
本文介绍基于Paimon的Hologres Serverless数据湖解决方案,适用于存储在OSS中的Paimon湖数据灵活加速的场景,无需预留资源,可按需使用,并按使用量付费。该方案提供的灵活、可扩展的数据湖架构,便于您更好地管理和利用数据,提升数据驱动决策和业务创新的能力。
背景信息
Apache Paimon是一种流批统一的湖存储格式,支持高吞吐的写入和低延迟的查询。目前阿里云大数据平台常见的计算引擎(例如Flink、Hologres、MaxCompute、EMR Spark)都与Paimon有着较为完善的集成度。您可以借助Apache Paimon快速地在云端OSS上构建自己的数据湖存储服务,并接入上述计算引擎实现数据湖的分析,详情请参见Apache Paimon。
Hologres共享集群是针对MaxCompute和OSS数据湖外部表设计的Serverless在线查询加速服务,基于Hologres存储计算分离的云原生架构,以共享集群资源的形式,加速分析存储在OSS中的湖数据,按需使用,按SQL扫描的数据量付费,详情请参见共享集群概述。
整体架构
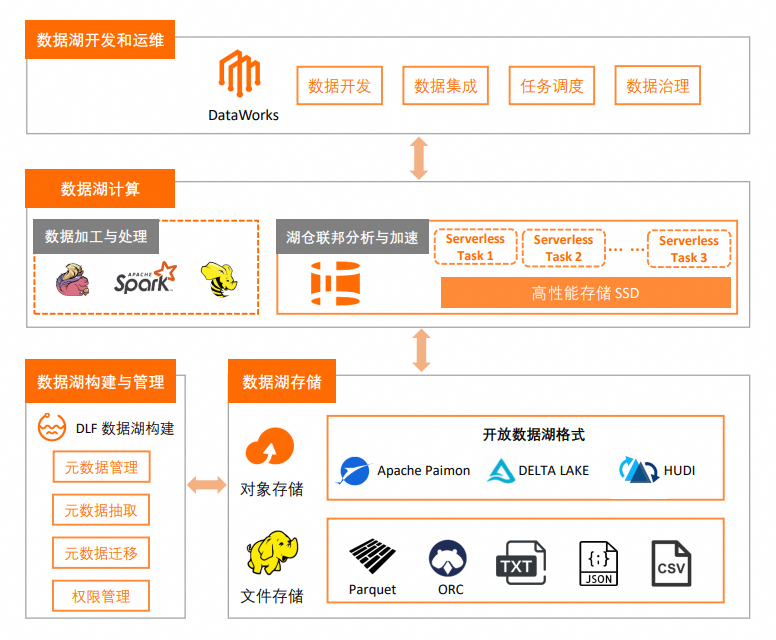
前提条件
已购买Hologres共享集群实例,购买方式请参见购买Hologres。
已开通DLF元数据构建服务,详情请参见DLF快速入门。
(可选)如果您需要使用DLF自定义数据目录功能(catalog),请先在DLF中新建数据目录,该数据目录将在后续创建Foreign Server时被使用,详情请参见新建数据目录。
已开通OSS数据湖存储。
已开通OSS-HDFS服务,详情请参见开通OSS-HDFS服务。
Hologres独享实例同样支持读取Paimon和其他湖格式,实际使用方式与共享集群实例相同,本文仅以共享集群实例为例。
注意事项
仅Hologres V2.1.6及以上版本支持查询Paimon数据湖的数据。
Hologres共享集群仅支持读取OSS数据湖数据,不支持导入OSS数据,如需导入OSS数据至Hologres内部表,请使用独享实例。
操作步骤
购买EMR新版数据湖实例。
登录EMR on ECS控制台,创建EMR集群,具体操作请参见创建集群。重点参数配置如下:
配置项
描述
业务场景
选择数据湖。
可选服务
必选服务为:Spark、Hive和Paimon,其余服务根据需要自行选择。
元数据
选择DLF统一元数据。
DLF数据目录
如果您需要使用DLF自定义数据目录,请选择已创建的catalog,例如paimon_catalog。具体操作请参见新建数据目录。
您也可以选择默认的default目录。使用DLF default catalog,在Hologres共享集群中创建Foreign Server时,无需指定
dlf_catalog参数。
集群存储根路径
选择一个开通了OSS-HDFS服务的Bucket路径。
构建数据源。
以TPC-H 10GB数据为例,使用EMR Hive构建textfile格式的数据源,构建方式请参考使用EMR Spark构建数据。
重要生成数据时,需将
./dbgen -vf -s 100命令替换为./dbgen -vf -s 10。使用Spark创建Paimon表。
登录Spark-SQL。
spark-sql --conf spark.sql.catalog.paimon=org.apache.paimon.spark.SparkCatalog --conf spark.sql.catalog.paimon.metastore=dlf创建数据库。
-- 创建数据库 CREATE DATABASE paimon_db location 'oss://${oss-hdfs-bucket}/tpch_10G/paimon_tpch_10g/';${oss-hdfs-bucket}:为上述已开通OSS-HDFS的Bucket名称。创建Paimon表并导入上述构建数据源中准备的textfile数据。
-- 切换至刚创建的数据库 use paimon_db; -- 创建表并导入数据 CREATE TABLE nation_paimon TBLPROPERTIES ( 'primary-key' = 'N_NATIONKEY' ) AS SELECT * from ${source}.nation_textfile; CREATE TABLE region_paimon TBLPROPERTIES ( 'primary-key' = 'R_REGIONKEY' ) AS SELECT * FROM ${source}.region_textfile; CREATE TABLE supplier_paimon TBLPROPERTIES ( 'primary-key' = 'S_SUPPKEY' ) AS SELECT * FROM ${source}.supplier_textfile; CREATE TABLE customer_paimon partitioned BY (c_mktsegment) TBLPROPERTIES ( 'primary-key' = 'C_CUSTKEY' ) AS SELECT * FROM ${source}.customer_textfile; CREATE TABLE part_paimon partitioned BY (p_brand) TBLPROPERTIES ( 'primary-key' = 'P_PARTKEY' ) AS SELECT * FROM ${source}.part_textfile; CREATE TABLE partsupp_paimon TBLPROPERTIES ( 'primary-key' = 'PS_PARTKEY,PS_SUPPKEY' ) AS SELECT * FROM ${source}.partsupp_textfile; CREATE TABLE orders_paimon partitioned BY (o_orderdate) TBLPROPERTIES ( 'primary-key' = 'O_ORDERKEY' ) AS SELECT * FROM ${source}.orders_textfile; CREATE TABLE lineitem_paimon partitioned BY (l_shipdate) TBLPROPERTIES ( 'primary-key' = 'L_ORDERKEY,L_LINENUMBER' ) AS SELECT * FROM ${source}.lineitem_textfile;${source}:为Hive中*_textfile表所在的数据库名称。
在Hologres共享集群中创建Foreign Server。
说明创建EMR新版数据湖实例时:
如果DLF数据目录选择的是自定义数据目录,下述
dlf_catalog参数值需填写该自定义目录。如果DLF数据目录选择的是default默认目录,执行时则无需配置
dlf_catalog参数,直接删除该参数即可。
-- 创建Foreign Sever CREATE SERVER IF NOT EXISTS dlf_server FOREIGN data wrapper dlf_fdw options ( dlf_catalog 'paimon_catalog', dlf_endpoint 'dlf-share.cn-shanghai.aliyuncs.com', oss_endpoint 'cn-shanghai.oss-dls.aliyuncs.com' );在Hologres共享集群中创建Paimon表的外部表。
IMPORT FOREIGN SCHEMA paimon_db LIMIT TO ( lineitem_paimon ) FROM SERVER dlf_server INTO public options (if_table_exist 'update');查询数据。
以Q1为例,SQL语句如下:
SELECT l_returnflag, l_linestatus, SUM(l_quantity) AS sum_qty, SUM(l_extendedprice) AS sum_base_price, SUM(l_extendedprice * (1 - l_discount)) AS sum_disc_price, SUM(l_extendedprice * (1 - l_discount) * (1 + l_tax)) AS sum_charge, AVG(l_quantity) AS avg_qty, AVG(l_extendedprice) AS avg_price, AVG(l_discount) AS avg_disc, COUNT(*) AS count_order FROM lineitem_paimon WHERE l_shipdate <= date '1998-12-01' - interval '120' DAY GROUP BY l_returnflag, l_linestatus ORDER BY l_returnflag, l_linestatus;说明其余21条SQL详情请参见TPC-H 22条查询语句。