
当Hologres响应速度变慢且您Hologres实例监控指标中某个或者某几个Worker的CPU使用率相比其他Worker的低时,此时可能出现了计算资源倾斜,Hologres建立了新的系统视图hologres.hg_worker_info,通过此视图可以查询当前数据库Worker、Table Group和Shard之间的关系,便于您判断资源倾斜等关系,解决资源负载不均问题,提高资源利用率。本文为您介绍如何通过hologres.hg_worker_info查看倾斜关系。
背景信息
Hologres中Worker、Table Group和Shard的概念及关系请参见产品架构和基本概念。Shard Count与Worker个数存在一定的分配关系。如果Worker个数与Shard数分配不均,那么很容易出现Worker资源倾斜,导致负载不均,资源得不到高效利用。同时管理控制台监控指标已经透出Worker概念,为了便于判断资源倾斜等关系,Hologres从 V1.3版本开始提供系统视图hologres.hg_worker_info,方便您查询当前数据库的Worker、Table Group和Shard之间的关系。
使用限制
仅Hologres V1.3.23及以上版本支持使用系统视图hologres.hg_worker_info,请在Hologres管理控制台的实例详情页查看当前实例版本,若实例版本较低,请您使用常见升级准备失败报错或加入Hologres钉钉交流群反馈,详情请参见如何获取更多的在线支持?。
hologres.hg_worker_info展示的是实时Worker与Shard的关系,不支持展示历史关系。
新建的Table Group需要一些时延才能获取
worker_id的信息,一般时延在10-20s左右,如果新建Table Group后立即查找该系统视图,可能会出现worker_id为空的情况。Table Group中没有表,那么Worker就会无法分配资源,查询结果中
worker_id会展示为id/0。Hologres从 V2.1版本开始,如果Worker没有分配Shard,也会展示worker_id,结果为空,代表该Worker在该数据库未分配Shard。仅支持查询当前数据库的Worker、Table Group和Shard信息,不支持跨数据库查询。
使用说明
系统视图hologres.hg_worker_info主要包含字段信息如下。
字段 | 类型 | 说明 |
worker_id | TEXT | 当前数据库所属Worker的ID。 |
table_group_name | TEXT | 当前数据库包含Table Group的名称。 |
shard_id | BIGINT | Table Group下Shard的ID。 |
warehouse_id | BIGINT | 当前Worker所属的计算组的ID。 |
使用如下命令查询hologres.hg_worker_info,查看每个Shard在Worker上的分布情况。
select * from hologres.hg_worker_info;查询结果示例如下:
查询结果中xx_tg_internal为实例的内置Table Group,用于管理元数据等信息,无需特别关注。
worker_id | table_group_name | shard_id
------------+------------------+----------
bca90a00ef | tg1 | 0
ea405b4a9c | tg1 | 1
bca90a00ef | tg1 | 2
ea405b4a9c | tg1 | 3
bca90a00ef | db2_tg_default | 0
ea405b4a9c | db2_tg_default | 1
bca90a00ef | db2_tg_default | 2
ea405b4a9c | db2_tg_default | 3
ea405b4a9c | db2_tg_internal | 3
最佳实践:解决计算资源倾斜(Worker负载不均)问题
在Hologres中数据分片(Shard)决定了数据的分布情况,一个Worker在计算时可能会访问一个或者多个Shard的数据。同一个实例中一个Shard同一时间只能被一个Worker访问,不能同时被多个Worker访问。如果实例中每个Worker访问的Shard总数不同,那么就有可能出现Worker资源负载不均的情况,主要表现为Worker节点CPU使用率监控指标中某个或者某几个Worker的CPU使用率较低,如下图所示。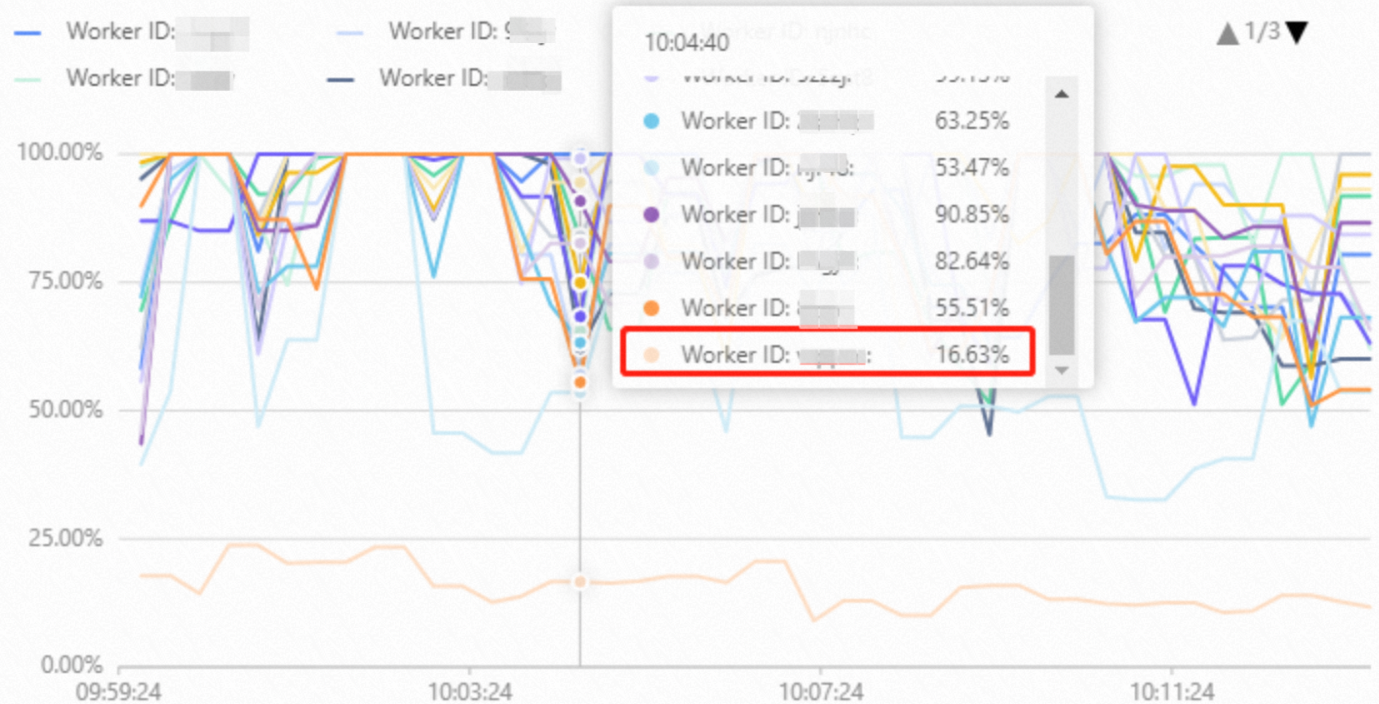 Worker负载不均会有多种原因导致,可以通过系统视图hologres.hg_worker_info做进一步分析。一般情况下原因和排查手段如下:
Worker负载不均会有多种原因导致,可以通过系统视图hologres.hg_worker_info做进一步分析。一般情况下原因和排查手段如下:
原因1:有Worker Failover后导致Shard分配不均。
如基本概念所述,当有Worker因为OOM等原因而出现Failover时,为了能快速恢复Worker的查询,系统会将该Worker对应的Shard,快速迁移至其他Worker。当被终止的Worker恢复,系统会再分配部分Shard给它,从而出现Worker间Shard分配不均的现象。通过hologres.hg_worker_info可以查看当前数据库下每个Worker上分配的Shard数,从而判断计算资源是否有分配倾斜的情况,但需要注意的是:hologres.hg_worker_info查询的是当前数据库下Shard与Worker的关系,而计算Worker是实例共享的,因此需要查看倾斜关系时,需要查询每个数据库中Shard与Worker的关系,得出实例维度每个Worker对应的总Shard数,以此综合判断倾斜情况。
命令示例:
select worker_id, count(1) as shard_count from hologres.hg_worker_info group by worker_id;查询结果示例:
--假设实例只有1个数据库,示例查询结果如下 worker_id | shard_count ------------+------------- bca90a | 4 ea405b | 4 tkn4vc | 4 bqw5cq | 3 mbbrf6 | 3 hsx66f | 1 (6 rows)结果解读:
实例只有6个Worker,但是6个Worker上分配的Shard数并不相同,查看管控台监控指标,发现较少Shard数的Worker对应的CPU使用率明显低于其他Worker,说明实例的计算资源分配不均。
解决方法:
重启实例,让计算Worker重新分配Shard,保证各个Shard在Worker上能够尽量均匀的分配。如果不重启实例,当另外的Worker出现Failover时,较空闲的Worker就会分配到更多的资源。
原因2:数据倾斜导致计算资源倾斜。
如果业务数据存在严重的倾斜,就会导致数据会分布在某些Shard,在查询时Worker负载就会访问固定的Shard,导致出现CPU负载不均的情况。可以通过hologres.hg_worker_info与hologres.hg_table_properties两个系统视图结合查询,根据表倾斜的数据对应的
worker id,从而判断是否是因为数据倾斜导致的计算资源倾斜,步骤如下。查看数据倾斜情况。
通过以下SQL查看表是否存在数据倾斜的情况,如果某个Shard的数据与其他Shard的数据相差较大,则说明这个表的数据存在倾斜。
select hg_shard_id,count(1) from <table_name> group by hg_shard_id order by 2; --示例结果:shard 39的count值较大,存在倾斜 hg_shard_id | count -------------+-------- 53 | 29130 65 | 28628 66 | 26970 70 | 28767 77 | 28753 24 | 30310 15 | 29550 39 | 164983通过数据倾斜的
hg_shard_id查询对应的worker_id。上一步骤得出哪个Shard数据存在倾斜,可以通过
hg_shard_id结合hologres.hg_worker_info与hologres.hg_table_properties两个系统视图,查询出倾斜的Shard对应的worker_id,命令示例如下 。SELECT distinct b.table_name, a.worker_id, a.table_group_name,a.shard_id from hologres.hg_worker_info a join (SELECT property_value, table_name FROM hologres.hg_table_properties WHERE property_key = 'table_group') b on a.table_group_name = b.property_value and b.table_name = '<tablename>' and shard_id=<shard_id>; --查询结果示例 table_name | worker_id | table_group_name | shard_id ------------+------------+-------------------+------------------ table03 | bca90a00ef | db2_tg_default | 39通过结果中的
worker_id,结合Worker节点CPU使用率监控指标,如果该Worker的负载情况明显高于其他Worker,则说明是数据倾斜导致的资源倾斜。
解决方法:
设置合适的Distribution Key,让数据尽可能的在Shard间分布均匀,详情请参见优化查询性能。
如果是业务的数据倾斜比较严重,例如直播订单表的商品交易总额(GMV),可能存在不同主播数据有明显的差异,可以考虑拆分成多个表来实现。
原因3:Shard数设置不合理
建议Shard数尽量与Worker的个数存在一定的倍数关系,这样才能使得Worker间的负载尽量均衡,如果Shard数设置不够合理,会导致Worker负载可能出现不均的情况。可以通过hologres.hg_worker_info查看当前数据库下TableGroup设置的Shard数是否合理。
命令示例
select table_group_name, worker_id, count(1) as shard_count, warehouse_id from hologres.hg_worker_info group by table_group_name, worker_id, warehouse_id order by table_group_name desc;示例结果
table_group_name | worker_id | shard_count | warehouse_id ------------------+------------+--------------+------------- tg2 | ea405b4a9c | 1 | 1 tg2 | bca90a00ef | 2 | 2 tg1 | ea405b4a9c | 5 | 1 tg1 | bca90a00ef | 6 | 2 db2_tg_default | bca90a00ef | 4 | 2 db2_tg_default | ea405b4a9c | 4 | 1 db2_tg_internal | bca90a00ef | 1 | 2 (7 rows)结果解读(假设实例只有2个Worker)
tg2设置了3个Shard,其中一个Worker会少分配一个Shard,如果性能不满足预期,建议优化Shard数或者扩容。tg1设置了11个Shard,其中一个Worker会少分配一个Shard,如果性能不满足预期,建议优化Shard数或者扩容。默认Table Group
db2_tg_default设置了8个Shard,Worker分配的Shard较均匀。
解决方法
如果是Shard数设置不合理导致Worker资源倾斜,可以根据业务情况综合评估Shard数的设置,建议设置成Worker个数的倍数。