AI搜索开放平台支持通过API的方式调用文档切片服务,您可以将服务集成到您的业务处理链路中,来提升检索或处理效率。
服务名称 | 服务ID | 服务描述 | API调用QPS限制(含主账号与RAM子账号) |
文档切片服务-001 | ops-document-split-001 | 提供通用的文本切片策略,可基于文档段落格式、文本语义、指定规则,对html, markdown, txt格式的结构化数据进行拆分,同时支持富文本形式提取代码,图片,表格。 | 2 说明 如需扩充QPS,请通过工单联系技术支持协助。 |
在基于检索的生成(Retrieval-Augmented Generation,简称RAG)中,通常的做法是将待检索的文本处理成向量,并保存在向量数据库中,方便后续检索。切片服务将长文档分成较小的片段,可以很好地匹配文本向量化模型对每段文本长度的要求,从而达到将超长文档向量化的目的。
基础使用方法
切片API输入是一条纯文本的字符串以及附加配置,输出是切成片段的文本(和可能的富文本)。一共返回4个list:chunks,nodes,rich_texts,sentences。只需要将chunks list,以及rich_texts list中type!=image的content字段内容提取出来,即可作为文档切片结果进行下一步embedding。可以参考场景中心的代码模板,python代码如下:
# 提取切片结果,注意这里只用了["chunks"]和除了图片外的["rich_texts"]
doc_list = []
for chunk in document_split_result.body.result.chunks:
doc_list.append({"id": chunk.meta.get("id"), "content": chunk.content})
for rich_text in document_split_result.body.result.rich_texts:
if rich_text.meta.get("type") != "image":
doc_list.append({"id": rich_text.meta.get("id"), "content": rich_text.content})进阶使用方法
文档切片服务可将复杂的文档内容按照指定Token数量进行切分,最终形成一个由多节点组成的树形结构。树形结构可以用于RAG的retrieval阶段,补全召回切片的上下文信息,实现更高的回答准确率。
文档切片服务的逻辑是尽可能地将文本按照最宏观的结构去切分,如果此时每个切片的长度不能满足要求,那么则会递归地继续切分每个切片,直到所有的切片长度都符合要求。递归切分的过程形成了一棵切片树,其中每个叶子节点对应了一个真正的切片结果,即最终节点。
在后续的向量召回切片的过程中,您可以使用切片树的信息做上下文补全。例如,可以在模型Token数限制范围内将召回切片的同一级其他切片一同补齐,提高信息的完整度。
例如,给出一段文本
首次开通AI搜索开放平台服务成功后,系统会自动创建出一个默认的工作空间:Default。
点击创建空间。输入自定义的工作空间名称,点击确认即可。点击创建新的API-KEY后,系统会创建生成API-KEY,此处客户可以点击复制按钮将API-KEY的内容复制保存。以下是一个可能的切片树:
root (6b15)
|
+-- paragraph_node (557b)
|
+-- newline_node (ef4d)[首次开通AI搜索开放平台...Default。]
|
+-- newline_node (c618)
|
+-- sentence_node (98ce)[点击创建空间...点击确认即可。]
|
+-- sentence_node (922a)[点击创建新的API-KEY后...复制按钮将API-KEY的内容复制保存。]在指定切片最大长度的前提下,完整的切片树包含最终节点(有切片内容的节点)及中间节点(不包含任何内容,仅为逻辑节点)两种类型。整棵树会以所有节点列表的形式被返回(nodes),同时最终节点还会在一个列表中单独返回(chunks)。以下是可能出现的一些节点种类:
root:根节点
paragraph_node:段落节点,代表对于"\n\n"分隔符的切分,用于标识段落位置(示例中无\n\n,因此只有一个这样的中间节点)
newline_node:换行节点,代表对于"\n"分隔符的切分(示例中newline_node (ef4d)节点满足切片长度要求,则为最终节点;newline_node (c618)节点需进一步切分,则为中间节点)
sentence_node:句子节点,代表对于“。”的切分
subsentence_node:子句节点,代表对于“,”的切分(示例未出现)
对于以markdown和html格式输入的内容,切片服务还会将一些富文本(rich_texts)单独输出。例如html中的<img>,<table>,<code> tags. 这些富文本在切片原文中的位置将会被替换成[image_0],<table>table_0</table>, <code>code_0</code>,与此同时每个富文本块都会在rich_texts字段被返回。这样的设计方便单独召回富文本块,也可以在需要时放回原文中。每个富文本块都归属于唯一切片的最终节点chunk。
此外,为了提升短query的召回率,客户可以选择配置strategy.need_sentence=true。此时会将原文按句子做切分并单独返回sentences列表,可以作为一路独立召回。为了方便扩展sentence,每个sentence块都归属于唯一的切片的最终节点chunk。(注意这个sentences列表和上面的sentence_node没有关系)
上文加粗的chunks,nodes,rich_texts,sentences就是API返回的全部字段了,您可以在下面的参数描述中找到详细用法。为了切片的简洁性,输出的每个切片使用的是简化版的html语法。
前提条件
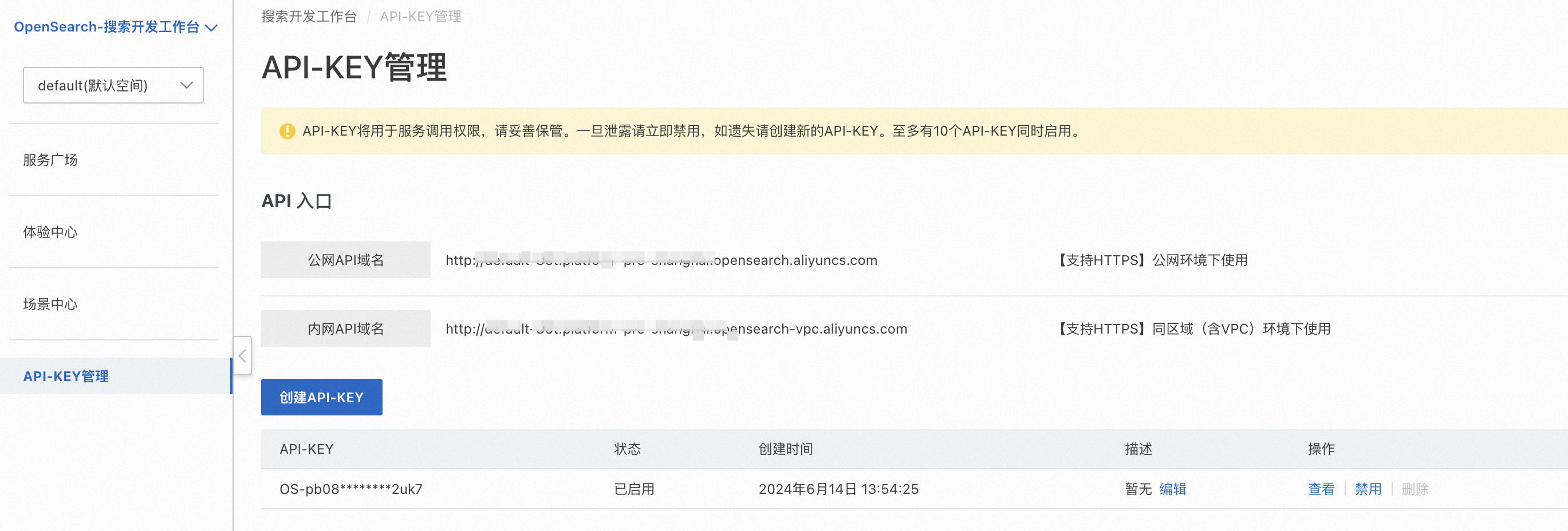
获取身份鉴权信息
通过API调用AI搜索开放平台服务时,需要对调用者身份进行鉴权,如何获取鉴权信息请参见获取API-KEY。
获取服务调用地址
支持通过公网和VPC两种方式调用服务,详情请参见获取服务接入地址。
请求说明
公共说明
请求body最大不能超过8MB。
请求方式
POST
URL
{host}/v3/openapi/workspaces/{workspace_name}/document-split/{service_id} host:调用服务的地址,支持通过公网和VPC两种方式调用API服务,可参见获取服务接入地址。
workspace_name:工作空间名称,例如default。
service_id: 系统内置服务id,例如ops-document-split-001。
请求参数
Header参数
API-KEY认证
参数 | 类型 | 必填 | 描述 | 示例值 |
Content-Type | String | 是 | 请求类型:application/json | application/json |
Authorization | String | 是 | API-Key | Bearer OS-d1**2a |
Body参数
参数 | 类型 | 必填 | 描述 | 示例值 |
document.content | String | 是 | 需要切片的纯文本内容,根据JSON标准,string字段如果包含以下字符需要转义:"\\、\"、\/、\b、\f、\n、\r、\t"。常用JSON库生成的JSON 串都无需手动转义。 | "标题\n第一行\n第二行" |
document.content_encoding | String | 否 | content编码类型
| utf8 |
document.content_type | String | 否 | content格式
| html |
strategy.type | String | 否 | 段落切片策略
| default |
strategy.max_chunk_size | Int | 否 | 切片的最大长度,默认300。 | 300 |
strategy.compute_type | String | 否 | 长度计算方式
| token |
strategy.need_sentence | Boolean | 否 | 是否同时返回sentence级别切片,用于优化短query查询
| false |
补充说明:
strategy.need_sentence参数:sentence级别切片是一种独立于段落切片的策略,简单来说就是将每一句话都作为独立的切片返回。开启sentence级别切片策略后,短切片及长切片可以同时召回,作为相互补充提升整体召回率。
返回参数
参数 | 类型 | 描述 | 示例值 |
request_id | String | 系统对一次API调用赋予的唯一标识。 | B4AB89C8-B135-****-A6F8-2BAB801A2CE4 |
latency | Float/Int | 请求耗时,单位ms。 | 10 |
usage | Object | 本次调用产生的计量信息。 | "usage": { "token_count": 3072 } |
usage.token_count | Int | Token数量。 | 3072 |
result.chunks | List(Chunk) | 切片结果列表(最终节点),包含切片内容及切片标识信息。 | [{ "content" : "xxx", "meta":{'parent_id':x, 'id': x, 'type': 'text'} }] |
result.chunks[].content | String | 切片结果中的切片内容。 | "xxx" |
result.chunks[].meta | Map | 切片结果中的切片标识信息,以下字段都是string类型
| { 'parent_id': '3b94a18555c44b67b193c6ab4f****', 'id': 'c9edcb38fdf34add90d62f6bf5c6****, 'type': 'text' 'token': 10, } |
result.rich_texts | List(RichText) | 富文本输出形式,当document.content_type为markdown、html时,切片内容中的image, code, table信息会被替换为富文本形式。例如,输入content中的""图片URL会被替换为占位符"[img_69646]",对应rich_texts中id=img_69646-0的富文本切片(注意id的命名后缀) 说明 document.content_type为text时不支持该形式。 | [{ "content" : "xxx", "meta":{'belonged_chunk_id':x, 'id': x, 'type': 'table'} }] |
result.rich_texts[].content | String | 富文本输出形式中的切片内容。image的content是URL,所以不会被切分,可能超过max_chunk_size。table会被切分为表头+每一行内容的形式。code和正文的切分方法一致。 | "<table><tr>\n<th>动作</th>\n<th>说明</th>\n</tr><tr>\n<td>隐藏组件</td>\n<td>隐藏组件,不需要参数。</td>\n</tr></table>" |
result.rich_texts[].meta | Map | 富文本输出形式中的切片标识信息,字段都为string类型
| { 'type': 'table', 'belonged_chunk_id': 'f0254cb7a5144a1fb3e5e024a3****b', 'id': 'table_2-1' 'token': 10 } |
result.nodes | List(Node) | 切片树节点列表。 | [{'parent_id':x, 'id': x, 'type': 'text'}] |
result.nodes[] | Map | 切片树节点信息,字段都为string类型
| { 'id': 'f0254cb7a5144a1fb3e5e024a3****b', 'type': 'paragraph_node', 'parent_id': 'f0254cb7a5144a1fb3e5e024a3****b' } |
result.sentences(可选) | List(sentence) | request中strategy.need_sentence=true时,返回每个分片中分句的列表。 | [{ "content" : "xxx", "meta":{'belonged_chunk_id':x, 'id': x, 'type': 'sentence'} }] |
result.sentences[].content(可选) | String | 句子内容 | "123" |
result.sentences[].meta(可选) | Map | 句子信息:
| { 'id': 'f0254cb7a5144a1fb3e5e024a3****b1-1', 'type': 'sentence', 'belonged_chunk_id': 'f0254cb7a5144a1fb3e5e024a3****b', 'token': 10 } |
Curl请求示例
curl -XPOST -H"Content-Type: application/json"
"http://***-hangzhou.opensearch.aliyuncs.com/v3/openapi/workspaces/default/document-split/ops-document-split-001"
-H "Authorization: Bearer 您的API-KEY"
-d "{
\"document\":{
\"content\":\"产品优势\\n行业算法版\\n智能\\n内置丰富的定制化算法模型,并结合不同行业搜索特点,推出行业召回、排序算法,保障更优搜索效果。\\n\\n灵活、可定制\\n开发者可基于自身业务特性与数据,定制相应的算法模型、应用结构、数据处理、查询分析、排序等配置,满足个性化搜索需求,提升搜索结果点击率,实现业务快速迭代,极大缩短需求上线的周期。\\n\\n安全、稳定\\n提供7×24小时的运行维护,并以在线工单和电话报障等方式提供技术支持,具备完善的故障监控、自动告警、快速定位等一系列故障应急响应机制。基于阿里云的AccessKeyId和AccessKeySecret安全加密对,从访问接口上进行权限控制和隔离,保证用户级别的数据隔离,用户数据安全有保障。数据冗余备份,保证数据不会丢失。\\n\\n弹性伸缩\\n具备弹性扩容能力,用户可根据需要自行扩展或缩减所使用的资源。\\n\\n丰富的外围功能\\n支持热搜、底纹、下拉提示、统计报表等一系列搜索外围功能,方便用户展示及分析。\\n\\n开箱即用\\n无需运维部署集群,快速一站式接入搜索服务\\n\\n高性能检索版\\n高吞吐\\n单表支持万级别的写入TPS,秒级更新。\\n\\n安全、稳定\\n提供7×24小时的运行维护,并以在线工单和电话报障等方式提供技术支持,具备完善的故障监控、自动告警、快速定位等一系列故障应急响应机制。基于阿里云的AccessKeyId和AccessKeySecret安全加密对,从访问接口上进行权限控制和隔离,保证用户级别的数据隔离,用户数据安全有保障。数据冗余备份,保证数据不会丢失。\\n\\n弹性伸缩\\n具备弹性扩容能力,用户可根据需要自行扩展或缩减所使用的资源。\\n\\n开箱即用\\n无需运维部署集群,快速一站式接入搜索服务\\n\\n向量检索版\\n稳定\\n底层采用C++实现,经过十多年的发展,支撑了多个核心业务,非常稳定,非常适用于对稳定性要求较高的核心搜索场景。\\n\\n高效\\n分布式搜索引擎,可以高效的支持海量数据的检索,同时也支持数据的实时更新(秒级生效),非常适用于对查询耗时敏感、时效性要求高的搜索场景。\\n\\n低成本\\n支持多种索引压缩策略,同时支持多值索引加载测试,能够以较低的成本满足用户的查询需求。\\n\\n向量算法\\n支持各种非结构化数据(如语音、图片、视频,语言文字、行为等)向量检索。\\n\\nSQL查询\\n支持SQL查询语法,支持多表在线join,提供丰富的内置UDF函数和UDF函数定制机制,以满足不同用户的检索需求。在运维系统中我们已经集成SQL studio,方便用户进行SQL开发和测试。\\n\\n召回引擎版\\n稳定\\n底层采用C++实现,经过十多年的发展,支撑了多个核心业务,非常稳定,非常适用于对稳定性要求较高的核心搜索场景。\\n\\n高效\\n问天引擎是一个分布式搜索引擎,可以高效的支持海量数据的检索,同时也支持数据的实时更新(秒级生效),非常适用于对查询耗时敏感、时效性要求高的搜索场景。\\n\\n低成本\\n问天引擎支持多种索引压缩策略,同时支持多值索引加载测试,能够以较低的成本满足用户的查询需求。\\n\\n功能丰富\\n问天引擎支持多种分析器类型、多种索引类型、强大的查询语法,能够很好的满足用户的检索需求。同时我们还提供插件机制,方便用户定制自己的业务处理逻辑。\\n\\nSQL查询\\n问天引擎支持SQL查询语法,支持多表在线join,提供丰富的内置UDF函数和UDF函数定制机制,以满足不同用户的检索需求。在运维系统中我们即将集成SQL studio,方便用户进行SQL开发和测试。\",
\"content_encoding\":\"utf8\",\"content_type\":\"text\"
},
\"strategy\":{
\"type\":\"default\",
\"max_chunk_size\":300,
\"compute_type\":\"token\",
\"need_sentence\":false
}
}"响应示例
正常响应示例
{
"request_id": "47EA146B-****-448C-A1D5-50B89D7EA434",
"latency": 161,
"usage": {
"token_count": 800
},
"result": {
"chunks": [
{
"content": "产品优势\\n行业算法版\\n智能\\n内置丰富的定制化算法模型,并结合不同行业搜索特点,推出行业召回、排序算法,保障 更优搜索效果。\\n\\n灵活、可定制\\n开发者可基于自身业务特性与数据,定制相应的算法模型、应用结构、数据处理、查询分析、排序等配置,满足个性化搜索需求,提升搜索结果点击率,实现业务快速迭代,极大缩短需求上线的周期。\\n\\n安全、稳定\\n提供7×24小时的运行维护,并以在线工单和电话报障等方式提供技术支持,具备完善的故障监控、自动告警、快速定位等一系列故障应急响应机制。基于阿里云的AccessKeyId和AccessKeySecret安全加密对,从访问接口上进行权限控制和隔离,保证用户级别的数据隔离,用户 数据安全有保障。数据冗余备份,保证数据不会丢失。\\n\\n弹性伸缩\\n具备弹性扩容能力,用户可根据需要自行扩展或缩减所使用的资源。\\n\\n丰富的外围功能\\n支持热搜、底纹、下拉提示、统计报表等一系列搜索外围功能,方便用户展示及分析。\\n\\n开箱即 用\\n无需运维部署集群,快速一站式接入搜索服务\\n\\n高性能检索版\\n高吞吐\\n单表支持万级别的写入TPS,秒级更新",
"meta": {
"parent_id": "dee776dda3ff4b078bccf989a6bd****",
"id": "27eea7c6b2874cb7a5bf6c71afbf****",
"type": "text"
}
},
{
"content": "。\\n\\n安全、稳定\\n提供7×24小时的运行维护,并以在线工单和电话报障等方式提供技术支持,具备完善的故障监控、自动告警、快速定位等一系列故障应急响应机制。基于阿里云的AccessKeyId和AccessKeySecret安全加密对,从访问接口上进行权限控制和隔离,保证 用户级别的数据隔离,用户数据安全有保障。数据冗余备份,保证数据不会丢失。\\n\\n弹性伸缩\\n具备弹性扩容能力,用户可根据需要自行扩展或缩减所使用的资源。\\n\\n开箱即用\\n无需运维部署集群,快速一站式接入搜索服务\\n\\n向量检索版\\n稳定\\n底层 采用c++实现,经过十多年的发展,支撑了多个核心业务,非常稳定,非常适用于对稳定性要求较高的核心搜索场景。\\n\\n高效\\n分布式搜索引擎,可以高效的支持海量数据的检索,同时也支持数据的实时更新(秒级生效),非常适用于对查询耗时敏感、时效性要求 高的搜索场景。\\n\\n低成本\\n支持多种索引压缩策略,同时支持多值索引加载测试,能够以较低的成本满足用户的查询需求。\\n\\n向量算法\\n支持各种非结构化数据(如语音、图片、视频,语言文字、行为等)向量检索。\\n\\nSQL查询\\n支持SQL查询语法,支持多表在线join,提供丰富的内置UDF函数和UDF函数定制机制,以满足不同用户的检索需求",
"meta": {
"parent_id": "dee776dda3ff4b078bccf989a6bd****",
"id": "bf9fcfb47fcf410aa05216e268df****",
"type": "text"
}
},
{
"content": "。在运维系统中我们已经集成SQL studio,方便用户进行SQL开发和测试。\\n\\n召回引擎版\\n稳定\\n底层采用C++实现,经过十多年的发展,支撑了多个核心业务,非常稳定,非常适用于对稳定性要求较高的核心搜索场景。\\n\\n高效\\n问天引擎是一个分布式搜索引擎,可以高效的支持海量数据的检索,同时也支持数据的实时更新(秒级生效),非常适用于对查询耗时敏感、时效性要求高的搜索场景。\\n\\n低成本\\n问天引擎支持多种索引压缩策略,同时支持多值索引加载测试,能够以较低的成本满足用户的查询需求。\\n\\n功能丰富\\n问天引擎支持多种分析器类 型、多种索引类型、强大的查询语法,能够很好的满足用户的检索需求。同时我们还提供插件机制,方便用户定制自己的业务处理逻辑。\\n\\nSQL查询\\n问天引擎支持SQL查询语法,支持多表在线join,提供丰富的内置UDF函数和UDF函数定制机制,以满足不同用户的检索需求。在运维系统中我们即将集成SQL studio,方便用户进行SQL开发和测试。",
"meta": {
"parent_id": "dee776dda3ff4b078bccf989a6bd****",
"id": "26ab0e4f7665487bb0a82c5a226a****",
"type": "text"
}
}
],
"nodes": [
{
"id": "dee776dda3ff4b078bccf989a6bd****",
"type": "root",
"parent_id": "dee776dda3ff4b078bccf989a6bd****"
},
{
"id": "27eea7c6b2874cb7a5bf6c71afbf****",
"type": "sentence",
"parent_id": "dee776dda3ff4b078bccf989a6bd****"
},
{
"id": "bf9fcfb47fcf410aa05216e268df****",
"type": "sentence",
"parent_id": "dee776dda3ff4b078bccf989a6bd****"
},
{
"id": "26ab0e4f7665487bb0a82c5a226a****",
"type": "sentence",
"parent_id": "dee776dda3ff4b078bccf989a6bd****"
}
],
"rich_texts": []
}
}异常响应示例
在访问请求出错的情况下,输出的结果中会通过code和message指明出错原因。
{
"request_id": "817964CD-1B84-4AE1-9B63-4FB99734****",
"latency": 0,
"code": "InvalidParameter",
"message": "JSON parse error: Invalid UTF-8 start byte 0xbc; nested exception is com.fasterxml.jackson.core.JsonParseException: Invalid UTF-8 start byte 0xbc\n at line: 2, column: 19]"
}状态码说明
请参见AI搜索开放平台状态码说明。