
OpenSearch-召回引擎版是阿里巴巴自主研发的大规模分布式搜索引擎,支持了淘宝、天猫、菜鸟、优酷乃至海外电商在内整个集团的搜索业务,同时也支撑了阿里云上的开放搜索业务。OpenSearch-召回引擎版经过多年的发展,在满足业务高可用、高时效性、低成本等需求的同时,也沉淀出一套自动化运维系统,使用它用户可以根据自己的业务特点方便的构建自己的搜索服务。
产品架构
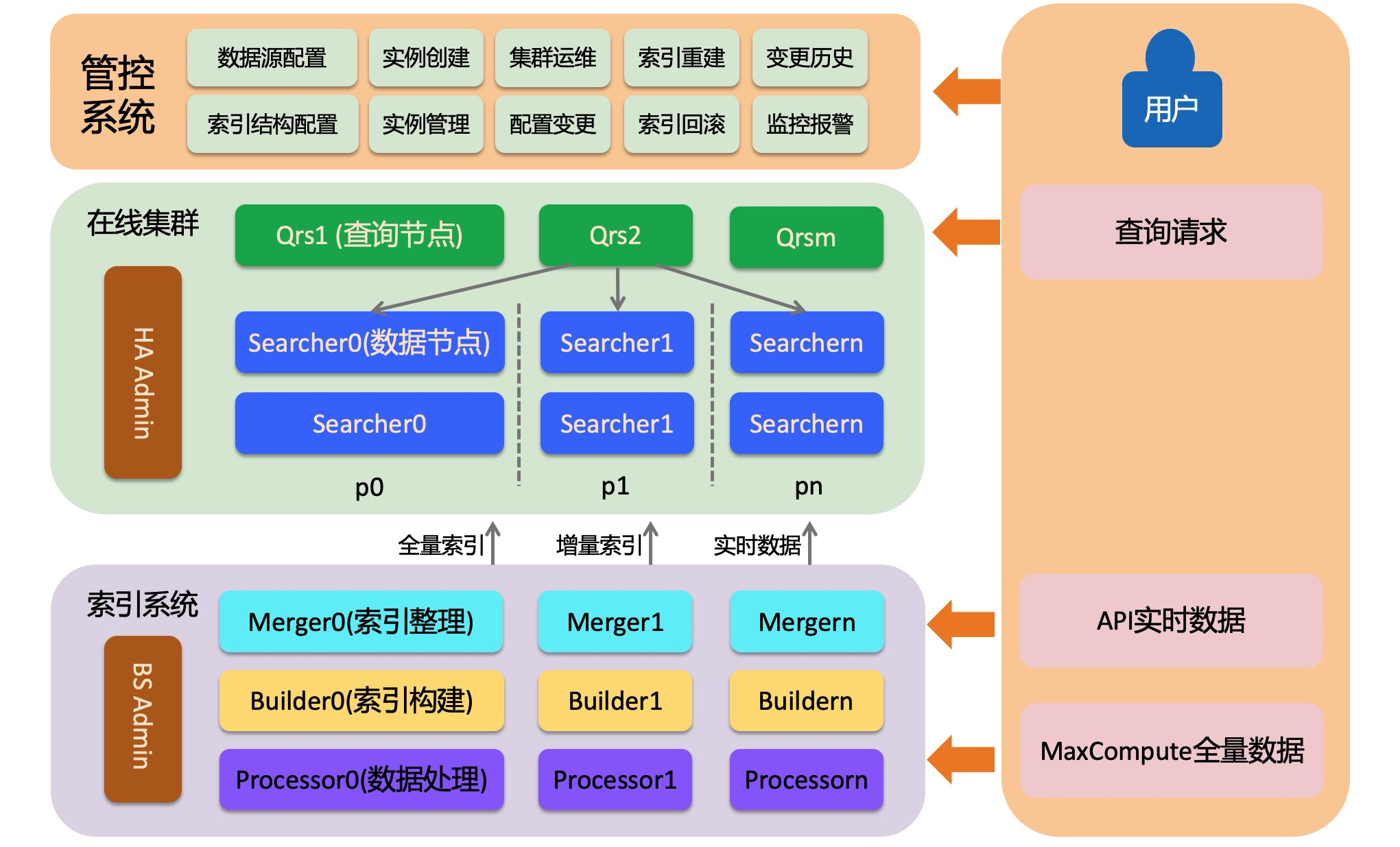
OpenSearch-召回引擎版主要有三部分构成,在线系统、离线索引构建系统、管控系统。在线系统加载索引,并提供检索服务;离线索引构建系统将用户的数据构建成索引,包括全量索引、批次增量索引、实时索引;管控系统为用户提供自动化运维服务,方便用户创建集群并对集群进行各种运维操作。
在线系统
在线系统是一个分布式检索系统,由三个角色构成:admin、qrs和searcher,下面分别介绍:
HA Admin
HA Admin是在线系统的大脑,每个物理集群都会有最少一个admin。HA admin负责接受管控系统的命令,并根据命令向Qrs和Searcher发送各种运维指令。另外admin还会实时监控Qrs和Searcher节点的运行情况,对于心跳异常的节点admin会自动替换。
Qrs(查询节点)
Qrs也叫查询节点或者查询与结果处理节点,它对输入的查询请求进行解析、校验或者改写,并将解析之后的请求转发给Searcher执行,收集并合并Searcher返回的结果,加工之后返回给用户。查询节点是一个计算型节点,不加载用户的数据,一般不需要太多的内存,但是当返回的文档个数较多或者统计产出的条目过多时才会消耗大量内存。如果查询节点的处理能力达到瓶颈,可以扩充查询节点的备份数或者扩查询节点的规格。
Searcher(数据节点)
Searcher加载用户的索引数据并根据查询检索文档、对文档进行过滤、统计、排序等操作。Searcher上的索引是可以分片的,分片的含义是将分片字段哈希到[0,65535]之间,将这个区间分成指定的片数(构建索引时指定)。这样对于数据量较大或者对查询性能有要求的集群,就可以通过分片提高单次请求的处理性能。如果想提高整个集群的处理能力(比如从支持1000 qps提升到10000 qps),可以通过扩展备份的方式进行。扩展备份不是只扩展一个Searcher节点,而是扩展承载所有数据的多个Searcher节点(多个分片要做成完整的[0,65535]区间)。
离线索引构建系统
OpenSearch-召回引擎版是一个读写分离的搜索引擎,数据的写入不影响在线检索服务,所以能够在支撑大批量数据实时写入的同时,也能保证查询服务足够稳定。索引构建系统主要包括两个流程(全量和增量),每个流程中都会有三个角色来处理数据、构建索引。
全量流程
OpenSearch-召回引擎版的索引是支持多版本的,每个索引版本都会基于一份原始数据来构建(API数据源默认为空数据),在第一次构建时启动的就是全量流程。全量流程是一个非常驻任务,数据处理完成,产出一份全量索引,全量流程结束。产出的全量索引通过全量切换,切换到在线集群提供检索服务,后续的增量数据更新都是更新到新产出的全量版本中。目前全量任务仅支持从MaxCompute数据源或者HDFS数据源中读取全量数据。
多索引版本的支持可以保证数据变更的稳定性,当索引结构变化或者数据结构发生变化时,通过全量产出新的索引是和老版本的索引完全隔离的,如果变更有问题可以及时回滚。
全量索引的产出需要经过数据处理,索引构建,索引合并等流程,在各个阶段可以通过设置索引处理的并发度提高全量索引的产出速度。
增量流程
全量索引产出之后,后续数据的更新都需要通过API推送完成。API推送的数据有两条处理链路:经过Processor处理之后直接推送到数据节点在内存中构建实时索引;处理之后的数据经过Builder和Merger构建出增量索引,通过增量切换的形式切换到数据节点。增量切换时会清理内存中的实时索引,将增量中已经包含的数据从实时内存中删除,减轻数据节点内存压力。
增量流程是一个常驻任务,每一个索引表都会对应一个增量流程,可以通过控制增量流程各个节点的并发度来提高实时数据的处理能力。
Processor
Processor处理原始文档,主要包括分词或者根据业务逻辑对字段内容进行改写。Processor在增量流程中是一个常驻的分布式服务,可以通过配置调节Processor的并发度来提高数据处理能力。Processor中支持配置多个数据处理插件,目前尚未对外开放,如果有需求可以联系我们。
Builder
Builder将处理之后的文档构建成索引。Builder不是一个常驻任务,它和Merger交替执行,每次Build完一次数据后,就会启动依赖Merger任务对索引进行整理,整理之后的索引才会切换到数据节点。
Merger
Merger将Builder产出的索引数据做合并整理,使产出的索引更加的整齐紧凑。随着数据更新,老的索引中必然会有很多被标记删除的数据,Merger会按照指定的索引合并策略将这些数据进行清理合并。
召回引擎版索引结构
|-- generation_0
|-- partition_0_32767
|-- index_format_version
|-- index_partition_meta
|-- schema.json
|-- version.0
|-- segment_0
|-- segment_info
|-- attribute
|-- deletionmap
|-- index
|-- summary
|-- segment_1
|-- segment_info
|-- attribute
|-- deletionmap
|-- index
|-- summary
|-- partition_32768_65535
|-- index_format_version
|-- index_partition_meta
|-- schema.json
|-- version.0
|-- segment_0
|-- segment_info
|-- attribute
|-- deletionmap
|-- index
|-- summary
|-- segment_1
|-- segment_info
|-- attribute
|-- deletionmap
|-- index
|-- summary结构名称 | 说明 |
generation | generation_x是引擎区分不同版本全量索引的标识。 |
partition | partition是searcher加载索引的基本单位。如果一个partition中数据过多,会导致searcher性能降低。线上数据一般通过划分多个partition的方式来保证每个searcher的检索效率。 |
schema.json | 索引配置文件。主要记录fields,index, attribute 和summary等信息。引擎通过该文件来加载索引。 |
version.0 | version文件。主要记录当前partition中引擎需要加载的segment和最新doc的时间戳。在实时build中,引擎会根据增量version的时间戳过滤旧的原始文档。 |
segment | segment是索引组成的基本单位。segment中包含了文档的倒排和正排结构。index builder每次dump都会生成一个segment。多个segment可以通过merge策略进行合并。一个partition中可用的segment在version文件中指明。 |
segment_info | segment信息摘要。记录了当前segment中文档数目,当前segment是否merge过,locator信息和最新doc时间戳信息。 |
index | 倒排索引目录。 |
attribute | 正排索引目录。 |
deletionmap | 删除的doc记录。 |
summary | 摘要索引目录。 |
管控系统
管控系统是一个OpenSearch-召回引擎版实例的运维平台,这个平台大大节省了我们的运维成本,关于这个运维平台的介绍请参考召回引擎版产品文档。
产品特性
稳定
召回引擎版底层采用C++实现,经过十多年的发展,支撑了多个核心业务,非常稳定,非常适用于对稳定性要求较高的核心搜索场景。
高效
OpenSearch-召回引擎版是一个分布式搜索引擎,可以高效的支持海量数据的检索,同时也支持数据的实时更新(秒级生效),非常适用于对查询耗时敏感、时效性要求高的搜索场景。
低成本
OpenSearch-召回引擎版支持多种索引压缩策略,同时支持多值索引加载测试,能够以较低的成本满足用户的查询需求。
功能丰富
OpenSearch-召回引擎版支持多种分析器类型、多种索引类型、强大的查询语法,能够很好的满足用户的检索需求。同时我们还提供插件机制,方便用户定制自己的业务处理逻辑。
SQL查询
OpenSearch-召回引擎版支持SQL查询语法,支持多表在线join,提供丰富的内置UDF函数和UDF函数定制机制,以满足不同用户的检索需求。在运维系统中我们即将集成SQL studio,方便用户进行SQL开发和测试。