百炼支持通过LlamaIndex API构建RAG(检索增强生成)应用,用于私域知识问答、客户支持等场景。本文通过构建一个示例RAG应用,演示LlamaIndex API的用法。
本方案中,LlamaIndex提供了构建RAG应用的工具和框架,百炼提供了数据管理能力和大模型服务。如果您已经熟悉LlamaIndex API,可以参考本方案,结合百炼和LlamaIndex的能力构建RAG应用。
本方案将知识库部署在云端,使用默认的智能文档切分与官方向量模型,不支持自定义文档切分方式或自定义嵌入模型。
如果您希望将知识库部署在本地,实现灵活地文档切分与嵌入模型选择,请参考基于本地知识库构建RAG应用。
如果您希望将知识库部署在云端,实现0代码地创建RAG应用,请参考0代码构建RAG应用。
效果展示
您可以通过本方案实现以下效果:
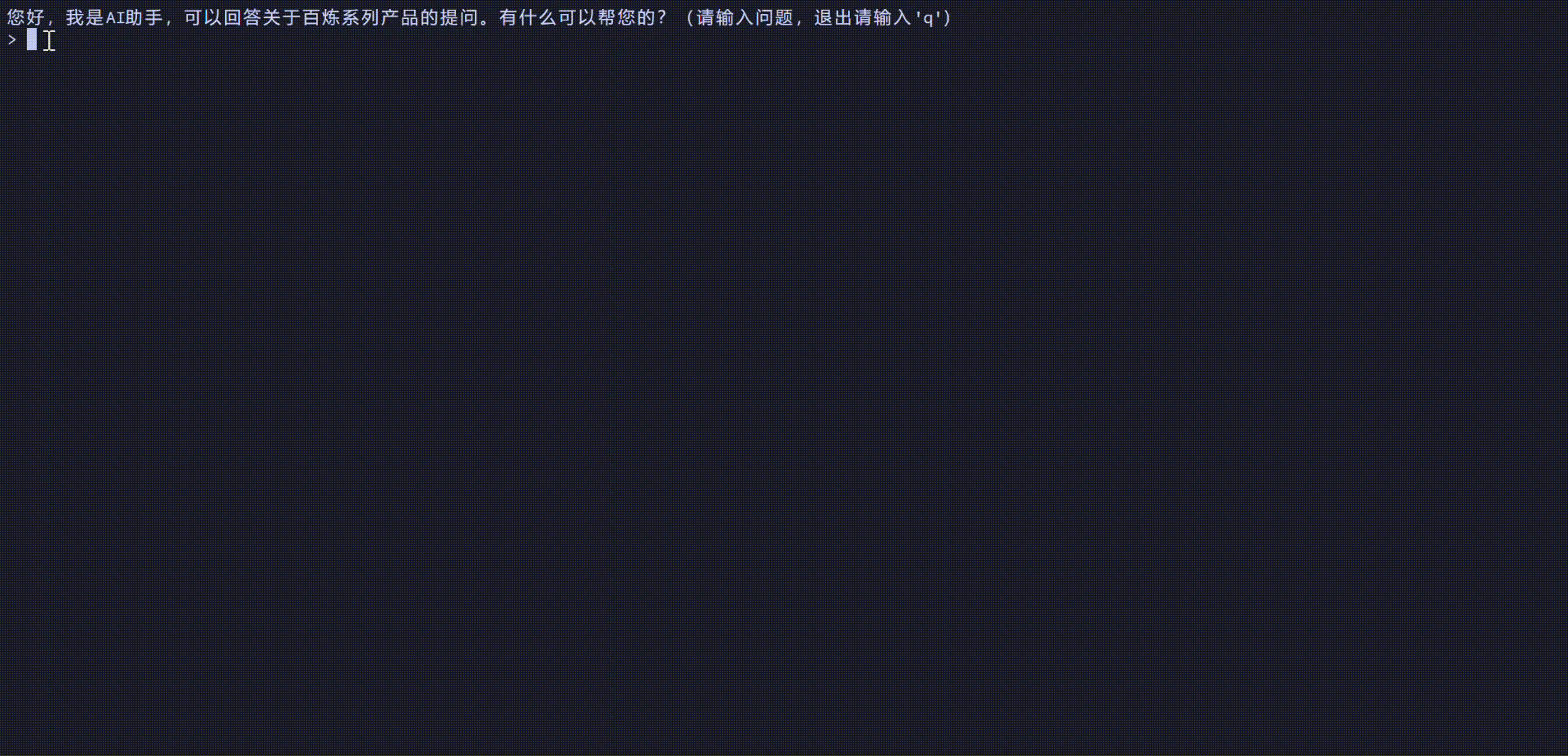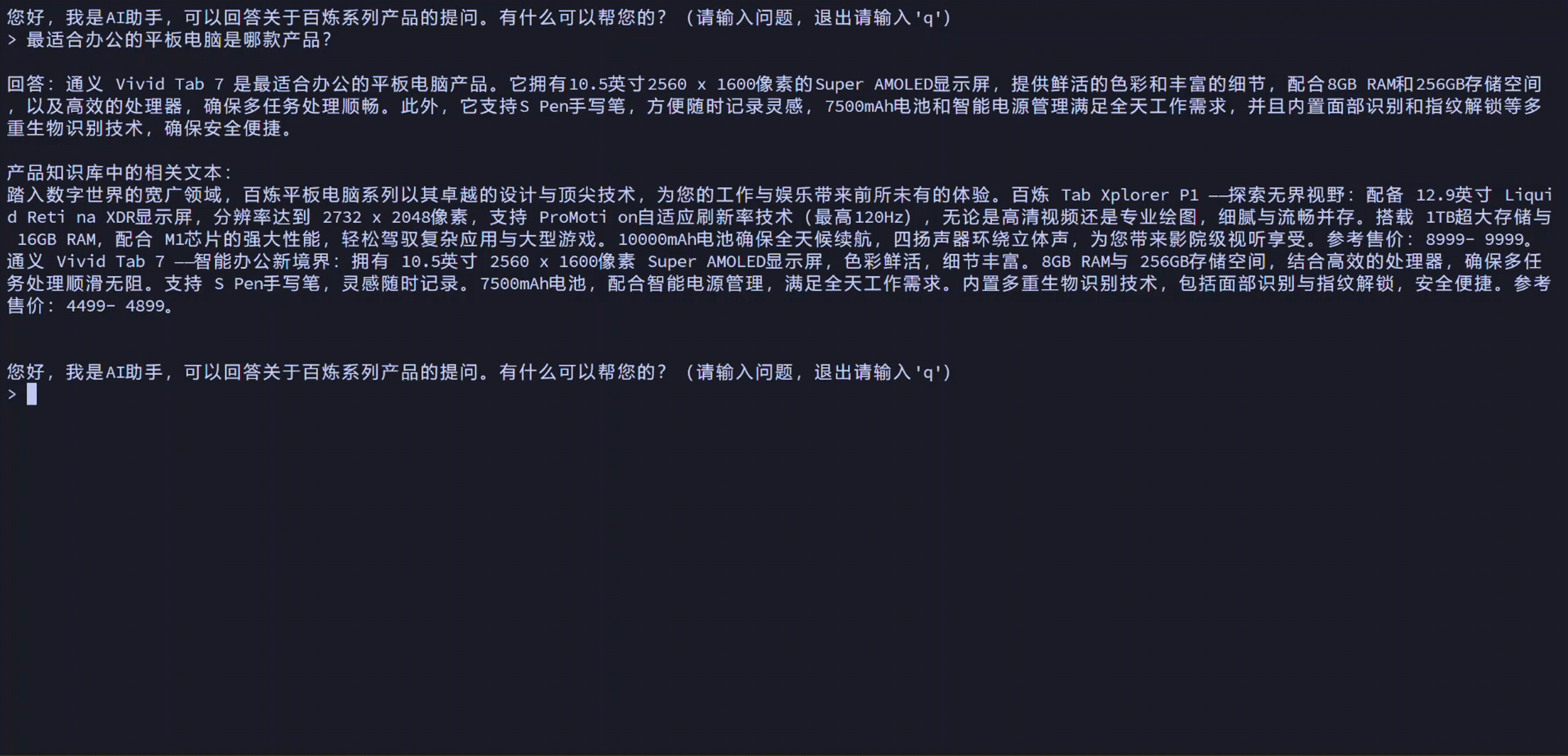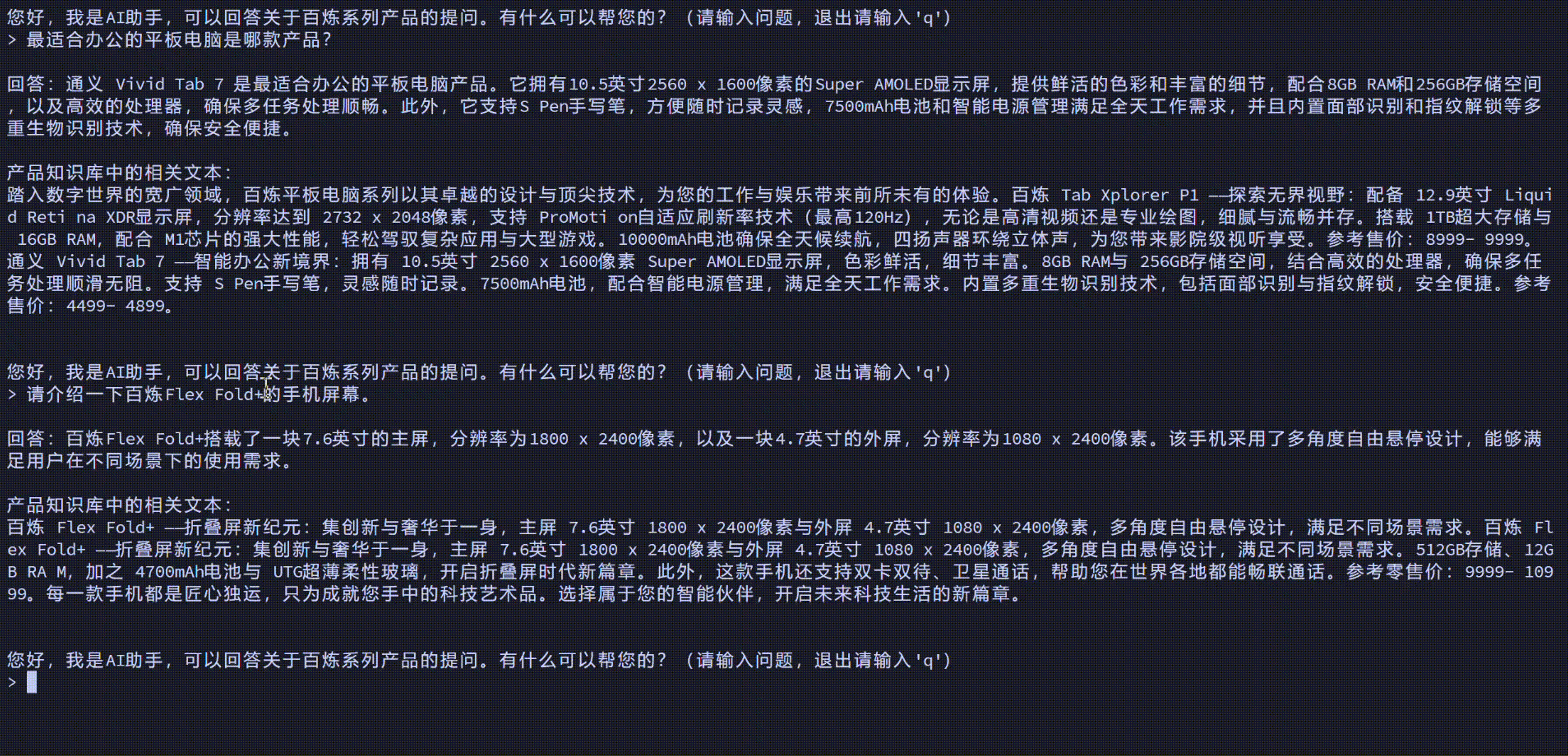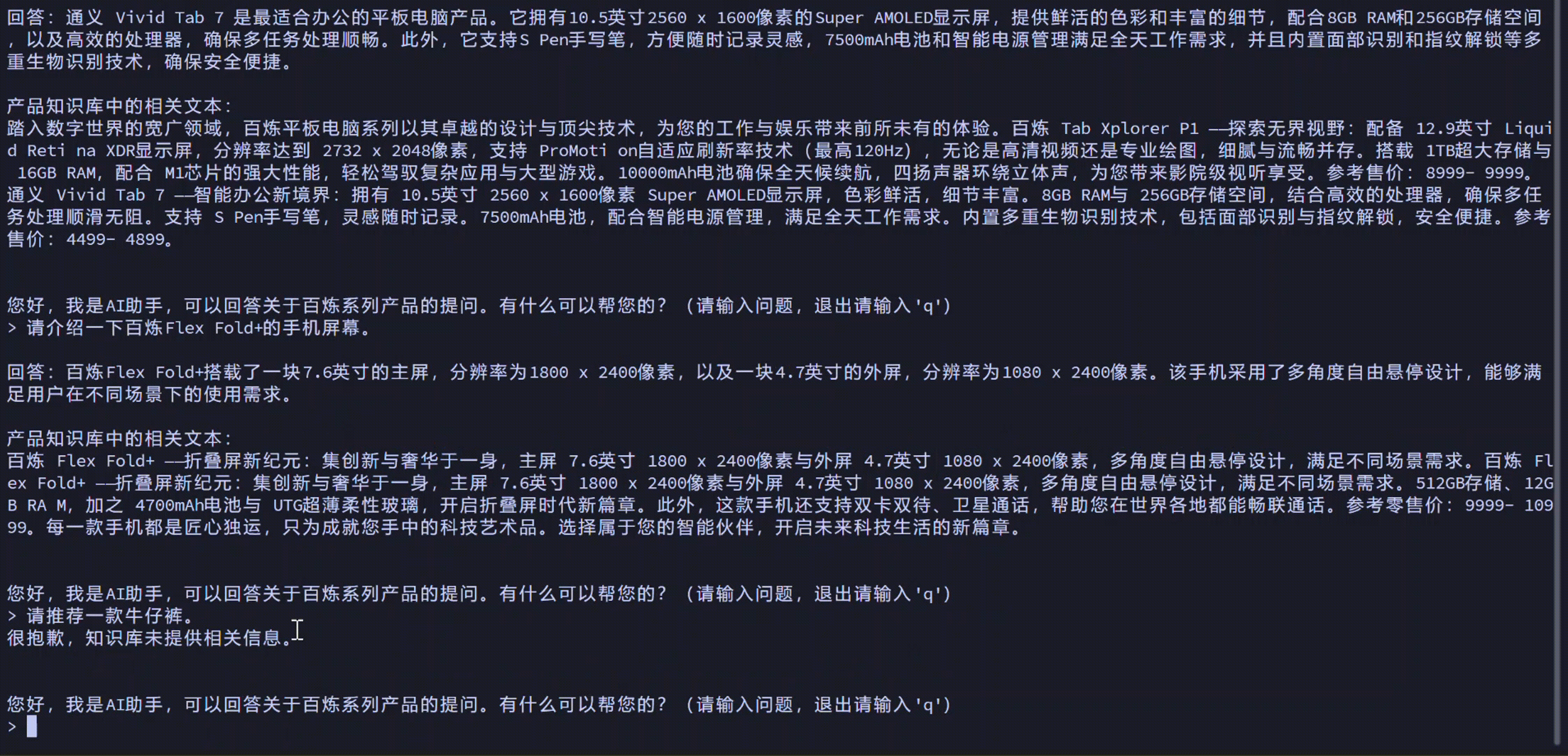
方案概览
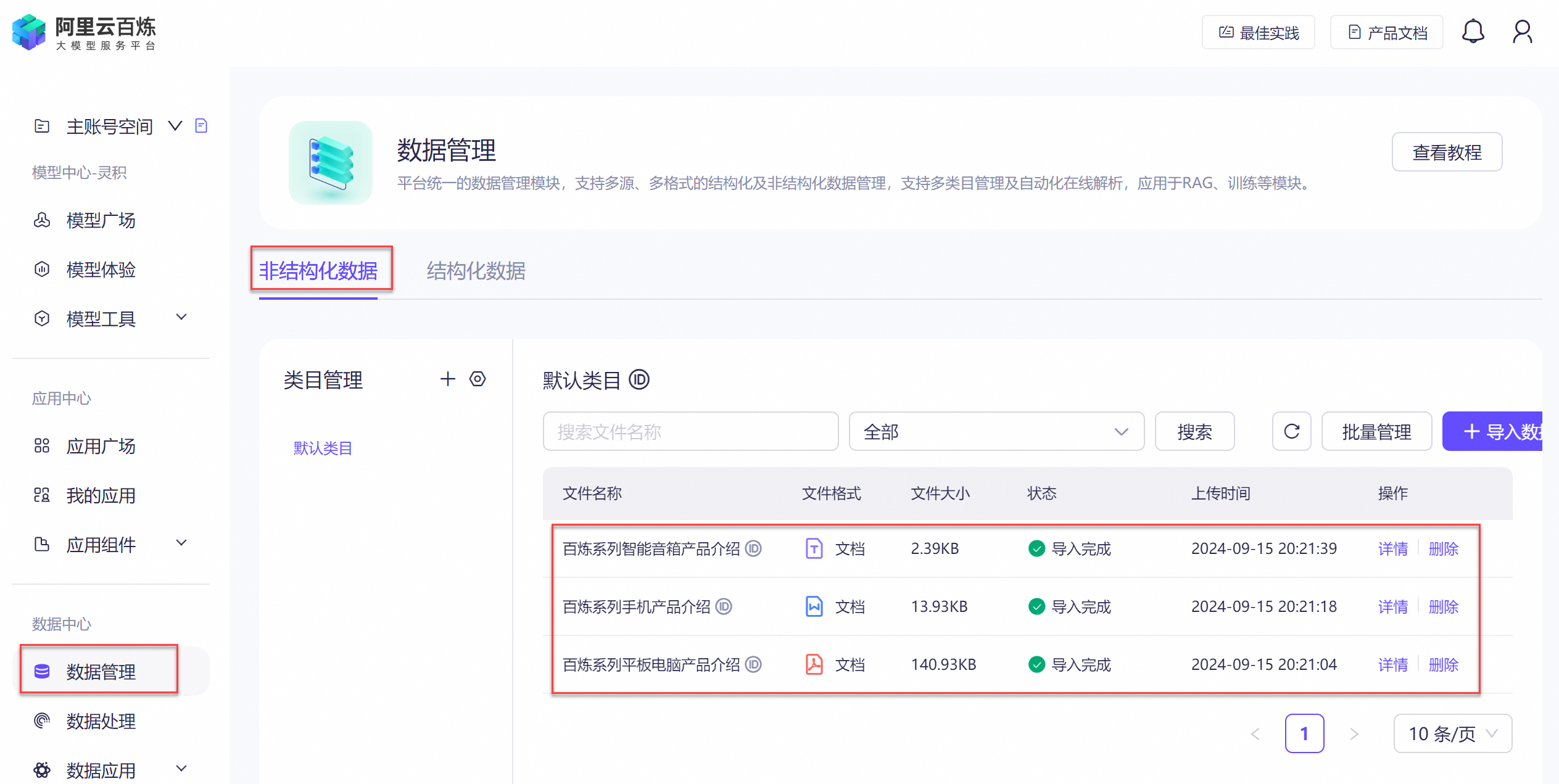
读取本地文件并构建云端知识库索引:仅支持读取并解析.txt、.docx、.pdf等非结构化数据文件,上传文件到云端,并构建云端知识库索引。
构建检索引擎和RAG应用:基于云端知识库索引,构建检索引擎,能够接收终端用户的提问,从云端知识库中检索相关的文本片段,再将提问和检索结果合并后输入到大模型,并生成回答。RAG应用提供与终端用户的交互界面,如果无法检索到相关的文本片段,或根据检索到的文本片段无法回答终端用户的提问,则返回适当的报错信息。
下载示例文件和代码
下载llamaindex_cloud_rag.zip并解压,目录结构如下:
llamaindex_cloud_rag
├── docs
│ ├── 百炼系列平板电脑产品介绍.pdf
│ ├── 百炼系列手机产品介绍.docx
│ └── 百炼系列智能音箱产品介绍.txt
├── create_cloud_index.py
├── rag.py
└── requirements.txt
其中docs/包含示例文件,您可以替换为实际的业务文件;create_cloud_index.py用于读取docs/中的文件并构建云端知识库索引;rag.py用于构建检索引擎和RAG应用;requirements.txt用于安装环境依赖。
安装环境依赖
进入requirements.txt所在路径,运行如下命令:
pip install -r requirements.txt
读取本地文件并构建云端知识库索引
进入create_cloud_index.py所在路径,运行如下命令:python create_cloud_index.py,即可将docs/中的业务文件上传到百炼数据管理平台,并构建云端知识库索引。
请确保本地可以访问公网。文件上传需要一定时间,请耐心等待执行完成。
代码执行完毕后,您可以在百炼控制台的数据管理页面,查看已上传到云端的文件集合。
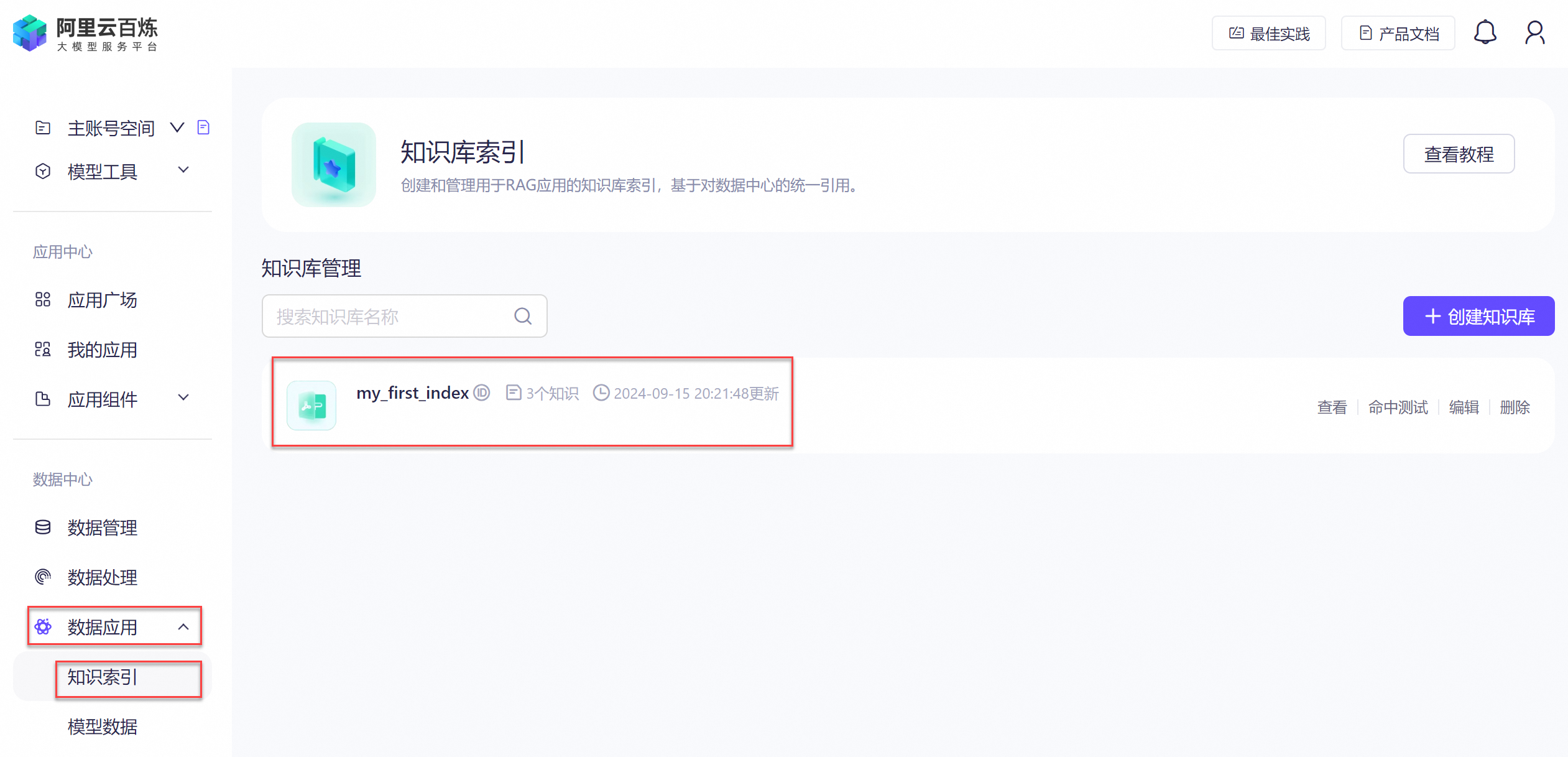
您可以在百炼控制台的页面,查看已构建的云端知识库索引。
代码解析
create_cloud_index.py
from llama_index.core import SimpleDirectoryReader
from llama_index.readers.dashscope.base import DashScopeParse
from llama_index.readers.dashscope.utils import ResultType
from llama_index.indices.managed.dashscope import DashScopeCloudIndex
def read_parse_upload_local_documents(dir, num_workers=1):
"""读取、解析、上传本地文件到百炼数据管理平台。
Args:
dir (str): 本地文件存储的路径。
num_workers (int, optional): 执行的并发数。
Returns:
已上传到云端的文件列表
"""
parse = DashScopeParse(result_type=ResultType.DASHSCOPE_DOCMIND)
file_extractor = {'.txt': parse, '.docx': parse, ".pdf": parse} # 设置需要读取解析的文件格式,请根据实际需求调整
documents = SimpleDirectoryReader(input_dir=dir, file_extractor=file_extractor).load_data(num_workers=num_workers)
return documents
if __name__ == '__main__':
dir = "./docs/" # 本例中,业务相关文件存储在当前路径下的docs文件夹,请根据实际情况调整。
documents = read_parse_upload_local_documents(dir)
cloud_index_name = "my_first_index" # 设置云端知识库索引名称
index = DashScopeCloudIndex.from_documents(documents, cloud_index_name, verbose=True) # 创建云端知识库索引
构建检索引擎和RAG应用
进入rag.py所在路径,运行如下命令:python rag.py,即可读取已创建的云端知识库索引,构建检索引擎,并在本地启动RAG应用。
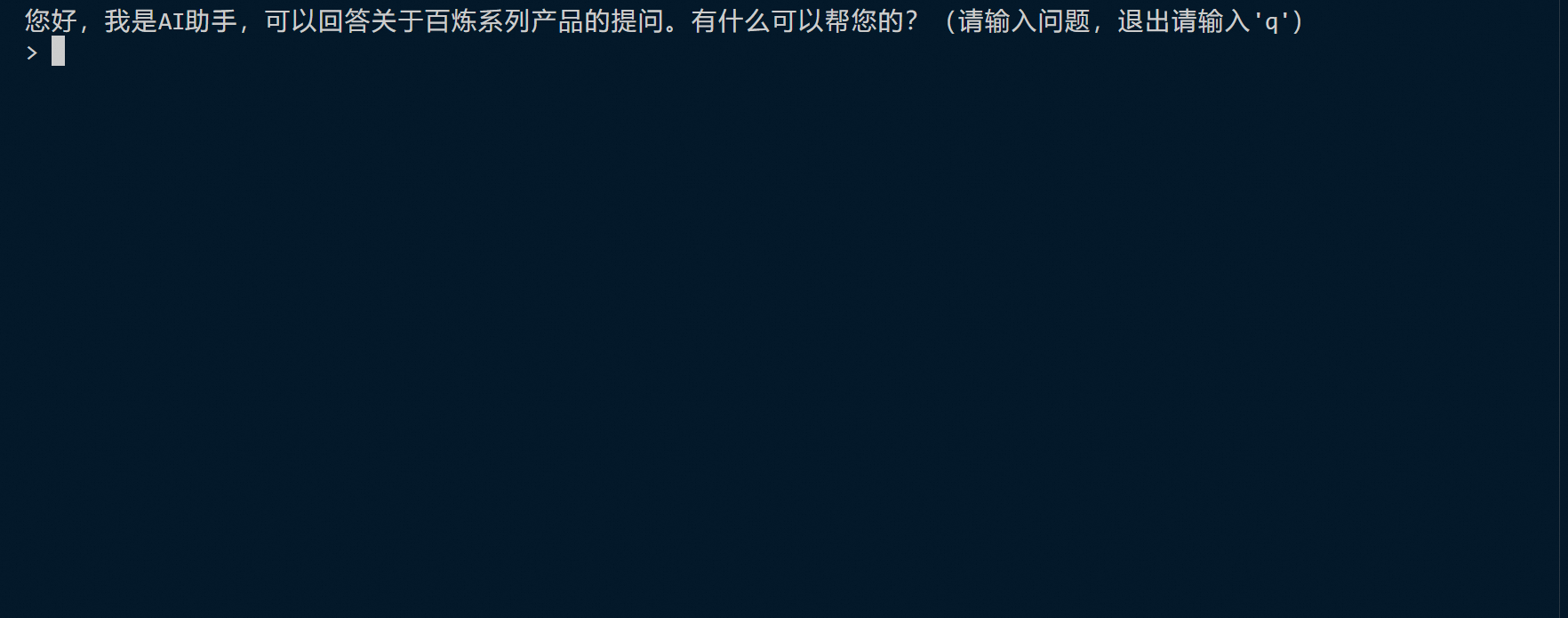
您可以根据界面提示与RAG应用交互,输入问题并按回车键,等待RAG应用返回结果;或者输入q并按回车键,退出RAG应用。
请确保本地可以访问公网。生成回答需要一定时间,请耐心等待执行完成。
代码解析
rag.py
Settings.llm = DashScope(model_name="qwen-max") :model_name参数可以传入"qwen-max"等模型名称,以设置检索引擎生成回答时调用的大模型。全部模型名称,请参考文本生成-通义千问和文本生成-通义千问-开源版。
from llama_index.core import Settings
from llama_index.llms.dashscope import DashScope
from llama_index.indices.managed.dashscope import DashScopeCloudIndex
from llama_index.core.postprocessor import SimilarityPostprocessor
from llama_index.postprocessor.dashscope_rerank import DashScopeRerank
'''
本例中构建检索引擎时,需要手动设置下列参数,请根据实际效果调整。
'''
Settings.llm = DashScope(model_name="qwen-max") # 设置检索引擎生成回答时调用的大模型。
similarity_top_k = 5 # 检索引擎找到的相似度最高的结果数
similarity_cutoff = 0.4 # 过滤检索结果时使用的最低相似度阈值
top_n = 1 # 进行重排后返回语义上相关度最高的结果数
'''
本例中构建RAG应用时,设置如下问答模板,请根据实际需求调整。
'''
init_chat = "\n您好,我是AI助手,可以回答关于百炼系列产品的提问。有什么可以帮您的?(请输入问题,退出请输入'q')\n> "
resp_with_no_answer = "很抱歉,知识库未提供相关信息。" + "\n"
prompt_template = "回答如下问题:{0}\n如果根据提供的信息无法回答,请返回:{1}"
def prettify_rag(resp): # 格式化输出
output = ""
output += "\n回答:{0}\n".format(resp.response)
for j in range(len(resp.source_nodes)):
output += "\n产品知识库中的相关文本:\n{0}\n".format(resp.source_nodes[j].text)
return output
'''
基于云端知识库索引,构建检索引擎,能够接收终端用户的提问,从云端知识库中检索相关的文本片段,再将提问和检索结果合并后输入到大模型,并生成回答。
RAG应用提供与终端用户的交互界面,如果无法检索到相关的文本片段,或根据检索到的文本片段无法回答终端用户的提问,则返回适当的错误信息。
'''
if __name__ == '__main__':
index = DashScopeCloudIndex("my_first_index") # 读取百炼平台上已创建的知识库索引
query_engine = index.as_query_engine( # 构建检索引擎
similarity_top_k=similarity_top_k,
node_postprocessors=[ # 默认检索结果可能不满足需求,本例中通过加入node_postprocessors对检索结果进行后处理。
SimilarityPostprocessor(similarity_cutoff=similarity_cutoff), # 过滤不满足最低相似度阈值的检索结果。
DashScopeRerank(top_n=top_n, model="gte-rerank") # 对检索结果进行重排,返回语义上相关度最高的结果。
],
response_mode="tree_summarize"
)
while True:
user_prompt = input(init_chat)
if user_prompt in ['q', 'Q']: # 当检测到终端用户输入'q'或'Q'时,退出RAG应用。
break
resp = query_engine.query(prompt_template.format(user_prompt, resp_with_no_answer))
if len(resp.source_nodes) == 0:
output = resp_with_no_answer # 如果未找到相关上下文信息,则返回适当的报错信息。
else:
output = prettify_rag(resp)
print(output)
相关文档
如果您需要查看与百炼相关的LlamaIndex API详情,请参考本目录下的内容。