本文为您介绍在PAI-Model Gallery中部署或微调训练模型时常见的问题及解决方式。
训练任务失败后,如何排查失败原因?
训练任务失败有很多可能的原因,比如用户准备的数据集格式不符合要求等。您可以尝试通过以下方式排查失败原因:
查看任务诊断:在PAI-Model Gallery > 任务管理 > 训练任务中单击指定任务,在任务详情页签下鼠标悬停于失败,系统会显示错误原因及解决办法。
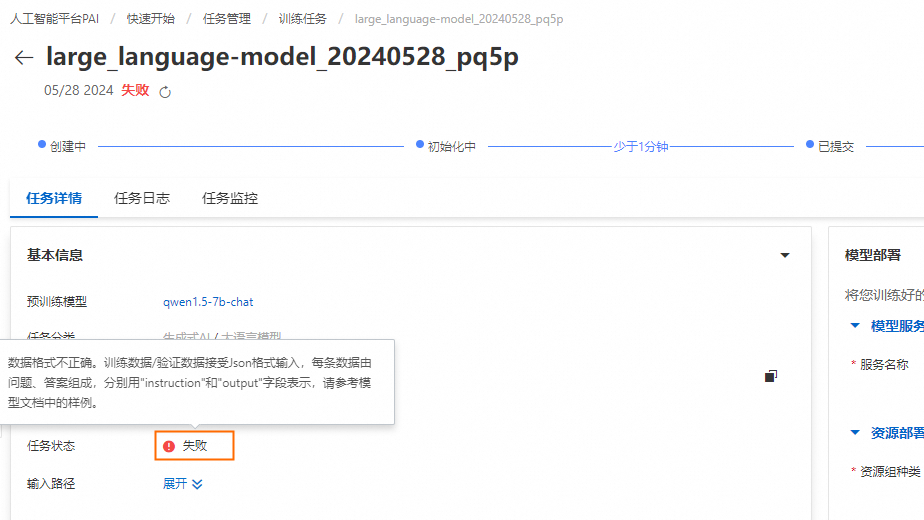
查看任务日志:在任务管理 > 训练任务中单击指定任务,在任务日志页签下查看错误信息:
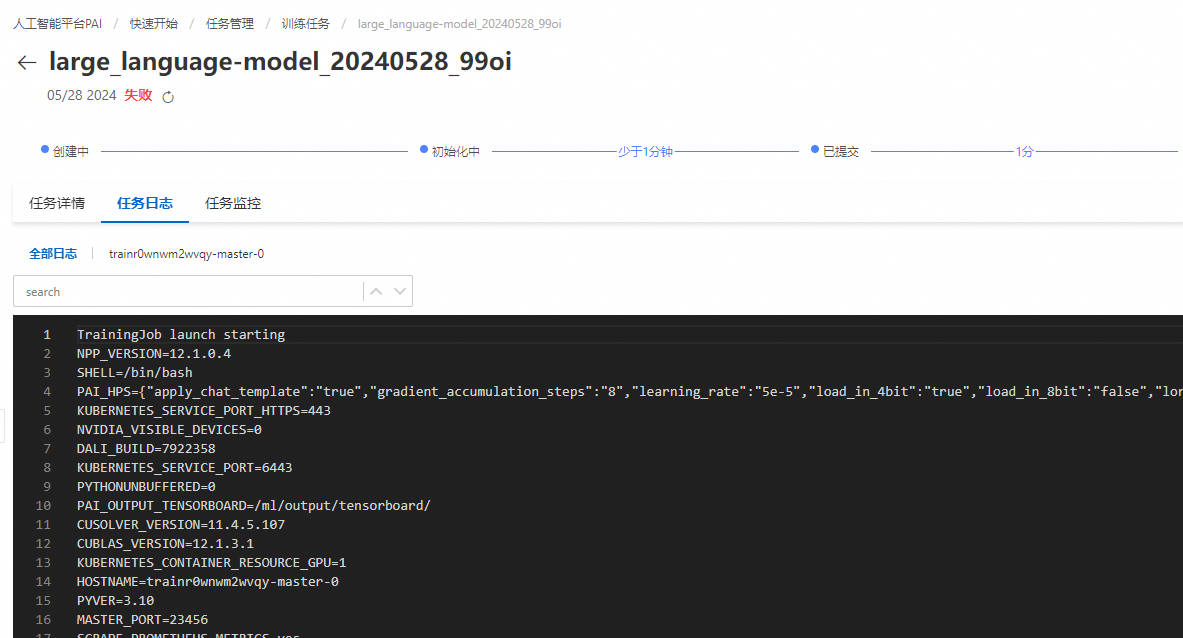
具体错误信息对应解决方法如下:
错误类型
错误信息
解决办法
输入/输出错误相关
ValueError: output channel ${your OSS uri} must be directory
检查训练设置的输出路径是否为文件夹,系统要求输出路径必须是一个文件夹。
ValueError:train must be a file
检查选择的输入路径是否为文件,系统要求输入路径必须是文件。
FileNotFoundError
检查选择的输入路径是否存在符合要求的文件。
JSONDecodeError
检查输入的JSON文件格式是否正确。
ValueError: Input data must be a json file or a jsonl file!
检查输入文件是否符合要求,要求为JSON或JSONL文件。
KeyError:${some key name}
多见于JSON格式训练集文件,根据模型说明页面检查训练集文件各个key-value值是否符合模型要求。
ValueError: Unrecognized model in /ml/input/data/model/.
PyTorch无法识别提供的模型文件。
UnicodeDecoderError
检查输入文件的编码格式是否正确。
Input/output error
检查输入路径是否具有读权限,输出路径是否具有读写权限
NotADirectoryError: [Errno 20] Not a directory:
检查输入/输出路径是否为文件夹。
超参数配置相关
ERROR:torch.distributed.elastic.multiprocessing.api:failed (exitcode: -9) local_rank: 0 (pid: 51) of binary: /usr/bin/python(且没有相关subprocess的日志)
当前机型内存不足,加载模型时OOM(Out of Memory),请选择内存更大的机型。
torch.cuda.OutOfMemoryError: CUDA out of memory
当前机型显存不足,需要选择显存更大的GPU机型或者降低涉及显存的相关超参数配置,如:lora dim,batch size。
ValueError: No closing quotation
提供的system prompt(也可能是其他参数)中出现了单个
",导致算法生成training command失败。需要删除单个",或补齐成对出现。机型资源配置相关
Exception: Current loss scale already at minimum - cannot decrease scale anymore. Exiting run
该模型参数格式为BF16,建议使用Ampere或更先进架构的GPU进行模型训练,例如A10/A100等。使用Ampere之前架构的GPU进行训练会将参数转换为FP16格式。
RuntimeError: CUDA error: uncorrectable ECC error encountered
选择的机型硬件错误。可换一个机型训练,或换个Region尝试。
MemoryError: WARNING Insufficient free disk space
选择的机型内存不够。需更换更大内存的机型。
用户限制相关
failed to compose dlc job specs, resource limiting triggered, you are trying to use more GPU resources than the threshold
当前用户同时启动了过多作业(3个或以上),触发资源限制。请等待正在运行中的任务完成。