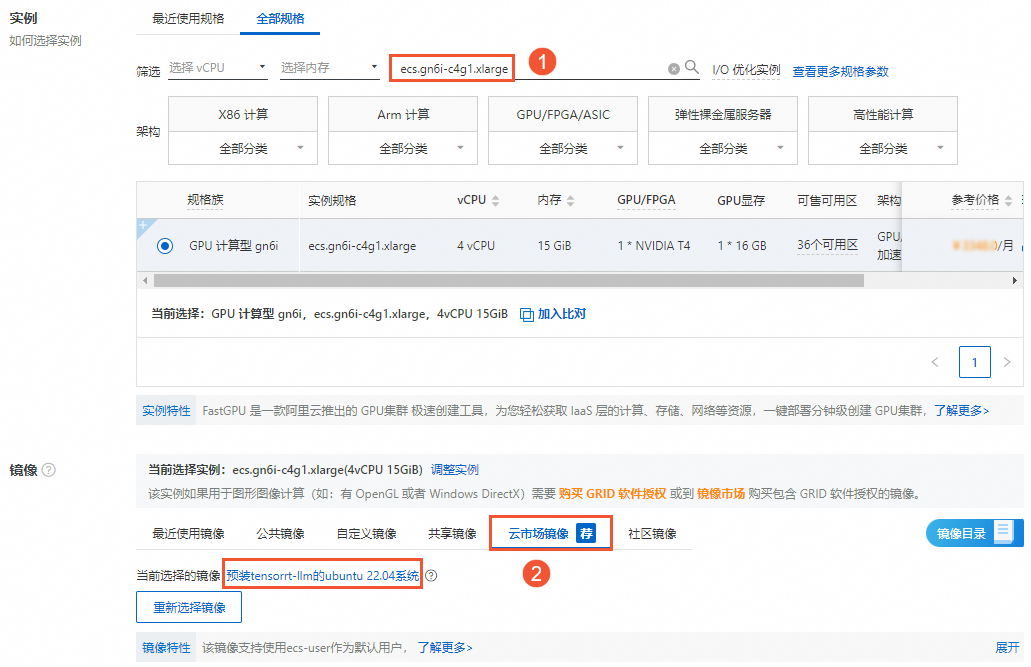
实例:以
ecs.gn6i-c4g1.xlarge实例规格为例。镜像:在云市场镜像中搜索
tensorrt-llm,然后选择所需镜像。在创建GPU计算型实例时,云市场镜像中提供了基于预装tensorrt-llm的ubuntu 22.04系统(VM版本)镜像供您选择,安装了TensorRT-LLM后即可立即使用TensorRT-LLM,您无需额外配置,具体镜像及版本信息如下。
支持的实例规格
预装大语言模型框架的镜像
最新版本
预装tensorrt-llm的ubuntu 22.04系统
V 0.10.0
按照页面提示操作,单击确认下单。
在支付页面查看实例的总费用,如无疑问,按照提示完成支付。
通过云市场获取
前往阿里云云市场页面。
在页面的搜索框输入
tensorrt-llm并按回车键。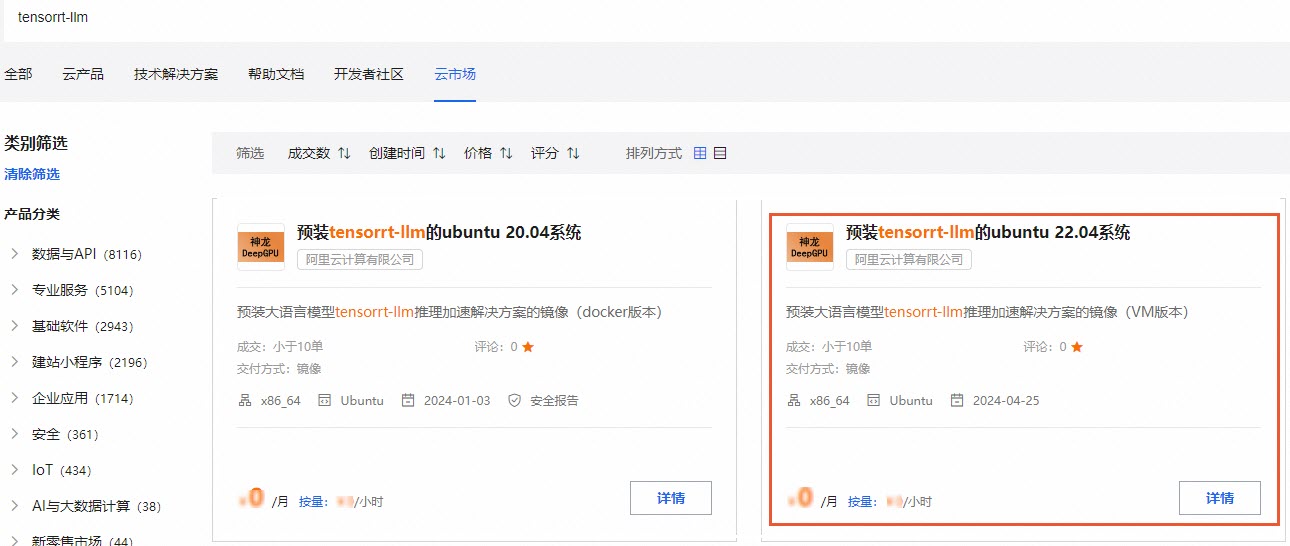
选择需要的镜像类型,单击详情。
云市场镜像中提供了基于预装tensorrt-llm的ubuntu 22.04系统(VM版本)镜像供您选择,安装了TensorRT-LLM后即可立即使用TensorRT-LLM,您无需额外配置,具体镜像及版本信息如下。
支持的实例规格
预装大语言模型框架的镜像
最新版本
预装tensorrt-llm的ubuntu 22.04系统
V 0.10.0
在镜像详情页,单击立即购买。
说明购买镜像时,系统镜像本身是免费的,您只需要支付GPU云服务器的费用。
在实例购买页的镜像区域,查看云市场镜像页签下是否已选中所购买镜像。
下图以购买的镜像被选中为例,如果镜像未被选中,则您需要继续单击重新选择镜像,选择所需镜像。
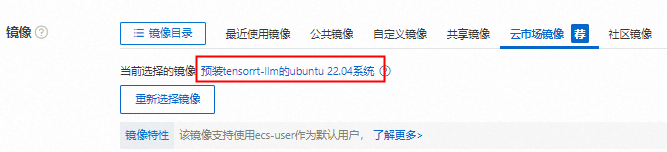
在实例购买页,配置其他参数并创建GPU实例。
更多信息,请参见配置项说明。
远程连接GPU实例。
具体操作,请参见使用Workbench登录Linux实例。
执行以下命令,检查TensorRT-LLM安装状态和版本信息。
python3 -c "import tensorrt_llm"如果TensorRT-LLM安装成功,则会返回TensorRT-LLM的版本信息。

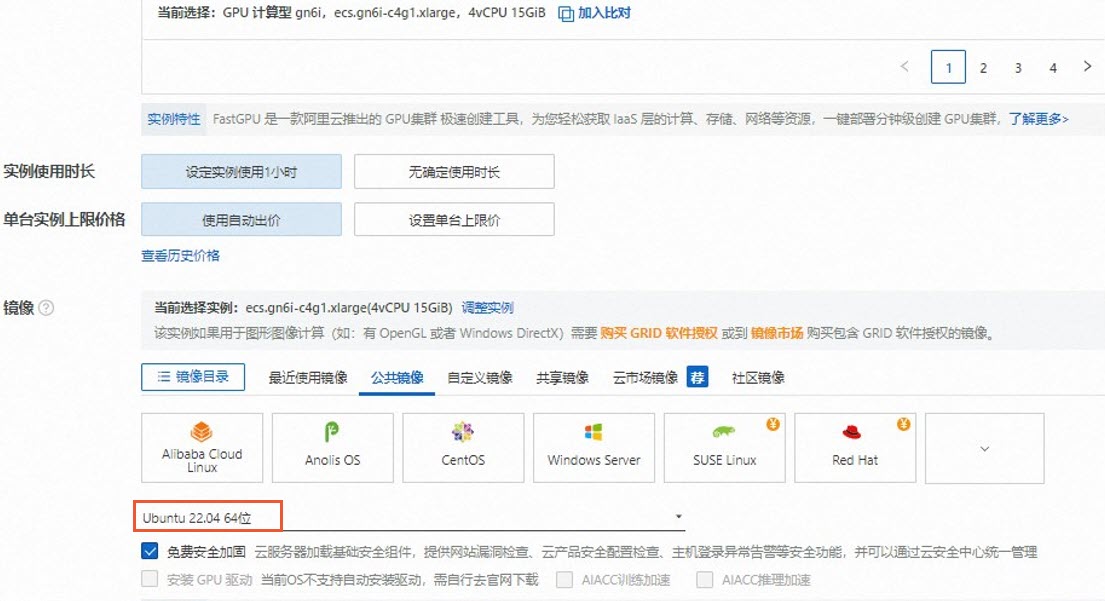
手动方式(选择公共镜像)
先创建GPU实例(镜像须选择公共镜像中的Ubuntu 22.04 64位系统镜像),然后在该GPU实例上安装TensorRT-LLM。
创建GPU实例。
远程连接GPU实例。
具体操作,请参见使用Workbench登录Linux实例。
依次执行以下命令,安装GPU实例的Tesla驱动和CUDA Tooklit。
wget https://developer.download.nvidia.com/compute/cuda/12.5.0/local_installers/cuda_12.5.0_555.42.02_linux.run sudo sh cuda_12.5.0_555.42.02_linux.run依次执行以下命令,配置环境变量。
export PATH=/usr/local/cuda-12.5/bin:$PATH export LD_LIBRARY_PATH=/usr/local/cuda-12.5/lib64:$LD_LIBRARY_PATH依次执行以下命令,查看GPU实例的驱动以及CUDA是否安装成功。
nvidia-smi nvcc -V依次执行以下命令,安装TensorRT-LLM以及相应依赖。
说明下载和安装过程需要较长时间,请您耐心等待。
sudo apt-get update sudo apt-get -y install python3.10 python3-pip openmpi-bin libopenmpi-dev sudo pip3 install tensorrt_llm -U --extra-index-url https://pypi.nvidia.com执行以下命令,检查TensorRT-LLM安装状态和版本信息。
python3 -c "import tensorrt_llm"如果TensorRT-LLM安装成功,则会返回TensorRT-LLM的版本信息。
使用TensorRT-LLM
TensorRT-LLM具有高性能推理优化能力,本文以使用TensorRT-LLM快速运行Qwen1.5-4B-Chat模型为例。
执行以下命令,下载TensorRT-LLM源代码。
本示例以TensorRT-LLM 0.10.0版本为例,您可以根据自己实际情况进行相应修改。
wget https://github.com/NVIDIA/TensorRT-LLM/archive/refs/tags/v0.10.0.tar.gz tar xvf v0.10.0.tar.gz执行以下命令,下载Qwen1.5-4B-Chat开源模型。
以ModelScope上的Qwen1.5-4B-Chat模型为例。
重要因为模型较大,请下载前确保网络连接稳定,网络带宽尽量保持最大。
git-lfs clone https://modelscope.cn/qwen/Qwen1.5-4B-Chat.git构建模型Engine。
执行以下命令,进入解压好的TensorRT-LLM源码目录。
cd TensorRT-LLM-0.10.0/examples/qwen执行以下命令,安装模型所需的依赖软件。
sudo pip install -r requirements.txt依次执行以下命令,配置模型参数并构建模型Engine。
python3 convert_checkpoint.py --model_dir /home/ecs-user/Qwen1.5-4B-Chat --output_dir /home/ecs-user/trt_checkpoint --dtype float16trtllm-build --checkpoint_dir /home/ecs-user/trt_checkpoint --output_dir /home/ecs-user/trt_engines/qwen1.5-4b-chat/1-gpu --gemm_plugin float16说明如果构建模型Engine失败,根据失败原因调整参数重新构建,也可以指定int8和int4量化等功能,更多信息,请参见模型目录下的
README.md。
执行以下命令,运行TensorRT-LLM进行模型推理。
以
你好,你是谁?作为文本输入参数为例,运行TensorRT-LLM进行模型的推理。python3 ../run.py --input_text "你好,你是谁?" --max_output_len=500 --tokenizer_dir /home/ecs-user/Qwen1.5-4B-Chat --engine_dir=/home/ecs-user/trt_engines/qwen1.5-4b-chat/1-gpu推理结果展示:
