
Model Gallery的模型评测功能支持使用自定义数据集和公开数据集(如MMLU、C-Eval等)评测大语言模型(LLM)的能力,帮助您量化对比不同模型的表现。
功能概述
模型评测功能支持从两个维度评测大语言模型:
自定义数据集评测
基于规则的评测:使用ROUGE和BLEU指标来衡量模型预测与标准答案之间的相似度。
裁判模型评测:使用Token服务提供的裁判员模型对模型输出进行逐题评分,特别适用于开放式和复杂的问答场景。
公开数据集评测
在行业标准的公开数据集上评测模型(如MMLU、TriviaQA、HellaSwag、GSM8K、C-Eval、TruthfulQA)。
提供与行业评测标准一致的基准分数。
支持的模型:目前支持所有HuggingFace AutoModelForCausalLM模型类型。
使用场景
以下是模型评测的典型使用场景:
模型基准测试:使用公开数据集评测模型通用能力,与行业模型或基准进行比较。
特定领域能力评测:将模型应用于特定领域,比较预训练模型和微调模型在不同领域的性能,评测模型应用领域知识的能力。
模型回归测试:构建回归测试集,评测模型在实际业务场景中的性能,确定模型是否符合生产标准。
计费说明
OSS存储费用:用于存储评测数据集和结果。请参见OSS计费说明。
DLC评测任务费用:用于运行评测任务。请参见DLC计费说明。
裁判员模型评测:参见PAI Token服务计费说明。
数据准备
模型评测功能支持基于自定义数据集和公开数据集(例如C-Eval)完成评测。
公开数据集:
目前PAI维护了MMLU、TriviaQA、HellaSwag、GSM8K、C-Eval、TruthfulQA等多个公开数据集,以页面实际展示为准,可直接选择使用。
自定义数据集:
需提供JSONL格式的自定义评测文件,可自行上传至OSS,并创建自定义数据集,详情参见上传OSS文件和创建及管理数据集。文件格式如下:
使用
question标识问题列,answer标识答案列,也可以在评测页面选择指定列。如果仅需要自定义数据集-裁判员模型评测,则answer列选填。{"question": "中国发明了造纸术,是否正确?", "answer": "正确"} {"question": "中国发明了火药,是否正确?", "answer": "正确"}文件示例:eval.jsonl
工作流程

步骤一:选定模型
进入Model Gallery页面。
登录PAI控制台。
在左侧导航栏单击工作空间列表,选择并进入目标工作空间。
在左侧导航栏选择快速开始 > Model Gallery,进入Model Gallery页面。
查找可评测的模型。
从模型广场筛选可评测模型。在支持操作筛选区选择评测即可过滤出可评测的模型。
评测二次训练的模型。对于支持评测的模型,其二次训练后的模型也支持评测。在Model Gallery页面单击左上角任务管理 > 训练任务,单击目标任务名称任务详情页,右上角可看到评测按钮。
步骤二:配置评测任务
支持选择公开数据集或自定义数据集完成评测,支持设置超参数,支持裁判员模型评测,支持选择多个公开数据集。
配置基础参数:
任务名称:自动生成的唯一名称。
结果输出路径:评测结果存储的OSS路径。
标签:用于对资源进行多维度查找、定位、批量操作、分账。
配置评测方式:
评测方式:支持自定义数据集评测或公开数据集评测。
公开数据集评测:
使用涵盖各个领域(如数学、编码)的开源评测数据集,为LLM提供全面的能力评测,分数越高表示模型性能越好。
可同时选择多个。其中GSM8K、TriviaQA、HellaSwag数据集较大,任务所需时间预计较长。
自定义数据集评测:自定义数据集支持指定问题和参考答案列,其中如果仅需要裁判员模型评测,则参考答案列可空。
数据集来源:支持选择OSS文件和选择现有数据集。
评测方法:可同时选择如下两种方法。
通用NLP指标评测:计算模型预测结果与参考答案的文本相似度,包括ROUGE、BLEU等指标。适用于有确定答案的场景,数据集需提供【问题-答案】对。
基于裁判员模型的多指标评测:使用裁判员模型对模型答案进行自动评分,支持自定义指标。适用于复杂答案或答案不唯一的场景,数据集可只提供【问题】,也可提供【问题-答案】对。
配置运行资源:
资源类型:不同模型支持的资源类型不一样,请以页面展示为准。
资源来源:可选择公共资源、资源配额或者竞价资源。
参数配置完成后,单击确定提交任务,页面将自动跳转到任务详情页面。等待任务执行成功,单击评测报告,即可查看评测报告。
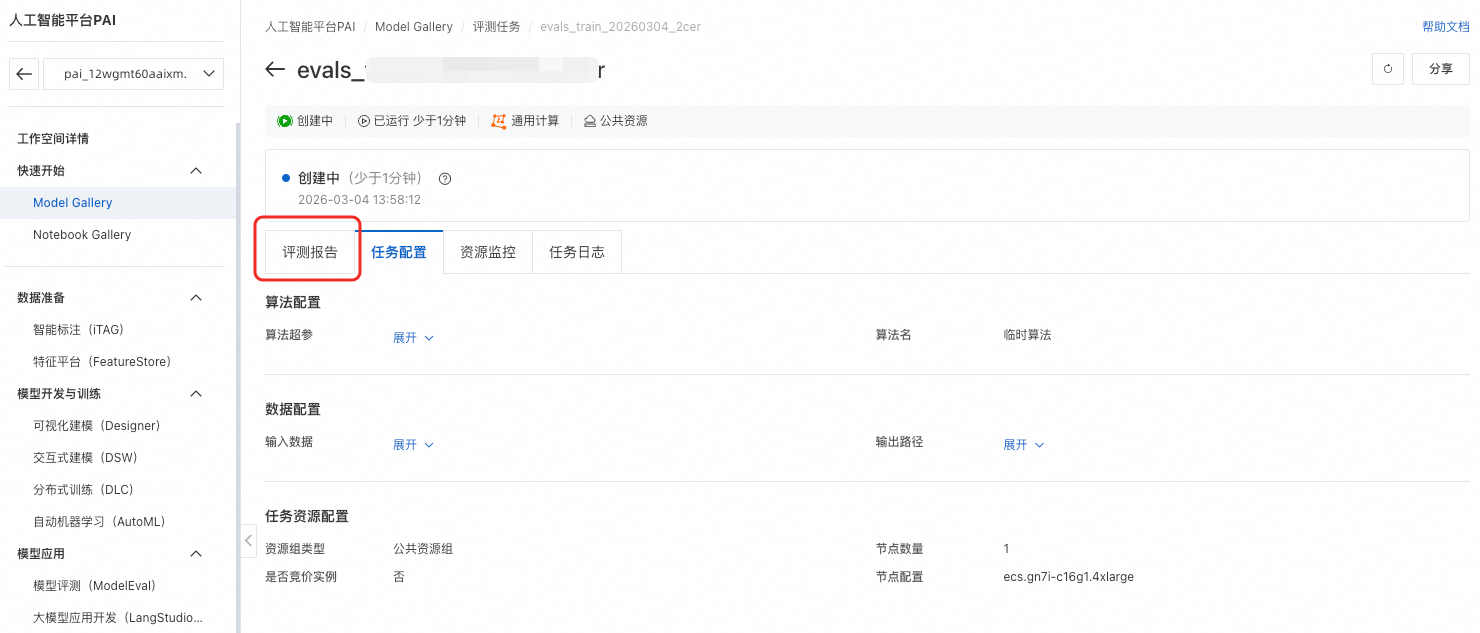
步骤三:查看评测结果
任务完成后,参见下文查看评测结果,了解如何查看单任务结果、对比多个评测任务,以及如何解读各项得分。
查看评测结果
评测任务列表
在Model Gallery页面,单击任务管理,然后切换到评测任务标签页。
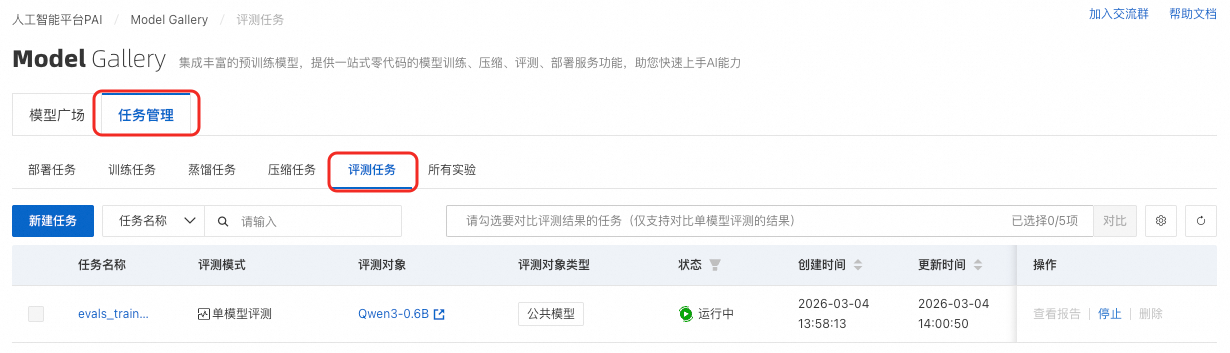
单任务结果
在评测任务列表页,单击目标评测任务操作列下的查看报告,即可进入评测任务详情页,在详情页评测报告一栏会展示模型在自定义数据集和公开数据集上的评测得分。
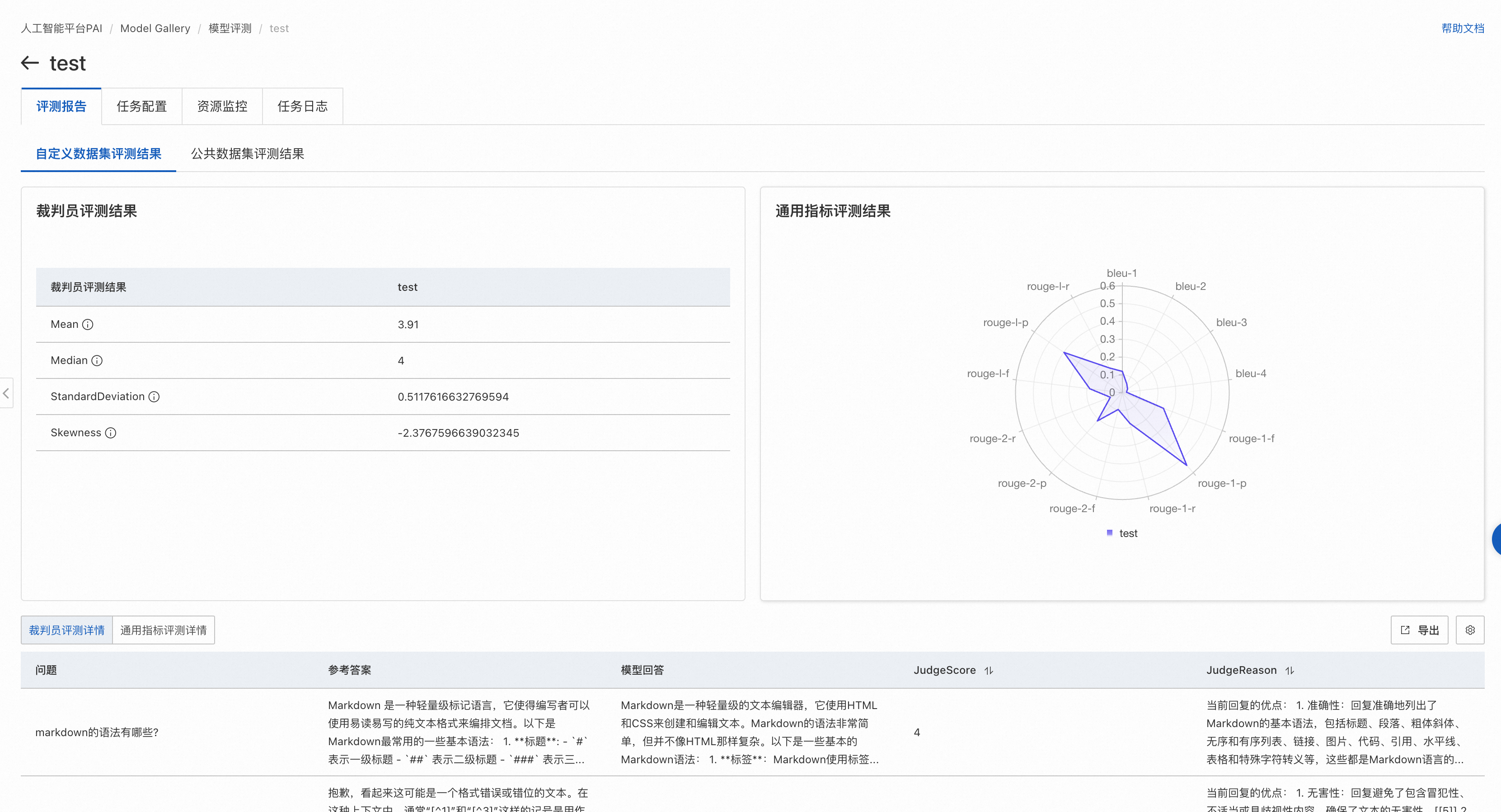
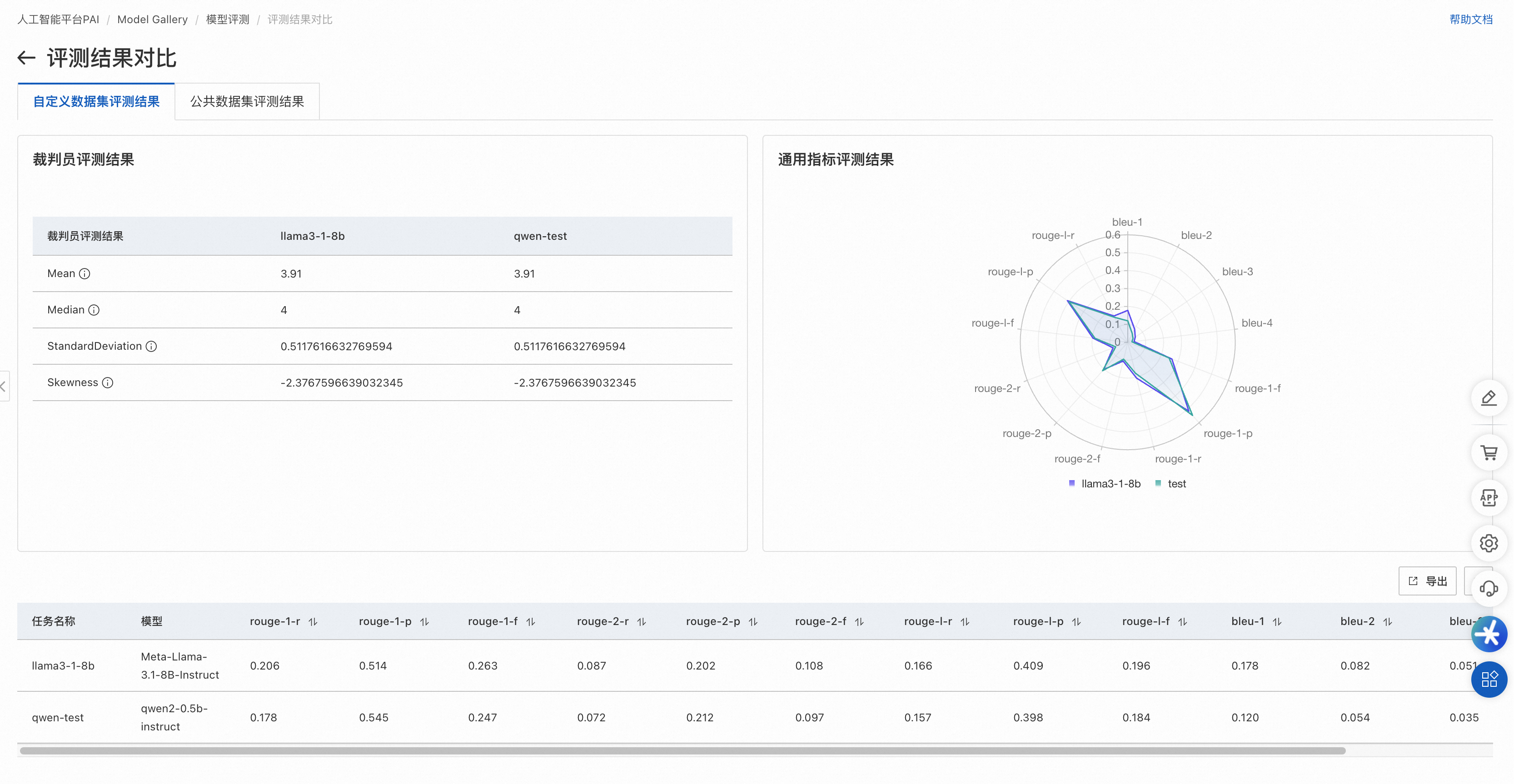
自定义数据集评测结果页面
通用指标评测:
使用标准NLP文本匹配方法,计算模型输出与标准答案之间的相似度,数值越高表示模型性能越好。
适用于使用特定领域数据评测模型对特定场景的适配度。
通过雷达图展示该模型在ROUGE和BLEU系列指标(共13个)上的得分。各指标含义详见附录:评测指标说明。
裁判员模型评测:
利用大语言模型的优势在语义层面评测输出质量。均值和中位数越高,标准差越低,表示模型性能越好。与简单的文本匹配相比,能更准确地评测输出质量。
通过列表展示裁判员模型评分的统计指标:
Mean:表示裁判员大模型对模型生成结果打分的平均值(不含无效打分),最低值1,最大值5,越大表示模型回答越好。
Median:表示裁判员大模型对模型生成结果打分的中位数(不含无效打分),最低值1,最大值5,越大表示模型回答越好。
StandardDeviation:表示裁判员大模型对模型生成结果打分的标准差(不含无效打分),在均值和中位数相同情况下,标准差越小,模型越好。
Skewness:表示裁判员大模型打分结果的分布偏度(不含无效打分),正偏度表示分布右侧(高分段)有较长尾部;负偏度则表示左侧(低分段)有较长尾部。
此外还会在页面底部展示评测文件中每条数据的评测详情。
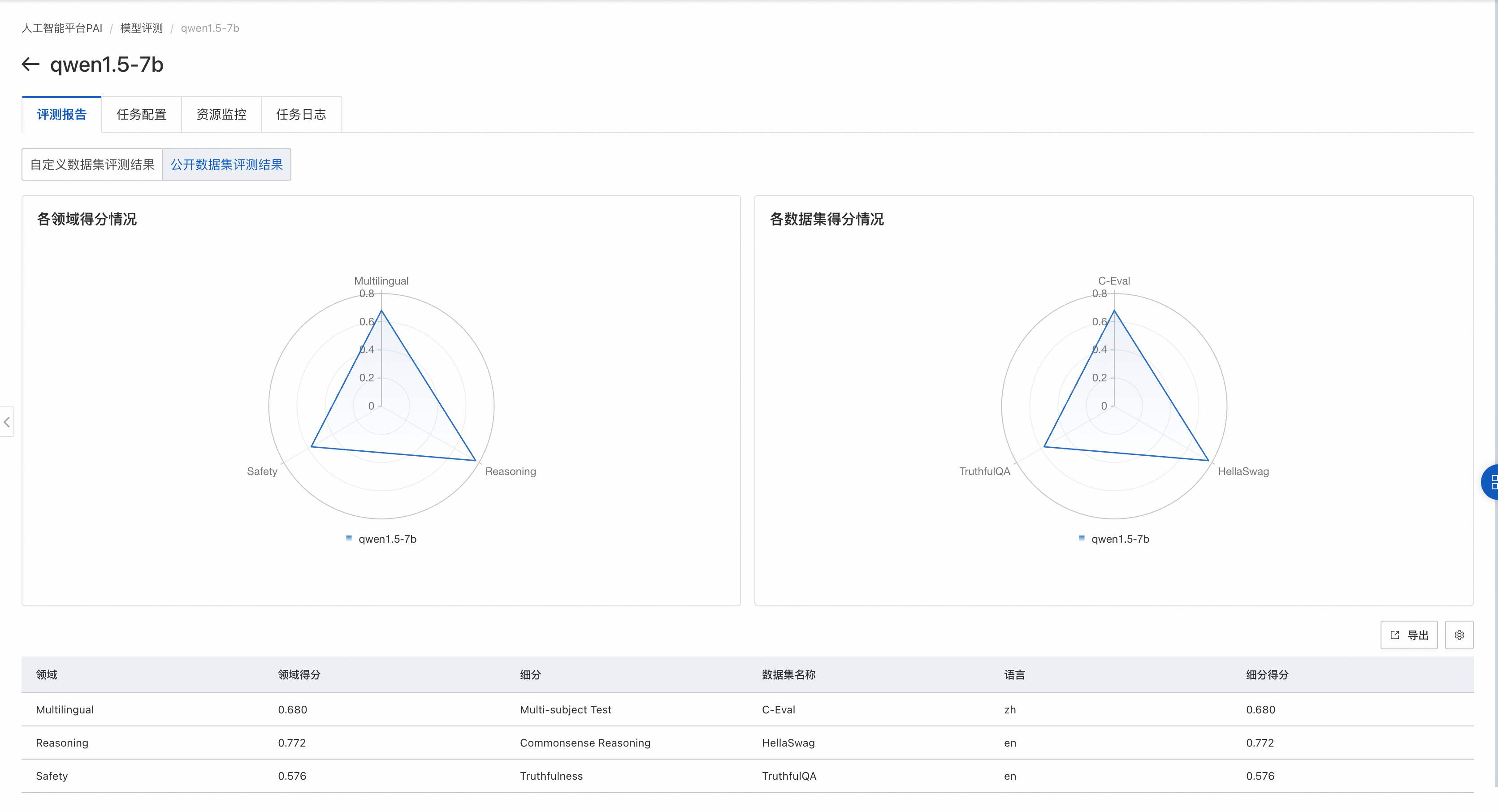
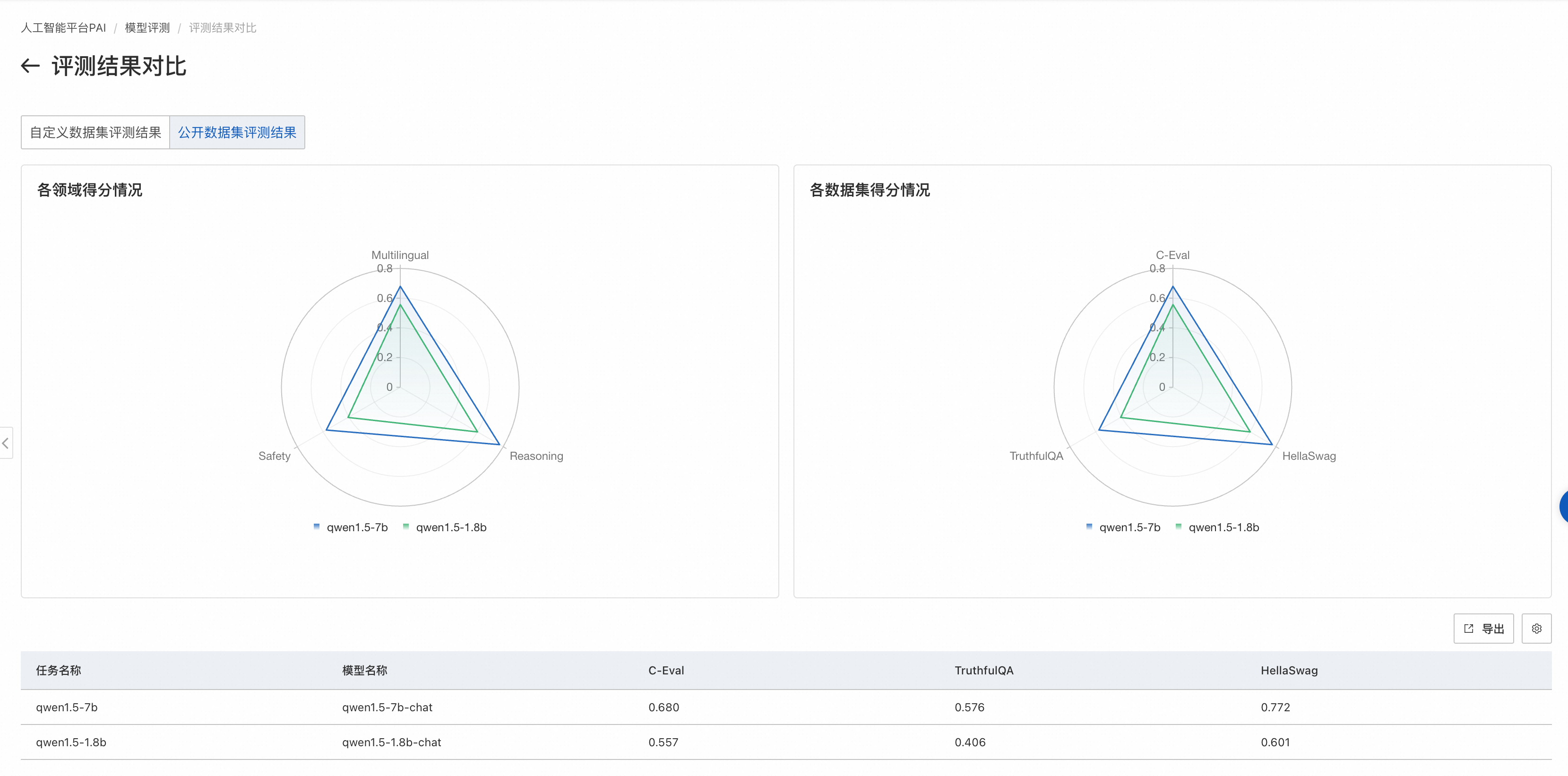
公开数据集评测结果页面
如果评测任务选择了公开数据集,则在雷达图展示该模型在公开数据集上的得分。
左侧图片展示了模型在不同领域的得分情况。每个领域可能会有多个与之相关的数据集,对属于同一领域的数据集,我们会把模型在这些数据集上的评测得分取均值,作为领域得分。
右侧图片展示模型在各个公开数据集的得分情况。每个公开数据集的评测范围见数据集官方介绍。
多评测任务对比
当需要对比多个模型的评测结果时,可以将它们在聚合在一个页面上展示,以便于比较效果。具体操作为在评测任务列表页左侧选择想要对比的模型评测任务,右上角点击对比,进入对比页面:
自定义数据集对比结果
公开数据集对比结果
相关文档
除了控制台页面,也可以通过PAI Python SDK使用模型评测功能,详情参考如下NoteBook:
附录:评测指标说明
本附录提供自定义数据集通用指标评测中各指标的详细定义。
ROUGE 指标
ROUGE系列指标衡量模型预测与标准答案的相似度。
rouge-n类指标计算N-gram(连续的N个词)的重叠度。其中rouge-1和rouge-2是最常用的,分别是unigram(1-gram)和bigram(2-gram)的重叠度。
rouge-l指标基于最长公共子序列(LCS)。
各指标后缀:-p(精确率)、-r(召回率)、-f(F-score)。
指标 | 说明 |
rouge-1-p | 系统摘要中的unigram与参考摘要中的unigram匹配的比例。 |
rouge-1-r | 参考摘要中的unigram在系统摘要中出现的比例。 |
rouge-1-f | rouge-1-p和rouge-1-r的调和平均数。 |
rouge-2-p | 系统摘要中的bigram与参考摘要中的bigram匹配的比例。 |
rouge-2-r | 参考摘要中的bigram在系统摘要中出现的比例。 |
rouge-2-f | rouge-2-p和rouge-2-r的调和平均数。 |
rouge-l-p | LCS长度与系统输出长度之比(精确率)。 |
rouge-l-r | LCS长度与参考答案长度之比(召回率)。 |
rouge-l-f | rouge-l-p和rouge-l-r的调和平均数。 |
BLEU 指标
BLEU(Bilingual Evaluation Understudy)是一种流行的评测机器翻译质量的指标,通过测量模型输出与参考答案之间的N-gram重叠度来评分。
指标 | 含义 |
bleu-1 | 考察unigram的匹配。 |
bleu-2 | 考察bigram的匹配。 |
bleu-3 | 考察trigram(连续三个词)的匹配。 |
bleu-4 | 考察4-gram的匹配。 |