
EAS提供了共享网关和专属网关,两者皆支持公网或内网调用,调用流程基本一致,可根据实际情况选择网关和调用地址。
网关选择
EAS服务的网关提供共享网关和专属网关,差异点如下:
对比维度 | 共享网关 | 专属网关 |
公网调用 | 默认支持。 | 支持,需先开通。 |
内网调用 | 默认支持。 | 支持,需先开通。 |
成本 | 免费提供。 | 额外付费。 |
适用场景 | 带宽共享,适合流量比较小且无需定制访问策略的服务。推荐测试场景使用。 | 带宽专享,适合对安全性、稳定性和性能要求高,流量比较大的服务。推荐生产环境使用。 |
服务配置方式 | 默认配置,直接使用。 | 需先创建,在服务部署时选择专属网关,详见通过专属网关调用。 |
调用地址选择
公网地址:适用于任何可以访问公网的环境。请求会经由EAS共享网关转发至EAS在线服务。
VPC地址:适用于当您的调用程序与EAS服务部署在同一地域的情况。位于同一地域的两个VPC网络支持建立VPC连接。
相比公网调用,VPC内网调用速度更快(免去公网调用中的网络性能开销)且成本更低(内网流量通常免费)。
如何调用
调用服务的关键是获取服务的访问地址和Token,并根据具体的模型服务构造请求。
一、获取访问地址和Token
部署服务后,系统会自动生成调用所需的访问地址(Endpoint)和授权令牌(Token)。
控制台提供的访问地址是基础地址。您通常需要在其后拼接正确的接口路径 ,才能构成完整的请求URL。路径错误是导致404 Not Found的最常见原因。
在推理服务页签,单击目标服务名称进入概览页面,在基本信息区域单击查看调用信息。
在调用信息面板,可获取访问地址和Token。根据您的实际情况选择公网或VPC地址,后续使用<EAS_ENDPOINT>和<EAS_TOKEN>指代这两个值。

二、构造并发送请求
无论是使用公网还是VPC地址,请求的构造方式基本一致,仅URL不同。一个标准的调用请求,通常包含以下四个核心要素:
请求方法(Method): 最常用的是POST、GET。
请求路径(URL):由基础地址<EAS_ENDPOINT>和具体的接口路径拼接而成。
请求头(Headers):通常至少需要认证信息Authorization: <Token>。
请求体(Body):其格式(比如JSON)由具体部署的模型接口决定。
重要通过网关调用时,请求体大小不得超过 1MB。
场景示例
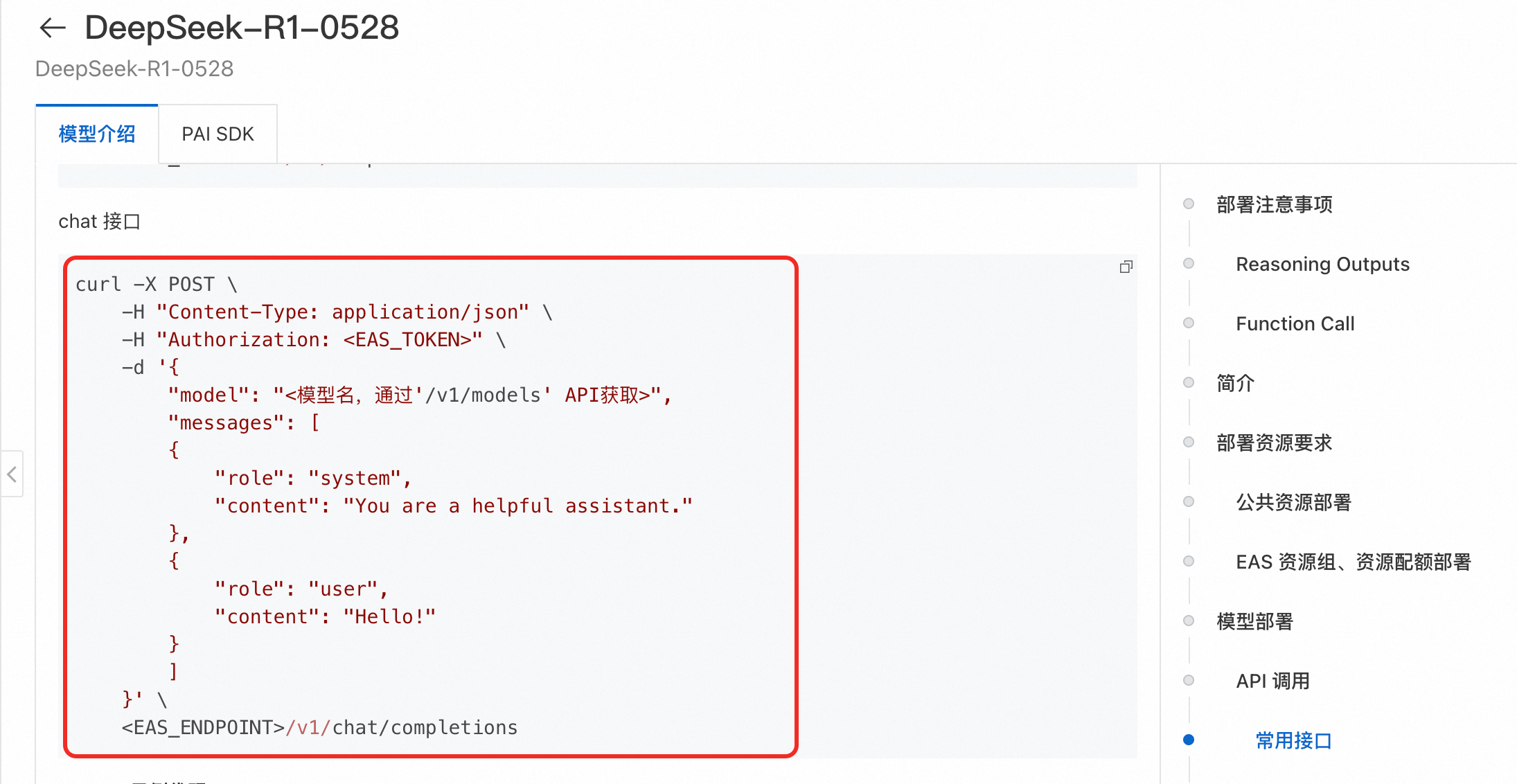
场景一:调用Model Gallery部署的模型
请直接查询Model Gallery的模型介绍页面,其中通常会以curl命令或Python代码提供最准确的API调用示例,包括完整的 URL 路径和请求体格式。
cURL命令
curl命令的基本语法格式为curl [options] [URL]:
options为可选参数,常用的有:
-X指定请求方法,-H指定请求头,-d指定请求体。URL表示要访问的HTTP接口。
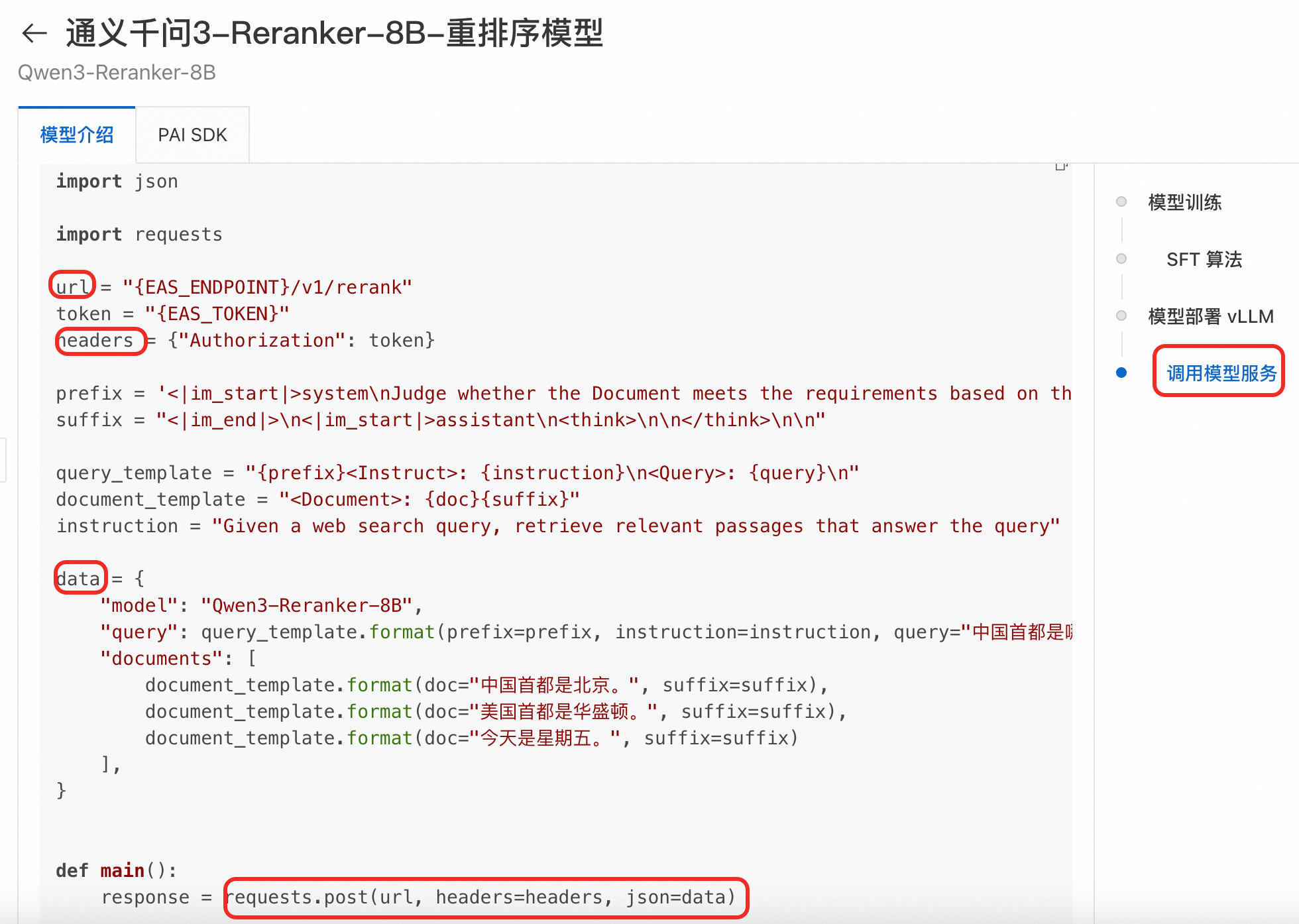
Python代码
通过python代码说明,以Qwen3-Reranker-8B模型为例,注意其URL、请求体就与curl命令示例不同,请务必参考对应的模型介绍说明。
场景二:调用大语言模型
LLM服务通常提供兼容OpenAI的API接口,例如对话接口(/v1/chat/completions)、补全接口(/v1/completions)等。
以使用vLLM部署的DeepSeek-R1-Distill-Qwen-7B模型服务为例,请求其对话接口需要的元素如下(更多请参见LLM调用):
请求方法:POST
请求路径:<EAS_ENDPOINT>/v1/chat/completions
请求头:Authorization: <Token> 和 Content-Type: application/json
请求体:
{ "model": "DeepSeek-R1-Distill-Qwen-7B", "messages": [ { "role": "system", "content": "You are a helpful assistant." }, { "role": "user", "content": "hello!" } ] }
示例:使用curl和python调用
假设<EAS_ENDPOINT>为http://16********.cn-hangzhou.pai-eas.aliyuncs.com/api/predict/test。
curl http://16********.cn-hangzhou.pai-eas.aliyuncs.com/api/predict/test/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: *********5ZTM1ZDczg5OT**********" \
-X POST \
-d '{
"model": "DeepSeek-R1-Distill-Qwen-7B",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "hello!"
}
]
}' import requests
# 替换为实际访问地址
url = 'http://16********.cn-hangzhou.pai-eas.aliyuncs.com/api/predict/test/v1/chat/completions'
# header信息 Authorization的值为实际的Token
headers = {
"Content-Type": "application/json",
"Authorization": "*********5ZTM1ZDczg5OT**********",
}
# 根据具体模型要求的数据格式构造服务请求。
data = {
"model": "DeepSeek-R1-Distill-Qwen-7B",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "hello!"
}
]
}
# 发送请求
resp = requests.post(url, json=data, headers=headers)
print(resp)
print(resp.content)更多场景
通用Processor(包括TensorFlow、Caffe、PMML等)部署的服务:请参见基于通用Processor构造服务请求。
自己训练的模型:调用方式与原模型一样。
其他自定义服务:请求格式由您在自定义镜像或代码中定义的数据输入格式决定。
常见问题
请参见服务调用FAQ。