
本文将介绍企业在没有向量数据的情况下,如何通过OpenSearch召回引擎版,快速搭建图像搜索服务。用户可以直接导入图片源数据,在OpenSearch内部便捷完成图片向量化、向量搜索等步骤,实现以图搜图、以文搜图等多种图像检索能力。
方案架构
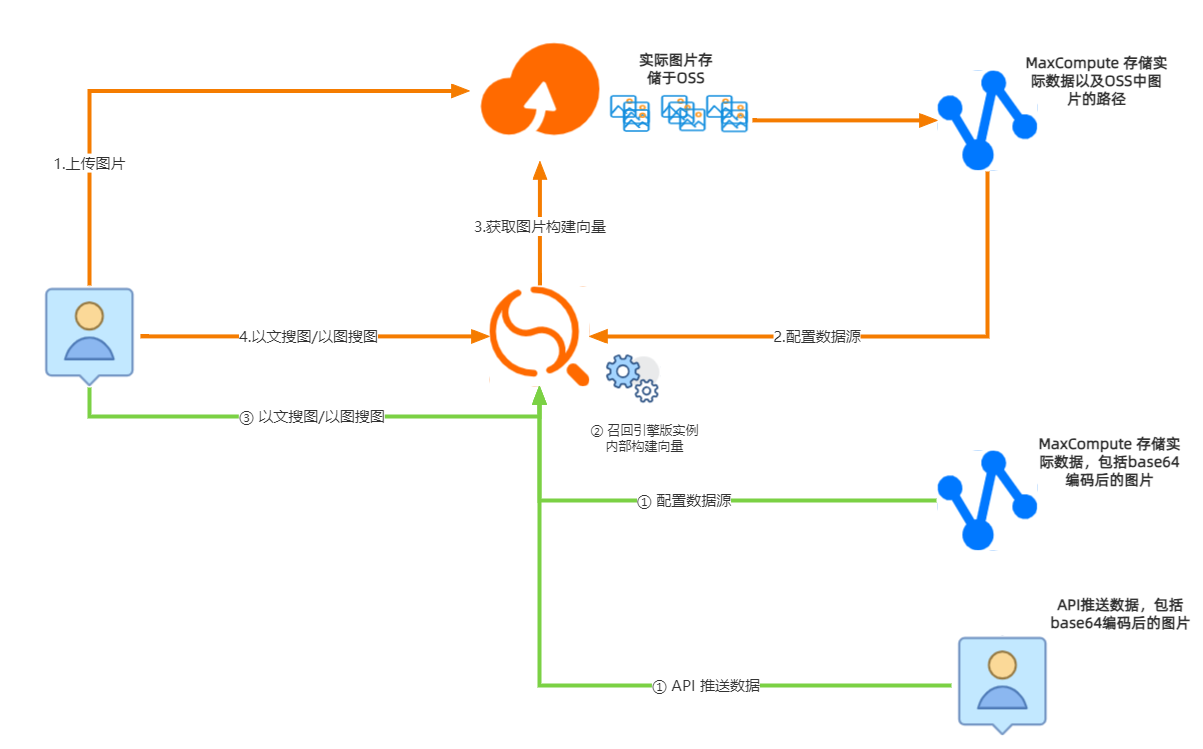
用户可以通过3种不同的方式上传图片进行图搜引擎的搭建:
OSS+MaxCompute+OpenSearch召回引擎版:用户先将图片上传至OSS中,在MaxCompute中存储业务表数据以及每条数据对应的图片地址(OSS里的路径,比如/image/1.jpg)
MaxCompute+OpenSearch召回引擎版:用户将图片通过base64编码后的图片及其表数据存储在MaxCompute中
API+OpenSearch召回引擎版:用户通过OpenSearch召回引擎版给出的数据推送接口,将base64编码后的图片及其表数据推送到OpenSearch召回引擎版实例中
本文演示的是OSS+MaxCompute+OpenSearch召回引擎版搭建图搜引擎。
环境准备
1、创建AK和SK
第一次开通阿里云账号并登录控制台时,会提示先创建AccessKey才能继续使用。
创建及使用应用依赖AccessKey参数,主账号下AccessKey参数不能为空。
在为主账号创建AccessKey参数后,还可以再创建RAM子账号AccessKey通过RAM子账号进行访问,RAM子账号赋予对应访问权限,请参考RAM(子账号)的创建及授权。
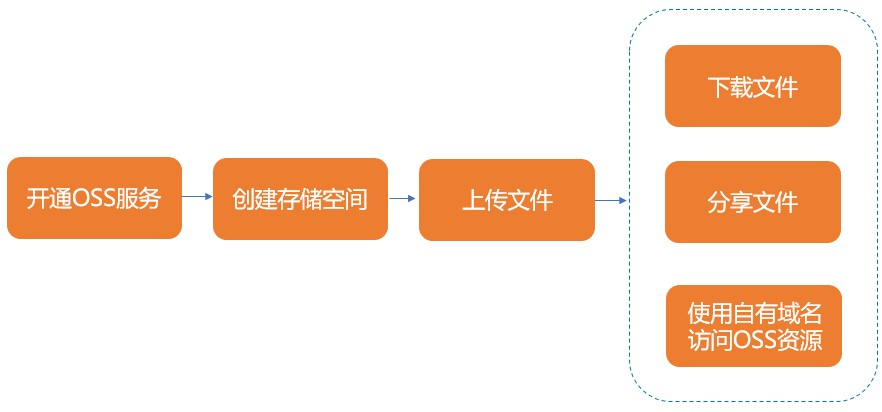
2、创建对象存储OSS
本文在OSS中上传了1000张图片:
路径为:/test/images/
部分图片类型如下:
购买OpenSearch召回引擎版实例
购买实例可参考购买OpenSearch召回引擎版实例。
配置实例
新购买的实例,在其详情页中,实例状态为“待配置”,并且会自动部署一个与购买的查询节点和数据节点的个数及规格一致的空集群,之后需要为该集群配置数据源--->索引结构--->索引重建,之后才可正常搜索,点击操作栏下的“配置”按钮。

配置数据源
配置数据源(目前支持的数据源有“MaxCompute数据源”和“API推送数据源”和“OSS数据源”)这里以MaxCompute数据源为例:点击“添加数据源”,数据源类型选择“MaxCompute”,设置project、AccessKey ID、AccessKey Secret、Table、分组键partition,可按需选择是否开启“自动索引重建”:
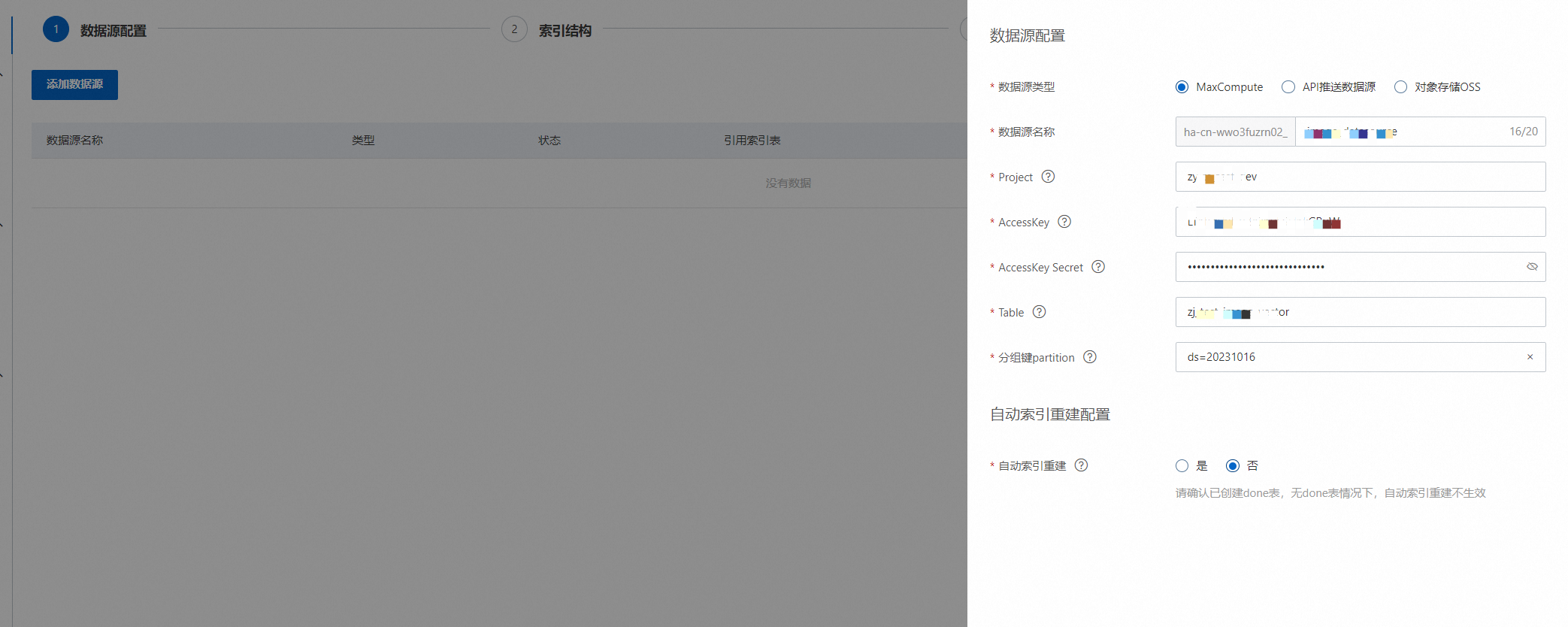
校验成功之后,点击“确定”,完成数据源的添加,等待数据源创建成功:

配置索引结构
数据源配置成功后,需点击下一步配置索引结构:

添加索引表:

配置索引表,填写索引表名称,选择1中的数据源,设置数据分片默认为1:

如果设置了MaxCompute数据源,会自动映射数据源字段:
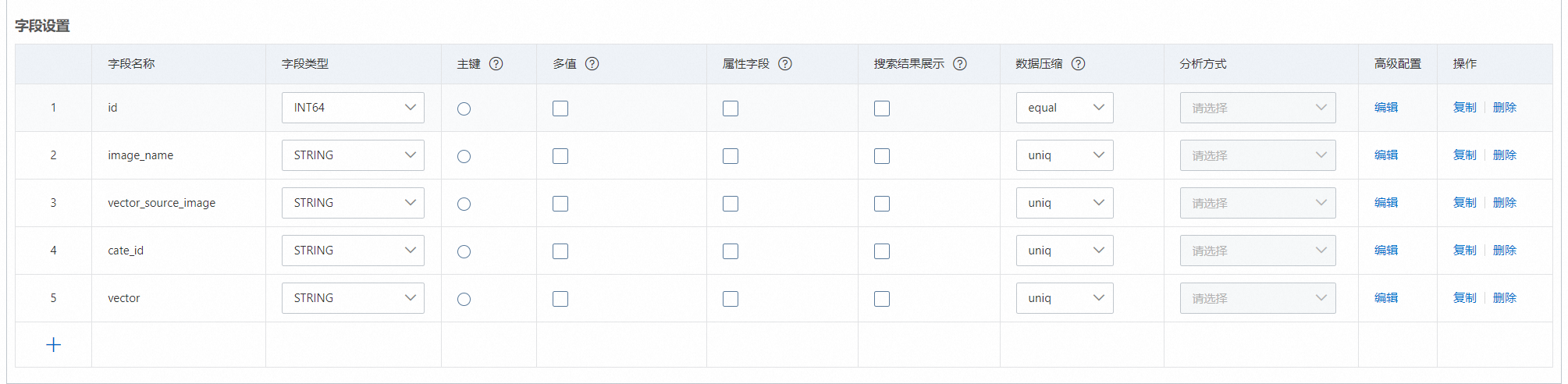
字段设置,端到端图搜方案是通过系统将图片转换成向量,然后通过向量进行检索数据,因此此处需要配置3个字段,如上图(名称均可以自定义):
主键字段:类型可以为STRING或者整数类型,需要勾选主键

vector_source_image:存储OSS中的图片路径,本文中为:/test/images/10031.png,其中高级配置如下:

高级版配置如下:
{ "content_type": "oss", "oss_endpoint": "oss-cn-hangzhou-internal.aliyuncs.com", "oss_bucket": "oss的bucket名称,本文中为test-image-vector" "crop": "true", //图片转向量, 使用oss图片转向量时传值,并且值为“true” "oss_use_slr": "true",//使用服务关联角色(slr)方式访问oss相关api,必须为字符串类型的true "uid": ""//阿里云账号uid }vector:图片转向量后存储向量的字段,该字段需要设置为FLOAT类型,同时勾选多值:

高级版配置如下:
{ "vector_model": "clip", "vector_modal": "image", "vector_source_field": "vector_source_image" }vector_model表示向量化模型,系统提供2种向量化模型:
clip:通用图片转向量模型;
clip_ecom:电商增强图片转向量模型
vector_modal:固定位image;
vector_source_field:需要向量化的图片字段,本文中为vector_source_image
索引设置,必要设置的索引为主键索引和向量索引:

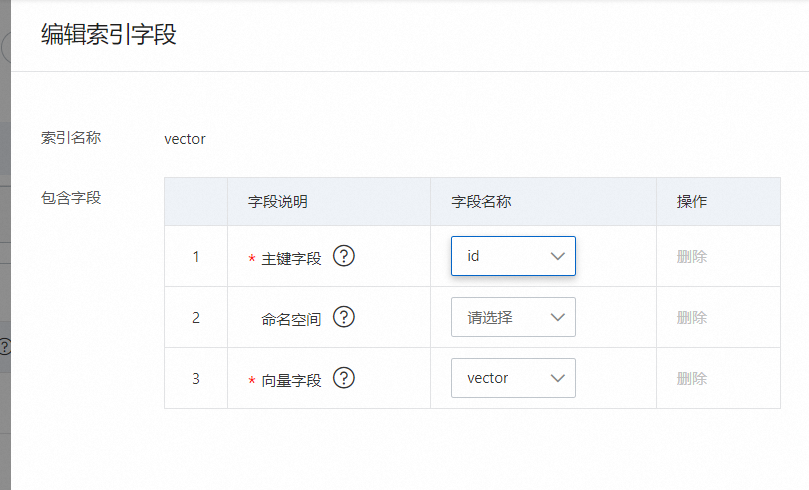
主键索引:名称自定义,索引类型选择PRIMARYKEY64,包含字段选择字段设置中设置为主键的字段,此处为id;
向量索引:名称自定义,索引类型选择CUSTOMIZED,包含字段可选择3个,如果没有标签可以不填,但是主键字段和向量字段必选:
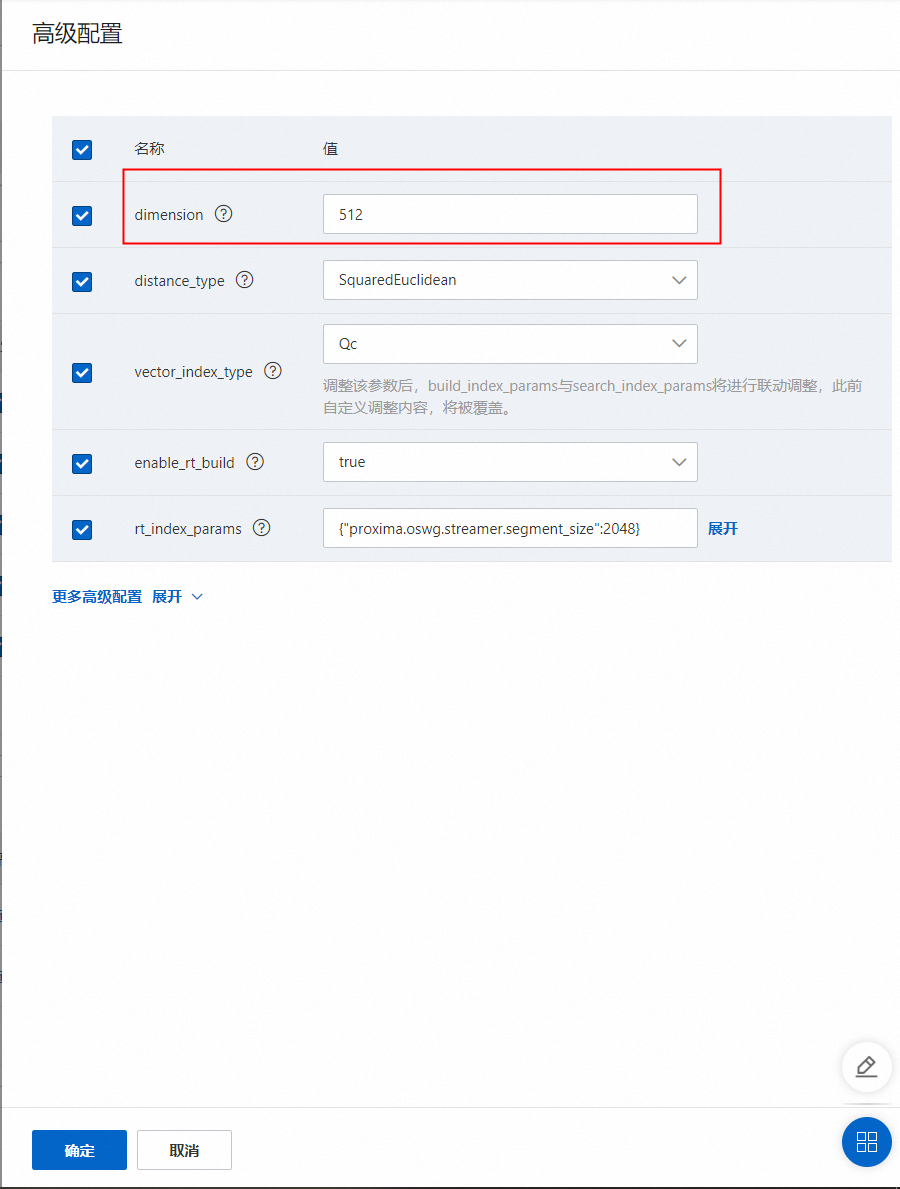
向量索引的高级配置中需要将dimension改成512维,固定512维不可修改为其他维度,其他参数建议保持默认:
schema示例:
"fields": [ { "field_name": "id", "field_type": "INT64", "compress_type": "equal" }, { "user_defined_param": { "content_type": "oss", "oss_endpoint": "", "oss_bucket": "OSS的Bucket名称", "oss_secret": "可以访问OSS的账号SK", "oss_access_key": "可以访问OSS的账号AK" }, "field_name": "vector_source_image", "field_type": "STRING", "compress_type": "uniq" }, { "field_name": "cate_id", "field_type": "INT64", "compress_type": "equal" }, { "user_defined_param": { "vector_model": "clip", "vector_modal": "image", "vector_source_field": "vector_source_image" }, "field_name": "vector", "field_type": "FLOAT", "multi_value": true } ]配置完成索引表之后,点击发布:
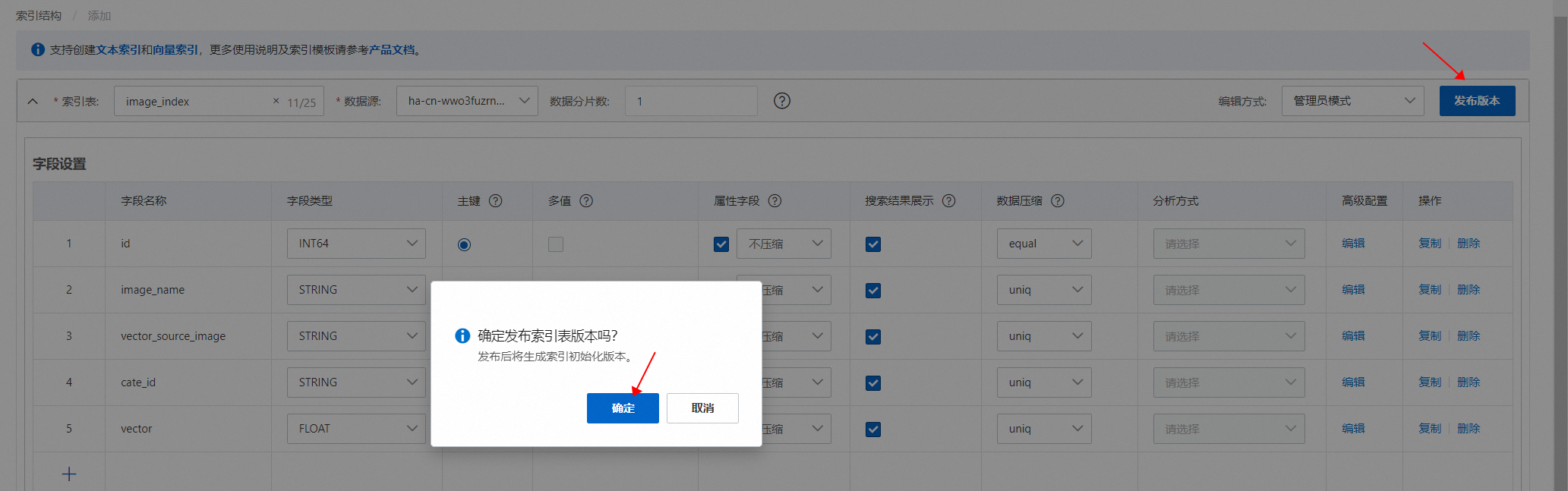
等待索引表创建完成,点击“下一步”:

索引重建
等待索引表创建完成后,点击下一步:

选择数据源名称、数据分区、时间戳,点击“下一步”:
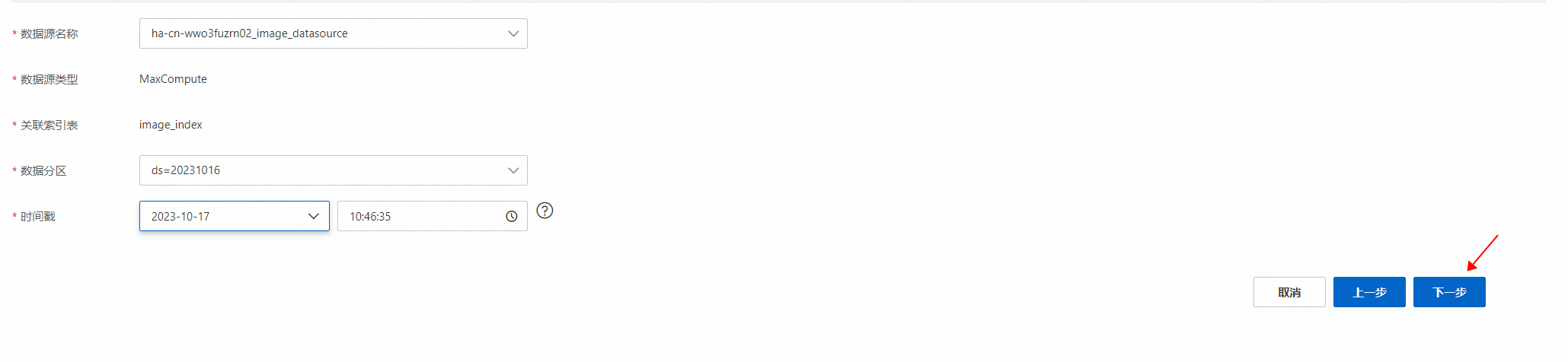
实例配置完成后,点击确定:
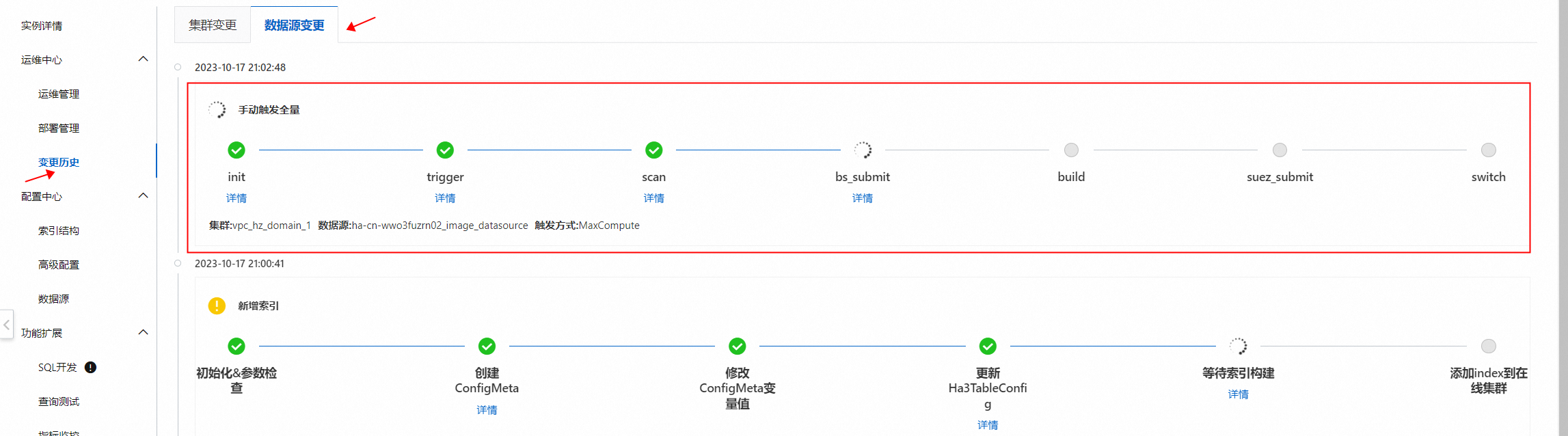
在变更历史>数据源变更中,等待手动触发全量完成,即可进行查询:
效果测试
语法介绍
query=image_index:'需要搜索的文本内容&modal=text&n=10&search_params={}'&&kvpairs=formula:proxima_score(vector)&&sort=+RANKmodal表示模态类型,以文搜图modal设置为text,以图搜图modal设置为image
n表示指定向量检索返回的top结果数
以文搜图
在查询测试页面通过HA查询:
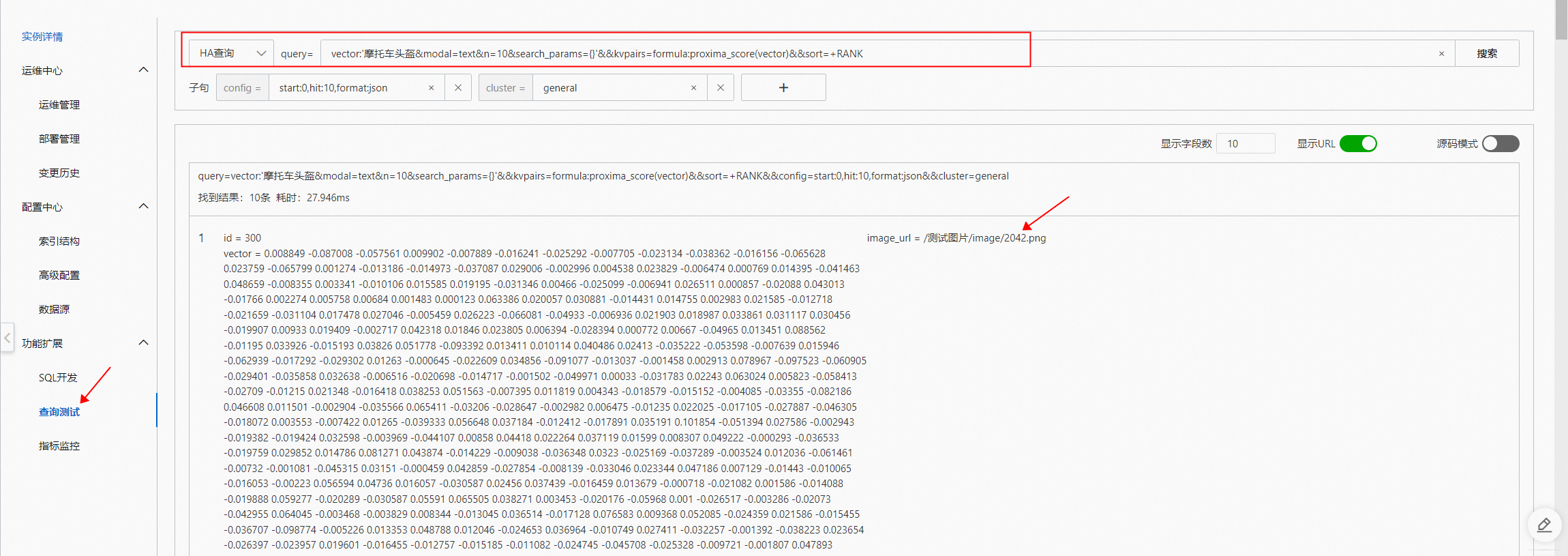
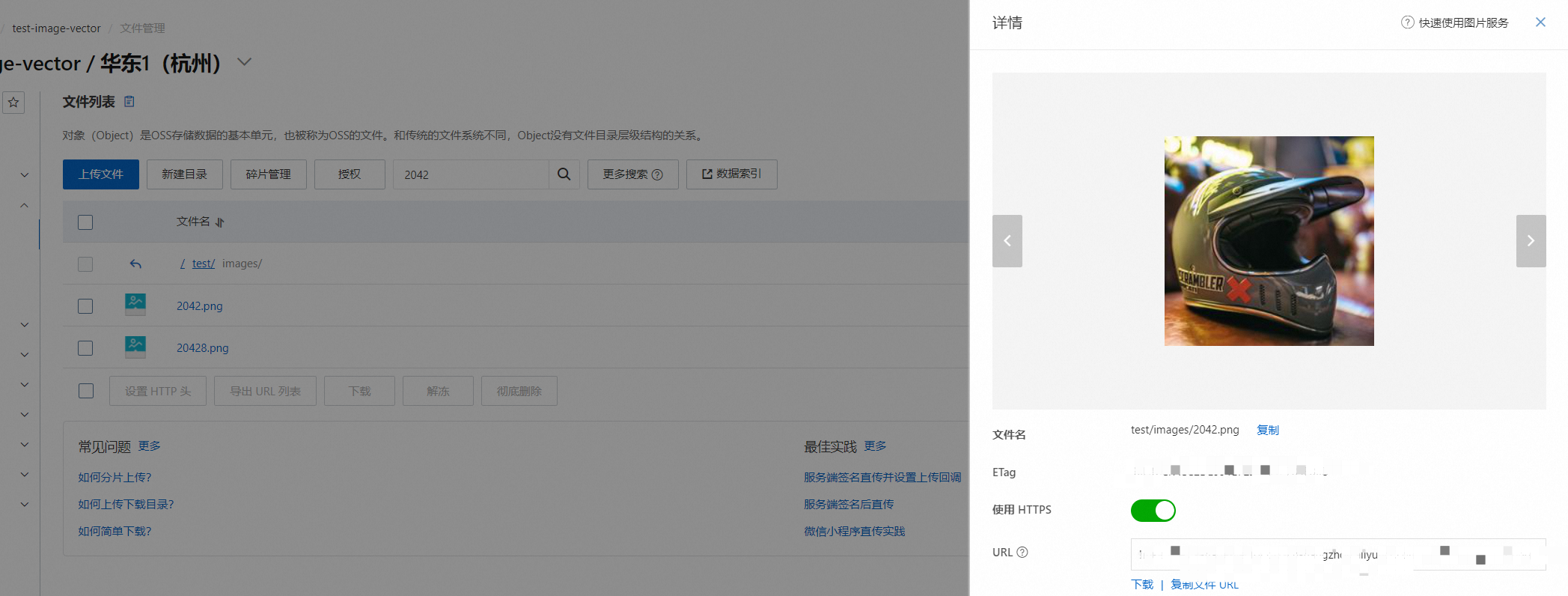
vector:'摩托车头盔&modal=text&n=10&search_params={}'&&kvpairs=formula:proxima_score(vector)&&sort=+RANK在OSS中查看2042.png 图片:
如果搜索的文本内容中特殊字符,需要进行base64编码,例如搜索内容为“摩托车&头盔”,则需要进行base64编码,结果为“5pGp5omY6L2mJuWktOeblA==”
控制台查询测试用法参考:查询测试
以图搜图
由于图片编码后长度比较大,暂不支持直接在控制台查询测试页面进行搜索。用户可以通过SDK进行检索。
示例:
vector:'base64编码后的图片&modal=image&n=10&search_params={}'&&kvpairs=formula:proxima_score(vector)&&sort=+RANKSDK中检索数据
添加依赖:
pip install alibabacloud-ha3engine搜索 demo:
# -*- coding: utf-8 -*-
from alibabacloud_ha3engine import models, client
from alibabacloud_tea_util import models as util_models
from Tea.exceptions import TeaException, RetryError
def search():
Config = models.Config(
endpoint="参考实例详情页>API入口下的API域名",
instance_id="",
protocol="http",
access_user_name="购买实例时设置的用户名",
access_pass_word="购买实例时设置的密码"
)
# 如用户请求时间较长. 可通过此配置增加请求等待时间. 单位 ms
# 此参数可在 search_with_options 方法中使用
runtime = util_models.RuntimeOptions(
connect_timeout=5000,
read_timeout=10000,
autoretry=False,
ignore_ssl=False,
max_idle_conns=50
)
# 初始化 Ha3Engine Client
ha3EngineClient = client.Client(Config)
optionsHeaders = {}
try:
# 示例1: 直接使用 ha 查询串进行搜索.
# =====================================================
query_str = "config=hit:4,format:json,fetch_summary_type:pk,qrs_chain:search&&query=image_index:'需要搜索的文本内容&modal=text&n=10&search_params={}'&&cluster=general"
haSearchQuery = models.SearchQuery(query=query_str)
haSearchRequestModel = models.SearchRequestModel(optionsHeaders, haSearchQuery)
hastrSearchResponseModel = ha3EngineClient.search(haSearchRequestModel)
print(hastrSearchResponseModel)
except TeaException as e:
print(f"send request with TeaException : {e}")
except RetryError as e:
print(f"send request with Connection Exception : {e}")其他SDK demo可参考开发指南
注意事项
如果对向量检索耗时有较严格的要求,建议向量索引lock内存
存储图片路径或者图片base64编码的字段需要设置为STRING
向量索引需要设置为CUSTOMIZED类型
该场景支持HA语法、RESTFUL API,不支持SQL