
Hologres是一款高性能的、计算存储分离的分布式一站式实时数仓引擎,数据存储在位于底层存储系统的数据分片(又称Shard)上。本文为您介绍Hologres中Table Group和Shard Count的概念。
Table Group和Shard
在Hologres中数据存储在Pangu系统上,Shard表示数据分片,Table Group则是用于管理这些Shard,类似于存储逻辑概念。一个表的数据将会存储在固定的一组Shard上,数据写入时会按照Distribution Key将数据分发到具体的Shard上。从创建表开始,负责存储表数据的这一组Shard就已经分配好了,Table Group则负责管理这一组Shard。
Table Group是Hologres特有的一个存储逻辑概念(PostgreSQL无此概念)。Table Group与PostgreSQL中的TABLESPACE是不一样的:TABLESPACE唯一标识了数据库对象的存储位置,类似一个目录的概念。而Table Group代表的是底层的逻辑Shard组。
Table Group布局图如下: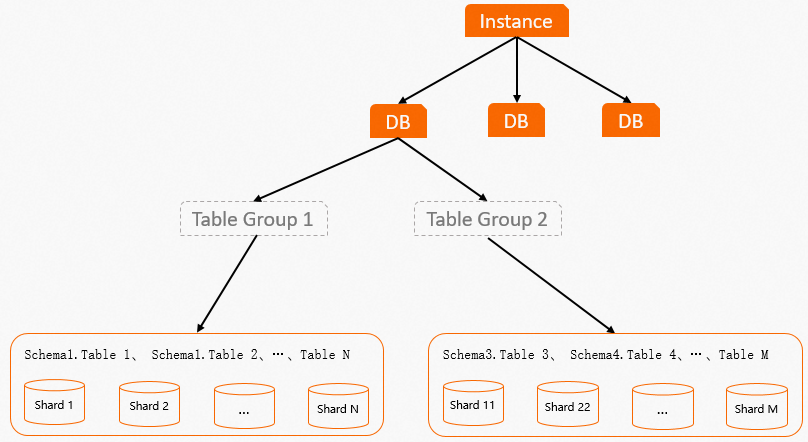 通过Table Group布局图,可以看出:
通过Table Group布局图,可以看出:
Table Group与Schema的区别
Schema是一个标准的数据库概念,而Table Group是一个逻辑存储概念,并非数据库标准。不同Schema下的表可以位于同一个Table Group,即底层使用同一组Shard存储。
Table Group与数据库(DB)的关系
一个DB可以包含一个或者多个Table Group,但是一个DB只能有一个默认Table Group。在创建DB之后,系统会创建一个默认Table Group,可以根据业务情况增加Table Group或者修改默认Table Group。
不同Table Group的区别
一个DB可以存在多个Table Group,但Table Group之间的Shard互不相交,每个Shard在实例级别拥有单独的编号。
Shard Count
一个Table Group中Shard的数量称为Shard Count。Shard Count在创建Table Group时指定,所以Table Group一旦建立,Shard Count就不能调整,如需调整Shard Count,需要重新创建Table Group并指定Shard数。
Shard与Table的关系
Shard负责表数据的存储和查询,系统根据Distribution Key决定表数据分布在哪些Shard,如果没有设置Distribution Key,那么数据就会被随机分配到各个Shard。
一个Table Group中可以有多个Table,即多个Table可以分布在同一组Shard上。但是一个Table只能属于一个Table Group,如果Table Group中没有Table,那么Table Group会被系统自动删除。
如果Table的数据要从一个Table Group迁移至另外一个Table Group,那么需要重新建表指定Table Group,或者通过迁移函数将数据进行迁移。
Shard与计算节点Worker的关系
在Hologres中存储引擎Storage Engine(SE)主要负责管理和处理数据,在DML的功能上,SE提供了单条或者批量的创建、查询、更新、和删除(CRUD操作)访问方法的接口,查询引擎(QE)可以通过这些接口访问Shard上的数据,从而实现数据的高性能写入或者读取。
计算节点Worker、SE、Shard的布局关系图如下。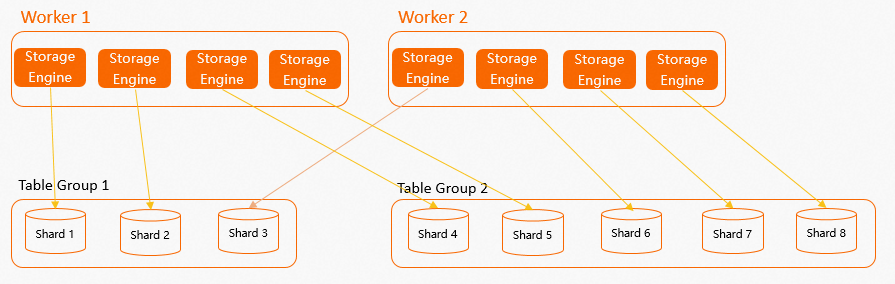 从图中可以看出Table Group和Shard不仅与数据的存储分布有关系,还与计算Worker有一定的关系:
从图中可以看出Table Group和Shard不仅与数据的存储分布有关系,还与计算Worker有一定的关系:
当创建Table Group并设置Shard数后(如果没有显式设置Table Group和Shard数,那么Hologres会在创建数据库时创建一个默认Table Group并为其设置默认的Shard Count,详情请参见实例管理),每个计算节点Worker会在内部创建多个SE,一个SE负责一个Shard数据的读取和写入。
系统机制会尽量保证每个Worker中的SE数量均匀,这样能够让Worker计算资源均匀分配。
系统会保证一个Table Group内的Shard一定是分配给多个Worker,不会出现一个Table Group仅对应一个Worker,其余Worker空置的情况。但如果Table Group的Shard数较少,但是实例规格较大即Worker较多,则会导致某些Worker无法分配Shard,导致某些Worker空置,因此在设计Shard数时一定要充分考虑业务情况,确保Worker的个数与实例总的Shard数有一定的均衡关系。
从上图中能很容易看出一个问题:假如Table Group的Shard数与Worker个数不成比例关系(如上图
Table Group 1有3个Shard,但是只有2个Worker),那么就一定会存在某个Worker比其他Worker多分配一个SE给Table Group的情况,这样在计算时,就非常容易造成Worker资源倾斜,容易出现计算长尾。因此我们建议若是要修改Shard Count,建议Shard Count与计算Worker成一定的比例关系。如下图所示Table Group 1和Table Group 2的Shard数都与Worker个数存在倍数关系,计算资源能够均匀的分配。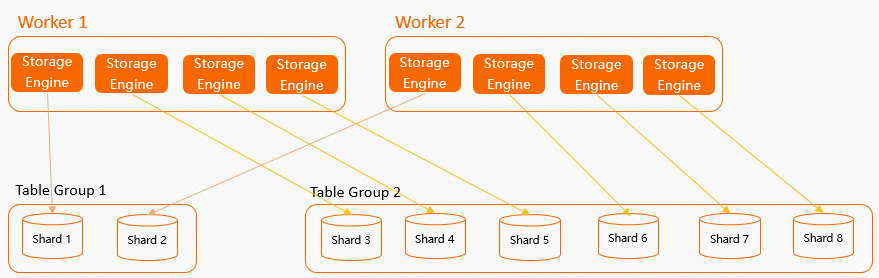
在实际业务中,可能会存在某个Worker因为OOM等原因出现Failover的情况,那么该Worker对应的Shard将会在Worker Failover之后自动挂载在其他Worker上,系统会保证每个Worker新分配的Shard均匀。如下示例,实例一共有4个Worker,2个Table Group共8个Shard,其中每个Worker有2个SE均匀对应Shard,当
Worker 4Failover后,假设Worker 4对应Shard 7和Shard 8,那么Shard 7和Shard 8就会被快速分配给其他3个Worker,因为只有2个Shard,所以系统会随机选择2个Worker进行分配,尽量保证Worker的SE数量均匀。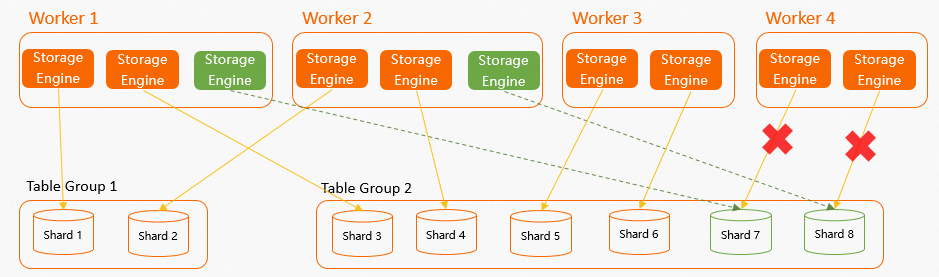
总结
Worker数量与Shard数有着非常紧密的联系。合理的设置Table Group与Shard Count,其数据写入和查询分析处理可以得到更大的并行度,将计算资源充分使用,从而从根本上提高数据的存储与计算效率。反之如果Table Group和Shard数制定不当,很容易出现性能不如预期的情况,且无法从根本上调优到最佳性能:
一定范围内Shard数多的Table Group,其数据写入和查询分析处理可以得到更大的并行度。但Shard数也并非越多越好,更多的Shard数需要更多的节点间通信资源、计算资源以及内存资源,在资源不满足的时候,或者Query很小时可能会导致适得其反的效果。
Shard数下限是1,在数据量只有几百几千条等很小的情况下,可以设置Shard数为1。一个Table Group上,Shard数的上限建议是实例的总计算Core数,这样是为了保证每个Shard在计算时,至少可以占据1个Core用于计算。如果Shard数超过计算Core数,那么运行查询时,将有部分Shard无法一直分到CPU资源,可能带来长尾和切换开销。
除Shard数量外,Table Group本身的数量也不是越多越好。每个Shard无论是否正在使用,都会占据一定的内存空间,用于存放表元数据、Schema等信息,在表有写入时则会占据更多内存空间。因此如果Table Group越多,则实例内总Shard数越多,内存空间占用越大。另外多个表之间有一些特殊的关系(例如需要Local Join)时,这些表必须要处在同一Table Group下才行。
从磁盘上来看,Shard数越多,对于同样的一张表,数据会分的越散,越容易出现小文件,从而文件个数更多。如果表多并且Shard也多,那文件数量就会非常庞大。在查询时Failover时都需要更多的开销,造成查询I/O增多,恢复时间变长。