
本文将为您介绍通过Hologres Dynamic Table的增量刷新和全量刷新两种模式,满足多种业务场景的数据分析需求,并通过Hologres对接BI分析工具(本文以DataV为例),实现海量数据的实时与离线分析,助力业务快速进行数据分析和数据探查。
背景信息
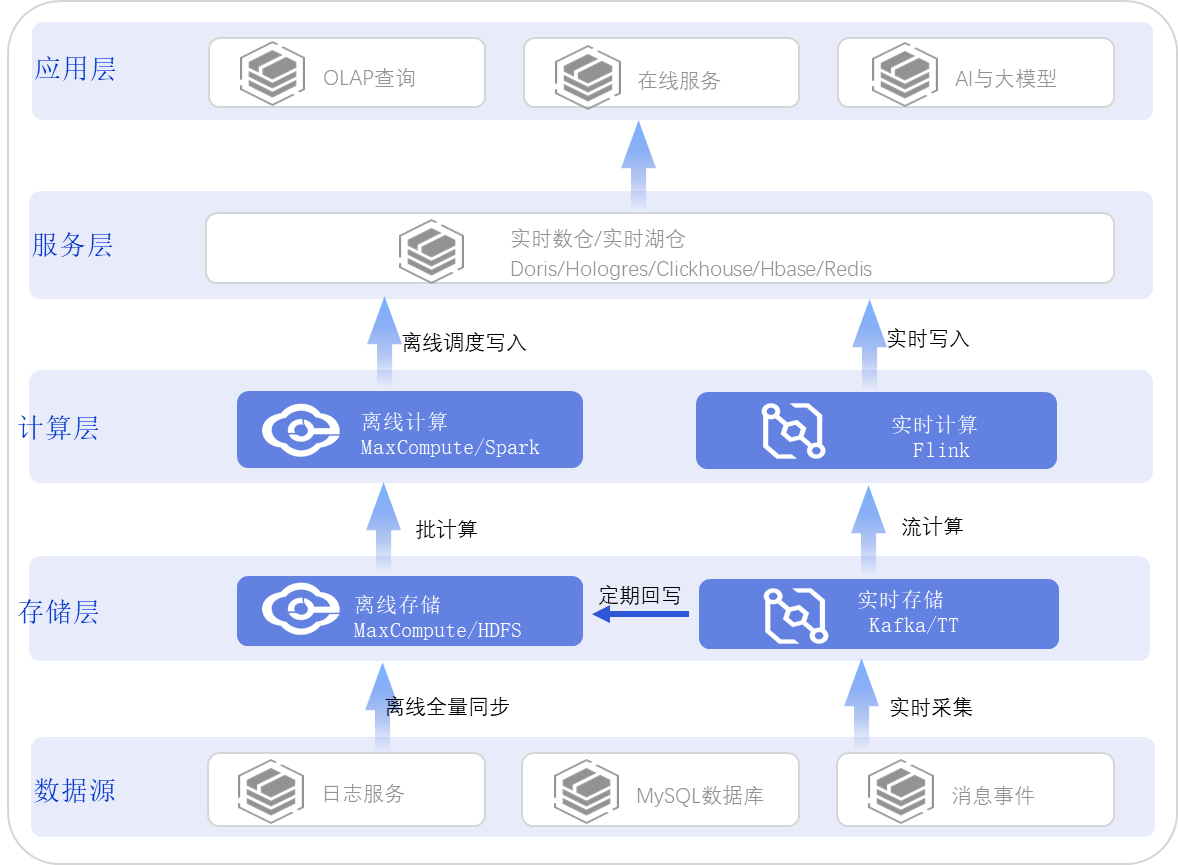
传统数仓架构
传统中要实现离线、近实时或实时的查询需求,需要引用多套系统来实现。传统数仓Lambda架构中存在一些问题,包括架构复杂、组件繁多、运维难度高及成本大。由于计算引擎的不一致性,数据加工标准难以统一,同时造成了数据冗余和同步难题,增加了资源消耗。此外,缺乏有效的数据仓库分层策略,导致查询延迟问题突出,操作不便,开发效率低下。
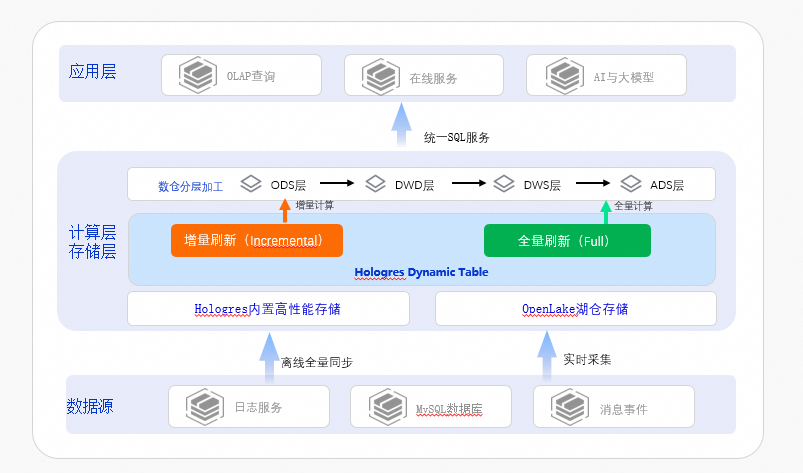
基于Hologres Dynamic Table的多模式统一计算架构
Hologres从3.0版本开始支持Dynamic Table,提供全量刷新和增量刷新两种刷新模式,支持数据自动刷新与流动刷新,通过多模式的统一计算,能有效地解决实时数仓分层、流批一体等强需求,同时也能实现性能、成本、时效性等的完美平衡。
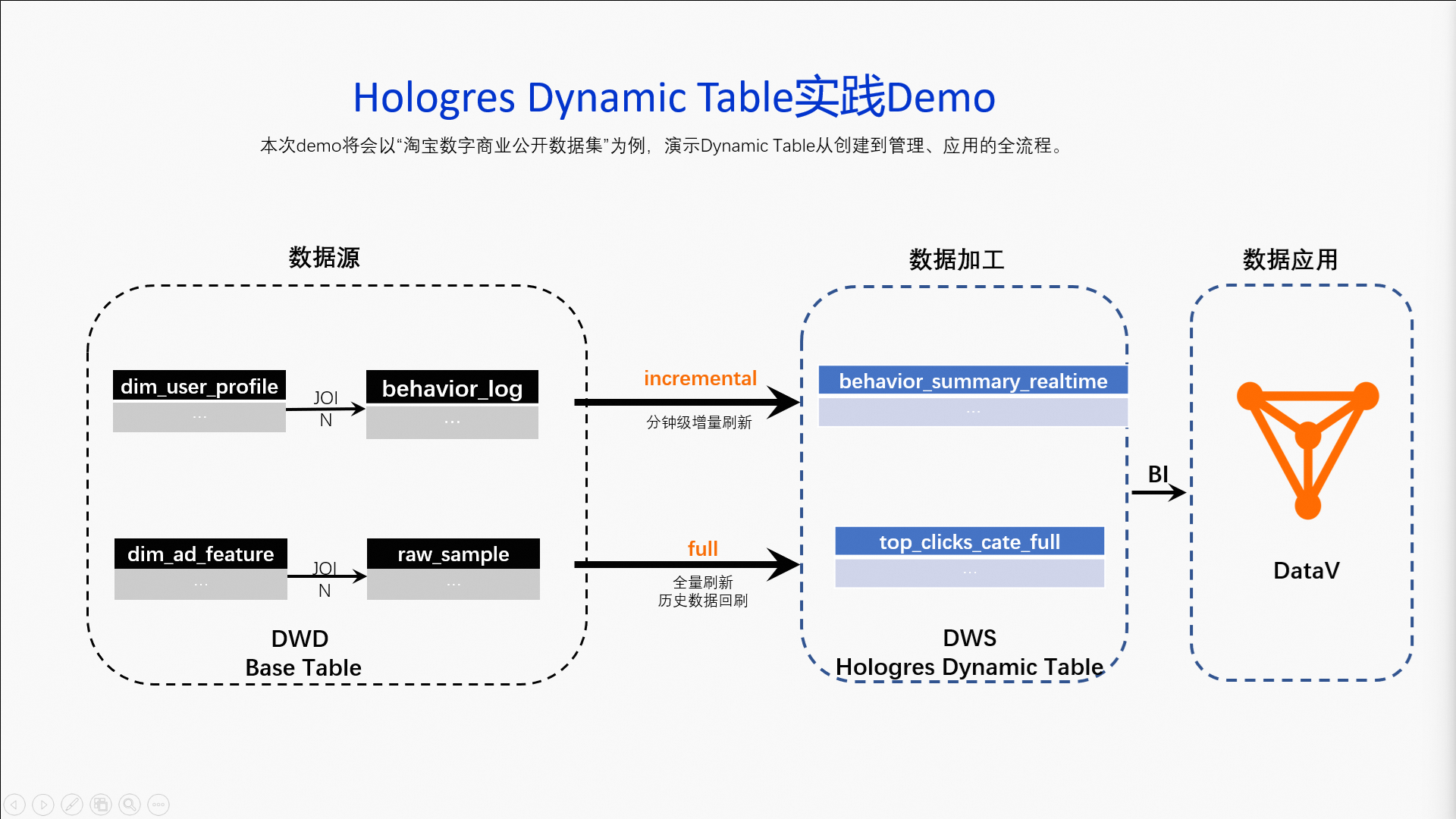
场景介绍
Hologres Dynamic Table增量刷新和全量刷新模式介绍如下:
增量刷新:场景1:累计增量成交分析。
全量刷新:场景2:历史广告数据分析与数据回刷。
数据链路如下。
数据源:本次示例中的数据来源为MaxCompute中的公开数据集,需要将数据写入到Hologres内部表,成为Dynamic Table的Base表。
数据加工:在Hologres中将Base表的数据,加工成两张Dynamic Table,分别配置增量刷新和全量刷新,形成DWS,满足业务的不同查询时效性。
数据应用:本次示例使用DataV展示Dynamic Table中数据的变化情况。
准备工作
环境准备
准备Hologres环境。
您需开通Hologres,创建并连接Hologres数据库,后续在Hologres数据库中执行命令读取数据。
说明您也可以申请Hologres的免费资源包,免费试用体验本教程的核心步骤。Hologres提供的免费资源包介绍及申请引导,详情请参见新用户免费试用。
建议开通Hologres Serverless资源,将刷新任务提交到Serverless集群执行,可以有效地隔离刷新任务之间的相互影响,详情请参见Serverless Computing。
准备DataWorks开发环境。
本次示例使用DataWorks进行Dynamic Table的创建和SQL开发,需要使用DataWorks新版数据开发,确保已开启参加数据开发(Data Studio)公测参数。具体操作,请参见创建工作空间。
您需要将上述Hologres数据源绑定至DataWorks开发环境。具体操作,请参见新版数据开发:绑定Hologres计算资源。
(可选)准备大屏搭建产品:本文以DataV为例。
本文以DataV为例,为您展示大屏搭建后的效果。
数据准备(准备Hologres Base表)
您需要创建如下表并将MaxCompute的公开数据集(数字商业数据集)其数据导入到Hologres内部表中,再创建Dynamic Table进行数据加工。
public.dim_ad_featurepublic.behavior_logpublic.raw_samplepublic.dim_user_profile
内部表的建表DDL和数据导入SQL如下。
--创建外表
CREATE SCHEMA foreign_holo;
IMPORT FOREIGN SCHEMA "BIGDATA_PUBLIC_DATASET#commerce" LIMIT to
(adv_raw_sample,adv_ad_feature,user_profile,behavior_log)
FROM server odps_server INTO foreign_holo options(if_table_exist 'error');
--创建广告基本信息维表
DROP TABLE IF EXISTS public.dim_ad_feature;
BEGIN;
CREATE TABLE public.dim_ad_feature (
adgroup_id bigint NOT NULL,
cate_id bigint,
campaign_id bigint,
customer_id bigint,
brand bigint,
price double precision
,PRIMARY KEY (adgroup_id)
) WITH (
orientation = 'column',
storage_format = 'orc',
distribution_key = 'adgroup_id'
);
END;
--导入维表数据
INSERT INTO dim_ad_feature SELECT
try_cast(adgroup_id as bigint) as adgroup_id,
try_cast(cate_id as bigint) as cate_id,
try_cast(campaign_id as bigint) as campaign_id,
try_cast(customer_id as bigint) as customer_id,
try_cast(brand as bigint) as brand,
price::double precision
FROM foreign_holo.adv_ad_feature;
--创建用户行为表
DROP TABLE IF EXISTS public.behavior_log;
BEGIN;
CREATE TABLE public.behavior_log (
user_id bigint,
ds text,
"time" text,
behavior_type text,
cate bigint,
brand bigint
) WITH (
orientation = 'column',
storage_format = 'orc',
binlog_level = 'replica',
binlog_ttl = '2592000',
bitmap_columns = 'ds,"time",behavior_type',
dictionary_encoding_columns = 'ds:auto,"time":auto,behavior_type:auto',
distribution_key = 'cate'
);
END;
--导入数据
INSERT INTO behavior_log SELECT
"user"::bigint,
date(to_timestamp(time_stamp::bigint)),
to_timestamp(time_stamp::bigint),
btag::text,
cate::bigint,
brand::bigint
FROM foreign_holo.behavior_log
WHERE date(to_timestamp(time_stamp::bigint))='2017-05-13' ;
--创建广告明细表
DROP TABLE IF EXISTS public.raw_sample;
BEGIN;
CREATE TABLE public.raw_sample (
user_id bigint,
adgroup_id bigint,
ds text,
"time" text,
pid text,
noclk integer,
clk integer
) WITH (
orientation = 'column',
storage_format = 'orc',
binlog_level = 'replica',
binlog_ttl = '2592000',
bitmap_columns = 'ds,"time",pid',
dictionary_encoding_columns = 'ds:auto,"time":auto,pid:auto',
distribution_key = 'user_id'
);
END;
--导入数据
INSERT INTO raw_sample SELECT
user_id::bigint,
adgroup_id::bigint,
date(to_timestamp(time_stamp::bigint)),
to_timestamp(time_stamp::bigint),
pid::text,
noclk::integer,
clk::integer
FROM foreign_holo.adv_raw_sample;
--创建用户基础信息维表
DROP TABLE IF EXISTS public.dim_user_profile;
BEGIN;
CREATE TABLE public.dim_user_profile (
user_id bigint NOT NULL,
cms_seg_id bigint,
cms_group_id bigint,
final_gender_code integer,
age_level integer,
pvalue_level integer,
shopping_level integer,
occupation integer,
new_user_class_level integer
,PRIMARY KEY (user_id)
) WITH (
orientation = 'column',
storage_format = 'orc',
distribution_key = 'user_id'
);
END;
--导入数据
INSERT INTO dim_user_profile SELECT
try_cast(userid as bigint),
try_cast(cms_segid as bigint),
try_cast(cms_group_id as bigint),
try_cast(final_gender_code as integer),
try_cast(age_level as integer),
try_cast(pvalue_level as integer),
try_cast(shopping_level as integer),
try_cast(occupation as integer),
try_cast(new_user_class_level as integer)
FROM foreign_holo.user_profile WHERE userid != 'userid';场景1:累计增量成交分析
在实际应用中,某些业务场景并不需要实时分析,例如:业务需要累积分析每小时的行为数据、成交数据等,允许数据有一定的延迟(近实时分析场景)。可以通过Dynamic Table的增量刷新,对新增数据的进行计算,减少数据计算量,同时也能提升数据加工的时效性,满足近实时数据分析需求。
创建Dynamic Table
使用DataWorks数据开发平台创建Dynamic Table,只需填写表名并添加查询SQL语句即可。若您使用Hologres控制台,完整创建SQL详情请参见增量刷新Dynamic Table。
进入DataWorks工作空间列表页,在顶部切换至目标地域,找到已创建的工作空间,单击操作列的,进入Data Studio。
单击左侧
 ,在数据目录页面,选择Hologres。
,在数据目录页面,选择Hologres。单击
 ,选择DataWorks数据源页签,单击已绑定目标数据源操作列的添加为数据目录。说明
,选择DataWorks数据源页签,单击已绑定目标数据源操作列的添加为数据目录。说明数据源的绑定操作详情,请参见新版数据开发:绑定Hologres计算资源。
单击左侧Hologres目录下的目标Schema,选择动态表页签,然后单击新建动态表。
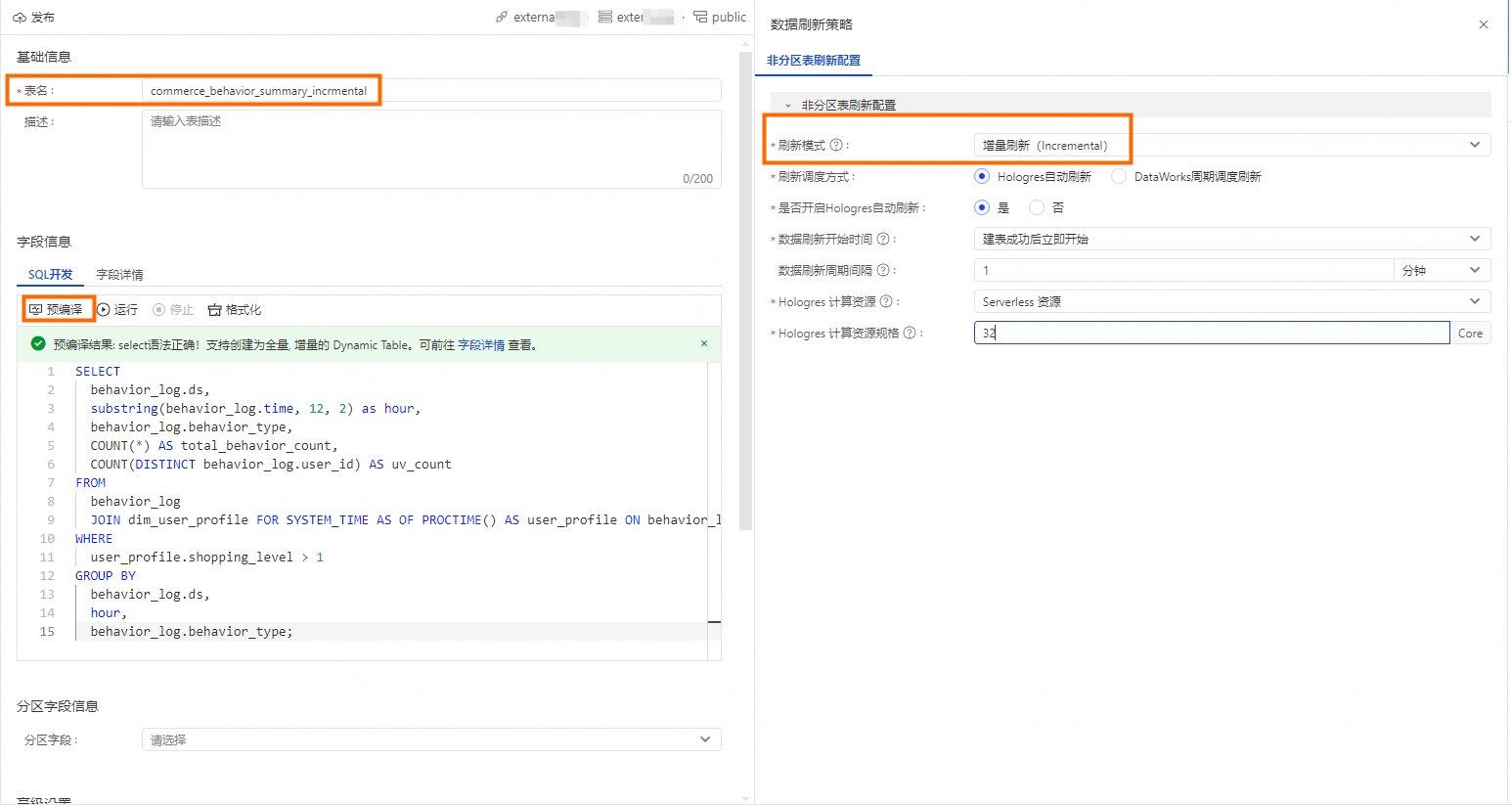
在新建动态表页面,填写建表信息。
填写表名:例如
commerce_behavior_summary_incrmental。若您自定义其他表名,下方查询SQL一并进行修改。在SQL开发界面填写SQL如下。
SELECT behavior_log.ds, substring(behavior_log.time, 12, 2) as hour, behavior_log.behavior_type, COUNT(*) AS total_behavior_count, COUNT(DISTINCT behavior_log.user_id) AS uv_count FROM behavior_log JOIN dim_user_profile FOR SYSTEM_TIME AS OF PROCTIME() AS user_profile ON behavior_log.user_id = user_profile.user_id WHERE user_profile.shopping_level > 1 GROUP BY behavior_log.ds, hour, behavior_log.behavior_type;单击预编译,对语法正确性进行校验。
右侧选择刷新策略,完成参数配置。
参数名称
说明
刷新模式
选择增量刷新(Incremental)。
数据刷新开始时间
选择建表成功立即开始。
数据刷新周期间隔
1分钟。
Hologres 计算资源
选择Serverless 资源。
Hologres 计算资源规格
32Core。

填写完成后,提交发布,发布成功后代表已经创建成功,增量刷新任务将会根据设置的刷新间隔周期性刷新Dynamic Table,实现数据的增量计算。
查询数据
增量Dynamic Table的刷新任务执行后,可以开始查询数据的增量变化,示例查询SQL如下。
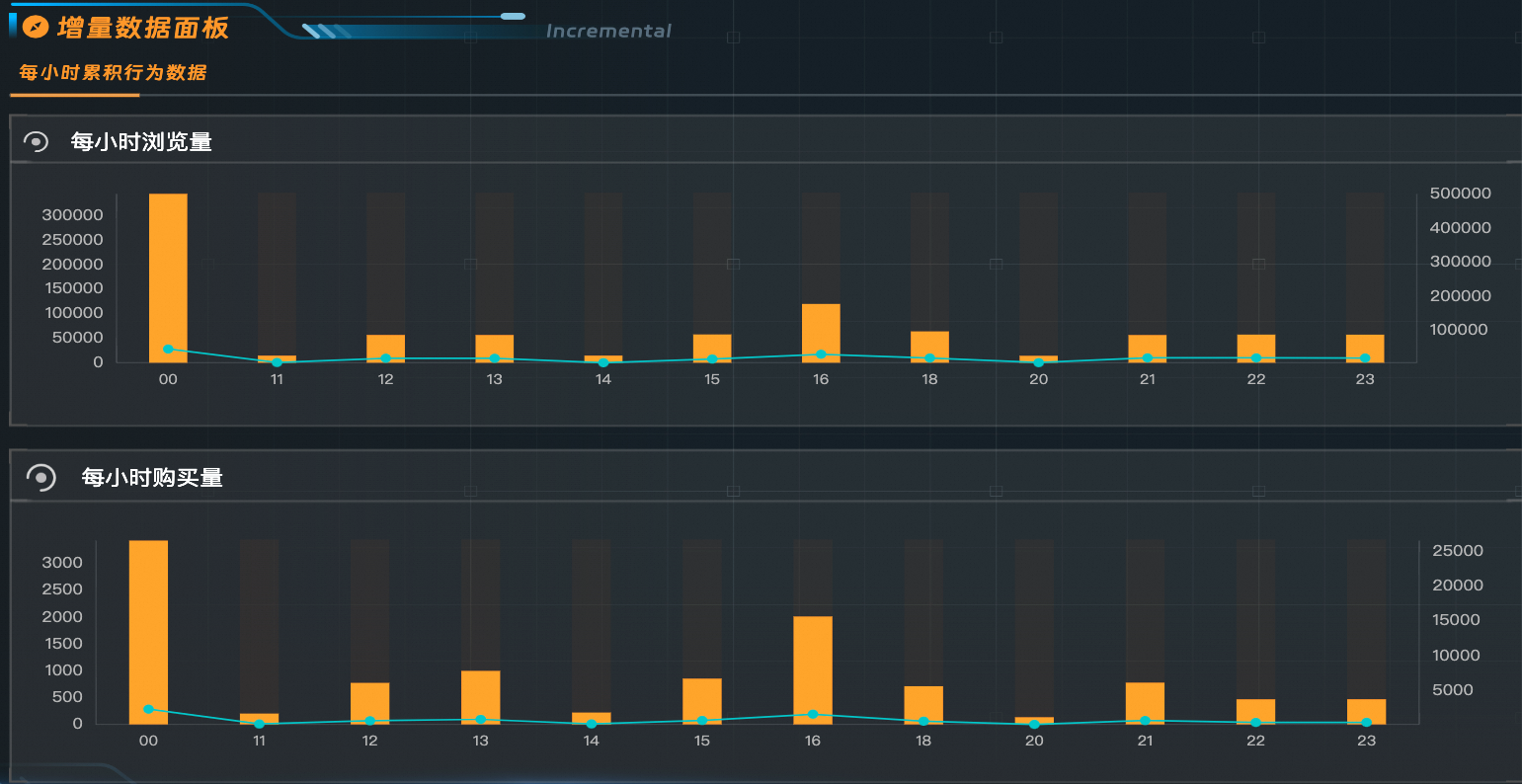
每小时浏览量。
--每小时浏览量 SELECT hour, total_behavior_count, uv_count FROM commerce_behavior_summary_incrmental WHERE ds = '2017-05-13' AND behavior_type = 'pv' ORDER BY hour;每小时购买量。
--每小时购买量 SELECT hour, total_behavior_count, uv_count FROM commerce_behavior_summary_incrmental WHERE ds = '2017-05-13' AND behavior_type = 'buy' ORDER BY hour;
增量大屏展示
当增量刷新任务启动成功后,可以直接使用Dynamic Table对接应用查询数据,本实践直接对接DataV大屏实时展示数据。操作步骤如下。
创建Hologres数据源(可选)。
将数据所在的Hologres实例和数据库创建为DataV的数据源,详情请参见DataV。
创建可视化应用。
登录DataV控制台。
在工作台页面,单击创建PC端看板。
选择已有模板或自定义模板,完成可视化数据展示。
示例展示每小时累计行为数据,使用DataV的柱状图可以直观地展示增量数据的变化。
场景2:历史广告数据分析与数据回刷
业务通常会有历史数据关联分析的场景,可以通过Dynamic Table的全量刷新(full)模式支持这种场景。批量刷新将会一次性刷新全量的数据,通过Dynamic Table就能完成历史数据的加工与计算,然后快速分析。本次实践通过全量刷新模式来计算过去7天广告点击排行榜Top10,通过DataWorks页面可视化创建Dynamic Table全量刷新模式。
创建Dynamic Table
使用DataWorks数据开发平台创建Dynamic Table,只需填写表名并添加查询SQL语句即可。若您使用Hologres控制台,完整SQL详情请参见全量刷新Dynamic Table。
进入DataWorks工作空间列表页,在顶部切换至目标地域,找到已创建的工作空间,单击操作列的,进入Data Studio。
单击左侧
图标,在数据目录页面,选择Hologres。单击
,选择DataWorks数据源页签,单击已绑定目标数据源操作列的添加为数据目录。说明数据源的绑定操作详情,请参见新版数据开发:绑定Hologres计算资源。
单击左侧Hologres目录下的目标Schema,选择动态表页签,然后单击新建动态表。
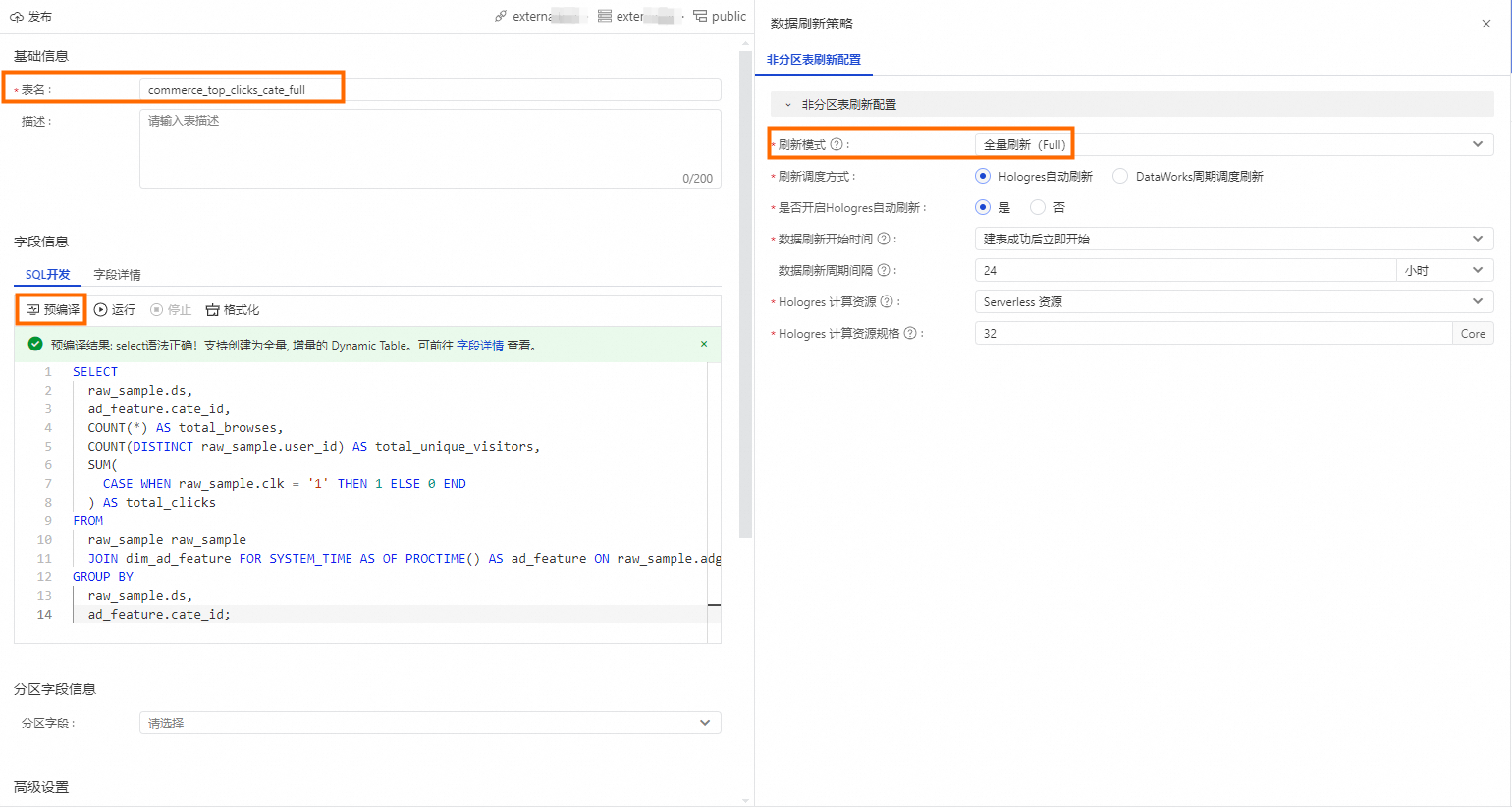
填写表名:例如
commerce_top_clicks_cate_full。若您自定义其他表名,下方查询SQL一并进行修改。在SQL开发界面填写SQL如下。
SELECT raw_sample.ds, ad_feature.cate_id, COUNT(*) AS total_browses, COUNT(DISTINCT raw_sample.user_id) AS total_unique_visitors, SUM( CASE WHEN raw_sample.clk = '1' THEN 1 ELSE 0 END ) AS total_clicks FROM raw_sample raw_sample JOIN dim_ad_feature FOR SYSTEM_TIME AS OF PROCTIME() AS ad_feature ON raw_sample.adgroup_id = ad_feature.adgroup_id GROUP BY raw_sample.ds, ad_feature.cate_id;单击预编译,对语法正确性进行校验。
右侧选择刷新策略,完成参数配置。
参数名称
说明
刷新模式
选择全量刷新(Full)。
数据刷新开始时间
选择建表成功立即开始。
数据刷新周期间隔
24小时。
Hologres 计算资源
选择 Serverless 资源。
Hologres 计算资源规格
32Core。
填写完成后,提交发布,发布成功后代表已经创建成功,全量刷新任务将会根据设置的刷新间隔周期性刷新Dynamic Table,实现数据的全量计算。
查询数据
全量刷新的Dynamic Table的刷新任务执行完成后,代表历史数据全量计算完成,可以直接查询Dynamic Table进行数据分析。示例SQL如下。
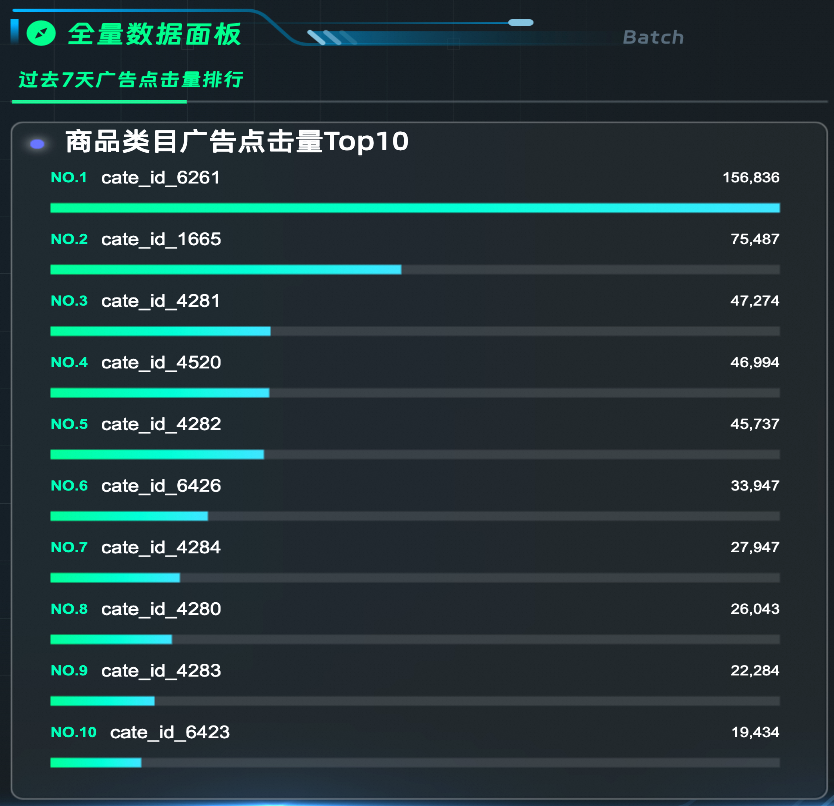
--过去7天广告点击排行
SELECT 'cate_id_' || cate_id, sum(total_clicks) AS sum_total_clicks FROM commerce_top_clicks_cate_full WHERE ds <= '2017-05-13' AND ds >= TO_CHAR(ds::date - INTERVAL '6 days', 'YYYY-MM-DD') GROUP BY cate_id ORDER BY sum_total_clicks DESC limit 10;全量大屏展示
可以直接将Dynamic Table对接DataV大屏展示数据。本实践已经提前准备好了DataV大屏,并连接好了数据源和配置大屏,能直接展示数据。
历史数据回刷
在实际场景中,历史数据可能会变化,为了保证数据口径的一致性,需要对历史数据刷新。可以通过Dynamic Table全量刷新的模式来完成历史数据的回刷,减少任务的维护,提升回刷的效率。本实践演示回刷场景,在DataWorks新建Hologres SQL节点,执行如下SQL。
模拟上游维表更新。
模拟业务中上游维表更新的场景,在DataWorks界面执行如下SQL对维表数据进行更新。
查询出数据。
SELECT * FROM raw_sample JOIN dim_ad_feature FOR SYSTEM_TIME AS OF PROCTIME () AS ad_feature ON raw_sample.adgroup_id = ad_feature.adgroup_id WHERE ad_feature.cate_id = '6261';模拟维表更新,将维表按照主键更新。
INSERT INTO dim_ad_feature (adgroup_id,cate_id) VALUES ('451376','888888'),('650847','000000') ON CONFLICT (adgroup_id) DO UPDATE SET cate_id = EXCLUDED.cate_id WHERE dim_ad_feature.cate_id= '6261';
回刷Dynamic Table。
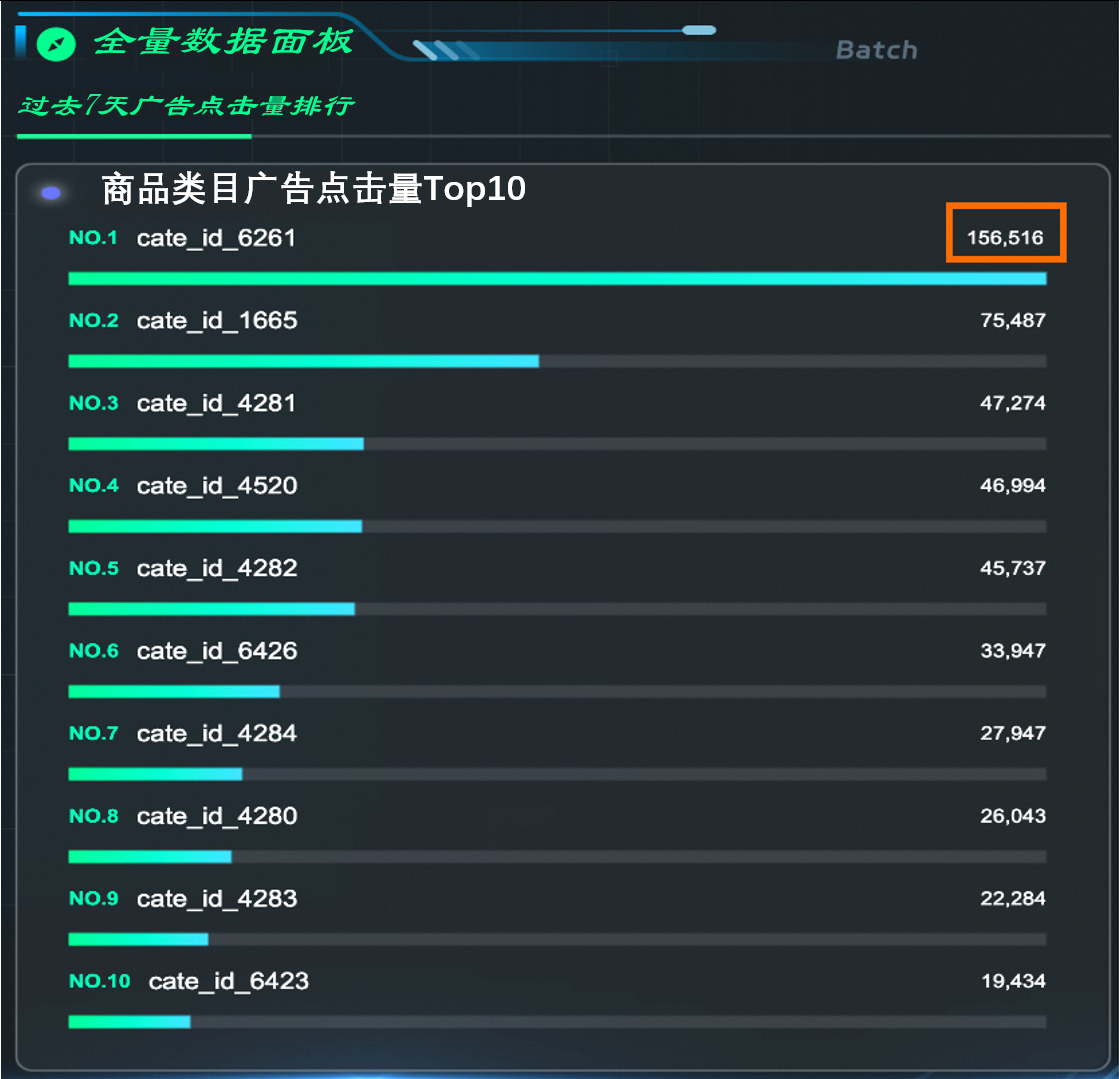
当维表更新完成后,需要对Dynamic Table执行一次刷新,匹配新的维表数据,从而保证数据口径的一致性。直接对Dynamic Table执行Refresh,即可完成回刷。
REFRESH TABLE commerce_top_clicks_cate_full;
回刷完成后,查看DataV大屏,全量数据面板中数据已经更新。
附录:Dynamic Table
增量刷新Dynamic Table
--累计增量成交分析,增量刷新
DROP TABLE IF EXISTS commerce_behavior_summary_incrmental;
CREATE DYNAMIC TABLE commerce_behavior_summary_incrmental WITH (
auto_refresh_enable='true',
refresh_mode = incremental,
incremental_auto_refresh_schd_start_time='immediate',
incremental_auto_refresh_interval = '1 minutes',
incremental_guc_hg_computing_resource = 'serverless',
incremental_guc_hg_experimental_serverless_computing_required_cores='32'
)
AS
SELECT
behavior_log.ds,
substring(behavior_log.time, 12, 2) as hour,
behavior_log.behavior_type,
COUNT(*) AS total_behavior_count,
COUNT(DISTINCT behavior_log.user_id) AS uv_count
FROM
behavior_log
JOIN dim_user_profile FOR SYSTEM_TIME AS OF PROCTIME() AS user_profile ON behavior_log.user_id = user_profile.user_id
WHERE
user_profile.shopping_level > 1
GROUP BY
behavior_log.ds,
hour,
behavior_log.behavior_type;全量刷新Dynamic Table
--历史广告数据分析,全量刷新
DROP TABLE IF EXISTS commerce_top_clicks_cate_full;
CREATE DYNAMIC TABLE commerce_top_clicks_cate_full WITH (
auto_refresh_enable='true',
refresh_mode = full,
full_auto_refresh_schd_start_time='immediate',
full_auto_refresh_interval = '24 hours',
full_guc_hg_computing_resource = 'serverless'
)
AS
SELECT
raw_sample.ds,
ad_feature.cate_id,
COUNT(*) AS total_browses,
COUNT(DISTINCT raw_sample.user_id) AS total_unique_visitors,
SUM(
CASE WHEN raw_sample.clk = '1' THEN 1 ELSE 0 END
) AS total_clicks
FROM
raw_sample
JOIN dim_ad_feature FOR SYSTEM_TIME AS OF PROCTIME() AS ad_feature ON raw_sample.adgroup_id = ad_feature.adgroup_id
GROUP BY
raw_sample.ds,
ad_feature.cate_id;