
LLM数据处理算法提供了对数据样本进行编辑和转换、过滤低质量样本、识别和删除重复样本等功能。您可以根据实际需求组合不同的算法,从而过滤出合适的数据并生成符合要求的文本,方便为后续的LLM训练提供优质的数据。本文以开源RedPajama arXiv中的少量数据为例,为您介绍如何使用PAI提供的大模型数据处理组件,对arXiv数据进行数据清洗和处理。
数据集说明
本文Designer中“LLM大语言模型数据处理-arXiv(论文数据)”预置模板用的数据集为开源项目RedPajama的原始数据中抽取的5000个样本数据。
创建并运行工作流
进入Designer页面。
登录PAI控制台。
在顶部左上角根据实际情况选择地域。
在左侧导航栏选择工作空间列表,单击指定工作空间名称,进入对应工作空间。
在左侧导航栏选择模型开发与训练 > 可视化建模(Designer),进入Designer页面。
创建工作流。
在预置模板页签下,选择业务领域 > LLM 大语言模型,单击LLM大语言模型数据处理-arXiv (论文数据)模板卡片上的创建。
配置工作流参数(或保持默认),单击确定。
在工作流列表,选择已创建的工作流,单击进入工作流。
工作流说明:
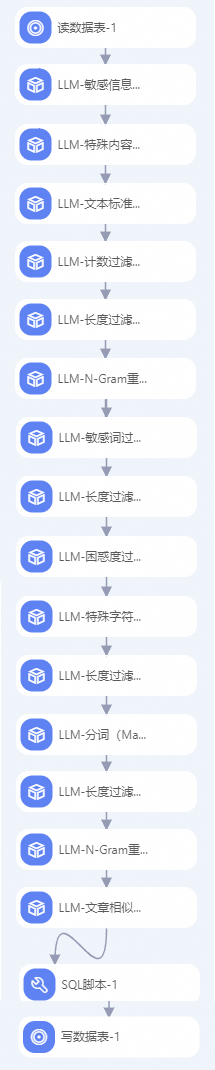
工作流中关键算法组件说明:
LLM-敏感信息打码(MaxCompute)-1
将“text”字段中的敏感信息打码。例如:
将邮箱地址字符替换成
[EMAIL]。将手机电话号码替换成
[TELEPHONE]或[MOBILEPHONE]。将身份证号码替换成
IDNUM。
LLM-特殊内容移除(MaxCompute)-1
将“text”字段中的URL链接删除。
LLM-文本标准化(MaxCompute)-1
将“text”字段中的文本进行Unicode标准化处理;将繁体转简体。
LLM-计数过滤(MaxCompute)-1
将“text”字段中不符合数字和字母字符个数或占比的样本去除。arxiv数据集中大部分字符都由字母和数字组成,通过该组件可以去除部分脏数据。
LLM-长度过滤(MaxCompute)-1
根据“text”字段的平均长度进行样本过滤。平均长度基于换行符
\n分割样本。LLM-N-Gram重复比率过滤(MaxCompute)-1
根据“text”字段的字符级N-Gram重复比率进行样本过滤,即将文本里的内容按照字符进行大小为N的滑动窗口操作,形成了长度为N的片段序列。每一个片段称为gram,对所有gram的出现次数进行统计。最后统计
频次大于1的gram的频次总和 / 所有gram的频次总和两者比率作为重复比率进行样本过滤。LLM-敏感词过滤(MaxCompute)-1
使用系统预置敏感词文件过滤“text”字段中包含敏感词的样本。
LLM-长度过滤(MaxCompute)-2
根据“text”字段的最大行长度进行样本过滤。最大行长度基于换行符
\n分割样本。LLM-困惑度过滤(MaxCompute)-1
计算“text”字段文本的困惑度,根据设置的困惑度阈值过滤样本。
LLM-特殊字符占比过滤(MaxCompute)-1
将“text”字段中不符合特殊字符占比的样本去除。
LLM-长度过滤(MaxCompute)-3
根据“text”字段的长度进行样本过滤。
LLM-分词(MaxCompute)-1
将“text”字段的文本进行分词处理,并将结果保存至新列。
LLM-长度过滤(MaxCompute)-4
根据分隔符
" "(空格)将“text”字段样本切分成单词列表,根据切分后的列表长度过滤样本,即根据单词个数过滤样本。LLM-N-Gram重复比率过滤(MaxCompute)-2
根据“text”字段的词语级N-Gram重复比率(会先将所有单词转成小写格式再计算重复度)进行样本过滤,即将文本里的内容按照词语进行大小为N的滑动窗口操作,形成了长度为N的片段序列。每一个片段称为gram,对所有gram的出现次数进行统计。最后统计
频次大于1的gram的频次总和 / 所有gram的频次总和两者比率作为重复比率进行样本过滤。LLM-文章相似度去重(MaxCompute)-1
根据设置的Jaccard相似度和Levenshtein距离阈值去除相似的样本。
运行工作流。
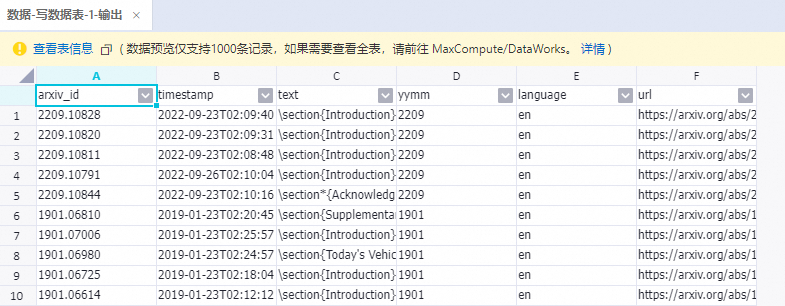
运行结束后,右键单击写数据表-1组件,选择查看数据 > 输出,查看经过上述所有组件处理后的样本。
相关参考
LLM算法组件详细说明,请参见LLM数据处理(MaxCompute)。
在完成数据处理后,您可以使用PAI平台提供的一系列大模型组件(包括数据处理组件、训练组件以及推理组件),来实现大模型从开发到使用的端到端流程。详情请参见LLM大语言模型端到端链路:数据处理+模型训练+模型推理。
- 本页导读 (1)
- 数据集说明
- 创建并运行工作流
- 相关参考
