
阿里云PAI灵骏智算服务是面向大规模深度学习场景的智算产品,提供一站式的异构计算资源和AI工程化平台。本方案将为您介绍如何使用阿里云PAI灵骏智算服务,以及基于Meta-Llama-3.1-8B的开源模型和Megatron的训练流程,进行模型微调、离线推理验证,并实现在线服务部署。
前提条件
本方案以Meta-Llama-3.1-8B模型为例,在开始执行操作前,请确认您已经完成以下准备工作:
已开通PAI(DSW、DLC、EAS)并创建了默认的工作空间。具体操作,请参见开通PAI并创建默认工作空间。
已购买灵骏智算资源并创建资源配额。具体操作,请参见新建资源组并购买灵骏智算资源和创建资源配额。不同模型参数量支持的资源规格列表如下,请根据您实际使用的模型参数量选择合适的资源,关于灵骏智算资源的节点规格详情,请参见灵骏Serverless版机型定价详情。
模型参数量
全参数训练资源
推理资源(最低)
Megatron训练模型切片
8B
8卡*gu7xf、8卡*gu7ef
1*V100(32 GB显存)、1*A10(22 GB显存)
TP1、PP1
70B
4*8卡*gu7xf、4*8卡*gu7ef
6*V100(32 GB显存)、2卡*gu7xf
TP8、PP2
已创建阿里云文件存储(通用型NAS)类型的数据集,用于存储训练所需的文件和结果文件。默认挂载路径配置为
/mnt/data/nas。具体操作,请参见创建及管理数据集。已创建DSW实例,其中关键参数配置如下。具体操作,请参见创建DSW实例。
资源配额:选择已创建的灵骏智算资源的资源配额。
资源规格:配置以下资源规格。
CPU(核数):90。
内存(GiB):1024。
共享内存(GiB):1024。
GPU(卡数):至少为8。
数据集挂载:单击自定义数据集,选择已创建的数据集,并使用默认挂载路径。
镜像:在镜像地址页签,配置镜像为
dsw-registry.cn-wulanchabu.cr.aliyuncs.com/pai/pai-megatron-patch:24.07。
如果使用RAM用户完成以下相关操作,需要为RAM用户授予DSW、DLC或EAS的操作权限。具体操作,请参见云产品依赖与授权:DSW、云产品依赖与授权:DLC或云产品依赖与授权:EAS。
使用限制
仅支持在华北6(乌兰察布)地域使用该最佳实践。
步骤一:下载模型训练工具源代码
进入PAI-DSW开发环境。
登录PAI控制台。
在页面左上方,选择使用服务的地域:华北6(乌兰察布)。
在左侧导航栏单击工作空间列表,在工作空间列表页面中单击待操作的工作空间名称,进入对应工作空间内。
在左侧导航栏,选择。
单击目标实例操作列下的打开。
在顶部菜单栏单击Terminal,在该页签中单击创建terminal。
在Terminal中执行以下命令,下载Pai-Megatron-Patch,并安装训练环境所需依赖。
cd /mnt/workspace/ # 方式一:通过开源网站获取训练代码。 git clone --recurse-submodules https://github.com/alibaba/Pai-Megatron-Patch.git cd Pai-Megatron-Patch # 目前LLama3.1已支持使用FlashAttention-3加速计算,但只能在Hopper架构的GPU卡上进行运算。如果需要在H卡上使用Flash Attention-3,请在DSW上的容器中安装上Flash Attention3并保存镜像。 pip install "git+https://github.com/Dao-AILab/flash-attention.git#egg=flashattn-hopper&subdirectory=hopper" python_path=`python -c "import site; print(site.getsitepackages()[0])"` mkdir -p $python_path/flashattn_hopper wget -P $python_path/flashattn_hopper https://raw.githubusercontent.com/Dao-AILab/flash-attention/main/hopper/flash_attn_interface.py
步骤二:准备Meta-Llama-3.1-8B模型
在DSW的Terminal中执行以下命令,下载Meta-Llama-3.1-8B模型。
cd /mnt/workspace
mkdir llama3-ckpts
cd llama3-ckpts
wget https://atp-modelzoo-wlcb-pai.oss-cn-wulanchabu.aliyuncs.com/release/models/pai-megatron-patch/llama3-ckpts/Meta-Llama-3.1-8B.tgz
tar -zxf Meta-Llama-3.1-8B.tgz步骤三:准备数据集
在DSW的Terminal中,执行以下命令,下载PAI已准备好的数据集。
cd /mnt/workspace
mkdir llama3-datasets
cd llama3-datasets
wget https://atp-modelzoo-wlcb-pai.oss-cn-wulanchabu.aliyuncs.com/release/models/pai-megatron-patch/llama3-datasets/mmap_llama3_datasets_text_document.bin
wget https://atp-modelzoo-wlcb-pai.oss-cn-wulanchabu.aliyuncs.com/release/models/pai-megatron-patch/llama3-datasets/mmap_llama3_datasets_text_document.idx
wget https://atp-modelzoo-wlcb-pai.oss-cn-wulanchabu.aliyuncs.com/release/models/pai-megatron-patch/llama3-datasets/alpaca_zh-llama3-train.json
wget https://atp-modelzoo-wlcb-pai.oss-cn-wulanchabu.aliyuncs.com/release/models/pai-megatron-patch/llama3-datasets/alpaca_zh-llama3-valid.json步骤四:Megatron-Core训练
您可以按照以下流程进行Megatron-Core训练。在Llama3.1中,PAI已将预训练和微调过程整合到run_mcore_llama3_1.sh脚本,对于不同的使用场景,二者各参数的意义有所不同。
Megatron-Core模型格式转换
在Terminal中执行以下命令,使用PAI提供的模型转换工具,可将Checkpoint无损转换成Megatron-Core模型格式,并输出到启动参数(TARGET_CKPT_PATH=$3)配置的目标Checkpoint路径中。
cd /mnt/workspace/Pai-Megatron-Patch/toolkits/model_checkpoints_convertor/llama
bash hf2mcore_convertor_llama3_1.sh \
8B \
/mnt/workspace/llama3-ckpts/Meta-Llama-3.1-8B \
/mnt/workspace/llama3-ckpts/Meta-Llama-3.1-8B/mcore-tp4-pp2 \
4 \
2 \
false \
true \
false \
bf16其中运行hf2mcore_convertor_llama3_1.sh脚本需要传入的参数说明如下:
参数 | 描述 |
MODEL_SIZE=$1 | 设置模型参数,取值如下:
|
SOURCE_CKPT_PATH=$2 | 源Checkpoint路径。 |
TARGET_CKPT_PATH=$3 | 目标Checkpoint路径。 |
TP=$4 | 模型并行度。 |
PP=$5 | 流水并行度。 |
mg2hf=$6 | 是否执行mcore2hf转换。 |
CHECK=$7 | 测试转换前后模型逐层输出是否一致。 |
CHECK_ONLY=$8 | 仅检测模型输出,不进行转换。 |
PR=$9 | 精度设置,取值如下:
|
HF_CKPT_PATH=$10 | HF的Checkpoint的路径。可选,当mg2hf=true时必须提供。 |
Megatron-Core预训练
先在DSW单机环境中对训练脚本进行调试,调试完成后,您便可以在DLC环境提交多机多卡的分布式训练任务,训练时长取决于您设定的训练Tokens数量。任务执行完成后,模型文件将被保存至/mnt/workspace/output_mcore_llama3_1/目录。
DSW单机预训练模型
在Terminal中使用以下命令对Meta-Llama-3.1-8B进行预训练,代码示例如下。
cd /mnt/workspace/Pai-Megatron-Patch/examples/llama3_1
sh run_mcore_llama3_1.sh \
dsw \
8B \
1 \
8 \
1e-5 \
1e-6 \
128 \
128 \
bf16 \
4 \
2 \
1 \
true \
true \
true \
false \
false \
false \
100000 \
/mnt/workspace/llama3-datasets/mmap_llama3_datasets_text_document \
/mnt/workspace/llama3-datasets/mmap_llama3_datasets_text_document \
/mnt/workspace/llama3-ckpts/Meta-Llama-3.1-8B/mcore-tp4-pp2 \
10000 \
100 \
/mnt/workspace/output_mcore_llama3_1其中运行run_mcore_llama3_1.sh脚本,需要传入的参数列表说明如下:
参数 | 描述 |
ENV=$1 | 配置运行环境:
|
MODEL_SIZE=$2 | 模型结构参数量级:8B、70B或405B。 |
BATCH_SIZE=$3 | 一次迭代一个数据并行内的样本数。 |
GLOBAL_BATCH_SIZE=$4 | 一次迭代多个数据并行的总样本数。 |
LR=$5 | 学习率。 |
MIN_LR=$6 | 最小学习率。 |
SEQ_LEN=$7 | 序列长度。 |
PAD_LEN=$8 | Padding长度。 |
PR=${9} | 训练精度:fp16、bf16或fp8。 |
TP=${10} | 模型并行度。 |
PP=${11} | 流水并行度。 |
CP=${12} | 上下文并行度。 |
SP=${13} | 是否使用序列并行,取值如下:
|
DO=${14} | 是否使用Megatron版Zero-1降显存优化器,取值如下:
|
FL=${15} | 是否优先使用Flash Attention,取值如下:
|
SFT=${16} | 是否执行微调,取值如下:
|
AC=${17} | 激活检查点模式,取值如下:
|
OPTIMIZER_OFFLOAD=${18} | 是否启用Offload optimizer,取值如下:
|
SAVE_INTERVAL=${19} | 保存CheckPoint文件的间隔。 |
DATASET_PATH=${20} | 训练数据集路径。 |
VALID_DATASET_PATH=${21} | 验证数据集路径。 |
PRETRAIN_CHECKPOINT_PATH=${22} | 预训练模型路径。 |
TRAIN_TOKENS=${23} | 训练TOKEN或者Iter数。 |
WARMUP_TOKENS=${24} | 预热TOKEN或者Iter数。 |
OUTPUT_BASEPATH=${25} | 训练输出日志文件路径。 |
DLC分布式预训练模型
在单机开发调试完成后,您可以在DLC环境中配置多机多卡的分布式任务。具体操作步骤如下:
进入新建任务页面。
登录PAI控制台,在页面上方选择目标地域,并选择目标工作空间,然后单击进入DLC。
在分布式训练(DLC)页面,单击新建任务。
在新建任务页面,配置以下关键参数,其他参数取默认配置即可。更多详细内容,请参见创建训练任务。
参数
描述
基本信息
任务名称
自定义任务名称。本方案配置为:test_llama3.1_dlc。
环境信息
节点镜像
选中镜像地址并在文本框中输入
dsw-registry.cn-wulanchabu.cr.aliyuncs.com/pai/pai-megatron-patch:24.07。数据集
单击自定义数据集,并配置以下参数:
自定义数据集:选择已创建的NAS类型的数据集。
挂载路径:配置为
/mnt/workspace/。
启动命令
配置以下命令,其中run_mcore_llama3_1.sh脚本输入的启动参数与DSW单机预训练模型一致。
cd /mnt/workspace/Pai-Megatron-Patch/examples/llama3_1 sh run_mcore_llama3_1.sh \ dlc \ 8B \ 1 \ 8 \ 1e-5 \ 1e-6 \ 128 \ 128 \ bf16 \ 4 \ 2 \ 1 \ true \ true \ true \ false \ false \ false \ 100000 \ /mnt/workspace/llama3-datasets/mmap_llama3_datasets_text_document \ /mnt/workspace/llama3-datasets/mmap_llama3_datasets_text_document \ /mnt/workspace/llama3-ckpts/Meta-Llama-3.1-8B/mcore-tp4-pp2 \ 10000 \ 100 \ /mnt/workspace/output_mcore_llama3_1资源信息
资源类型
选择灵骏智算。
资源来源
选择资源配额。
资源配额
本方案选择已创建的灵骏智算资源的资源配额。
框架
选择PyTorch。
任务资源
在Worker节点配置以下参数:
节点数量:2,如果需要多机训练,配置节点数量为需要的机器数即可。
GPU(卡数):8
CPU(核数):90,且不能大于96
内存(GiB):1024
共享内存(GiB):1024
单击确定,页面自动跳转到分布式训练(DLC)页面。当状态变为已成功时,表明训练任务执行成功。
Megatron-Core指令微调
先在DSW单机环境中对训练脚本进行调试,调试完成后,您便可以在DLC环境提交多机多卡的分布式训练任务,训练时长取决于您设定的训练迭代次数。任务执行完成后,模型文件将被保至/mnt/workspace/output_megatron_llama3/目录。
创建用于微调的idxmap数据集,详情请参见sft_data_preprocessing。
准备好微调数据集后,进行模型微调。
DSW单机微调模型
将SFT开关设置为
true即可进行指令微调。代码示例如下:cd /mnt/workspace/Pai-Megatron-Patch/examples/llama3_1 sh run_mcore_llama3_1.sh \ dsw \ 8B \ 1 \ 8 \ 1e-5 \ 1e-6 \ 128 \ 128 \ bf16 \ 4 \ 2 \ 1 \ true \ true \ true \ true \ false \ false \ 100000 \ /mnt/workspace/llama3-datasets/path_to_your_dataset \ /mnt/workspace/llama3-datasets/path_to_your_dataset \ /path/to/pretraining/checkpoint \ 10000 \ 100 \ /workspace/output_mcore_llama3_1其中运行run_mcore_llama3_1.sh脚本,需要将启动参数DATASET_PATH=${20}、VALID_DATASET_PATH=${21}和PRETRAIN_CHECKPOINT_PATH=${22}配置的数据集和预训练模型路径替换为您的实际路径,更多参数配置说明,请参见Megatron-Core预训练。
DLC分布式微调模型
在DSW单机环境调试完成后,您可以在DLC环境中配置多机多卡分布式任务。提交DLC训练任务时,启动命令配置如下,其他参数配置详情,请参见Megatron-Core预训练。
cd /mnt/workspace/Pai-Megatron-Patch/examples/llama3_1 sh run_mcore_llama3_1.sh \ dlc \ 8B \ 1 \ 8 \ 1e-5 \ 1e-6 \ 128 \ 128 \ bf16 \ 4 \ 2 \ 1 \ true \ true \ true \ true \ false \ false \ 100000 \ /mnt/workspace/llama3-datasets/path_to_your_dataset \ /mnt/workspace/llama3-datasets/path_to_your_dataset \ /path/to/pretraining/checkpoint \ 10000 \ 100 \ /workspace/output_mcore_llama3_1其中运行run_mcore_llama3_1.sh需要传入的参数与DSW单机微调模型相同。
您也可以通过设置MP_DATASET_TYPE环境变量,使用JSON格式的数据集进行指令微调。
DSW单机微调模型
代码示例如下:
export MP_DATASET_TYPE="raw"
cd /mnt/workspace/Pai-Megatron-Patch/examples/llama3_1
sh run_mcore_llama3_1.sh \
dsw \
8B \
1 \
8 \
1e-5 \
1e-6 \
128 \
128 \
bf16 \
4 \
2 \
1 \
true \
true \
true \
true \
false \
false \
100000 \
/mnt/workspace/llama3-datasets/alpaca_zh-llama3-train.json \
/mnt/workspace/llama3-datasets/alpaca_zh-llama3-valid.json \
/path/to/pretraining/checkpoint \
10000 \
100 \
/mnt/workspace/output_mcore_llama3_1其中运行run_mcore_llama3_1.sh脚本,需要将启动参数PRETRAIN_CHECKPOINT_PATH=${22}配置的预训练模型路径替换为您的实际路径,更多参数配置说明,请参见Megatron-Core预训练。
DLC分布式微调模型
在DSW单机环境调试完成后,您可以在DLC环境中配置多机多卡分布式任务。提交DLC训练任务时,启动命令配置如下,其他参数配置详情,请参见Megatron-Core预训练。
export MP_DATASET_TYPE="raw"
cd /mnt/workspace/Pai-Megatron-Patch/examples/llama3_1
sh run_mcore_llama3_1.sh \
dlc \
8B \
1 \
8 \
1e-5 \
1e-6 \
128 \
128 \
bf16 \
4 \
2 \
1 \
true \
true \
true \
true \
false \
false \
100000 \
/mnt/workspace/llama3-datasets/alpaca_zh-llama3-train.json \
/mnt/workspace/llama3-datasets/alpaca_zh-llama3-valid.json \
/path/to/pretraining/checkpoint \
10000 \
100 \
/mnt/workspace/output_mcore_llama3_1其中运行run_mcore_llama3_1.sh需要传入的参数与DSW单机微调模型相同。
步骤五:下游任务评估
您需要将已训练好的Megatron-Core格式模型转换为HuggingFace格式。具体操作步骤如下:
请将模型路径
/mnt/workspace/llama3-ckpts/Meta-Llama-3.1-8B/mcore-tp4-pp2中的JSON文件拷贝至mnt/workspace/output_mcore_llama3_1/checkpoint/pretrain-mcore-llama3-1-8B-****目录下,以保证模型可以正常使用。说明请替换为您的实际路径。
在Terminal中执行以下命令,将训练生成的模型转换成Huggingface格式的模型。
cd /mnt/workspace/Pai-Megatron-Patch/toolkits/model_checkpoints_convertor/llama bash hf2mcore_convertor_llama3_1.sh \ 8B \ /mnt/workspace/output_mcore_llama3_1/checkpoint/pretrain-mcore-llama3-1-8B-**** \ /mnt/workspace/llama3-ckpts/Meta-Llama-3.1-8B/hf-from-mg \ 4 \ 2 \ true \ true \ false \ bf16 \ /mnt/workspace/llama3-ckpts/Meta-Llama-3.1-8B其中运行hf2mcore_convertor_llama3_1.sh脚本需要传入的参数说明,请参见Megatron-Core模型格式转换。
评估模型效果。
在Terminal中执行以下命令,下载评估数据。
# In container cd /workspace wget https://atp-modelzoo-wlcb-pai.oss-cn-wulanchabu.aliyuncs.com/release/models/pai-megatron-patch/evaluation-datasets/evaluate.tgz wget https://atp-modelzoo-wlcb-pai.oss-cn-wulanchabu.aliyuncs.com/release/models/pai-megatron-patch/evaluation-datasets/cmmlu.tgz wget https://atp-modelzoo-wlcb-pai.oss-cn-wulanchabu.aliyuncs.com/release/models/pai-megatron-patch/evaluation-datasets/ceval.tgz tar -xvzf cmmlu.tgz tar -xvzf ceval.tgz tar -xvzf evaluate.tgz运行以下命令,对转换后的模型进行评估。
cd /mnt/workspace/Pai-Megatron-Patch/LM-Evaluation-Harness-240310 accelerate launch --main_process_port 29051 -m lm_eval \ --model hf \ --model_args pretrained=/mnt/workspace/llama3-ckpts/Meta-Llama-3.1-8B/hf-from-mg,trust_remote_code=True \ --tasks cmmlu,ceval-valid \ --batch_size 16
步骤六:部署及调用在线模型服务
完成离线推理并评估完成模型效果后,您可以将转换为Huggingface格式的模型部署为在线服务,并在实际的生产环境中调用,从而进行推理实践。具体操作步骤如下:
部署模型服务
登录PAI控制台,在页面上方选择目标地域,并在右侧选择目标工作空间,然后单击进入EAS。
单击部署服务,然后在自定义模型部署区域,单击自定义部署。
在自定义部署页面配置以下关键参数,其他参数取默认配置即可。
参数
描述
基本信息
服务名称
自定义模型服务名称,同地域内唯一。本方案配置为:test_llama3_1_8b。
环境信息
部署方式
选择镜像部署,并选中开启Web应用。
镜像配置
选择镜像地址,在本文框中配置镜像地址
eas-registry-vpc.cn-wulanchabu.cr.aliyuncs.com/pai-eas/chat-llm-webui:3.0.5-llama3.1。直接挂载
选择NAS类型的挂载方式,单击通用型NAS,并配置以下参数:
选择文件系统:选择创建数据集使用的NAS文件系统。
文件系统挂载点:选择创建数据集使用的挂载点。
文件系统路径:配置为存放在NAS中的转换后的Huggingface格式模型的路径。本方案配置为
/llama3-ckpts/Meta-Llama-3.1-8B/hf-from-mg。挂载路径:指定挂载后的路径,本方案配置为:
/llama3.1-8b。
运行命令
配置为
python webui/webui_server.py --port=7860 --model-path=/llama3.1-8b --model-type=llama3。其中配置的--model-path需要与模型配置中的挂载路径一致。
端口号
配置为7860。
资源信息
资源类型
选择公共资源。
部署资源
本方案以Llama3.1-8B模型为例,推荐使用实例规格ml.gu7i.c16m60.1-gu30,性价比高。
说明如果当前地域的资源不足,您还可以选择A10(ecs.gn7i-c8g1.2xlarge)类型的资源规格。
服务接入
专有网络(VPC)
配置好NAS挂载点后,系统将自动匹配与预设的NAS文件系统一致的VPC、交换机和安全组。
交换机
安全组名称
单击部署。
当服务状态变为运行中时,表明服务部署成功。
调用服务
通过WebUI调用模型服务
服务成功部署后,您可以使用WebUI对该服务进行调试操作。具体操作步骤如下:
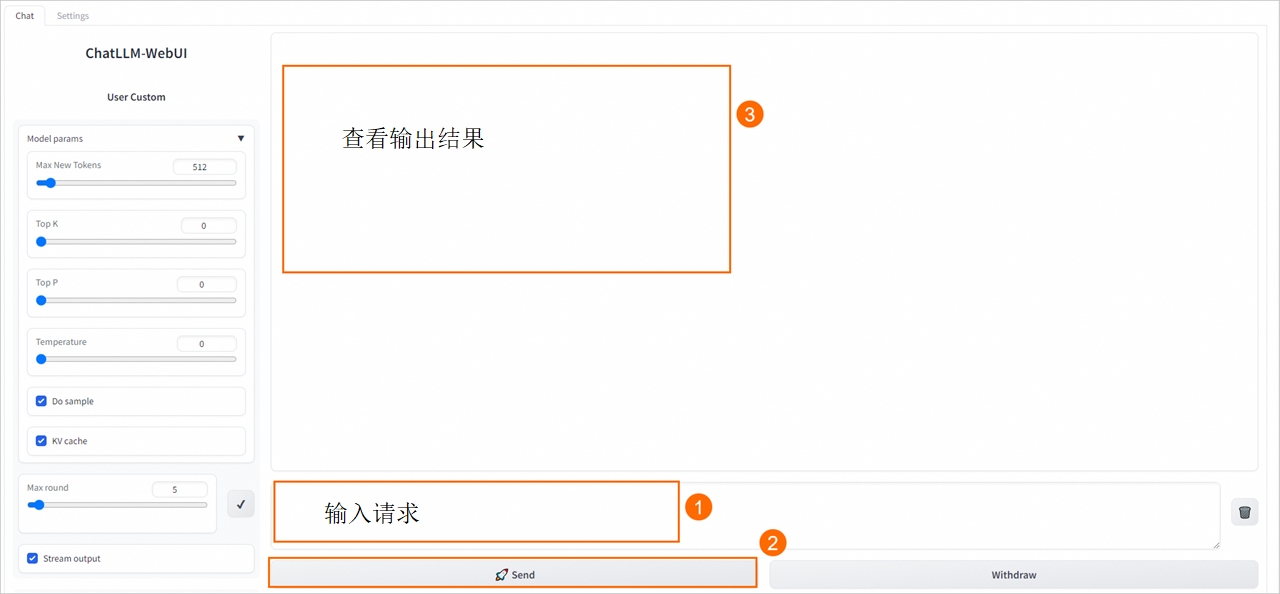
在服务列表中,单击目标服务名称,然后在页面右上角单击查看Web应用。
在WebUI页面中,进行推理模型推理。
通过API调用模型服务
当您在WebUI页面调试好问答效果后,您可利用PAI所提供的API接口,将其集成到您的业务系统中。具体操作,请参见LLM大语言模型部署。
相关文档
您也可以通过PAI-快速开始(PAI-QuickStart)部署和微调Llama-3系列模型。详情请参见快速开始:Llama-3系列模型部署及微调。