
EasyAnimate是阿里云PAI基于Diffusion Transformer(DiT)架构自主研发的视频生成框架。它提供了一套完整的解决方案,支持通过文本或图片快速生成高清长视频,并包含模型微调功能以满足个性化需求。
方案介绍
方案 | 优势和适用场景 | 计费说明 |
提供云端集成开发环境(IDE),内置教程和代码。适合需要深入了解模型、进行二次开发的场景。 | 本教程将使用公共资源创建DSW实例,其采用按量付费模式。更多计费详情请参见DSW计费说明。 | |
无需关心环境配置,可一键部署或微调模型,并通过 WebUI 或 API 快速调用。适合需要快速验证效果或进行应用集成的场景。 | 本教程将使用公共资源创建EAS服务(用于模型部署),和DLC任务(用于模型微调),其均采用按量付费模式。更多计费详情请参见DLC计费说明、EAS计费说明。 |
方案一:使用DSW生成视频
步骤一:创建DSW实例
登录PAI控制台,选择目标地域。在左侧导航栏单击工作空间列表,选择并单击进入目标工作空间。
在左侧导航栏单击模型开发与训练 > 交互式建模(DSW),进入DSW页面。
单击新建实例,配置以下关键参数,其他参数保持默认即可。
参数
说明
实例名称
本教程使用的示例值为:AIGC_test_01。
资源类型
选择公共资源。
资源规格
选择GPU规格下的
ecs.gn7i-c8g1.2xlarge,或其他A10、GU100规格。镜像
选择官方镜像,搜索并选择
easyanimate:1.1.5-pytorch2.2.0-gpu-py310-cu118-ubuntu22.04。单击确定,创建实例,等待实例状态变为运行中。
步骤二:下载EasyAnimate教程和模型
单击目标DSW实例操作列下的打开,进入DSW实例的开发环境。
在Notebook页签的Launcher页面,单击打开DSW Gallery。
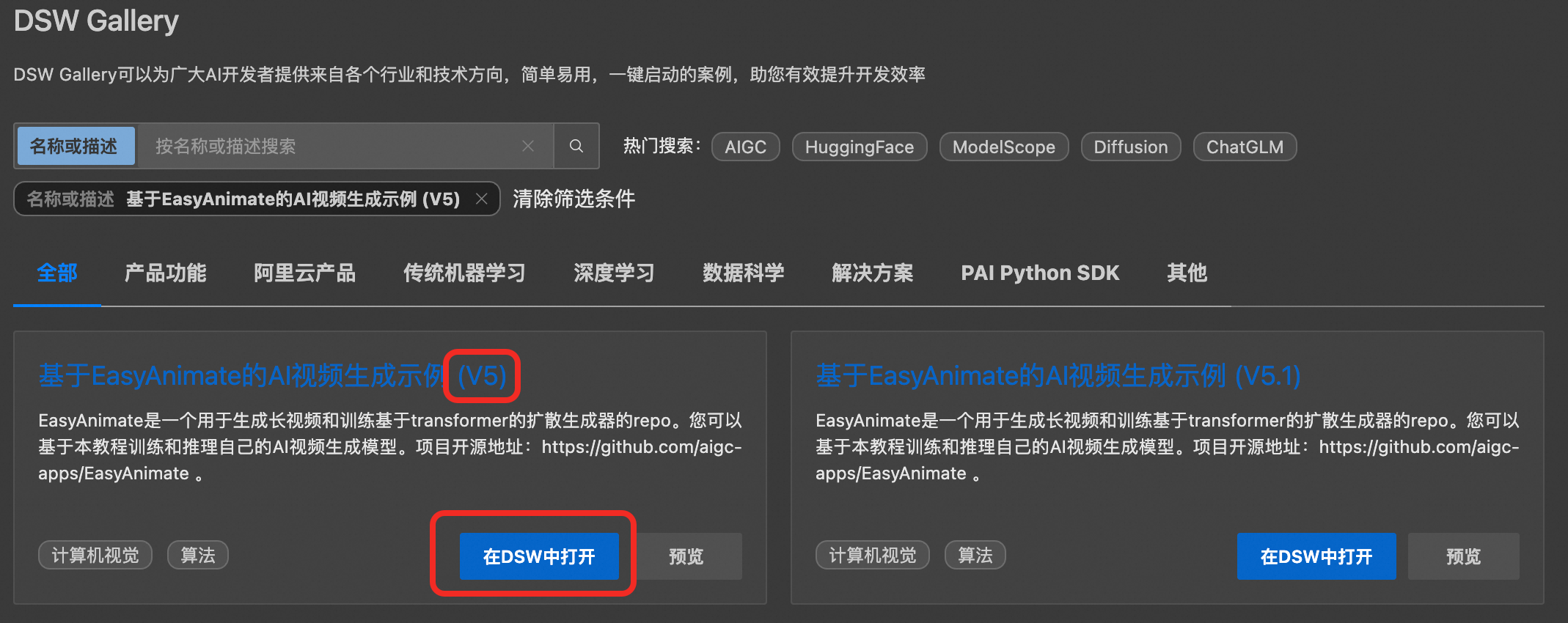
在DSW Gallery页面,搜索基于EasyAnimate的AI视频生成示例 (V5)。单击在DSW中打开,即可自动将本教程所需的资源下载至DSW实例中。
基于EasyAnimate的AI视频生成示例有多个版本,本文以V5版本为例进行说明。
下载EasyAnimate相关代码和模型并进行安装。
在EasyAnimate的教程文件中,单击
 依次运行标题为函数定义、下载代码和下载模型单元格。
依次运行标题为函数定义、下载代码和下载模型单元格。
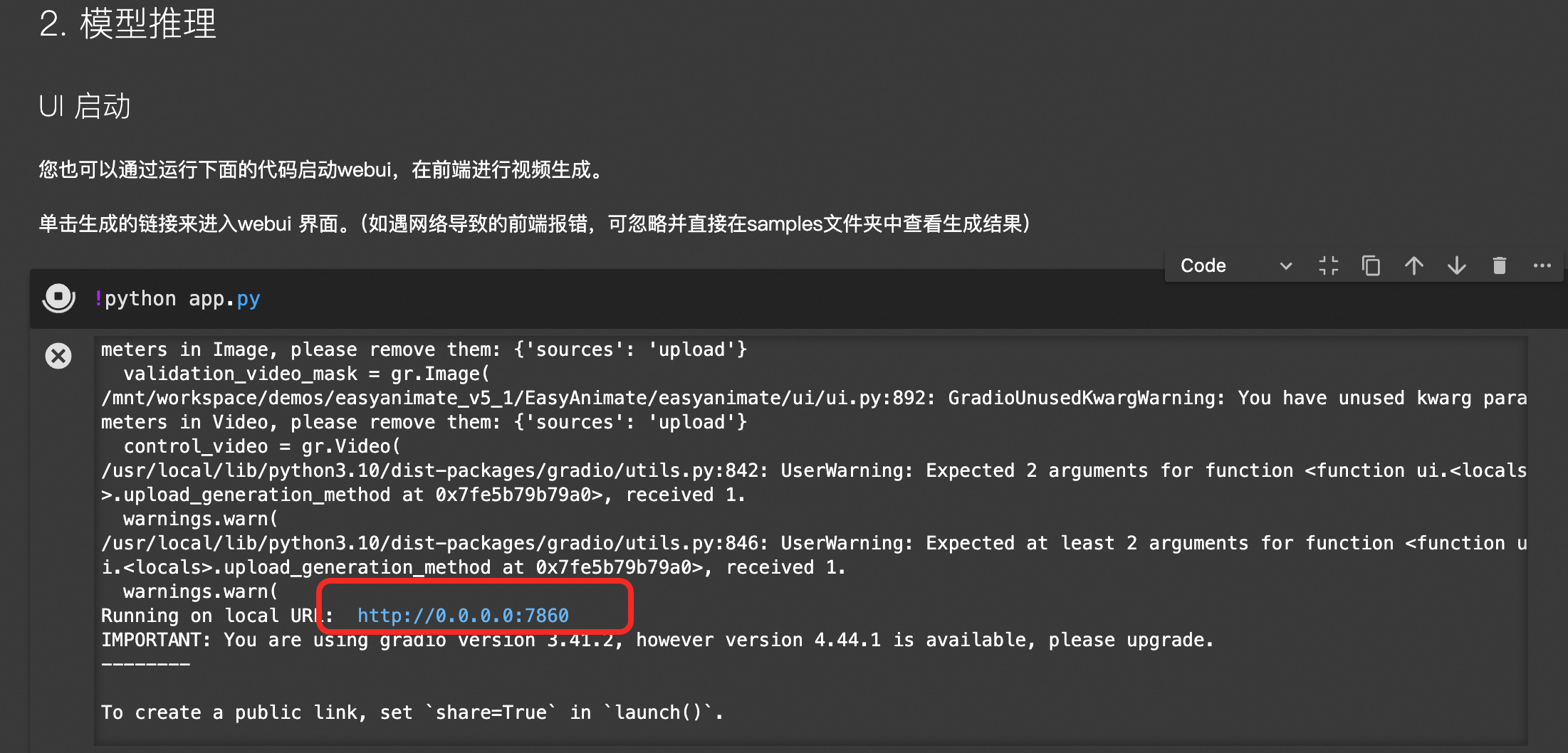
步骤三:启动WebUI并生成视频
单击
运行标题为UI启动的单元格,启动WebUI服务。单击生成的链接,进入WebUI。
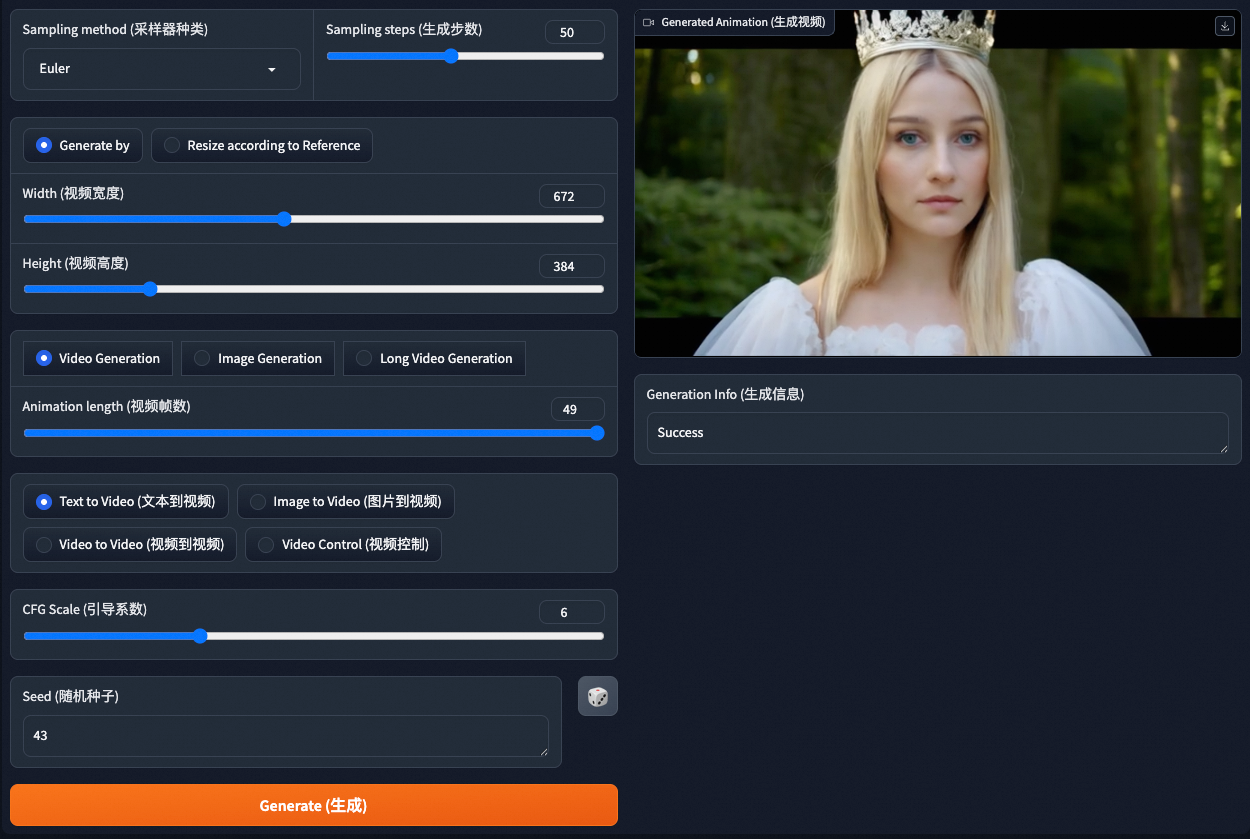
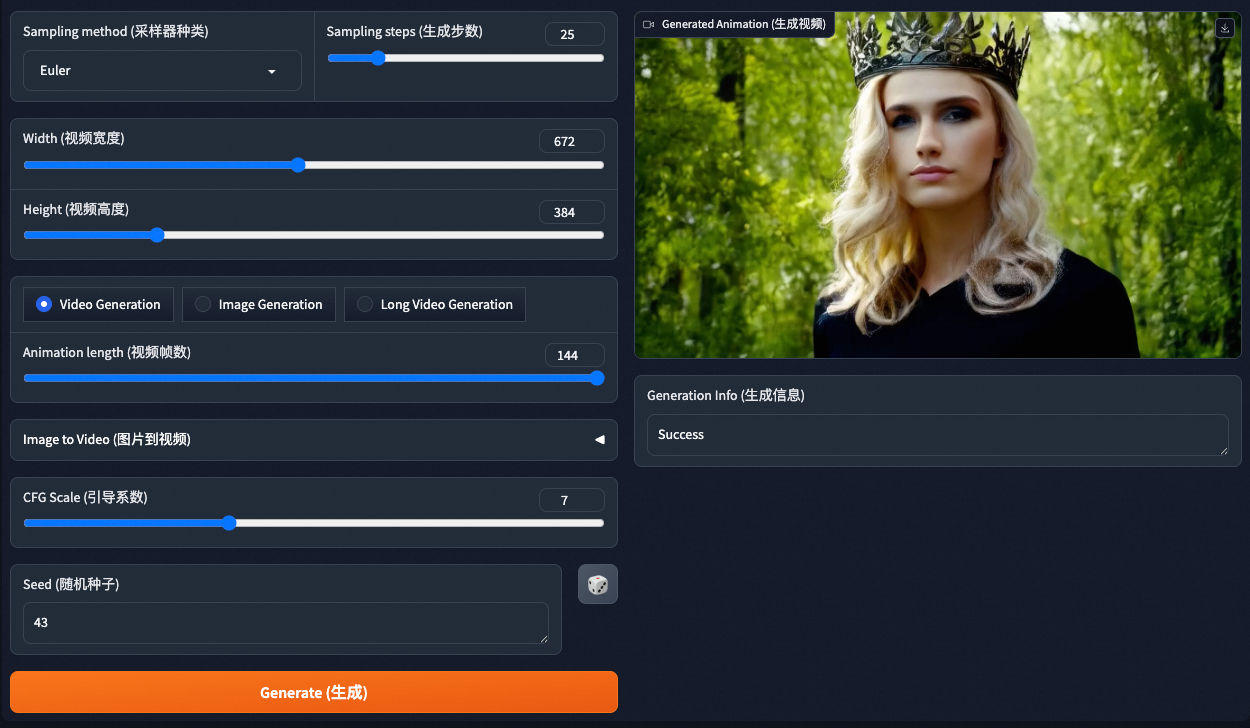
在WebUI界面下拉选择预训练模型路径,其它参数按需配置即可。

单击Generate(生成),等待约5分钟后,即可在右侧查看或下载生成的视频。
方案二:使用Model Gallery生成视频
步骤一:部署预训练模型
登录PAI控制台,选择目标地域。在左侧导航栏单击工作空间列表,选择并单击进入目标工作空间。
在左侧导航栏单击。搜索EasyAnimate 高清长视频生成模型,单击部署,使用默认配置,确认部署。当服务状态变为运行中时,表示模型部署成功。

步骤二:通过WebUI或API生成视频
模型部署完成后,您可以使用WebUI及API两种方式调用服务来生成视频。
后续查看部署任务详情,可通过在左侧导航栏单击Model Gallery > 任务管理 > 部署任务,然后再单击服务名称查看。
WebUI方式
在服务详情页面,单击查看WEB应用。
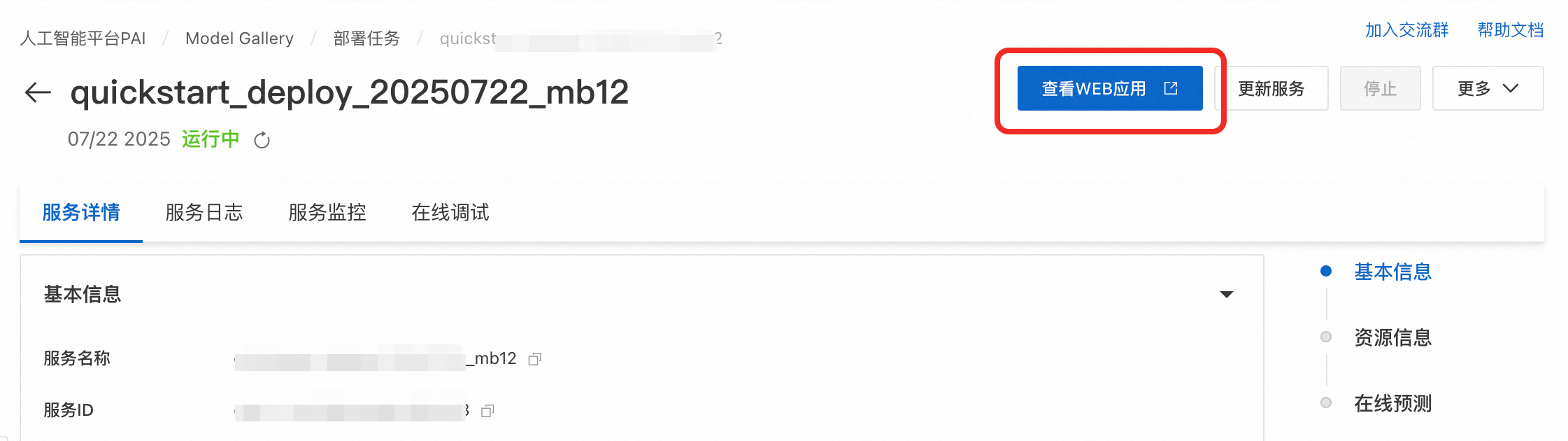
在WebUI界面选择预训练的模型路径,其它参数按需配置即可。

单击Generate(生成),等待大约5分钟后,即可在右侧查看或下载生成的视频。
API方式
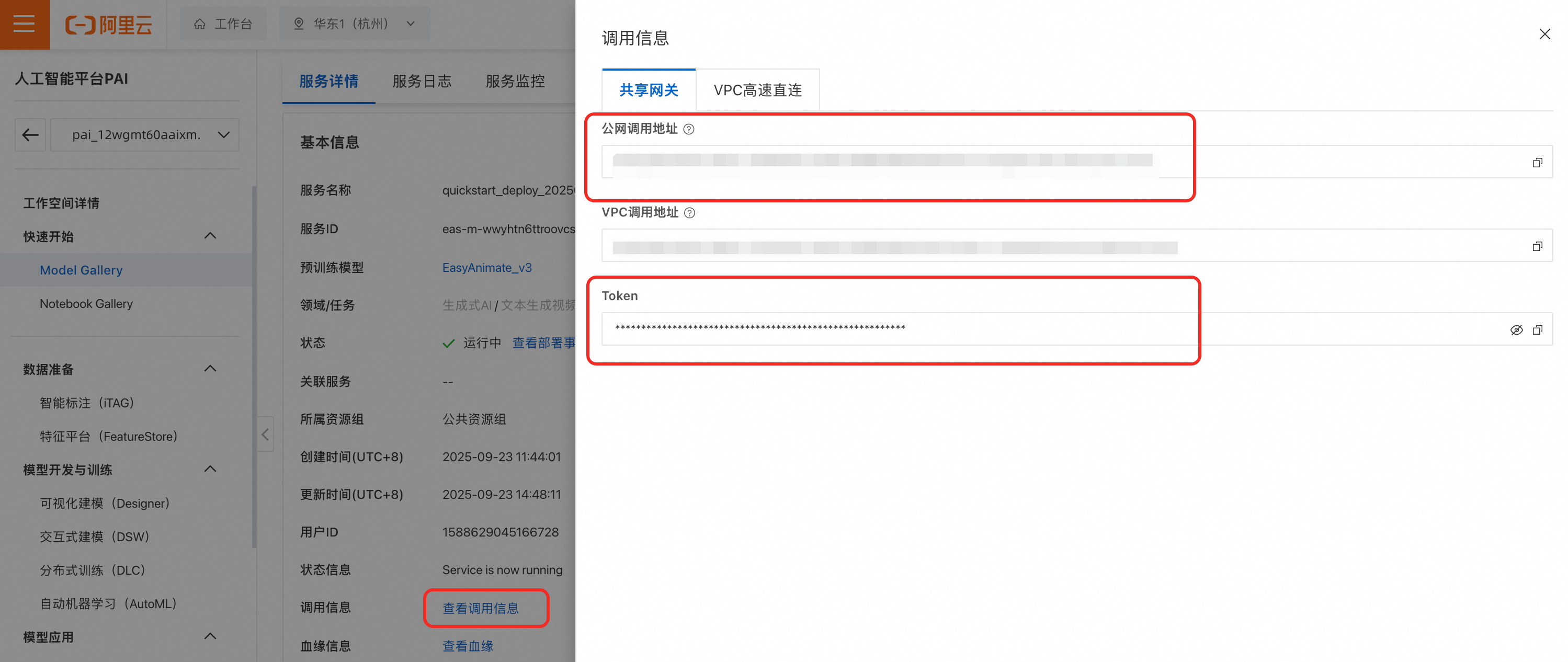
在服务详情页面的资源详情区域,单击查看调用信息,获取服务调用地址和Token。
调用服务,生成视频。Python请求示例如下:
import os import requests import json import base64 from typing import Dict, Any class EasyAnimateClient: """ EasyAnimate EAS 服务 API 客户端。 """ def __init__(self, service_url: str, token: str): if not service_url or not token: raise ValueError("服务地址 (service_url) 和 Token 不能为空") self.base_url = service_url.rstrip('/') self.headers = { 'Content-Type': 'application/json', 'Authorization': token } def update_model(self, model_path: str, edition: str = "v3", timeout: int = 300) -> Dict[str, Any]: """ 更新并加载指定的模型版本和路径。 Args: model_path: 模型在服务内的路径, 如 "/mnt/models/Diffusion_Transformer/EasyAnimateV3-XL-2-InP-512x512"。 edition: 模型版本,默认为 "v3"。 timeout: 请求超时时间(秒),模型加载较慢,建议设置较长时间。 """ # 1. 更新版本 requests.post( f"{self.base_url}/easyanimate/update_edition", headers=self.headers, json={"edition": edition}, timeout=timeout ).raise_for_status() # 2. 更新模型路径并等待加载 print(f"发送加载模型请求: {model_path}") response = requests.post( f"{self.base_url}/easyanimate/update_diffusion_transformer", headers=self.headers, json={"diffusion_transformer_path": model_path}, timeout=15000 ) response.raise_for_status() return response.json() def generate_video(self, prompt_textbox: str, **kwargs) -> bytes: """ 根据提示词生成视频。 Args: prompt: 英文正向提示词。 **kwargs: 其他可选参数,参考下方的参数说明表格。 Returns: MP4 格式的视频二进制数据。 """ payload = { "prompt_textbox": prompt_textbox, "negative_prompt_textbox": kwargs.get("negative_prompt", "The video is not of a high quality, it has a low resolution..."), "width_slider": kwargs.get("width_slider", 672), "height_slider": kwargs.get("height_slider", 384), "length_slider": kwargs.get("length_slider", 144), "sample_step_slider": kwargs.get("sample_step_slider", 30), "cfg_scale_slider": kwargs.get("cfg_scale_slider", 6.0), "seed_textbox": kwargs.get("seed_textbox", 43), "sampler_dropdown": kwargs.get("sampler_dropdown", "Euler"), "generation_method": "Video Generation", "is_image": False, "lora_alpha_slider": 0.55, "lora_model_path": "none", "base_model_path": "none", "motion_module_path": "none" } response = requests.post( f"{self.base_url}/easyanimate/infer_forward", headers=self.headers, json=payload, timeout=1500 ) response.raise_for_status() result = response.json() if "base64_encoding" not in result: raise ValueError(f"API 返回格式错误: {result}") return base64.b64decode(result["base64_encoding"]) # --- 使用示例 --- if __name__ == "__main__": try: # 1. 配置服务信息,请替换为真实的服务调用地址和Token,建议将其设置为环境变量 EAS_URL = "<eas-service-url>" EAS_TOKEN = "<eas-service-token>" # 2. 创建客户端 client = EasyAnimateClient(service_url=EAS_URL, token=EAS_TOKEN) # 3. 加载模型 (服务部署后,默认不会加载任何模型。在发起生成请求前,您必须至少调用一次update_model来指定要使用的模型。后续若需切换模型,则再次调用此方法。) client.update_model(model_path="/mnt/models/Diffusion_Transformer/EasyAnimateV3-XL-2-InP-512x512") # 4. 生成视频 video_bytes = client.generate_video( prompt_textbox="A beautiful cat playing in a sunny garden, high quality, detailed", width_slider=672, height_slider=384, length_slider=72, sample_step_slider=20 ) # 5. 保存视频文件 with open("api_generated_video.mp4", "wb") as f: f.write(video_bytes) print("视频已成功保存为 api_generated_video.mp4") except requests.RequestException as e: print(f"网络请求错误: {e}") except (ValueError, KeyError) as e: print(f"数据或参数错误: {e}") except Exception as e: print(f"发生未知错误: {e}")服务接口输入参数说明如下:
步骤三:(可选)微调预训练模型
在自定义数据集上微调训练模型,可以生成特定风格或内容的视频。微调操作步骤如下:
登录PAI控制台。在左侧导航栏单击工作空间列表,选择并单击进入目标工作空间。
在左侧导航栏单击。
在Model Gallery页面,搜索EasyAnimate 高清长视频生成模型,单击训练进入配置页面。

资源来源选择公共资源,实例规格选择A10及其以上显卡的实例,超参数可以按需配置,其他参数默认即可。
如果您想使用自定义数据集微调模型,可参考如下内容:
准备数据文件夹和meta文件。数据文件夹中为训练使用的图片和视频。meta文件为JSON格式,每条数据由文件路径、文本描述,数据类型组成,分别用 "file_path", "text", "type"字段表示,例如:
[ { "file_path": "00031-3640797216.png", "text": "1girl, black_hair", "type": "image" }, { "file_path": "00032-3838108680.png", "text": "1girl, black_hair", "type": "image" } ]当数据类型为视频时,指定 "type":"video";当数据类型为图片时,指定 "type":"image"。
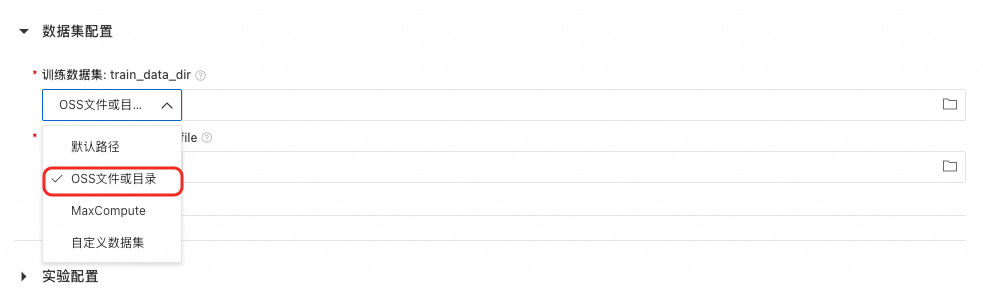
分别上传和选择数据文件夹和meta文件。在训练配置页面,选择OSS文件或目录,然后分别上传和选择数据文件夹和meta文件。
单击训练 > 确定创建训练任务。在本文选择的环境配置下训练大约需要40分钟,当任务状态为成功时,代表模型训练成功。
后续查看训练任务详情,可通过在左侧导航栏单击Model Gallery > 任务管理 > 训练任务,然后再单击任务名称查看。
单击右上角的部署按钮部署微调后的模型。当状态变为运行中时,代表模型部署成功。

在服务详情页面,单击页面上方的查看WEB应用。
后续查看服务详情,您可通过在左侧导航栏单击Model Gallery > 任务管理 > 部署任务,然后再单击服务名称查看。
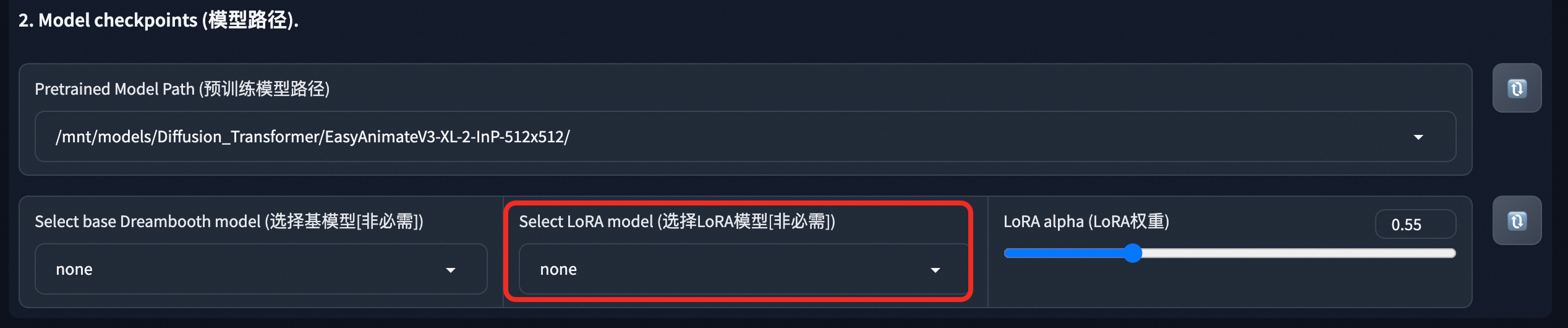
在WebUI界面,选择训练完成的LoRA模型进行视频生成。API调用方式可参考步骤二。
生产环境应用建议
及时停止实例或服务节省成本:本教程使用了公共资源创建DSW实例及EAS模型服务,当您不需要时请及时停止或删除实例(服务),以免继续扣费。
停止或删除DSW实例:
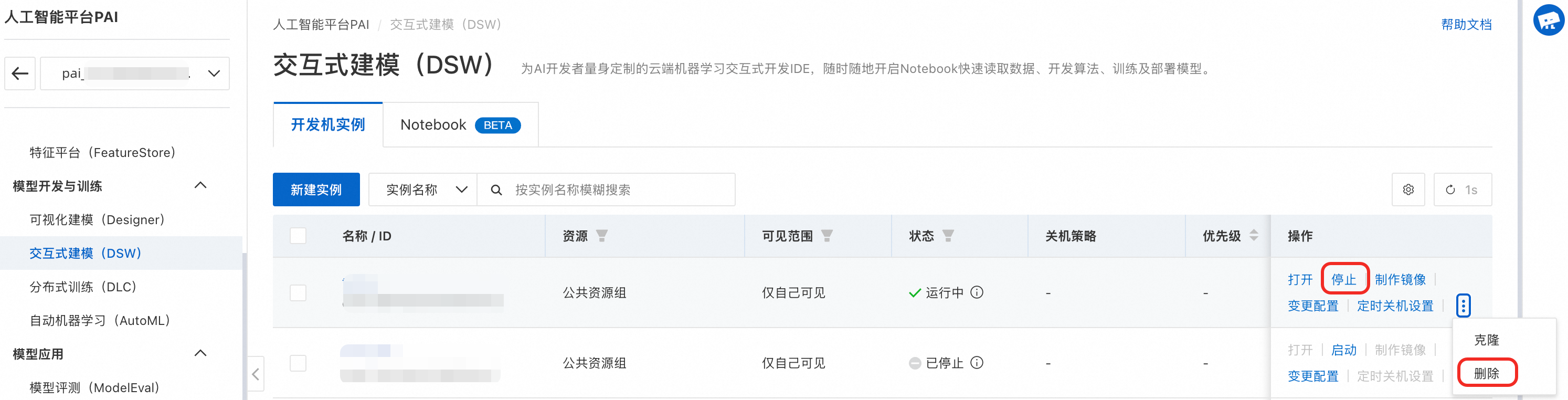
停止或删除EAS模型服务:
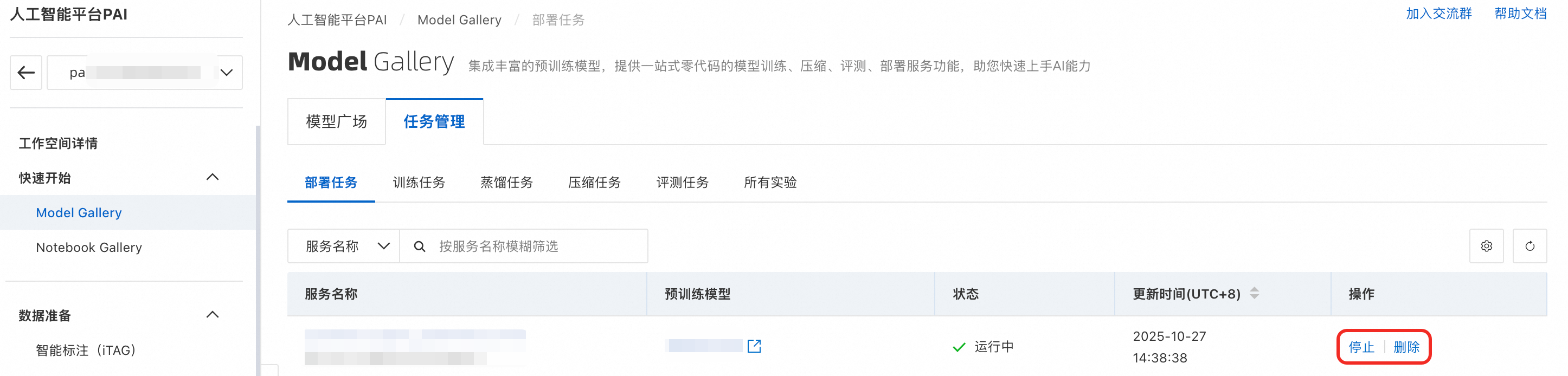
生产环境使用EAS部署服务:如果需要将模型应用于生产环境,建议采用方式二,一键将模型部署到EAS。如果采用了方式一,您可以通过制作自定义镜像方式将模型部署到EAS,详情请参见将模型部署为在线服务。
EAS 提供了如下功能,以应对复杂的生产环境:
相关文档
EAS提供了场景化部署方式,可一键部署基于ComfyUI和Stable Video Diffusion模型的AI视频生成服务,详情请参见AI视频生成-ComfyUI部署。