
本文将介绍基于百炼新推出的ONE-PEACE通用多模态表征模型搭配OpenSearch向量检索服务进行多模态检索。
参考文章
流程架构
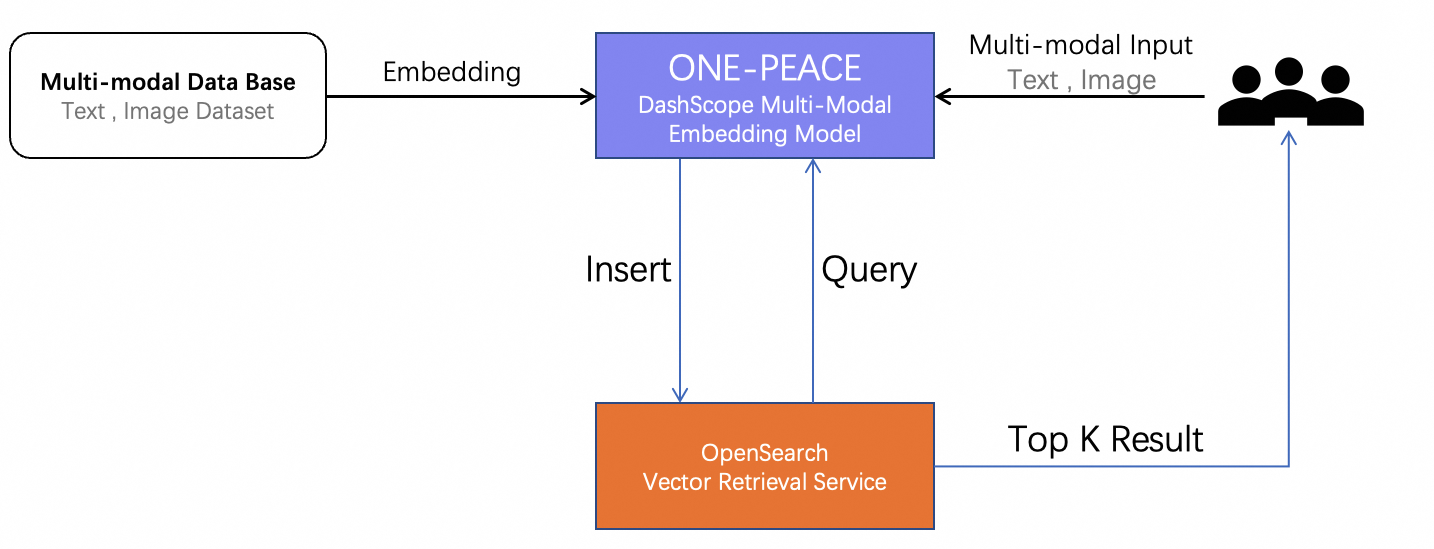
主要分为两个阶段:
模态数据Embedding + 入库:通过ONE-PEACE模型服务多模态向量接口将多种模态的数据转化为1536维向量。
多模态数据检索:基于ONE-PEACE模型提供的多模态Embedding能力,您可以实现不同模态的数据检索,例如:以文搜图,以音频搜图、文本+音频搜图等等,原理是通过ONE-PEACE模型将输入Embedding向量后通过OpenSearch向量检索服务跨模态检索相似结果。
前置条件
开通相应服务
开通百炼,并获得API-KEY:获取API Key和配置API Key到环境变量。
开通OpenSearch向量检索服务,并配置表:通用版快速入门
开发环境准备
多模态向量 和 OpenSearch向量检索服务相关的环境依赖如下:
# 安装 dashscope 和 OpenSearch向量检索服务 sdk
pip3 install dashscope
pip3 install alibabacloud_ha3engine_vector需要提前安装Python 3.7及以上版本,请确保相应的Python版本。
多模态检索
1、数据准备
说明: 由于DashScope的ONE-PEACE模型服务当前只支持URL形式的图片、音频输入,因此需要将测试数据提前上传到公共网络存储(例如OSS),并获取对应图片、音频的url地址。
文本和图片输入由用户自定义,用户也可对不同模态数据自由组合。您也可以使用以下公开数据集
单实体图片集:Dataset for ImageNet-1k
多实体图片集:Dataset for MSCOCO
也可以直接使用测试数据集:点击此处imgSource。
2、数据Embedding入库
这在此部分,我们利用ONE-PEACE模型来提取原始图像的向量,并将其写入OpenSearch向量检索服务的表中。同时,为了能够更方便地展示图像,我们将每张原始图像的URL地址也一并存储至表中。以下是实现该过程的代码示范:
# -*- coding: utf-8 -*-
import dashscope
from dashscope import MultiModalEmbedding
from alibabacloud_ha3engine_vector import models, client
from Tea.exceptions import TeaException, RetryError
# imagenet1k-urls.txt 文件每行存储数据集单张图片的名称,公共url,与当前python脚本位于同目录下
IMAGENET1K_URLS_FILE_PATH = "imagenet1k-urls.txt"
dashscope.api_key = '{your-dashscope-api-key}'
def push_embedding_data():
Config = models.Config(
endpoint="{your-opensearch-public_endpoint}", # // API域名,可在实例详情页>API入口 查看(需要去掉http://前缀)
instance_id="{your-opensearch-instance_id}", # // 实例id,可在实例详情页左上角查看,例:ha-cn-i7*****605
protocol="http",
access_user_name="{your-opensearch-instance-userName}", # // 用户名,可在实例详情页>API入口 查看
access_pass_word="{your-opensearch-instance-password}" # // 用户名密码,可在实例详情页>API入口 修改
)
# 初始化 引擎客户端
ha3EngineClient = client.Client(Config)
# 文档推送的表名称,是实例id与表名的拼接,中间用下划线连接
tableName = "{instance_id}_{table_name}"
with open(IMAGENET1K_URLS_FILE_PATH, 'r') as file:
count=1
for line in file:
image_name,url = line.split(' ')
input = [{'image': url.strip()}]
result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1,
input=input,
auto_truncation=True)
if result.status_code != 200:
print(f"ONE-PEACE failed to generate embedding of {url}, result: {result}")
continue
embedding = result.output["embedding"]
try:
# 文档推送的文档主键字段.
pkField = "pk"
# 添加文档
add2DocumentFields = {
"pk": count, # 主键
"embedding":embedding,
"url":url
}
# 将文档内容添入 add2Document结构
add2Document = {
"fields": add2DocumentFields,
"cmd": "add" # 新增对应的文档命令: add
}
optionsHeaders = {}
# 文档推送外层结构, 可添加对文档操作的结构体.结构内支持 一个或多个文档操作内容.
documentArrayList = []
documentArrayList.append(add2Document)
pushDocumentsRequest = models.PushDocumentsRequest(optionsHeaders, documentArrayList)
# 使用默认 运行时参数进行请求
response = ha3EngineClient.push_documents(tableName, pkField, pushDocumentsRequest)
count=count+1
print(response.body)
except TeaException as e:
print(f"send request with TeaException : {e}")
if __name__ == '__main__':
push_embedding_data()上述代码需要访问DashScope的ONE-PEACE多模态Embedding模型,总体运行速度视用户开通该服务的 QPS 有所不同。
上述代码是通过测试数据imagenet1k-urls.txt中的图片进行数据入库
若要运行上述代码,需要在OpenSearch向量检索服务中配置的表包含:pk(主键)、embedding(向量字段,多值的float类型)、url(图片的url),并且向量维度为1536
3、模态检索
3.1. 文本检索
以文搜图检索流程:
通过ONE-PEACE模型获取文本Embedding向量,
再通过OpenSearch向量检索服务的检索接口,快速检索相似的图片。
这里文本query是鸟 “bird”,代码示例如下:
# -*- coding: utf-8 -*-
import json
import dashscope
from dashscope import MultiModalEmbedding
from alibabacloud_ha3engine_vector.client import Client
from alibabacloud_ha3engine_vector.models import Config
from alibabacloud_ha3engine_vector.models import QueryRequest
from urllib.request import urlopen
from PIL import Image
dashscope.api_key = '{your-dashscope-api-key}'
def show_image(image_list):
for img in image_list:
# 注意:show() 函数在 Linux 服务器上可能需要安装必要的图像浏览器组件才生效
# 建议在支持 jupyter notebook 的服务器上运行该代码
img.show()
def search_by_text(input_text):
Config = models.Config(
endpoint="{your-opensearch-public_endpoint}", # // API域名,可在实例详情页>API入口 查看(需要去掉http://前缀)
instance_id="{your-opensearch-instance_id}", # // 实例id,可在实例详情页左上角查看,例:ha-cn-i7*****605
protocol="http",
access_user_name="{your-opensearch-instance-userName}", # // 用户名,可在实例详情页>API入口 查看
access_pass_word="{your-opensearch-instance-password}" # // 用户名密码,可在实例详情页>API入口 修改
)
# 初始化 引擎客户端
client = Client(Config)
# 获取文本 的 Embedding 向量
input = [{'text': input_text}]
result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1,
input=input,
auto_truncation=True)
if result.status_code != 200:
raise Exception(f"ONE-PEACE failed to generate embedding of {input}, result: {result}")
text_vector = result.output["embedding"]
#通过OpenSearch进行向量检索
request = QueryRequest(table_name="{your-opensearch-table_name}",
vector=text_vector,
include_vector=False,
search_params="{\\\"qc.searcher.scan_ratio\\\":0.01}",
top_k=2,
output_fields=["pk","url"])
result = client.query(request)
result_json=json.loads(result.body)
image_list = list()
for doc in result_json['result']:
img = Image.open(urlopen(doc['fields']['url']))
image_list.append(img)
return image_list
if __name__ == '__main__':
"""文本检索"""
# 鸟
input_text="bird"
show_image(search_by_text(input_text))运行上述代码,检索结果如下:

3.2. 音频检索
以音频搜图检索流程:
通过ONE-PEACE模型获取音频Embedding向量,
再通过OpenSearch向量检索服务的检索接口,快速检索相似的图片。
这里音频query取自ESC-50的“猫叫声”片段,代码示例如下:
# -*- coding: utf-8 -*-
import json
import dashscope
from dashscope import MultiModalEmbedding
from alibabacloud_ha3engine_vector.client import Client
from alibabacloud_ha3engine_vector.models import Config
from alibabacloud_ha3engine_vector.models import QueryRequest
from urllib.request import urlopen
from PIL import Image
dashscope.api_key = '{your-dashscope-api-key}'
def show_image(image_list):
for img in image_list:
# 注意:show() 函数在 Linux 服务器上可能需要安装必要的图像浏览器组件才生效
# 建议在支持 jupyter notebook 的服务器上运行该代码
img.show()
def search_by_audio(input_audio):
Config = models.Config(
endpoint="{your-opensearch-public_endpoint}", # // API域名,可在实例详情页>API入口 查看(需要去掉http://前缀)
instance_id="{your-opensearch-instance_id}", # // 实例id,可在实例详情页左上角查看,例:ha-cn-i7*****605
protocol="http",
access_user_name="{your-opensearch-instance-userName}", # // 用户名,可在实例详情页>API入口 查看
access_pass_word="{your-opensearch-instance-password}" # // 用户名密码,可在实例详情页>API入口 修改
)
# 初始化 引擎客户端
client = Client(Config)
# 获取音频 的 Embedding 向量
input = [{'audio': input_audio}]
result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1,
input=input,
auto_truncation=True)
if result.status_code != 200:
raise Exception(f"ONE-PEACE failed to generate embedding of {input}, result: {result}")
audio_vector = result.output["embedding"]
#通过OpenSearch进行向量检索
request = QueryRequest(table_name="{your-opensearch-table_name}",
vector=audio_vector,
include_vector=False,
search_params="{\\\"qc.searcher.scan_ratio\\\":0.01}",
top_k=2,
output_fields=["pk", "url"])
result = client.query(request)
result_json = json.loads(result.body)
image_list = list()
for doc in result_json['result']:
img = Image.open(urlopen(doc['fields']['url']))
image_list.append(img)
return image_list
if __name__ == '__main__':
#猫叫
input_audio = "http://opensearch-jiayi.oss-cn-hangzhou.aliyuncs.com/audio/audio/1-47819-A-5.wav"
show_image(search_by_audio(input_audio))运行上述代码,检索结果如下:

3.3. 文本+音频检索
接下来,我们尝试“文本+音频”联合模态检索,流程如下:
通过ONE-PEACE模型获取“文本+音频”Embedding向量,
再通过OpenSearch向量检索服务的检索接口,快速检索相似的图片。
这里的文本query选取的是眼镜“glasses”,音频query依然选择的是ESC-50的“猫叫声”片段。代码示例如下:
# -*- coding: utf-8 -*-
import json
import dashscope
from dashscope import MultiModalEmbedding
from alibabacloud_ha3engine_vector.client import Client
from alibabacloud_ha3engine_vector.models import Config
from alibabacloud_ha3engine_vector.models import QueryRequest
from urllib.request import urlopen
from PIL import Image
dashscope.api_key = '{your-dashscope-api-key}'
def show_image(image_list):
for img in image_list:
# 注意:show() 函数在 Linux 服务器上可能需要安装必要的图像浏览器组件才生效
# 建议在支持 jupyter notebook 的服务器上运行该代码
img.show()
def search_by_text_and_audio(input_text,input_audio):
Config = models.Config(
endpoint="{your-opensearch-public_endpoint}", # // API域名,可在实例详情页>API入口 查看(需要去掉http://前缀)
instance_id="{your-opensearch-instance_id}", # // 实例id,可在实例详情页左上角查看,例:ha-cn-i7*****605
protocol="http",
access_user_name="{your-opensearch-instance-userName}", # // 用户名,可在实例详情页>API入口 查看
access_pass_word="{your-opensearch-instance-password}" # // 用户名密码,可在实例详情页>API入口 修改
)
# 初始化 引擎客户端
client = Client(Config)
# 获取文本+音频 的 Embedding 向量
input = [
{'text': input_text},
{'audio': input_audio},
]
result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1,
input=input,
auto_truncation=True)
if result.status_code != 200:
raise Exception(f"ONE-PEACE failed to generate embedding of {input}, result: {result}")
embedding = result.output["embedding"]
#通过OpenSearch进行向量检索
request = QueryRequest(table_name="muitl_modal_search",
vector=embedding,
include_vector=False,
search_params="{\\\"qc.searcher.scan_ratio\\\":0.01}",
top_k=1,
output_fields=["pk", "url"])
result = client.query(request)
result_json = json.loads(result.body)
image_list = list()
for doc in result_json['result']:
img = Image.open(urlopen(doc['fields']['url']))
image_list.append(img)
return image_list
if __name__ == '__main__':
"""文本+音频检索"""
# 眼镜
input_text = "glasses"
# 猫叫声
input_audio = "http://opensearch-jiayi.oss-cn-hangzhou.aliyuncs.com/audio/audio/1-47819-A-5.wav"
show_image(search_by_text_and_audio(input_text,input_audio))运行上述代码,检索结果如下:

3.4. 图片+音频检索
我们再尝试通过“图片+音频”联合模态检索,流程如下:
通过ONE-PEACE模型获取“图片+音频”Embedding向量,
再通过OpenSearch向量检索服务的检索接口,快速检索相似的图片。
这里的图片选取的是草地图像(需先上传到公共网络存储并获取 url),音频query选择的是ESC-50的“狗叫声”片段。代码示例如下:
# -*- coding: utf-8 -*-
import json
import dashscope
from dashscope import MultiModalEmbedding
from alibabacloud_ha3engine_vector.client import Client
from alibabacloud_ha3engine_vector.models import Config
from alibabacloud_ha3engine_vector.models import QueryRequest
from urllib.request import urlopen
from PIL import Image
dashscope.api_key = '{your-dashscope-api-key}'
def show_image(image_list):
for img in image_list:
# 注意:show() 函数在 Linux 服务器上可能需要安装必要的图像浏览器组件才生效
# 建议在支持 jupyter notebook 的服务器上运行该代码
img.show()
def search_by_image_and_audio(input_image,input_audio):
Config = models.Config(
endpoint="{your-opensearch-public_endpoint}", # // API域名,可在实例详情页>API入口 查看(需要去掉http://前缀)
instance_id="{your-opensearch-instance_id}", # // 实例id,可在实例详情页左上角查看,例:ha-cn-i7*****605
protocol="http",
access_user_name="{your-opensearch-instance-userName}", # // 用户名,可在实例详情页>API入口 查看
access_pass_word="{your-opensearch-instance-password}" # // 用户名密码,可在实例详情页>API入口 修改
)
# 初始化 引擎客户端
client = Client(Config)
# 获取图片+音频 的 Embedding 向量
input = [
{'image': input_image},
{'audio': input_audio},
]
result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1,
input=input,
auto_truncation=True)
if result.status_code != 200:
raise Exception(f"ONE-PEACE failed to generate embedding of {input}, result: {result}")
embedding = result.output["embedding"]
#通过OpenSearch进行向量检索
request = QueryRequest(table_name="muitl_modal_search",
vector=embedding,
include_vector=False,
search_params="{\\\"qc.searcher.scan_ratio\\\":0.01}",
top_k=1,
output_fields=["pk", "url"])
result = client.query(request)
result_json = json.loads(result.body)
image_list = list()
for doc in result_json['result']:
img = Image.open(urlopen(doc['fields']['url']))
image_list.append(img)
return image_list
if __name__ == '__main__':
"""图片+音频检索"""
# 草地
input_image = "http://opensearch-jiayi.oss-cn-hangzhou.aliyuncs.com/image/grass.png"
# 狗叫声
input_audio = "http://opensearch-jiayi.oss-cn-hangzhou.aliyuncs.com/audio/audio/1-59513-A-0.wav"
show_image(search_by_image_and_audio(input_image, input_audio))欢迎测试
在本文中,通过结合百炼推出的ONE-PEACE模型和通用版快速入门,我们向读者们展现了一系列精彩纷呈的多模态检索实例。ONE-PEACE模型卓越的多模态嵌入功能搭配OpenSearch向量检索服务的强效向量检索技术,共同揭示了多模态搜索技术达到的新高度。
文章中提到的搜索服务、模型服务以及数据源都是可公开获取的资源,我们所提供的示例仅是对于这一领域可能性的有限探索。我们期待广大读者能亲自体验这些工具,进一步探索和释放多模态搜索的无限潜能。