
本文中含有需要您注意的重要提示信息,忽略该信息可能对您的业务造成影响,请务必仔细阅读。
索引表结构介绍
每个Document都是由多个field组成,每个field中包含一系列的词语,构建索引的目的是为了加快检索的速度,根据映射关系方向的不同,索引可以分为:
字段(field):用于定义索引表的字段名及字段类型。
倒排索引(index):倒排索引存储了从单词到DocID的映射关系,形如:词:(Doc1,Doc2,...,DocN),倒排索引主要用在检索中,它能快速的定位用户查询到关键字对应的Document。
正排索引(attribute):正排索引存储从DocID到field的映射关系,形如:DocID-->(term1,term2,...termn),正排索引分单值和多值两种,单值attribute由于长度是固定的(不包括string类型),因此查找效率高,而且可以支持更新。多值attribute表示某个field中有多个数据(数量不固定),由于长度不确定,因此查找效率相较与单值更慢,而且不能支持更新。
正排索引主要用于查询到某个 Document 后,根据 docid 快速获取其 attribute 以进行统计、排序或过滤。目前引擎支持的正排字段基本类型包括:
INT8(8位有符号数字类型), UINT8(8位无符号数字类型),
INT16(16位有符号数字类型),
UINT16(16位无符号数字类型),
INTEGER(32位有符号数字类型),
UINT32(32位无符号数字类型), INT64(64位有符号数字类型),
UINT64(64位无符号数字类型),
FLOAT(32位浮点数),
DOUBLE(64位浮点数),
STRING(字符串类型)
摘要(summary):summary的存储形式与attribute类似,但是summary是将一个Document对应的多个field存储在一起,并且建立映射,所以能很快从docid定位到对应的summary内容。summary主要是用于结果的展示,一般而言summary的内容都比较大,对于每次查询而言不适合取过多的summary,只有最终需要展示结果的Document会取到对应的summary。由于summary过大,引擎在存储summary时提供压缩的机制,在schema中配置summary压缩,那么引擎在存储时会用zlib压缩后再存储,读取时引擎会先解压,再返回给用户。
说明有关索引表配置的详细介绍的文章可参考索引表配置。
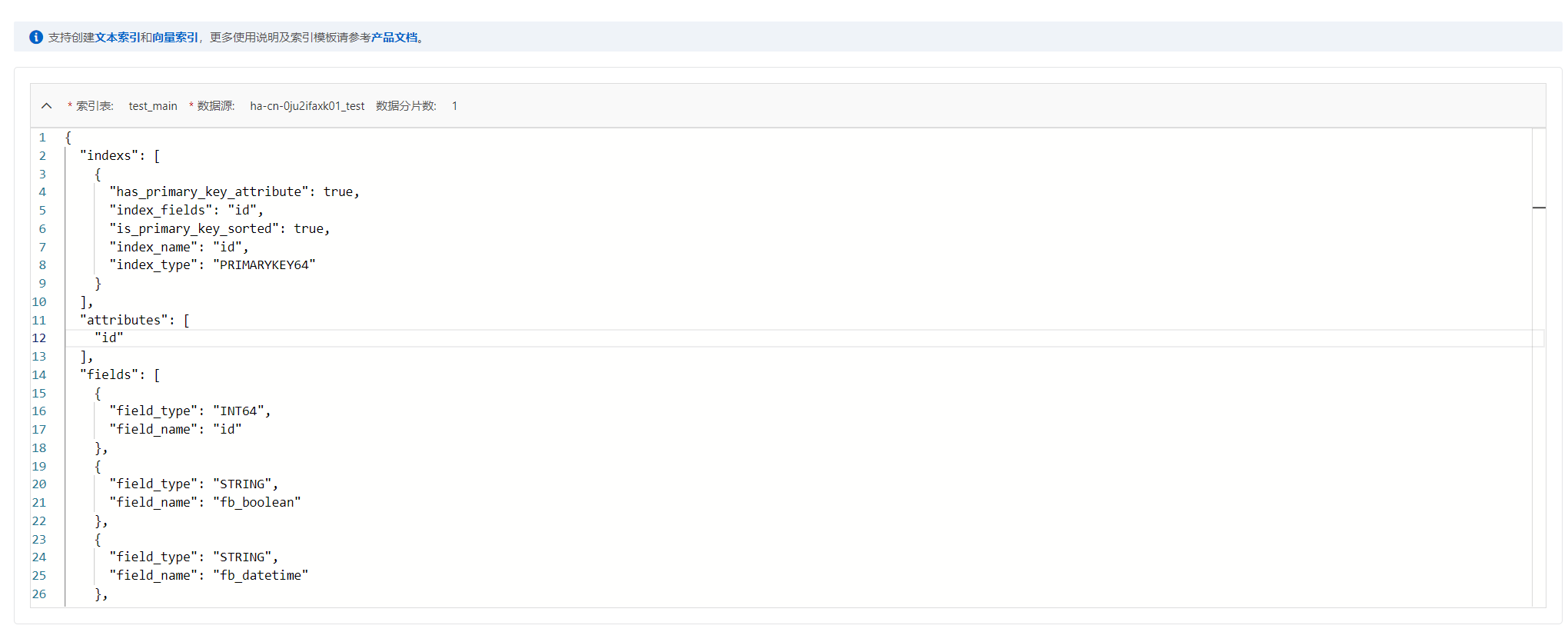
索引schema示例:
{
"summarys": {
"summary_fields": [
"pk",
"embedding",
"cate_id"
],
"parameter": {
"file_compressor": "zstd"
}
},
"indexs": [
{
"index_name": "id",
"index_type": "PRIMARYKEY64",
"index_fields": "pk",
"has_primary_key_attribute": true,
"is_primary_key_sorted": false
},
{
"index_name": "vector",
"index_type": "CUSTOMIZED",
"index_fields": [
{
"field_name": "pk",
"boost": 1
},
{
"field_name": "cate_id",
"boost": 1
},
{
"field_name": "embedding",
"boost": 1
}
],
"parameters": {
"dimension": "128",
"distance_type": "SquaredEuclidean",
"vector_index_type": "Qc",
"build_index_params": "{\"proxima.qc.builder.quantizer_class\":\"Int8QuantizerConverter\",\"proxima.qc.builder.quantize_by_centroid\":true,\"proxima.qc.builder.optimizer_class\":\"BruteForceBuilder\",\"proxima.qc.builder.thread_count\":10,\"proxima.qc.builder.optimizer_params\":{\"proxima.linear.builder.column_major_order\":true},\"proxima.qc.builder.store_original_features\":false,\"proxima.qc.builder.train_sample_count\":3000000,\"proxima.qc.builder.train_sample_ratio\":0.5}",
"search_index_params": "{\"proxima.qc.searcher.scan_ratio\":0.01}",
"embedding_delimiter": ",",
"major_order": "col",
"linear_build_threshold": "5000",
"min_scan_doc_cnt": "20000",
"enable_recall_report": "false",
"is_embedding_saved": "false",
"enable_rt_build": "false",
"builder_name": "QcBuilder",
"searcher_name": "QcSearcher"
},
"indexer": "aitheta2_indexer"
}
],
"attributes": [
{
"field_name": "pk",
"file_compress": "no_compressor"
},
{
"field_name": "embedding",
"file_compress": "no_compressor"
},
{
"field_name": "cate_id",
"file_compress": "file_compressor"
}
],
"fields": [
{
"user_defined_param": {},
"field_name": "pk",
"field_type": "INTEGER",
"compress_type": "equal"
},
{
"user_defined_param": {
"multi_value_sep": ","
},
"field_name": "embedding",
"field_type": "FLOAT",
"compress_type": "uniq",
"multi_value": true
},
{
"user_defined_param": {},
"field_name": "cate_id",
"field_type": "INTEGER",
"compress_type": "equal"
},
{
"field_name": "titile",
"field_type": "TEXT",
"analyzer": "chn_ecommerce_general"
}
],
"file_compress": [
{
"name": "file_compressor",
"type": "zstd"
},
{
"name": "no_compressor",
"type": ""
}
]
}添加索引表
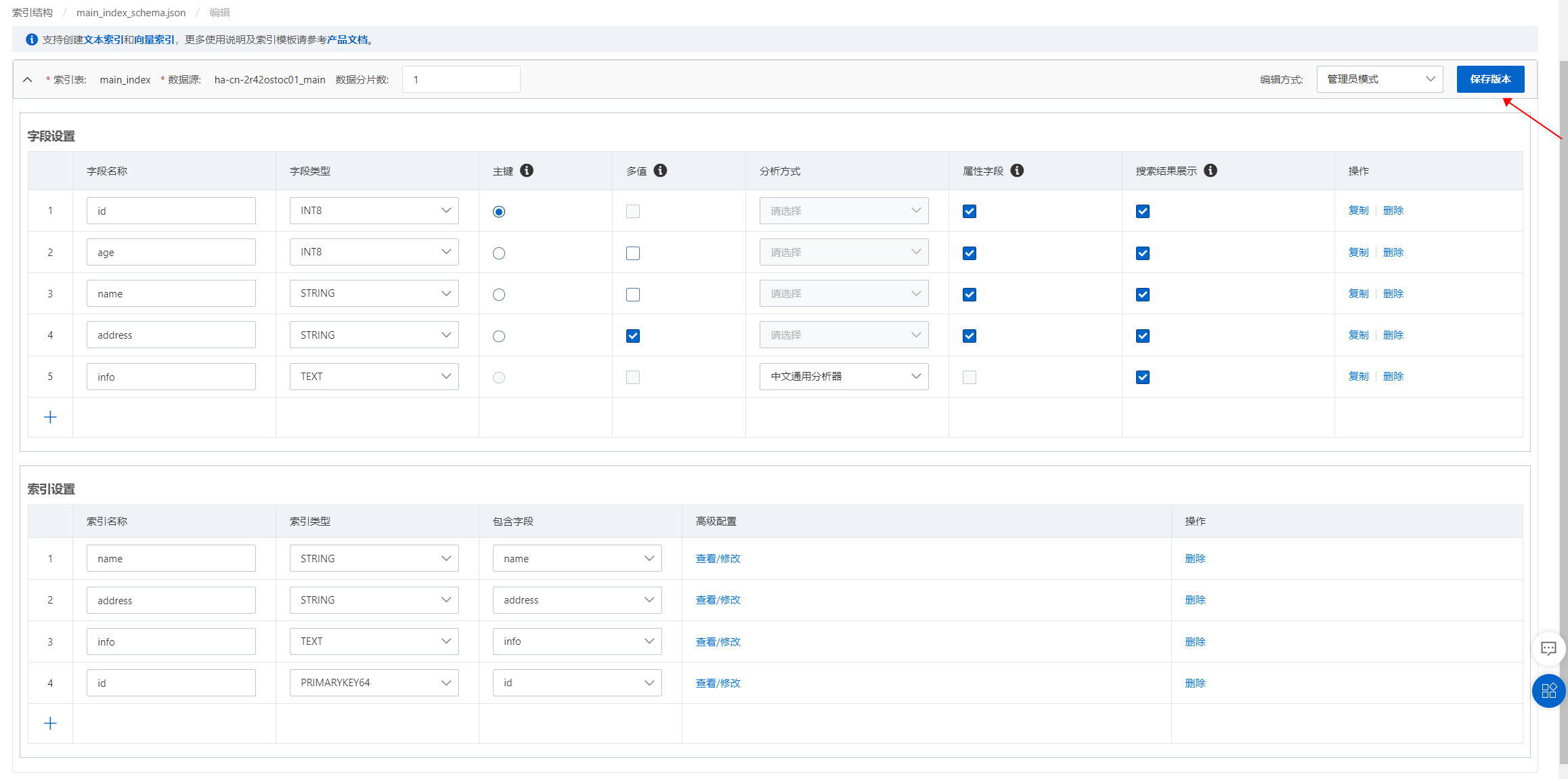
在实例管理界面,进入配置中心 > 索引结构页面,单击添加索引表。
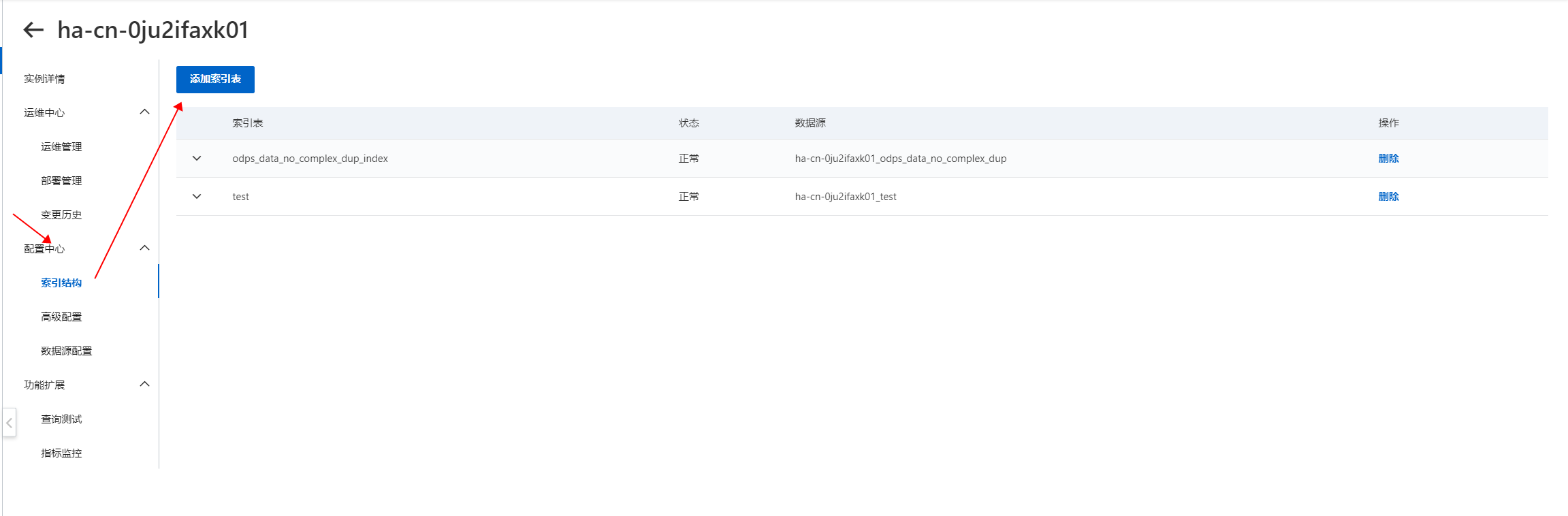
配置索引表,模板选择通用模板。
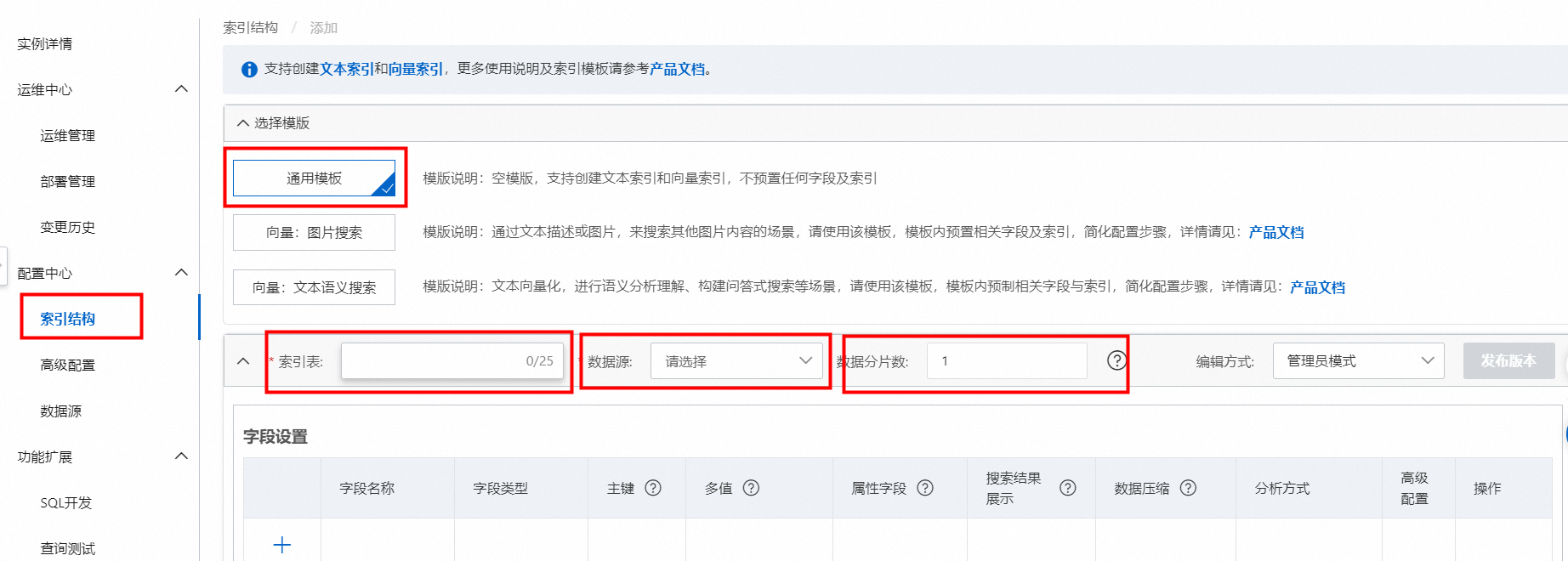
索引表:可自定义。
数据源:按需选择已添加数据源。
数据分片:根据用户购买的数据节点个数进行配置。
设置字段,至少需要定义2个字段主键字段和向量字段(向量字段需要设置为多值float类型)。

如果需要带有类目的向量,可以在主键和向量字段中间加一个类目字段,类型要求单值或多值的整数类型。

属性和字段内容压缩:
属性字段可以选择是否压缩,默认为不压缩,选择file_compressor表示开启压缩
字段内容可以选择是否压缩,默认为不压缩,默认多值和STRING类型选择uniq,单值数值类型是equal
说明使用向量检索,在定义字段时有位置要求,需要按照主键字段、标签字段(非必要)、向量字段的顺序创建(如上图所示)。
如果开启了属性压缩,建议前往「部署管理-数据节点-在线表配置」编辑索引加载方式,以此降低对性能的影响。
设置索引,主键字段索引类型设置为PRIMARYKEY64,向量索引类型选择。CUSTOMIZED:

索引字段设置压缩:
索引字段可以选择是否压缩,默认为不压缩,选择file_compressor表示开启压缩。
说明主键索引不支持压缩
如果开启了索引压缩,建议前往「部署管理-数据节点-在线表配置」编辑索引加载方式,以此降低对性能的影响
为向量字段添加包含字段:
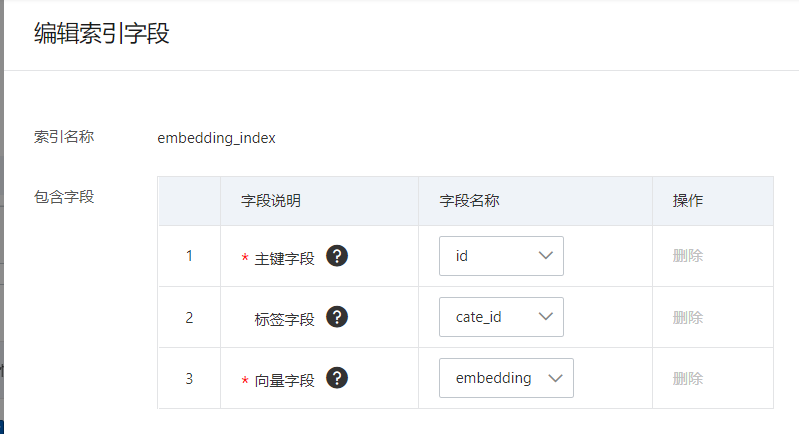 说明
说明主键字段、向量字段必须填写,标签字段非必填,可以为空。
仅支持选择固定的三个字段,不支持新增。
高级配置,向量索引需要单独配置参数,可以参考如下配置,详情可参考向量索引:
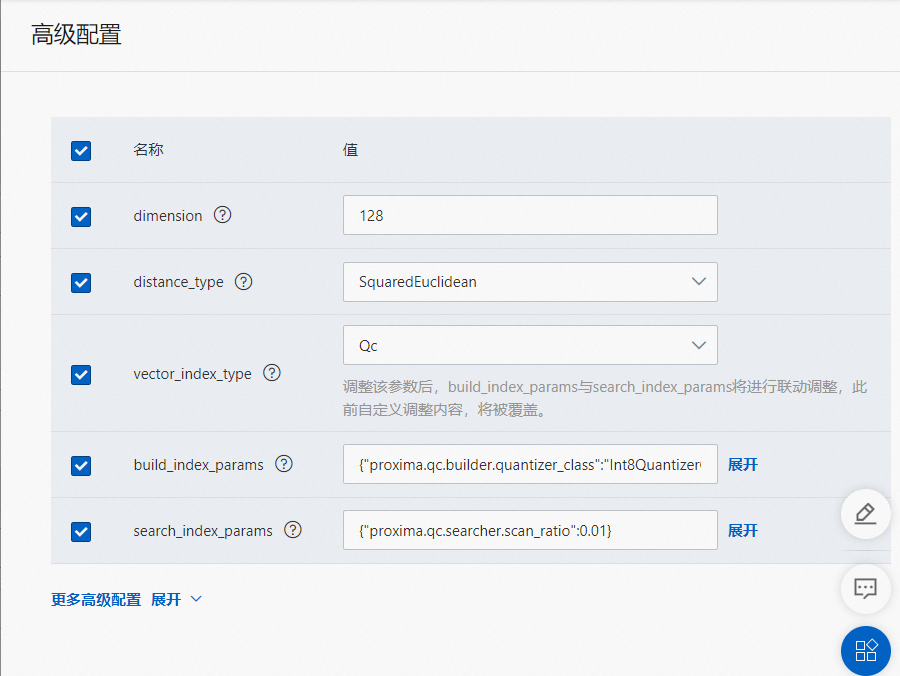
更多参数:
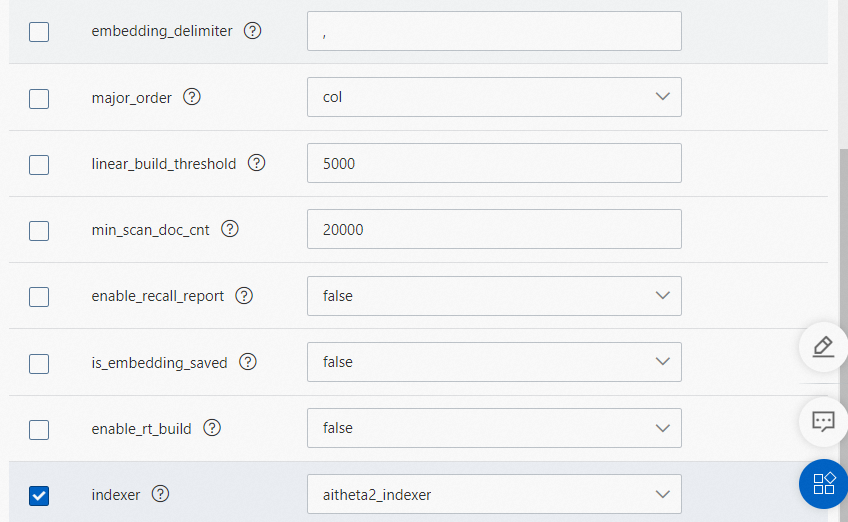
其中build_index_params的配置如下:
{ "proxima.qc.builder.quantizer_class": "Int8QuantizerConverter", "proxima.qc.builder.quantize_by_centroid": true, "proxima.qc.builder.optimizer_class": "BruteForceBuilder", "proxima.qc.builder.thread_count": 10, "proxima.qc.builder.optimizer_params": { "proxima.linear.builder.column_major_order": true }, "proxima.qc.builder.store_original_features": false, "proxima.qc.builder.train_sample_count": 3000000, "proxima.qc.builder.train_sample_ratio": 0.5 }search_index_params的配置如下:
{ "proxima.qc.searcher.scan_ratio": 0.01 }
配置完成后,单击保存版本,并在弹框后填写备注(可选),单击发布。

索引表添加成功后,可在运维中心>部署管理中查看新加的索引表的拓扑。
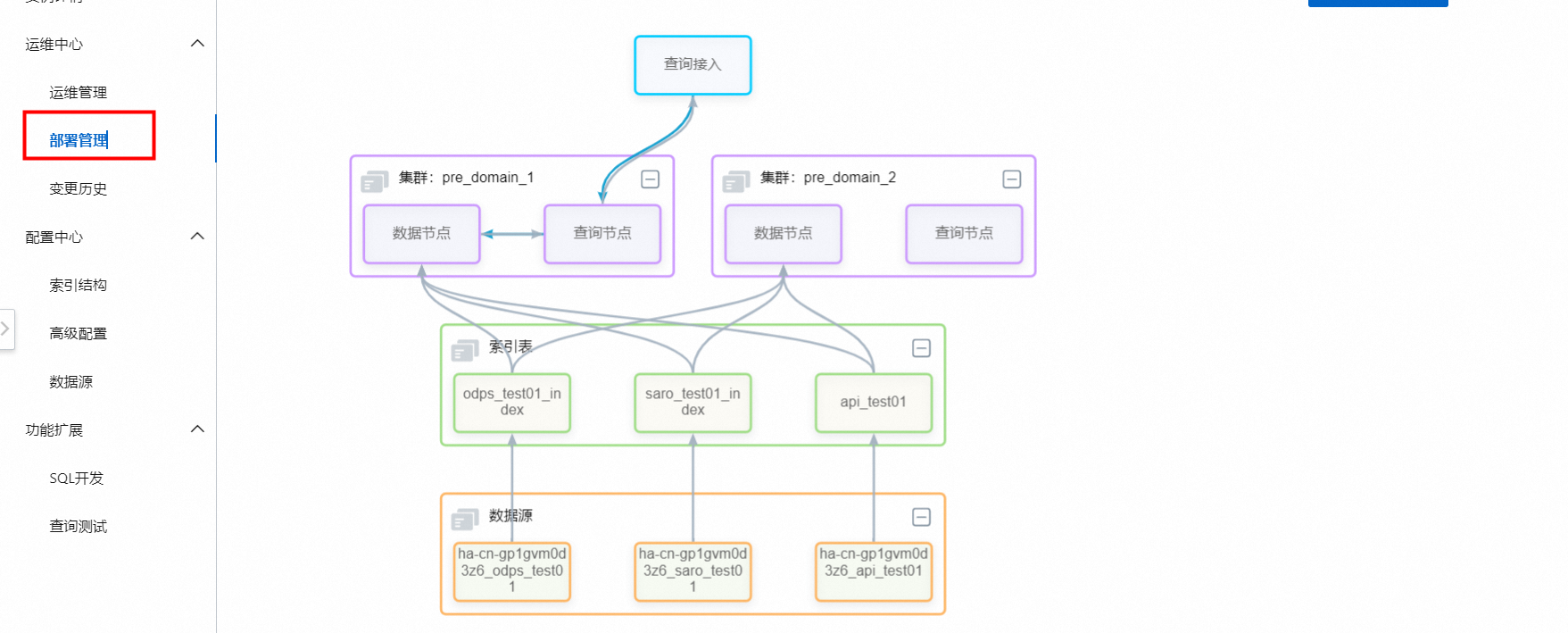
若需要新加的索引表在集群中生效,需要在运维中心>运维管理中手动触发配置更新并全量,配置更新操作中执行“推送配置并触发索引重建”。
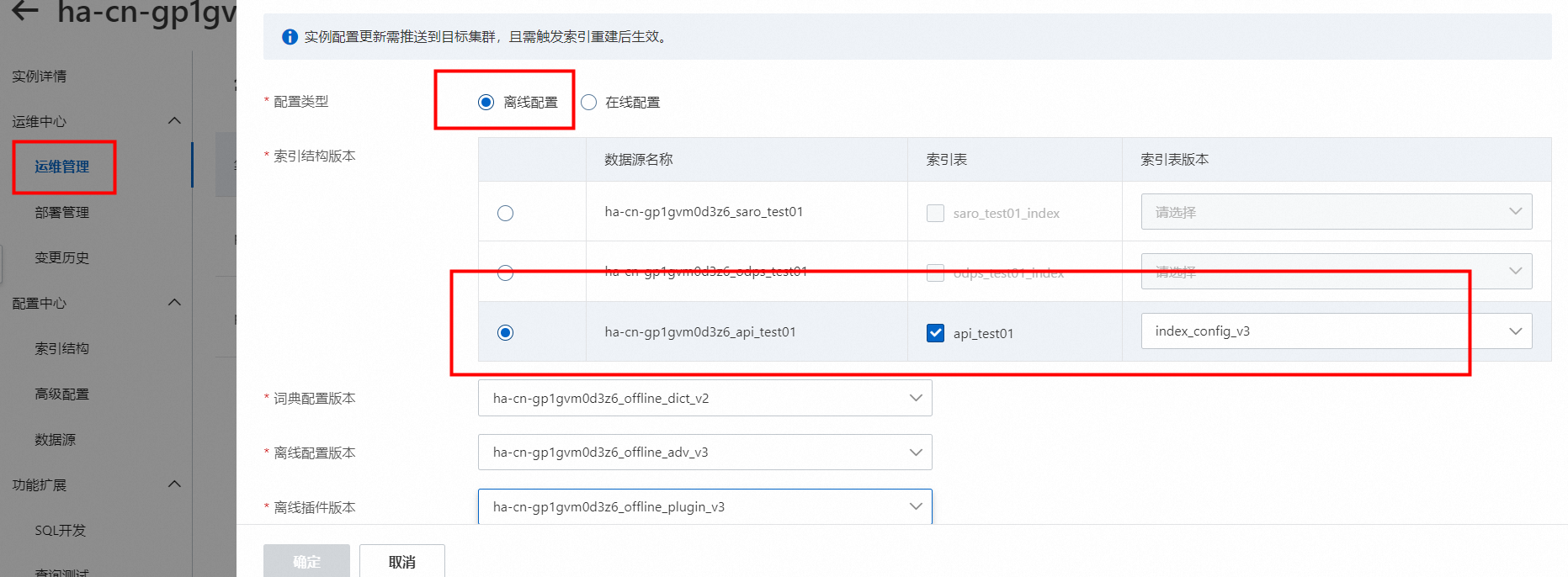
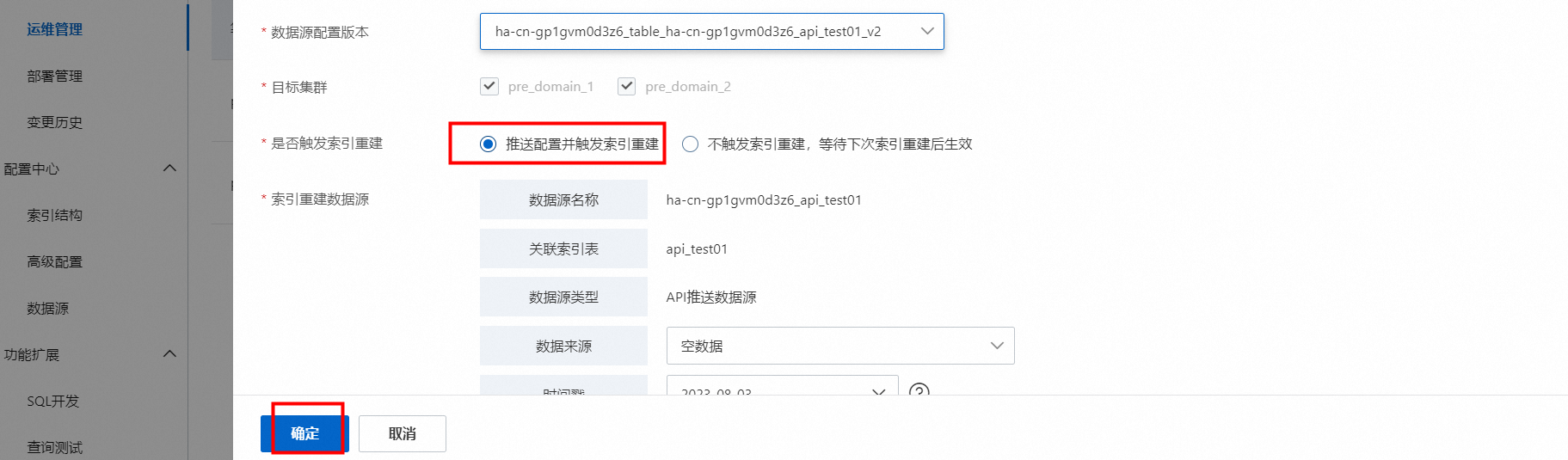
索引重建时,可以在运维中心>变更历史中的数据源变更中查看全量进度。
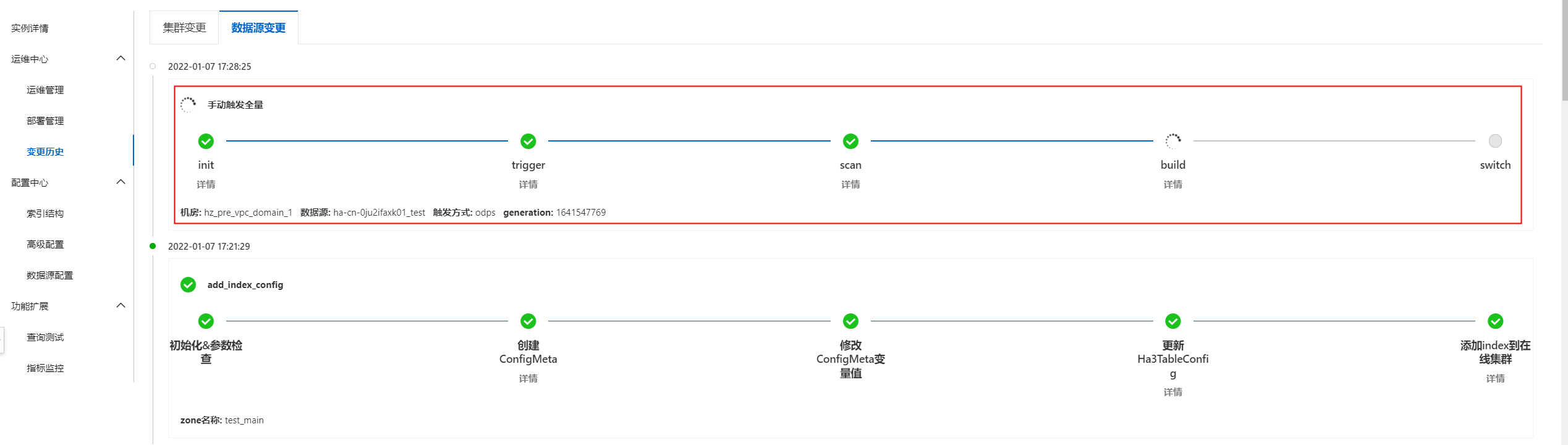
索引重建完成后,即可对新索引表进行查询。
重要字段设置有且仅有一个主键;
字段设置中,至少需要有一个字段勾选搜索结果展示;
TEXT类型的字段需要设置分析方式,且不支持多值;
索引设置有且仅有一个主键索引;
多值分割符除默认分割符外,只支持单字符,且不支持全角字符;
在设置数据分片时需要注意,假设集群的副本个数为2,数据分片设置为2,那么在购买实例时数据节点数量需要大于副本个数*数据分片,新加的索引表才能正常使用。
分片数设置时参考下面几个规则:单个分片数据量不要超过6亿(最大21亿);单个分片的索引大小不要超过300G;如果有实时更新需求,单个分片数据更新tps不要超过4000(add命令的文档,如果只是update可以达到1w tps)。
编辑索引表
索引表版本介绍:
新创建的索引表默认有2个版本:
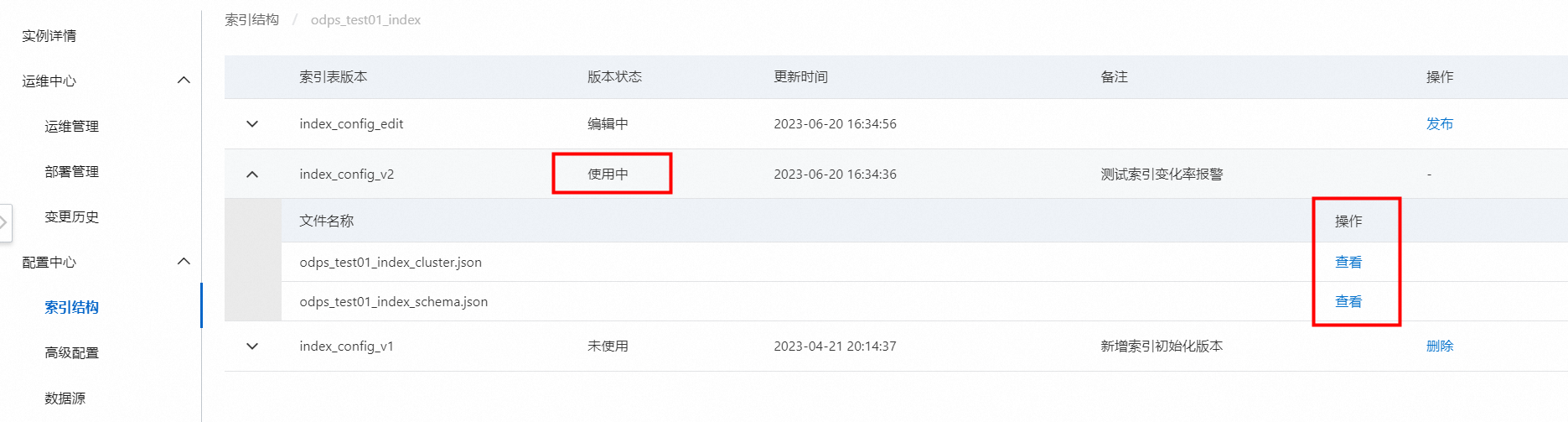
index_config_v1:初次配置的索引表版本,若已推送配置并索引重建,状态变为使用中,若未推送配置并索引重建,状态则为未使用。
index_config_edit:正在编辑中的索引表版本,状态一直为编辑中。
随着索引表版本的连续发布版本名称会依次递增,比如第二个版本名为“index_config_v2”,第三个版本名为“index_config_v3”依此类推,为明显区分各个版本,每个版本的备注是必须填写的。
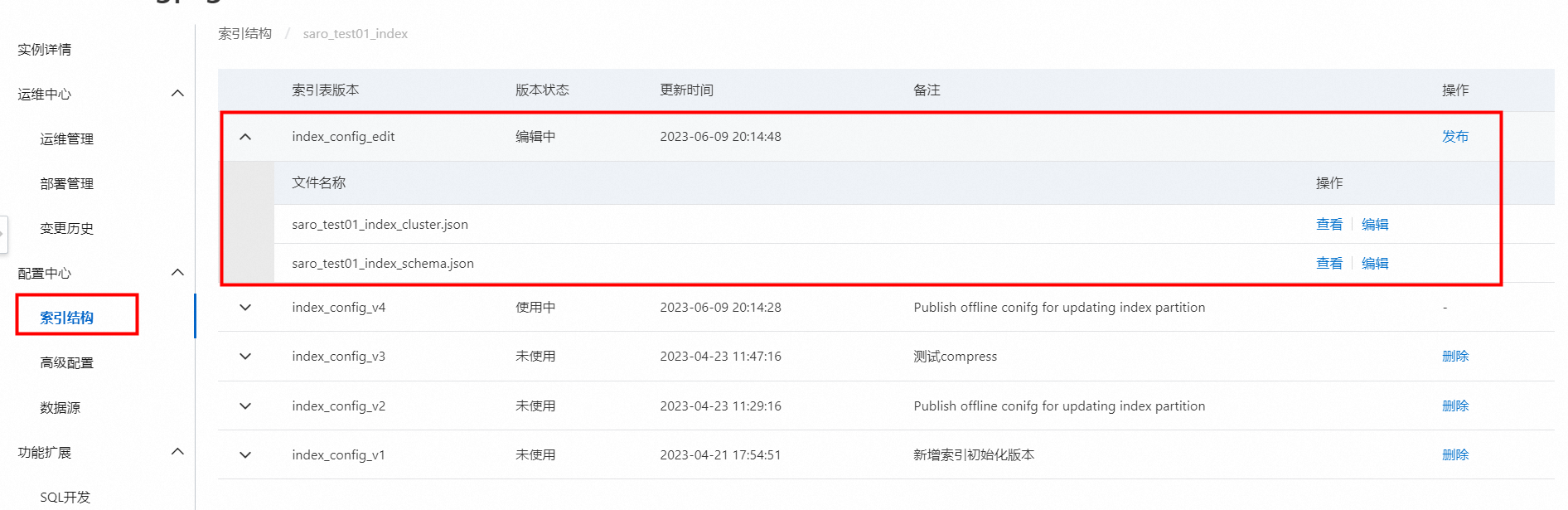
编辑并发布新的索引表版本:
找到版本状态为编辑中的版本,单击编辑:
 说明
说明cluster.json配置补充说明:
平台支持配置索引整理策略,可以对
customized_merge_config和segment_customize_metrics_updater(仅新实例支持)进行配置,如图: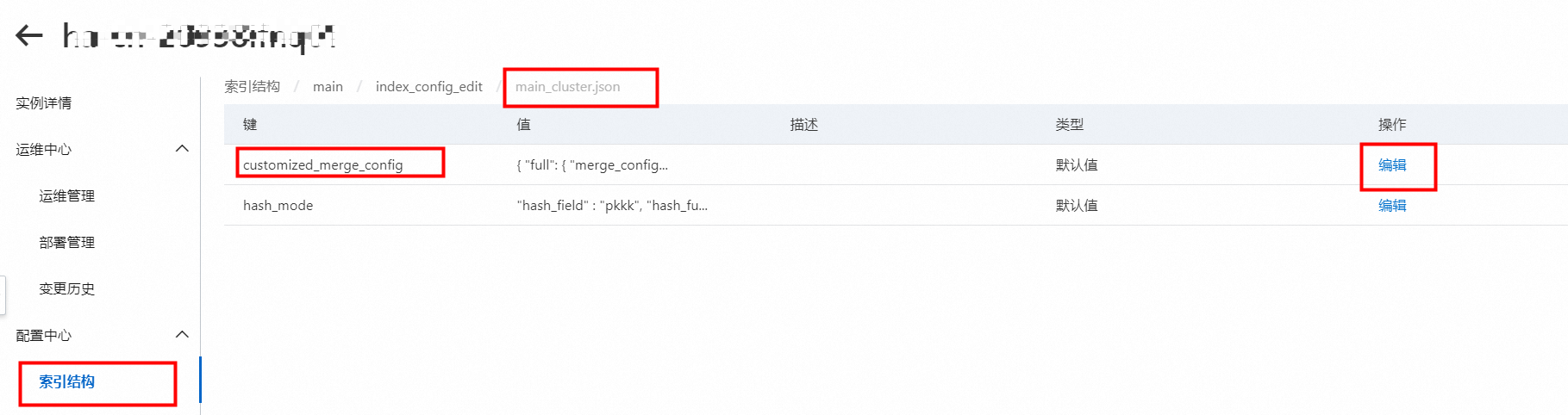
参数详解参考:离线cluster配置
修改后,单击保存版本:
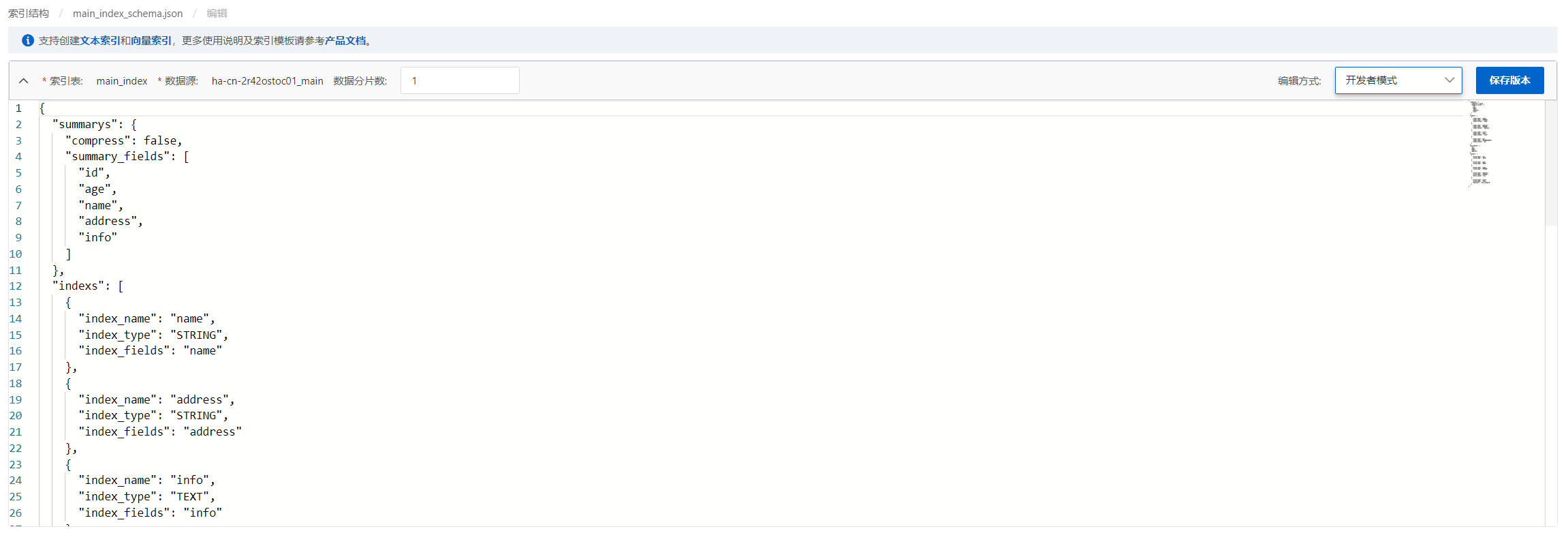
也可以切换到开发者模式手动编辑schema:
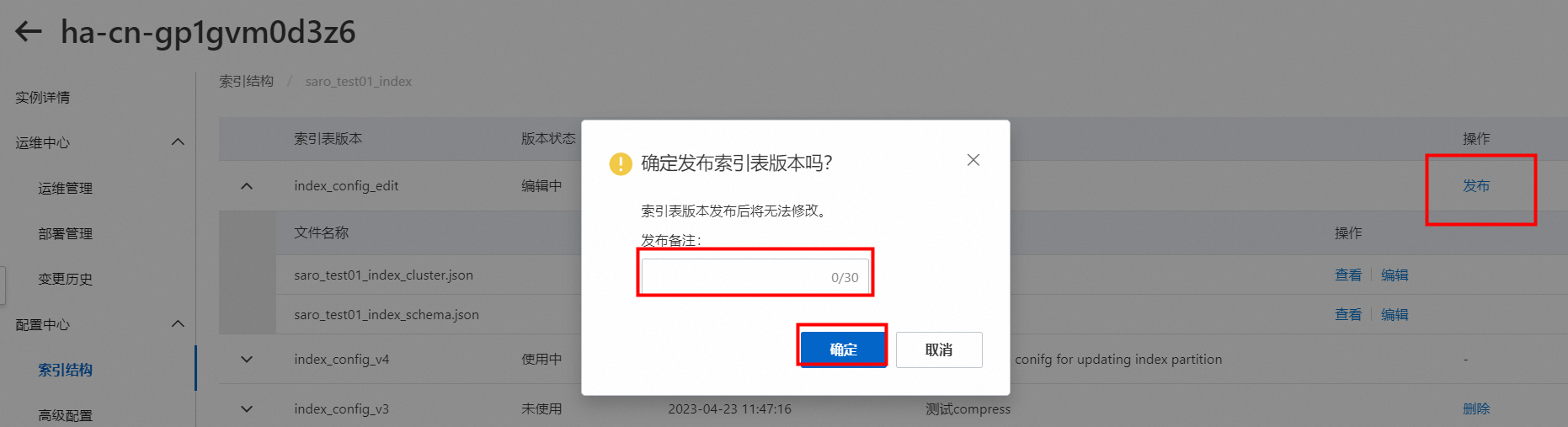
找到版本状态为编辑中的版本,单击发布,并填写备注,单击确定:
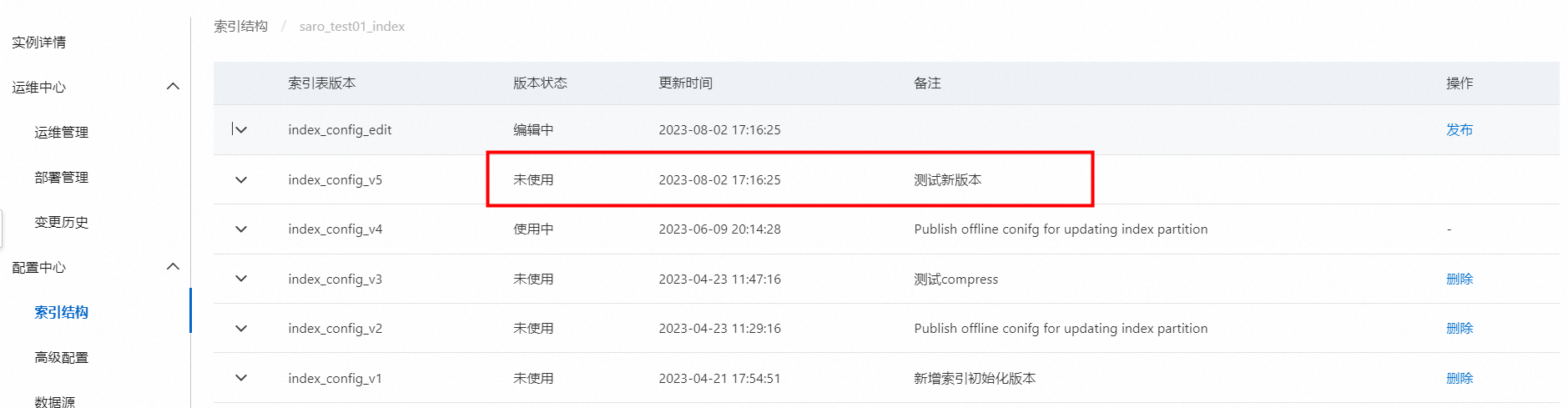
此时系统会为该索引表生产一个新的索引表版本,版本状态为“未使用”。
若需要将新添加的索引表版本在集群中生效,则需要在运维中心>运维管理>更新配置中执行推送配置并触发索引重建:
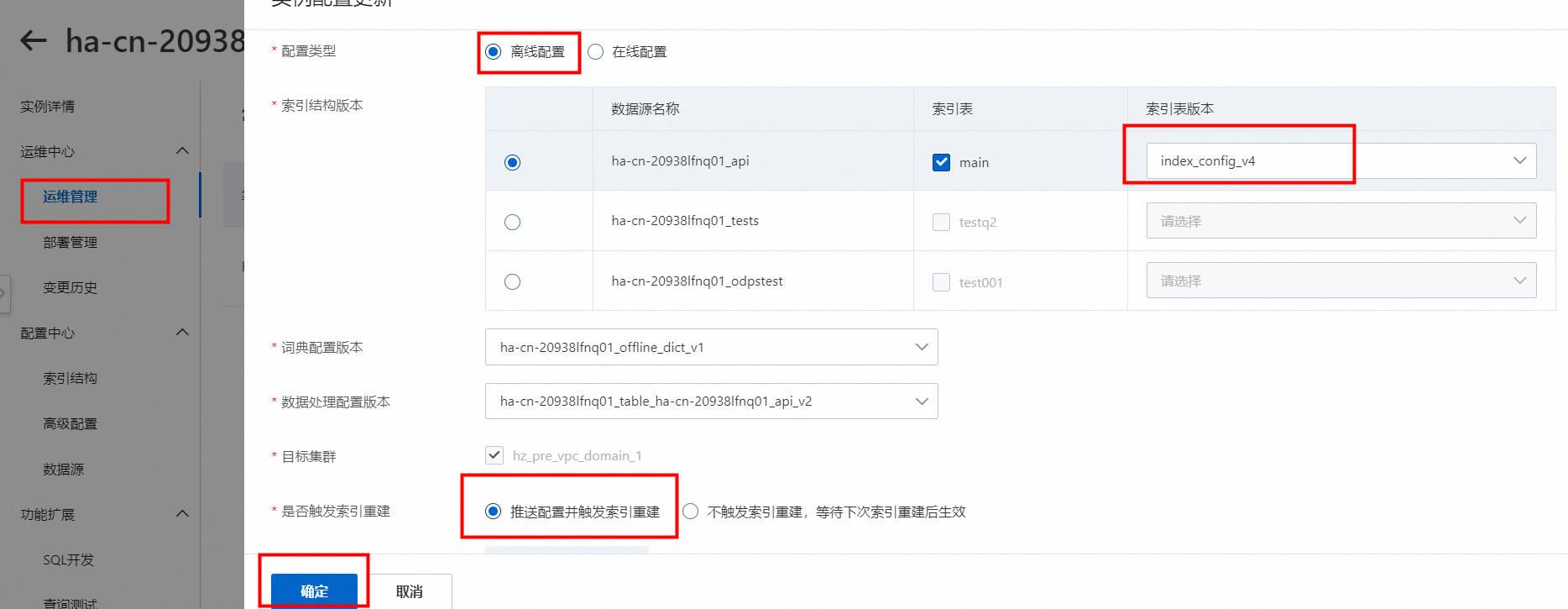
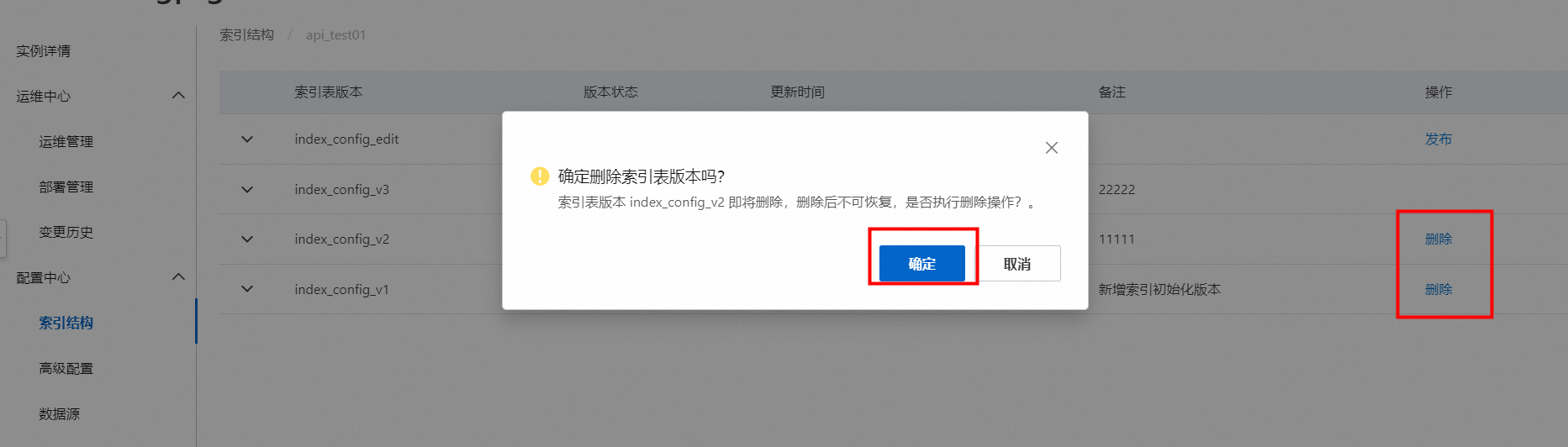
删除索引表版本:
状态为未使用的索引表版本可以直接删除:
查看索引表版本:
单击查看后,可跳转到索引表版本的只读配置界面:
管理员模式:
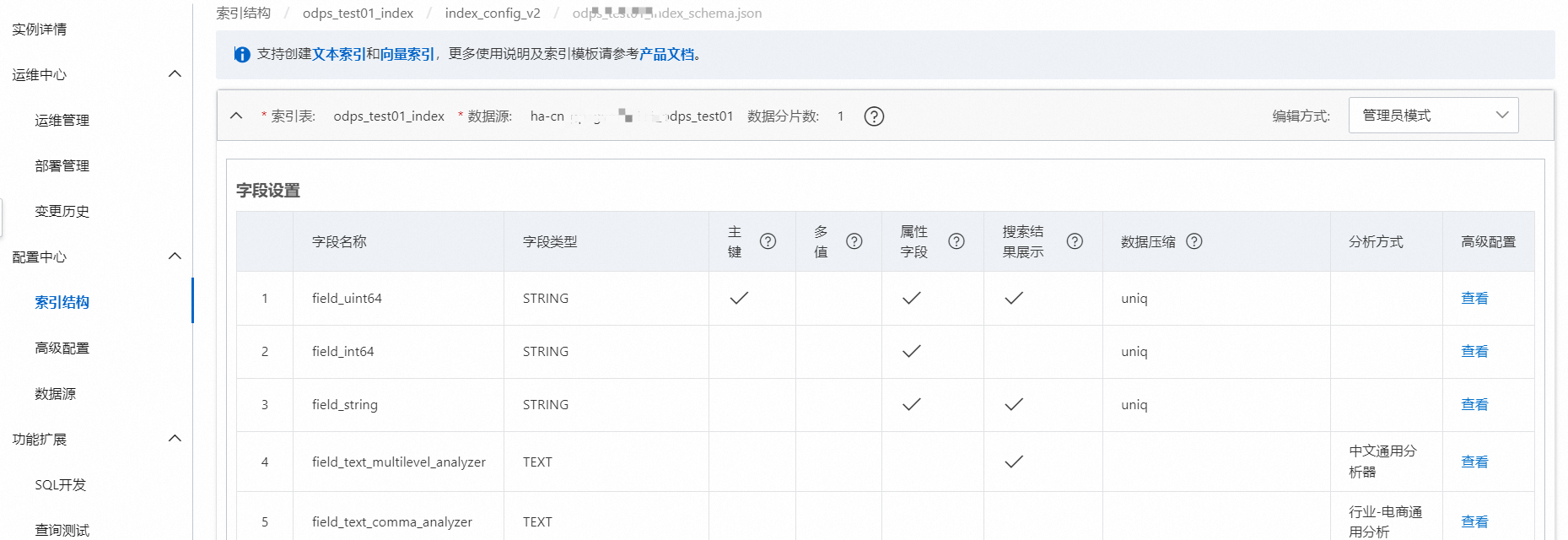
开发者模式:
删除索引表
若索引表中的索引表版本没有使用中的状态,可以直接删除索引表:

若索引表中的索引表版本有使用中的状态

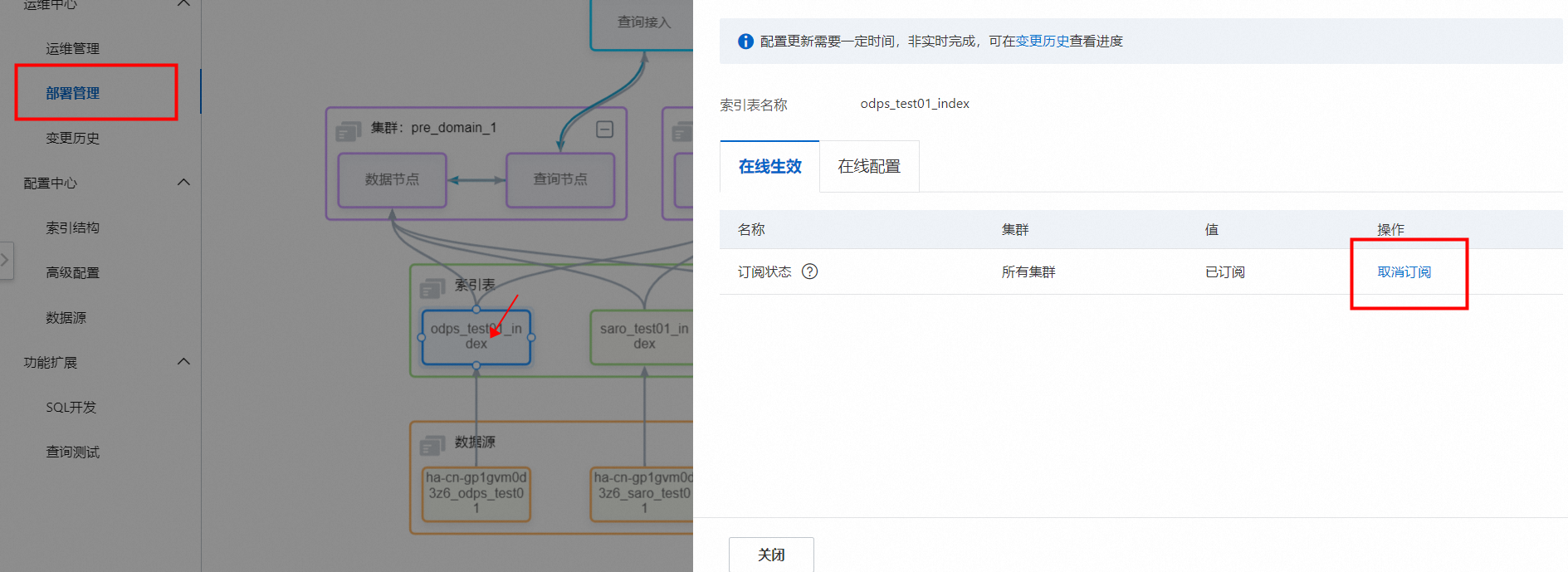
则需要按如下步骤操作,才可删除:
在运维管理>部署管理中,单击索引表,取消订阅,如图:
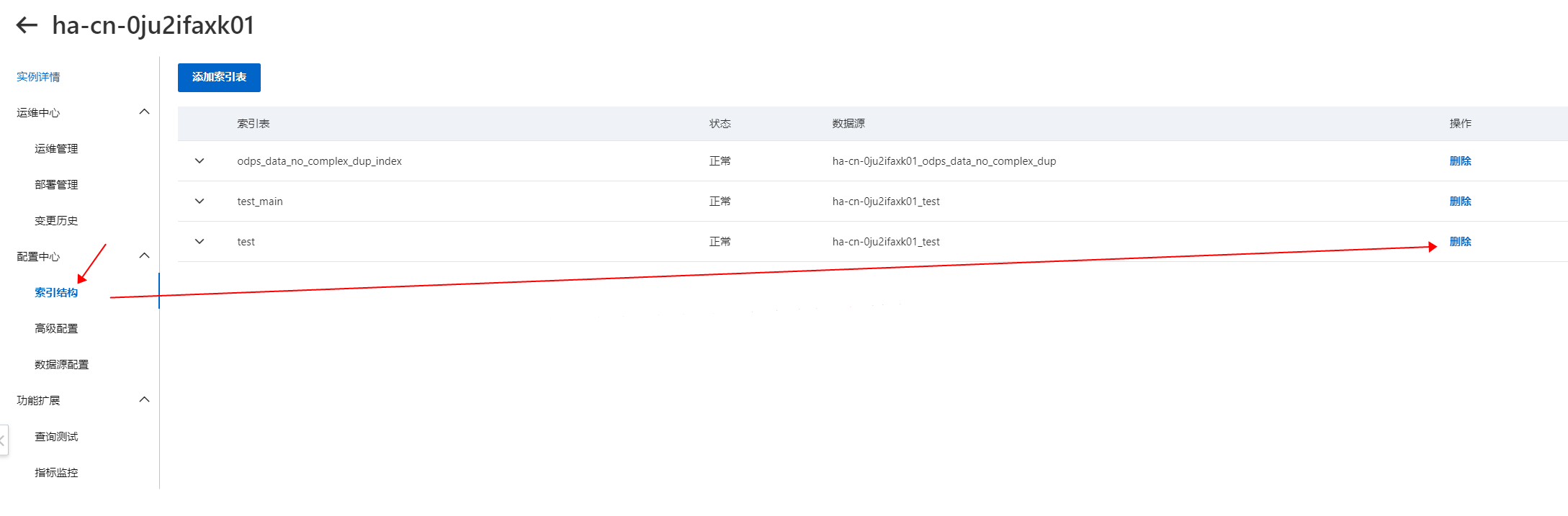
然后在配置中心>索引结构中,删除对应的索引表。
警告如果在部署管理中,索引表取消订阅,一定要在索引结构中删除对应的索引表,否则会影响线上集群。
注意事项
添加索引表时,数据源为必选项,若无数据源,则需要先添加数据源再添加索引表。
索引表名称创建后不可修改。
索引表中如有“使用中”的索引表版本,则无法直接删除索引表。
每个索引表只能存在一个编辑中的索引表版本。