
向量检索版简介
OpenSearch-向量检索版是阿里巴巴自主研发的大规模分布式搜索引擎,支持了淘宝、天猫、菜鸟、优酷乃至海外电商在内整个集团的搜索业务,同时也支撑了阿里云上的开放搜索业务。OpenSearch-向量检索版经过多年的发展,在满足业务高可用、高时效性、低成本等需求的同时,也沉淀出一套自动化运维系统,使用它用户可以根据自己的业务特点方便的构建自己的搜索服务。
OpenSearch-向量检索版架构
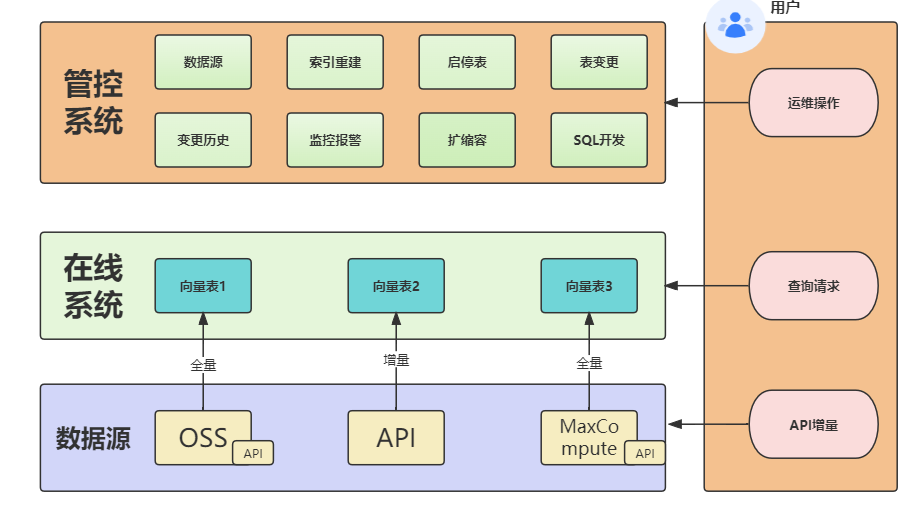
OpenSearch-向量检索版主要由三部分构成:管控系统、在线系统、数据源。在线系统加载索引,并提供向量检索服务;数据源用于配置用户的全量数据导入入口同时支持用户的实时数据写入;管控系统为用户提供自动化运维服务,方便用户创建集群并对集群进行各种运维操作。
系统架构
在线系统
在用户视角中在线系统是按表维度进行划分,用户可以通过接口单独查询每张向量表的数据,也可以对每张表进行单独管理,比如设置表字段、设置向量索引,配置数据源,控制每张表的实时数据并发等等。
后端的在线系统架构则是由查询节点和数据节点组成的多行多列的分布式架构:
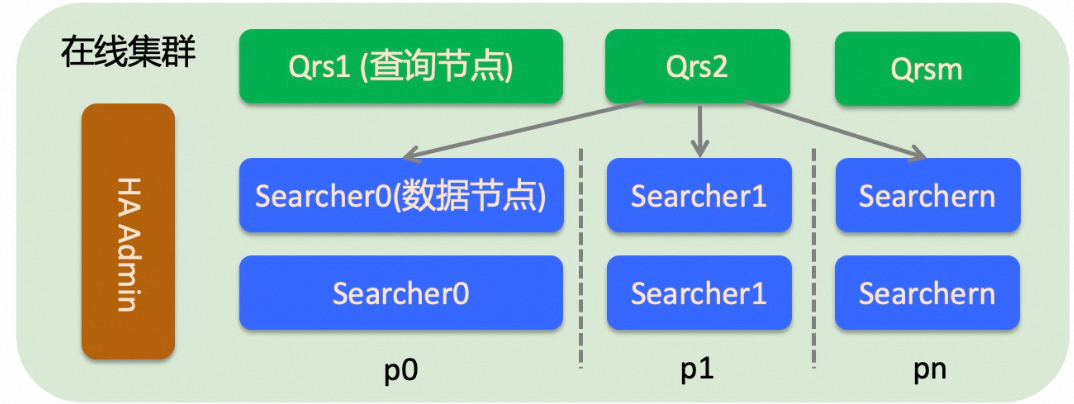
查询节点:它对输入的查询请求进行解析、校验或者改写,并将解析之后的请求转发给数据节点执行,收集并合并数据节点返回的结果,加工之后返回给用户。查询节点是一个计算型节点,不加载用户的数据,一般不需要太多的内存,但是当返回的文档个数较多或者统计产出的条目过多时才会消耗大量内存。如果查询节点的处理能力达到瓶颈,可以扩充查询节点的备份数或者扩查询节点的规格。
数据节点:数据节点加载用户的索引数据并根据查询检索文档、对文档进行过滤、统计、排序等操作。数据节点上的索引是可以分片的,分片的含义是对分片字段哈希到[0,65535]之间,将这个区间分成指定的片数(构建索引时指定)。这样对于数据量较大或者对查询性能有要求的集群,就可以通过分片提高单次请求的处理性能。如果想提高整个集群的处理能力(比如从支持1000 qps提升到10000 qps)可以通过扩备份的方式进行。扩副本不是只扩一个Searcher节点,而是扩承载所有数据的多个Searcher节点(多个分片要做成完整的[0,65535]区间)。
表之间共享数据节点资源(CPU、内存、磁盘):
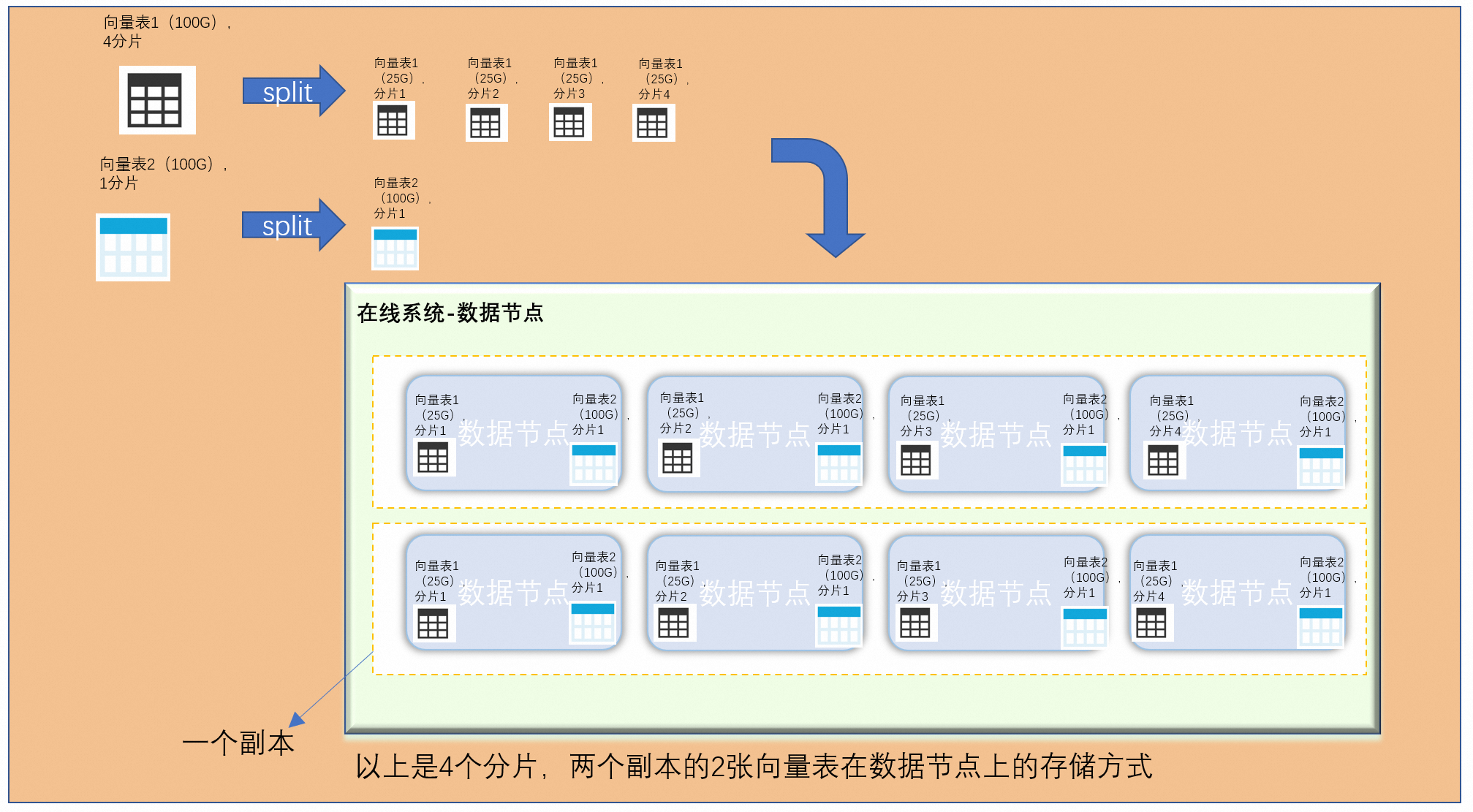
上图中展示的就是两张向量表,一个是4分片,一个是1分片,4分片的会根据产出的索引进行均分数据到每个分片中,而1分片的向量表则会形成广播表在每个数据节点中存储一份完整的向量表2的索引数据。
数据源
用户可通过配置数据源将原始数据通过索引重建(全量)的方式,将索引重建后的索引数据导入到在线系统的表中进行数据检索,数据源和表是一一对应的关系,目前系统支持的数据源有MaxCompute、Saro、API,API是一个空的数据源所有的数据需要用户通过接口推送到在线系统的表中。
管控系统
管控系统是一个OpenSearch-向量检索版实例的运维平台,这个平台大大节省了我们的运维成本。
数据同步流程
全量流程
OpenSearch-向量检索版的索引是支持多版本的,每个索引版本都会基于一份原始数据来构建(API数据源默认为空数据),触发一次索引重建就是全量流程。全量流程是一个非常驻任务,数据处理完成,产出一份全量索引,全量流程结束。产出的全量索引通过全量切换,切换到在线集群提供检索服务。
多索引版本的支持可以保证数据变更的稳定性,当索引结构变化或者数据结构发生变化时,通过全量产出新的索引是和老版本的索引完全隔离的,如果变更有问题可以及时回滚。
全量索引的产出需要经过数据处理,索引构建,索引合并等流程,在各个阶段可以通过设置索引处理的并发度提高全量索引的产出速度。
实时增量流程
全量索引产出后,每个全量版本都会有一个常驻的增量流程,而增量数据同步是通过数据更新节点完成的,
MaxCompute、OSS、API 的数据源都是通过API的方式推送实时增量数据,通过API将增量数据推送到表中,由数据更新节点消费增量数据,最后由数据节点实时构建索引,供用户查询。
增量流程是一个常驻任务,每一个表的每一个全量都会对应一个增量流程,可以通过控制数据更新节点的个数来提高实时数据的处理能力。
向量检索版特性
稳定
向量检索版底层采用c++实现,经过十多年的发展,支撑了多个核心业务,非常稳定,非常适用于对稳定性要求较高的核心搜索场景。
高效
OpenSearch-向量检索版是一个分布式搜索引擎,可以高效的支持海量数据的检索,同时也支持数据的实时更新(秒级生效),非常适用于对查询耗时敏感、时效性要求高的搜索场景。
低成本
OpenSearch-向量检索版支持多种索引压缩策略,同时支持多值索引加载测试,能够以较低的成本满足用户的查询需求。